EVENT AGENDA
Event times below are displayed in PT.
RTC @Scale is a conference for engineers who develop and manage large-scale real-time communication (RTC) systems. The operation of large-scale RTC systems has always involved complex engineering challenges and has attracted much attention in recent months given the explosive growth of RTC in these unprecedented times. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The conference will be hosted virtually with speakers and attendees from major RTC players including Meta, Google, Microsoft, Dolby, Cisco, Clubhouse, and Visionular. The event will feature talks and panel discussions themed around audio, video and transport technologies for RTC, applications of machine learning for RTC, metrics, quality evaluation, resilience and encryption.
Event times below are displayed in PT.
Session 1: Future RTC Experiences
Session 2: Audio ML
Session 3: Video
Session 4: Resilience and Encryption
Session 1: Future RTC Experiences
During COVID, the importance of video calling grew as people were stuck and separated from their family and friends. But the 2D experience falls short of making you feel present in the same space together. Moving to a 3D calling experience (e.g. holographic calling) can help people feel closer and more immersed. People are familiar with the concept of holographic video calling from sci-fi movies, and there have been some demos by different companies using highly specialized equipment. But what would it take to make it a reality, enabling this technology for the masses, and making it so that people can use it as easily as 2D calls? The answer to this question spans multiple domains, both on hardware and software, from computer vision and machine learning to compression and real-time transport. In this talk, I will focus on some of the technical challenges this brings for video and real time communication.

Talking with a group of friends face-to-face can be very engaging, with fast-paced turn-taking and overlapping conversations. You can even have such a conversation in a noisy restaurant in the presence of background voices and noises. However, talking with a group of friends online is much more stilted; if people talk over the top of each other, it quickly becomes unintelligible - it is a much less engaging experience. We will present Dolby's experience building large-scale spatial voice communications services for virtual environments for millions of users. We will introduce psychoacoustic literature that talks about how spatial improves voice intelligibility. We then discuss our experiences replicating crowded communication scenes in a virtual world while maintaining intelligibility.

The real-time communications industry has evolved rapidly since the release of Skype in 2003, and saw unprecedented growth during the COVID-19 pandemic. This talk will look at the trends of the last 20 years and explore where the RTC ecosystem may be heading.

Microsoft Teams and Skype are used daily by hundreds of millions of users, and their usage has increased significantly since the COVID-19 pandemic and is a critical tool for working remotely and communicating with friends and family. In this talk we describe how we are replacing traditional digital signal processing components with machine learning based models. One recent new feature in Microsoft Teams and Skype for removing annoying background noise in telecommunication calls, which is the third most common call quality issue users complain about. We used deep learning to create a noise suppressor that performs >7X better than the previous non-machine learning solution. It’s a great feature, but how we developed it is even more interesting. Starting just under two years before shipping the feature, we first created three open source datasets and test sets for Deep Noise Suppression (DNS), as well as a best-in-class open source subjective test framework. We held two international challenges for DNS at INTERSPEECH 2020 and ICASSP 2021. Using the challenge results and our own models, we created the first background noise objective function that is highly correlated to human perception (PCC=0.97). This allowed us to iterate fast in model training and evaluation, and enabled us to create best in class DNS models. This type of open development model is new at Microsoft, and we are successfully applying it to another speech enhancement components like acoustic echo cancellation and packet loss concealment.

AI and deep learning has radically advanced many speech and audio processing applications. For example, we have all experienced improvements in speech recognition and synthesis in conversational systems on our phones. Recently deep learning has also revamped the quality of data compression of speech. In this talk we will discuss properties of some of these new architectures, and how they can be utilized to build a practical system for RTC.

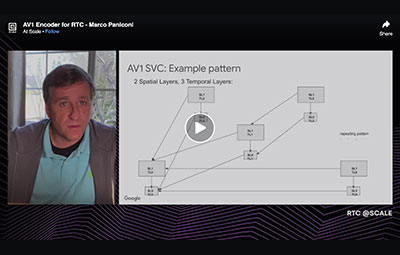
In this presentation we discuss the various features and techniques that make libaom AV1 encoder suitable for RTC applications: from encoding tool selection to reducing complexity of the existing encoding tools. By implementing this approach libaom AV1 encoder is now able to provide low-latency real-time video encoding in RTC applications.

