






Overview
In the System @Scale 2019, Justin Meza and Shruti Padmanabha spoke about Disaster Recovery at Facebook Scale, describing varying dimensions of the disaster recovery (DR) program at Meta. Since then, the DR program has evolved to pivot towards new risks that have surfaced.
Recap
To recap, let’s look at a typical Meta region.

As can be seen from the satellite view, this Meta region consists of several H-shaped buildings that house individual data centers (DC). A full-scale Meta region consists of five to six DC buildings consuming up to 150 megawatts (MW) of server load.
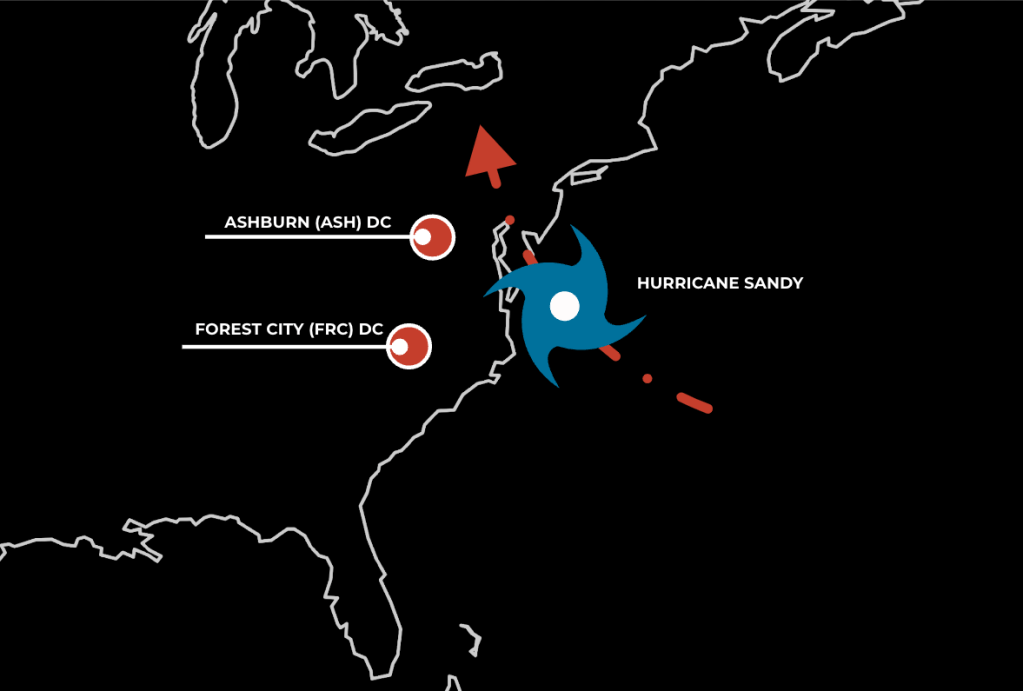
In October 2012, Hurricane Sandy came within 30 miles of one such full-scale region—our Ashburn (ASH) data center—and within a few hundred miles of another—our Forest City (FRC) data center. ASH was a fiber optic cables hub that connected us to the rest of the world, and FRC contained all of our MySQL primaries, so the destruction of either data center would have been devastating to our business.
Adding to the potential for disaster, at that time Meta was distributed across only three major data centers and was not prepared for the loss of an entire DC. With plans in the works to grow our infrastructure, the likelihood of regional disasters happening was growing.
At this critical juncture, Meta initiated the creation of its Disaster Recovery program to ensure that we can handle the loss of a single region without impacting site availability.
Disaster Recovery Since Then
To make sure our infrastructure is ready to handle single-region loss, we as a company decided to add extra capacity, which will enable the healthy, running regions to have enough resources to absorb the traffic from the faulty region without any overload risks or user impact. We refer to this physical capacity as DR buffer. We have been working with capacity-planning teams to make sure that services have the minimal capacity needed to survive single-region failures.
In addition, we worked on improving global replication for the services, including stateful and storage services, to make sure that we don’t have single points of failure or data unavailability during single-regions failures.
DR Storms are our Disaster Readiness Exercises, during which we isolate a production region to validate the end-to-end (E2E) readiness of the DR buffer and service placement. All of this happens in the production environment. We have executed several single-region DR storms in the production environment over the last 10 or so years.
New Risks on the Horizon: Power

In 2022, we started seeing an increasing number of risks pertaining to the electrical grid that affected the supply of power to our regions. Whereas in previous DR Storms we could validate the loss of (single) regional capacity, we hadn’t exercised our readiness relating to this particular mode of failure, so our recovery here was unknown.
