EVENT AGENDA
Event times below are displayed in PT.




Data @Scale is an invitation-only technical conference for engineers focused on the latest developments and challenges associated with building, operating, and using Data systems at scale. Building services that serve millions or even billions of people presents a set of complex, and often unprecedented, engineering challenges.
Join experts from companies including Google, Hubspot, InfluxData, OM1 and Wayfair to openly discuss these challenges and collaborate on the development of new solutions. We’ll spend the day covering a wide range of topics including database, analytics, streaming, distributed systems, data privacy, and machine learning.
Keep an eye on this page – we’ll continue to add to the lineup as we get closer to the show.
Event times below are displayed in PT.
The growing availability of healthcare data in digital form is changing clinical research and the way that medicine is practiced. When massive amounts of healthcare data are combined with big data architectures, machine learning, and a great deal of ingenuity, it is now possible to compare treatments and providers based upon their outcomes in real patient populations, and it is increasingly possible predict patient outcomes under different treatment scenarios. But how do we protect the privacy of patients while enabling this?In this talk, I will explore the challenges of working with patient data and present solutions to combining large-scale healthcare datasets while still preserving patient privacy.

Options for database technologies and deployment strategies, whether on-premises or cloud-based, are growing at a significant pace. With this growth often comes the desire to implement organizational constraints around technology choices. In this session we’ll examine the positive and negative impacts of selection constraints, highlighting two contrasting use cases. We’ll also offer recommendations on how to achieve a balance of flexibility and control.

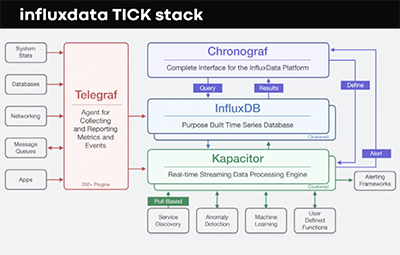
InfluxData builds a timeseries platform primarily deployed for DevOps and IOT monitoring. This talk presents several lessons learned while scaling the platform across a large number of deployments - from single server opensource instances to highly available high-throughput clusters. This talk presents a number of failure conditions that informed subsequent design choices. I'll discuss designing backpressure in an AP system with 10's of thousands of resource limited writers; trade-offs between monolithic and service-oriented database implementations; and lessons learned implementing multiple query processing systems.

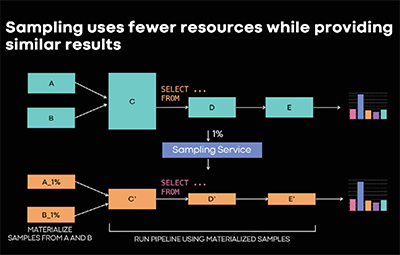
The volume of data processed by Facebook’s analytics workload has been rapidly increasing, resulting in greater compute and storage demands. We have been investigating how to use sampling as a technique offset such demand while still providing good approximate query results. In this talk, we discuss the approaches we have been using to support the computation of analytical dashboards using sampling, where approximations result in negligible visual differences of the graphs. We discuss the challenges that this poses to approximate computation, such as the need to consider uncertainty propagation when calculating aggregated metrics. We will also show the benefits in terms of resource consumption, in both compute and storage.


Transient Replication, an adaptation of Witness Replicas, is a mechanism for achieving up to 50% disk space and compute savings in a DBMS that replicates many small records without a distributed log. With Transient Replication we divide the group of voting replicas into nodes that fully replicate a value and nodes that transiently replicate that value. Under non-failure conditions, this allows nodes to avoid retaining values they transiently replicate. Building on Transient Replication we can also implement an optimization, called Cheap Quorums, to avoid writing to transient replicas entirely that helps eliminate read and write load at transient replicas. I will also present mitigations that enable Transient Replication to perform well even under failure conditions.

Deletion is critical to helping people control their data. It also has unique technical challenges at scale – for example, managing deletion across distributed systems and building in mechanisms to confirm completeness and accuracy. This talk will cover Facebook’s Deletion Framework, a system we built to automatically detect gaps, ensure completeness, and make sure the correct data is deleted.

