EVENT AGENDA
Event times below are displayed in PT.




Networking @Scale is a technical conference for engineers that build and manage large-scale networks.
Networking solutions are critical for building applications and services that serve billions of people around the world. Building and operating such large-scale networks often present complex engineering challenges to solve. The Networking @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
Joining us are speakers from Alibaba, Apple, AWS, Google, Meta and Microsoft. The Fall Networking @Scale will cover all aspects of networking innovation (L2-L7) such as load balancing and prioritization of traffic, monitoring and diagnosis of problems in the network with new instrumentation, testing strategies for new devices and protocols, achieving design, deployment and operational efficiencies at scale for optical networks and much more. We are asking speakers to share their experience in Improving the Network performance, and experience across these areas for large-scale networks.
This event will take place virtually and span two days, featuring pre-recorded presentations and LIVE Q&A sessions.
Event times below are displayed in PT.

This presentation will introduce Alibaba Predictable Network. With the emerging AI/ML new workload, data center network is evolving rapidly. A large-scale high-performance network becomes crucial to support a large-scale AI cluster. During the large-scale deployment of the RDMA network in the past 5 years, Alibaba cloud came out with the new Host-Network Fusion architecture, which can provide predictable network performance at scale.

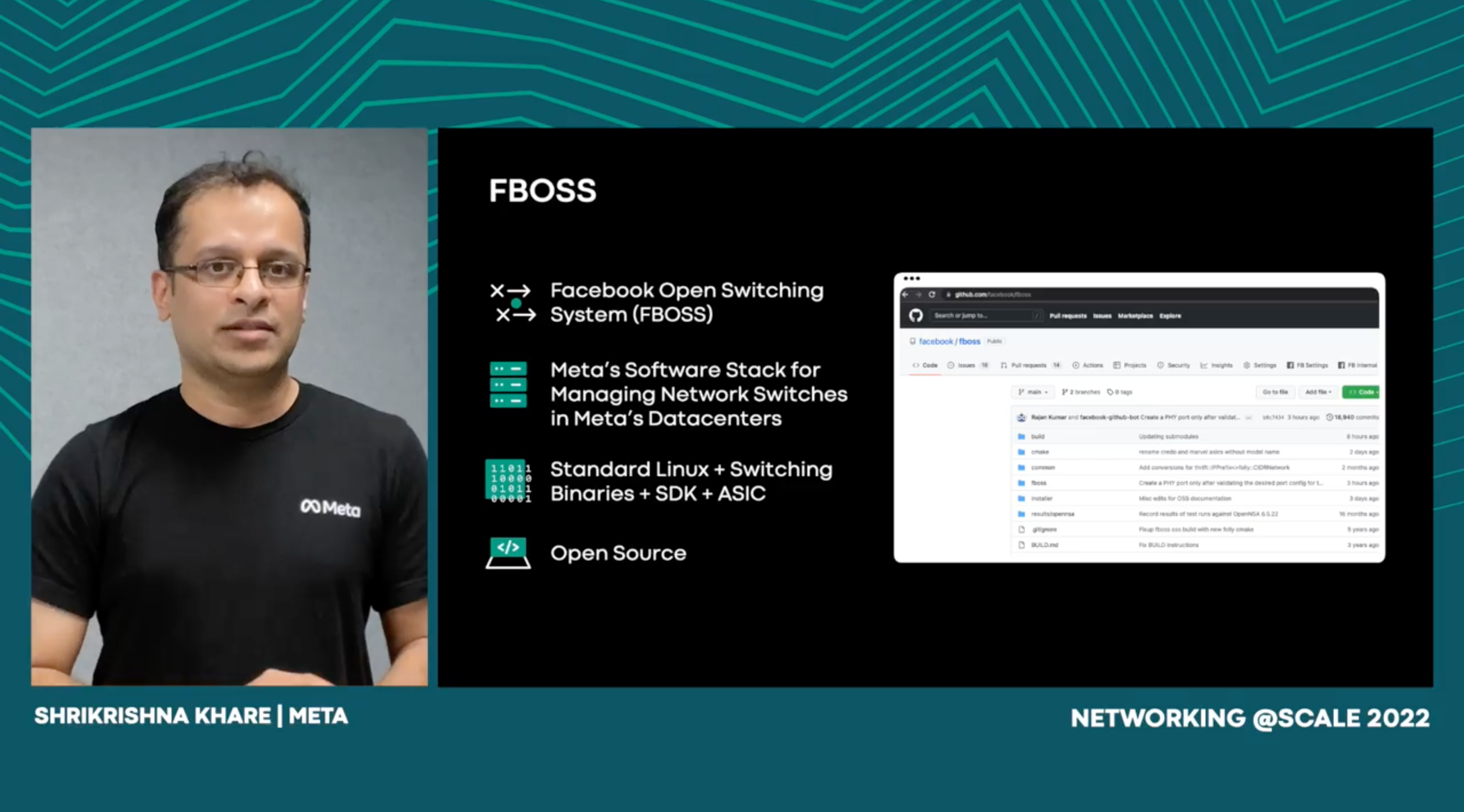
FBOSS is Meta’s software stack for controlling/managing network switches deployed in Meta’s datacenters. FBOSS is one of the largest services in Meta (in terms of the number of instances deployed) and powers Meta’s Network. The talk presents our experience designing, developing and operating FBOSS: an in-house software built to manage and support a set of features required for data center switches of a large scale Internet content provider. We present the key ideas underpinning the FBOSS model viz.: switch-as-a-server and deploy-early-and-iterate. These ideas have enabled us to build a stable and scalable network. We demonstrate these ideas with concrete examples: Switch Abstraction Interface (SAI) defines a vendor-independent API for programming the forwarding ASIC. We developed a new SAI based implementation for FBOSS. The new FBOSS implementation was deployed at a massive scale to a brownfield deployment, and was also leveraged to onboard a new switch vendor into the Meta infrastructure. We present this effort as a case study to further illustrate the FBOSS design, development and operations model. In particular, the case study shares our experience and lessons learned while: -Developing the new FBOSS implementation to be functionally equivalent to the existing implementation for all production use cases, -Methodology for Third party vendor ASIC/SDK integration and functionality validation, -FBOSS push infrastructure and qualification pipeline, Maintaining and upgrading a mix of old and new implementation during gradual and phased brownfield deployment, -Tooling enhancements to detect/mitigate/triage/repair issues discovered while rolling out the new implementation to the brownfield deployment as well as onboarding new switch vendor to production, -Rolling out patches to mitigate/fix production issues without causing traffic disruption.