Let’s review a case that occurred in the winter of 2022 in which one of our European data centers was at risk of a power loss due to an unusually high probability of demand curtailment requests from the electrical grid provider. A demand curtailment request is one where the grid provider asks the consumer (a data center in this case) to shed load by a considerable amount—50 to 100 percent—within a defined window of time. The window of risk in this case persisted for an extended period of time—not just days but weeks. We had a limited time to prepare for and exercise this scenario; we had entered uncharted territory.
Three key factors guided our decision-making process here:
- Response window: Refers to the amount of time we had to reduce demand once we’d been informed of the demand curtailment. Demand reduction in this case entailed the shutdown of server load. With this particular data center, we could rely on site-level redundancies such as backup generators, thus retaining the ability to define a window of our own beyond which shutdown was a must.
- State Transition: We had only exercised DR buffers with regional disconnection in the past. Never in the history of Disaster Recovery had we shut down a fully functioning production region—and we were determined not to let it happen now. It would have meant bringing a large data center region—one that’s serving user traffic and live streams, undergoing several manual and automated maintenance regimens and upgrades —to a complete halt. This sort of mammoth feat had never been exercised in the past!
- Recovery time: Refers to the time needed after the demand curtailment has been rescinded completely for the region to recover from the shutdown state. A long recovery would be indistinguishable from a permanent loss of the data center region, which could require a complete regional rebuild. Thus the recovery time needed to be limited, and the recovery steps had to be specific, repeatable and deterministic.
Based on the above factors, we needed to prepare and execute an end-to-end test to guarantee a graceful shutdown and recovery. This is where the DR exercises we call Power Storms were born. A Power Storm is a mammoth DR exercise where a typical production region is brought to a complete stop; then all servers are gracefully transitioned to a powered-down state and then fully restored to serving traffic again.
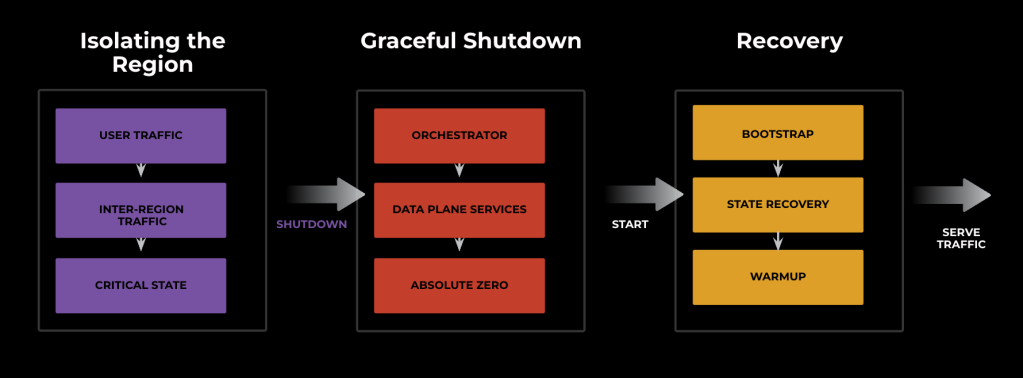
Flow of a typical Power Storm
A typical Power Storm has three stages:
Isolating a Region
A region is isolated by moving service and user traffic away from it through edge-to-origin VIPs. Critical-state transfer in the form of replica rebuild and primary promotions also take place here.
Graceful Shutdown
In this stage, all the data plane services are shut down gracefully through an asynchronous, data center-wide signaling mechanism. These signals are managed by the container orchestrator (called Twine). After this, all servers are shut down and brought to an absolute zero state where no services in the region are running.
During graceful shutdown it is critical to pay attention to all dependencies, especially with regard to the orchestrator. In the first version of the test, our orchestrator shut down prematurely, before all the data plane services could be reaped and shut down, because the orchestrator also reacted to the shutdown signal, and there was no clear way to distinguish the data plane from the dependencies of the orchestrator itself!
Paying close attention to dependencies in a fast-changing environment involves:
- Ensuring that critical dependencies between the control plane (such as Twine here) and the data plane are correctly and separately delineated in the recovery and shutdown paths.
- Guaranteeing that the control plane is immune from any signals that it is meant to manage.
- Continuously tracking dependencies by using frameworks such as BellJar.
Recovery
Recovery involves bootstrapping the region for the regional control plane/orchestrator, then starting data plane services and kicking off their recovery. The recovery also involves warming up various caches, replication catch-up, and other full or incremental state transfers. Once the region is healthy, we re-enable the VIPs, and the region resumes serving traffic!