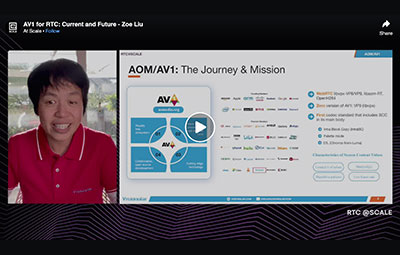
In this talk, we will mainly focus on the state-of-the-art AV1 software encoding capability for its deployment in RTC use cases, taking our Aurora1 AV1 as an instantiation. RTC in essence requests a sufficiently fast encoder with limited computational resource requested, so that it can be deployed in a wide range of client devices with minimum delay incurred. Meanwhile, the encoder should also collaborate closely with the network layer to handle varying and various networking conditions. AV1 as a codec standard provides several intrinsic critical features, making it a better fit for the RTC scenario. For instance, for the first time AV1 includes the Screen Content Coding (SCC) tools, such as IntraBC, palette, etc., in its main standard body, ideal for the coding of screen content that is widely present in such RTC use cases as video conferencing, distance learning, and remote desktop sharing. Taking our Aurora1 AV1 encoder as an example, we will first demonstrate AV1 is quite ready and has already been deployed for RTC. For SCC, for instance, Aurora1 is able to conduct a steady 1080p real-time encoding in zero latency at speed of 15fps, using one single CPU core on a PC platform, consuming just a quarter or even less of the bitrate consumed by x264 superfast whereas providing a superior visual quality. Aurora1 can also encode 720p30 camera content real time and steadily over recent generations of mobile platforms, e.g. iPhone12, with a significant coding efficiency advantage as opposed to existing codec standards. We will present such advantages of AV1 for RTC with extensive, detailed stats data, comparing Aurora1 against widely acknowledged open source encoders, including OpenH264, x264, libvpx-VP8/VP9, SVT-AV1, and liabom RT (libaom real-time mode). We will also introduce AV1's scalability support, as well as its natural integration with WebRTC across various PC and mobile platforms, optimized for both x86/ARM architectures. We will illustrate different speed presets provided by Aurora1 and confirm that more aggressively faster speed levels are being developed. We will also describe the role that is being played by dav1d, an open source AV1 decoder led by the joint efforts of VideoLAN and FFmpeg, funded by AOM, together with the ecosystem of AV1 that is being gradually formed.

The users of Meta RTC products experience a very diverse set of network conditions, some of those may be far from perfect. In this presentation, we are going to cover the following discussions: (1) the challenges we faced to deliver smooth real-time audio over lossy network conditions; (2) the error resiliency technologies we explored to recover audio packet losses; (3) the delicate trade-offs between audio packet loss recovery and end-to-end latency; (4) future directions to improve user perceptive audio quality with packet loss.

WhatsApp’s mission is to connect the world privately by designing a product that's simple and private. Privacy and security is in our DNA. In this presentation, we are going to talk about how we build the private calling for billions of users by leveraging client centric architecture and E2EE. We'll start from discussing the protection levels of user privacy, and our basic E2EE and architecture for 1:1 call and the challenges and benefits for privacy in a client centric E2EE design. Then we will talk about how we evolve our E2EE and architecture for group call and multi-device for scalability.

Meta helps billions of users connect daily by providing real time communication services. Group call is one of these services were more than two users can join a call. A common way of supporting group calls is by leveraging Selective Forwarding Unit (SFU) server to route the media among the participants. In an e2e encrypted call, the server forwards the media without having the capability to decrypt them. In this talk we will discuss the methods to encrypt the media communicated among the participants and the encryption key negotiation mechanism. We will also discuss how to keep the call secrecy under various scenarios such as participants joining or leaving the call. As the call size grows (more participants in a call), there are increasing number of the challenges to keep the e2e encryption and the call secrecy under different scenarios. We will discuss these challenges and ways to solve them.

Maher Saba is the VP of Remote Presence on Messenger and is responsible for... read more

Nitin Garg has been at Meta since 2014 and has spent most of his... read more


Paul is VP of product for Dolby's developer platform, Dolby.io, and is passionate about... read more

Justin is currently the Head of Streaming Technology at Clubhouse. Previously at Google, he... read more

Ross Cutler is a Distinguished Engineer at Microsoft where he manages a team of... read more

Jan Skoglund leads a team at Google in San Francisco, CA, developing speech and... read more

Mike is Meta’s product lead for the cloud platform supporting Horizon and Facebook Gaming.... read more

Cullen Jennings is CTO of Security and Collaboration Products at Cisco. He is the... read more

Marco Paniconi has been at Google since 2011, working on video codecs for live... read more

Zoe is the Co-Founder of Visionular, a tech startup with its HQ based in... read more

Andy Yang is a tech lead manager in Remote Presence team at Meta. He... read more

Xi Deng joined WhatsApp of Meta as a Software Engineer in 2017. His main... read more

Abo-Talib Mahfoodh is a software engineer who is passionate to help billions feel safe... read more