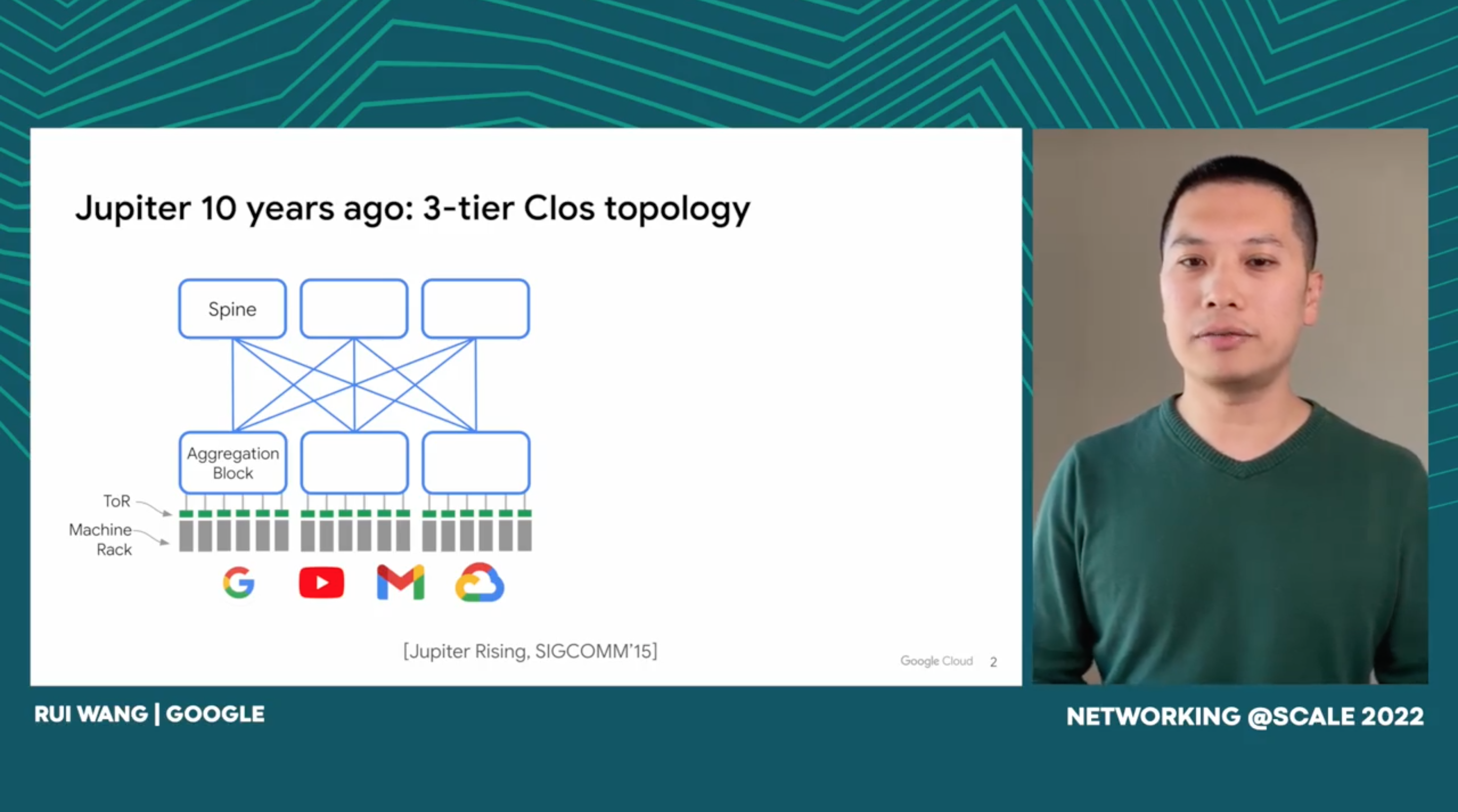
We present a decade of evolution and production experience with Google’s Jupiter datacenter network. In this period, Jupiter has delivered 5x higher speed and capacity, 30% reduction in capex, 41% reduction in power, incremental deployment and technology refresh all while serving live production traffic. A key enabler for these improvements is evolving Jupiter from a Clos to a direct-connect topology among the machine aggregation blocks. Critical architectural changes for this include: A datacenter interconnection layer employing Micro-Electro-Mechanical Systems (MEMS) based Optical Circuit Switches (OCSes) to enable dynamic topology reconfiguration, centralized Software-Defined Networking (SDN) control for traffic engineering, and automated network operations for incremental capacity delivery and topology engineering.