After we tested Power Storm in a small region and achieved sufficient confidence, exercising similar testing in production at scale is key. Since the first storm in the winter of 2022, we have exercised Power Storms regularly!
While we were looking at these grid-related issues in Europe, our infrastructure was at risk from other sources too. This was even more evident in the winter of 2022, when multiple risk factors were prevalent nearly simultaneously.
Multi-regional Disaster Recovery (MRDR)
Over the last few years, we have observed multiple events that might overlap to impact our regions simultaneously. For example, in the winter of 2022:
- Electrical grid-related risks in Europe put all our EU regions at risk of load shedding.
- At the same time, winter storms and hurricane risks enveloped a large region of the mainland US.
- While one region was already impacted by the risks outlined above, a range of software failures threatened to shut down another region.
The potential combined impact of these scenarios put Meta at risk of losing multiple data center regions simultaneously! We call this multi-regional failure—a large-scale outage where more than one region is impacted—and we started to work on our Multi-regional Disaster Recovery (MRDR) program to prepare our infrastructure to be resilient to such complex and far-reaching incidents.
Let’s focus now on MRDR events where two regions are impacted. As our infrastructure grows, the likelihood of multi-regional outages increases, and we anticipate such incidents happening more often.
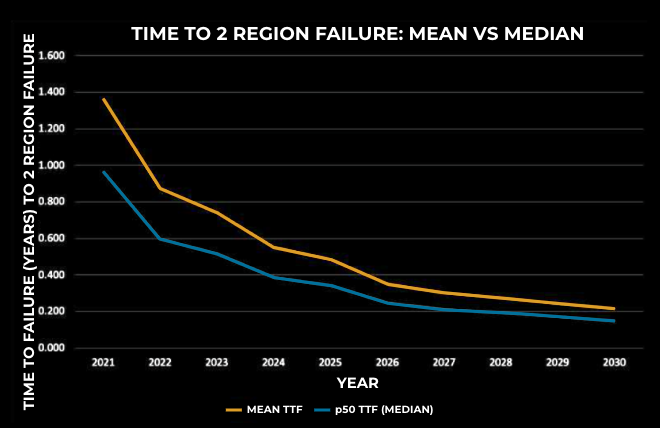
In the diagram above, the x-axis represents the year and the y-axis represents the time to region failure for two regions. As we can see, over recent years the mean and median times to region failure have become shorter and shorter. During MRDR events, we anticipate similar risks as a single-region DR problem:
- Overload: Demand can exceed supply, leading to an infrastructure meltdown. Demand here refers to user traffic on our products, and supply refers to our serving capacity as it pertains to single region failures.
- Data unavailability for data stores: We store data replicated across or with majority quorum. So if we don’t have the right data replication and placement, losing two or more regions can lead to data unavailability.
Next, we’ll take a deep dive into our strategy for mitigating the overload risks during MRDR. We hope to discuss our data unavailability strategy in our upcoming 2023 Reliability @Scale presentations.
Let’s assume we already had to disconnect one of our US regions due to hurricane risks, and all the healthy regions are running and consuming the DR buffer. With ongoing risks of load shedding in the EU, draining the EU region is not an option, since this will cause overload for the other regions. At this point, we ask ourselves about the overload strategy for MRDR. Shall we add capacity again, as we did in the single-region failures? Unfortunately, this solution presents multiple challenges:
- MRDR events can go beyond two downed regions, and adding capacity is not a scalable solution.
- Supply-chain or capacity-crunch issues. Given the scale of Meta’s infrastructure, getting capacity will take too much time.
Based on those challenges, we changed our buffer-based DR strategy to a site degradation-based one where each service in our infrastructure will degrade itself gracefully to tolerate the demand and survive the MRDR events. While this is a tradeoff between maintaining capacity and degrading our products during MRDR events, the site-degradation strategy works well for two-region failure, and we are continuing to refine it to minimize the impact on users during such events.
Applying site-degradation techniques such as service-level degradation, request shedding, and delaying non-critical requests or jobs, we will free up some capacity. This approach is part of Meta’s Unified Site Degradation (USD), program to build a portfolio of solutions to degrade the service gracefully or non-gracefully to reclaim capacity when the amount of traffic exceeds our ability to serve it. USD’s goal is to control demand during MRDR events, and its portfolio complements the DR physical buffer.