Wayfair is an e-commerce company in the home goods space, whose annual revenue has grown ~10x in 6 years. The corresponding data infrastructure’s growth is superlinear. Ben Clark will describe an early-stage hodge-podge of under-engineered components, traffic patterns that started to looked like trouble, and four decisions to invest in writing or modifying data plumbing components in C, C++ and Rust. The latest of these is ‘Tremor,’ a traffic shaper and router that is replacing logstash and regulating the flow of data through our fast-growing network of Kafka clusters and destination data stores.

Kubeflow, a framework on Kubernetes that supports the full lifecycle of an ML application, addresses three of the biggest development challenges: scalability, portability, and composability. It provides a single, unified tool for running common processes such as model training, evaluation, and serving, as well as monitoring, logging, and other operational tools. It supports the use of the entire stack locally, on-premises, or on the cloud platform of your choice, including specialized hardware such as GPUs. By reducing variability between services and environments, Kubeflow enables applications that are more robust and resilient, resulting in less downtime, quality issues, and customer impact.

At DataXu, we manage digital advertising campaigns at scale — collecting and processing large volumes of log data daily, and delivering reports that track campaign performance metrics on an hourly basis. To achieve this, we successfully migrated multiple databases and warehouses to the cloud. Today, our reporting warehouse supports all major business workflows, ranging from daily impression/activity reporting for customers to business metrics for internal teams. DataXu’s “cloud native” warehouse architecture was an early user of Glue Data Catalog, Athena (Presto-as-a-service), Lambda and serverless infrastructure on AWS. In this talk, we will share lessons learned in our multi-year journey to the cloud.

Since the passing of the General Data Protection Regulation (GDPR), many companies needed to increase the security of their data systems. In order to easily migrate teams to new, secure clusters, the HubSpot Data Infrastructure team wrote a managed ingestion pipeline using Kafka that enables them to seamlessly migrate teams' indices from one cluster to another with minimal effort on the teams' behalf. Patrick will discuss the ingestion pipeline, the migration process, and how it leverages Elasticsearch features to make the migration seamless for HubSpot's other development teams.

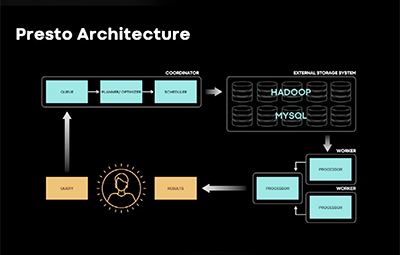
Presto is an open source distributed SQL engine widely recognized for its low-latency queries, high concurrency, and native ability to query multiple data sources. Inspired by increasingly complex SQL queries, engineers at Facebook and Starburst have recently focused on cost-based query optimization. In the first part of this talk, we will present the design and implementation of the Presto cost-based optimizer (CBO) to support connector-provided statistics, estimate selectivity, and choose efficient query plans. In the second part of the talk, we will discuss a new mechanism in Presto that computes statistics seamlessly and efficiently making all Presto-generated data ready for CBO without any extra manual steps. Finally, we will discuss our future work enhancing the CBO and statistics collection in Presto.


With the growth of edge services, we face the challenge of safely collecting large volumes of data at low latency for data processing and analytics systems. In this talk, we present Palisade, an overload protection system for reporting and analytics data processing infrastructures. Palisade is built on a flexible stream processing system called Akamill that provides buffering, connection pooling, and transformations to support near-real-time data collection for applications. We focus on the continuous collection of traffic summaries and the control system that smooths out large dynamic traffic spikes with minimal overhead.

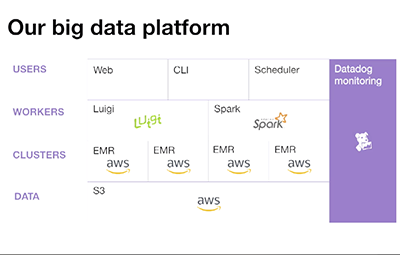
Every day at Datadog, we run massive data pipelines to power core functionality. In this talk, we’ll cover best practices we use at Datadog to ensure that we reliably deliver this functionality while processing trillions of points/day in the face of exponential data growth, hardware failures, corrupt data, and even human error.