Featuring Rui Miao - Alibaba, Shrikrishna Khare, Srikrishna Gopu, Rui Wang Moderated by Luca Niccolini

The first half of the talk will highlight the expansive global fiber network that is being built and managed by BBE. We will first highlight the submarine fiber optic systems that we are building to connect the globe. We are working on over 25 submarine fiber network builds but will highlight just a few. Bifrost and Echo will be shown which are the first to directly connect the US and Singapore and will support SGA, our first APAC data center. The vast 2Africa project will be discussed, which is both the world’s largest submarine cable network and has the potential to connect the largest number of people, 3 Billion. We have established a series of firsts in the submarine fiber world and are driving new innovations which are transforming the industry. The connection of our submarine networks to our terrestrial backbone will be shown and how this network interconnects our data centers. Next, we describe how we design and build the hierarchies of the optical transport layer built on top of those fiber paths. We have to model and inter-operate multiple hardware types, from multiple vendors, across multiple technology generations, to achieve maximum utilization of our fiber. The scale of network growth means that we continuously deploy the latest generation of high-performance transponder systems onto our network, but each additional generation imposes an operational (support) tax which can only be mitigated by focusing on automation for both configuration and maintenance (e.g. software upgrades). Finally, we will discuss our approach to provisioning capacity on this network, our solutions for distributed provisioning and monitoring of this global fleet of hardware, and our approach to diagnosing and remediating network failures. This, as well as the design challenge described prior, requires us to maintain a suite of in-house software systems, without which operating at our scale would not be possible.