We have multiple techniques to degrade our infrastructure:
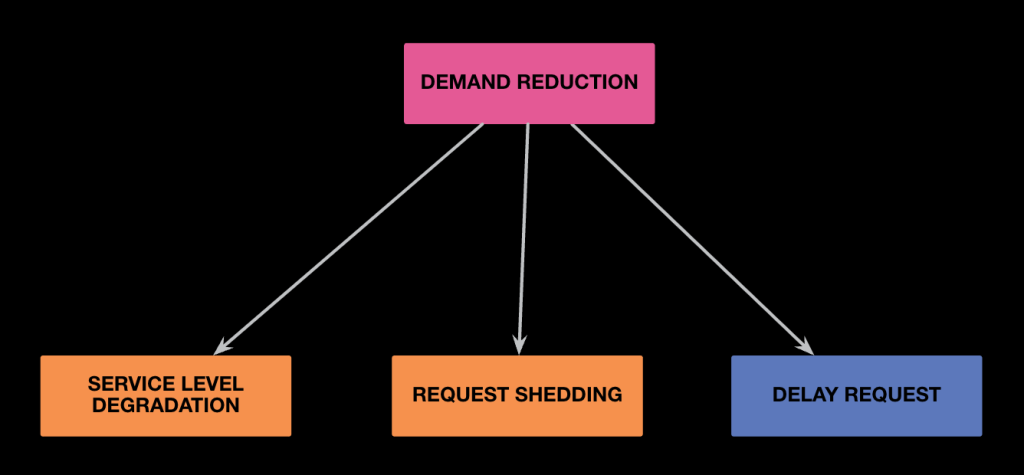
- Service-level degradation: By turning off non-critical features to reclaim some capacity, we instantly boost core functionality such as Defcon.
- Request shedding solutions: As a last line of defense, we drop traffic coming to our infrastructure to prevent meltdown if things are going south during disasters or we experience capacity-crunch events.
- Delay request: We delay executing non-critical jobs or requests when we are running out of capacity during disasters.
For a deep dive into Meta’s service degradation at scale, please refer to this 2022 Reliability @Scale presentation. Now, let’s explore the USD program’s validation strategy. Validation is critically important to any disaster response tool to ensure it is ready for use when needed. We rely on two validation techniques to evaluate our infrastructure readiness for handling MRDR events:
- Validation through testing: We conduct production tests to measure the capacity savings from each degradation technique. In addition, we execute failure-based tests tailored for particular failure scenarios. For example, we do MRDR tests where we disconnect two regions while providing degradation support to validate the end-to-end solution.
- Testing in production: This is vital but comes with a cost, especially when site degradation is involved. To minimize the impact on users and gain critical information while running fewer tests, we invested in auditing to extrapolate from the signals we are getting from small-scale tests to determine the MRDR infrastructure readiness.
Key Insights
Let us summarize what we have learned above.
- The map is not the territory: This relates to the mental model where the territory under consideration cannot be completely reduced to a static map. This is vitally important with Disaster Readiness, where risks and contexts are constantly changing, and adaptability is key. Hence, be prepared to pivot fast when a new, untested risk arises.
- Exercise the entire data center DR lifecycle AT SCALE: Make sure to rigorously test your data centers (and fault domains in general) through a complete DR lifecycle. Only by exercising and recovering successfully at scale can sufficient confidence toward large-scale risks be achieved.
- Degradation is a critical DR strategy: Degradation helps in DR failure scenarios as a complementary solution to prevent site overload. Don’t be afraid to degrade the entire infrastructure during disasters, especially given the attendant state of supply-chain and capacity-crunch problems.
- Auditing is key for E2E infrastructure validation: Although testing service degradation in production is critical to gain confidence for handling emergency situations, auditing is equally important to extrapolate the signals and help determine MRDR readiness for the entire infrastructure.
Future Work
What lies ahead for the DR team in this space?
Prepare for Instantaneous Failure Modes
We have focused above on situations where a region is shut down through Power Storm and a buffer of a few hours is available. That availability may not always be possible, so we also need to be prepared for instantaneous regional loss. The window of response in these cases can be in the order of just a few minutes. Hence, the critical-state transfer needs to be even more highly prioritized. This comes with tradeoffs of its own and requires a greater emphasis on handling shutdown and recovery autonomously.
Continuous E2E MRDR Validation
We are iterating on our validation strategy through testing and auditing to measure and track the MRDR overload readiness for the entire infrastructure. We will keep working on that strategy to make sure our infrastructure is resilient to such failures and to minimize the impact on users and business as much as possible.
Credits
None of this work would have been possible without the concerted efforts of the entire Fault Tolerance team and our indispensable partners from Reliability Infra, Infra Data Center (IDC), Core Systems, and Core Data.