Like other large cloud providers, Microsoft operates two planet-scale wide-area networks: AS8075 WAN for Internet traffic and AS8074 software-defined WAN to carry inter-datacenter traffic. Maintaining two networks has operational challenges and so we consolidated the split-WAN architecture into a unified OneWAN using SDN principles (used in Swan). OneWAN grappled with the scaling challenges posed by network and routing table sizes 10 times larger than Swan. In addition, Internet Traffic Engineering (ITE) is another SDN system that enables performance-aware egress peer selection and inbound traffic engineering between autonomous systems. Together, OneWAN and ITE controllers measure peering traffic and adapt the backbone and the peering edge to dynamic demand spikes and capacity reductions.

Featuring Stephen Grubb, Joseph Kakande, Somesh Chaturmohta Moderated by Andrey Golovanov, Meta


Managing data center networks with low loss requires understanding traffic patterns, especially burstiness of the traffic, at fine time granularity. Yet, monitoring traffic with millisecond granularity fleet wide is challenging. To gain more visibility into our production network, we design millisampler, a BPF based lightweight traffic measurement tool deployed in every server in the entire fleet for continual monitoring that operates at high granularity timescale. Millisampler data allows us to characterize microbursts at millisecond or even microsecond granularity, and simultaneous data collection enables analysis of how synchronized bursts interact in rack buffers. We’ll discuss the design, implementation, and production experience with millisampler, and share some interesting observations we got with the millisampler data.

At Meta, we need to be able to readily determine if network conditions are responsible for instances of poor quality of experience (QoE) such as images loading slowly or video stalling during playback. In response, we’ve developed Network SLOs, which can be thought of as a product’s "minimum network requirements’ for good QoE. If the network between Meta and a user does not meet the product’s SLO requirements, QoE will be degraded. In this talk, we describe our work over the past three years on deriving and operationalizing Network SLOs for Meta’s user facing products. First, we discuss how we measure quality of experience for a handful of products and our approach to quantifying the relevant network conditions. We then discuss how we use a combination of statistical tools to derive Network SLOs, and how we process trillions of measurements each day to evaluate Network SLO compliance. We present case-studies of how Network SLOs have been used to triage regressions in QoE, identify gaps in Meta’s edge network capacity, and surface inefficiencies in how product utilizes the network.


Since the early days of the Internet, capacity has been the prime metric to quantify the quality of the Internet access. While capacity was the primary challenge back in those days, we have successfully reached a point where the vast majority of users can easily access sufficient capacity for the majority of the use-cases. But still, Internet experience is often lacking the smoothness that we would expect. Video-conferencing still has frequent issues, video gaming is rarely a smooth experience and web-browsing still suffers from bad page-load times. We present a new metric, called ""Responsiveness under working conditions"", which significantly broadens the scope far beyond traditional capacity and latency measurements. This metric aims at quantifying the network's ability to provide low latency while at the same time providing high capacity. The measurement methodology not only measures the network, but also the end-host networking stack. We will describe how measuring responsiveness will allow to detect deep buffers in the server's networking stack and how it affects the end-user experience. Further, we describe steps that can be taken to reduce those buffers. We will conclude this talk by providing resources and open-source tools to allow everyone to reproduce the same measurement on their infrastructure and tune their networking stack for the benefit of their end-users.

Featuring Yimeng Zhao, Brandon Schlinker, Sharad Jaiswal. Moderated by Neil Spring

We work on a layer 4 load balancer called Shiv. Shiv routes packets to backends using a consistent hash of the 5-tuple of the packet (namely, the source ip, destination ip, source port, destination port, and protocol). Shiv’s objective is to route packets for a connection (which all have the same 5-tuple) to the same backend for the duration of the connection. If it is unable to do so, this leads to broken connections and user impact (for example, stalled videos). While consistent hashing is quite resilient to changes, when a large number of backends are added or removed, remappings occur, resulting in broken connections. To protect from such changes, Shiv maintains a cache that contains a mapping from 5-tuple to backend. The logic used by Shiv to route packets can be summarized as follows: If the 5-tuple of the packet is in its cache, route it to the backend indicated by the cache. Otherwise, calculate the hash function on the 5-tuple to obtain the destination backend, route the packet to that backend, and place the (5-tuple, backend) entry in the cache. Shiv works well under the following conditions: - In steady state, when the arrangement of Shivs and backends is the same. - When the arrangement of Shivs changes. In this case, packets for a connection may land on a different Shiv host than earlier packets, but both Shiv hosts use the same consistent hash function, and therefore, pick the same backend. - When the arrangement of backends changes. In this case, packets for a connection continue to land on the same Shiv host, which utilizes its cache to route the packet to the same backend as it used to. However, during changes to the arrangement of both Shivs and backends, a nontrivial number of misroutings occur, because the following sequence of events could happen: - Packets for a connection C arrive at a Shiv host A, which picks a backend X - A large topology change occurs on the Shivs and backends. - Packets for connection C now land at Shiv host B != A, which picks a backend Y != X because the hash ring has changed. We have implemented two solutions to this problem, that we will talk about: - Embedding “Server ID” hints into packets, that enable Shiv to route the packets to a specific server without having to perform a consistent hash. - Sharing the 5-tuple to backend cache among all Shivs in a cluster, thereby facilitating consistent decision making among them in the face of hash ring changes.


AWS Global Accelerator (AGA) leverages Amazon’s global network, anycast routing, and integrated load-balancing techniques to reduce latency and improve availability. In this session, we discuss the architecture, capabilities, and challenges of operating AGA at scale. We will provide insight into how AGA drives path optimization through the integration of customer-defined traffic control and real-time internet performance. We end the session describing future work in this space.


Featuring: Aman Sharma, Andrii Vasylevskyi, Alan Halachmi, Akshat Aranya Moderated by Bharet Parekh

Rajiv is a Software Engineering Director in the Network Infrastructure group at Meta. He... read more


Dennis Cai, Head of Network Infrastructure of Alibaba Cloud. His team is responsible for... read more

Shrikrishna Khare is a software engineer at Meta Platforms Inc. (formerly Facebook). He works... read more

Srikrishna Gopu is a software engineer at Meta Platforms Inc. (formerly Facebook). He works... read more

Rui Wang is a Senior Staff Software Engineer at Google. He has contributed to... read more

Luca is a Software Engineer working on network protocols, improving applications performance at scale.... read more

Stephen Grubb is a Global Optical Architect at Meta. He is part of the... read more

Joseph Kakande is a Network Engineer at Meta. He is part of the BBE... read more

Umesh is a Partner Software Engineer in Microsoft Azure Networking. He works on software-defined... read more

Somesh Chaturmohta is a Principal Software Engineering Manager in the Microsoft Global Networking team,... read more

Andrey Golovanov, Network Engineer at Meta. His team is responsible for the development and... read more

Yimeng Zhao is a Research Scientist at Meta on the Network and Transport Analytics... read more

Brandon is a research scientist at Meta, where his work spans all things networking... read more

Sharad Jaiswal is an Optimization Engineer in Meta’s Edge/Traffic Infrastructure organization. His work focuses... read more

Christoph Paasch has been working on transport layer networking since 2010. Focusing on extensions... read more

Neil is a Research Scientist at Meta, working on tools to measure and improve... read more

Aman has been working as a software engineer in Networking at Meta over the... read more

Andrii has been working as a software engineer in networking for over a decade.... read more

Alan Halachmi is the Director of Solutions Architecture for Worldwide Public Sector at Amazon... read more

Akshat Aranya is a senior software engineer working with AWS Global Accelerator team for... read more

Bharat is a Software Engineering Manager in the Traffic Infrastructure group at Meta. He... read more