EVENT AGENDA
Event times below are displayed in PT.
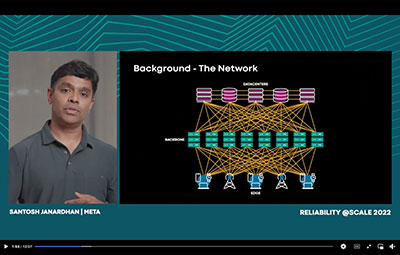
Reliability @Scale is a technical conference for engineers who are passionate about building and understanding highly resilient and reliable systems at massive scale. Whether it’s novel design decisions, or outages that impact billions of people, providing reliable experiences for Systems at this scale present unique technical challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
Reliability @Scale will be hosted virtually. Joining us are speakers from Akamai, Cloudflare, Fastly, Google, Meta, and Roblox. The event will be hosted on August 31, 2022 with talks themed around large-scale outages, incident response and learnings, and measuring reliability at scale.
Event times below are displayed in PT.
In this talk, VP of Engineering Max Ross will discuss the 73 hour outage that impacted Roblox late last year. He will also share some of the ways that a multi-day outage can turn conventional reliability wisdom on its head.

A crash bug in QUIC handshake code exposed a new class of bugs we termed ‘contagion bugs’. For these bugs, a tiny number of tasks can cause a huge outage and rollbacks don’t work as expected. This talk details what contagion bugs are, discusses the details of the outage, and what we did to prevent and mitigate them going forward.

This talk will provide a technical overview of a service incident on the Akamai platform in July 2021 which, despite layers of safety technologies, nevertheless impacted some of Akamai’s customers. In addition to exploring the technical underpinnings of the incident, there will be discussion of lessons learned and actions taken to broadly reduce the risk of recurrence.

In this talk, we share some lessons from several of our long-running investigations. Some of them are well-known, but are worth repeating, and some of them are things we learned and want to share.


Learn about culture of tracking Service Level Indicators/Service Level Objectives at Instagram specifically and Meta in general, the tools that we use and how teams' SLI/SLO workflows can be improved by annotating SLO violations and analysing them later. In the talk we will briefly cover history of SLI/SLO tracking at Meta, then talk about how Instagram team used data annotations to tackle some of the reliability issues they had and how we're expanding this approach to the whole company.


We will talk about what factors made us realize that service degradation is necessary for our infrastructure and the challenges we faced while implementing service degradation at scale. We will also speak about how we are changing our Fault Tolerance Strategy to use service degradation instead of provisioning extra buffer.


Shrinking Production Incidents details an organized approach for reducing the overall impact of production outages.
Attendees can expect to learn how to prioritize reliability-related engineering tasks based on incident postmortem data, focusing on tasks that:

Thousands of services at Meta use Configuration Management, so it is important we change that configuration reliably. Tune in for a story spanning several years, covering how we exponentially grew coverage of a protection mechanism for one our most critical developer workflows. Along the way, we'll dive into some specifics of challenges we faced and overcame to reliably change configuration at scale.

Would you believe us if we said the more SEVs we have, the more reliable we are? In this talk we'll talk about the reasons why we love SEVs at Meta, and how our culture around SEVs has allowed us to build reliable services at scale. We'll start by exploring research from other industries about how incident culture shapes how reliable they are. We'll then share how we've applied these lessons to our own culture. Along the way we'll give a peek at our SEV tool, some insight into our SEV review process, and describe how we encourage a "culture of SEVs" from the very first day an engineer arrives at Meta.


Santosh Janardhan is the head of infrastructure at Meta, where he supports the teams... read more

As Vice President of Engineering, Max Ross leads the development and operation of the... read more


Ian Swett is the Manager of Google Cloud Networking's Protocols and Web Performance teams.... read more

James Kretchmar is Vice President and CTO of Akamai's Edge Technology Group, responsible for... read more

Jana Iyengar is the Product Lead for Infrastructure Services at Fastly, where he is... read more

Hossein is VP of Engineering at Fastly, where he leads Network Systems, an organization... read more

Prasad Kalyanaraman has been with Amazon for over 17 years. He leads the AWS... read more

Jeremy Hartman is currently serving as Senior Vice President of Production Engineering at Cloudflare.... read more

Anca is a seasoned software engineer with over 11 years of experience at Meta,... read more

I enjoy working on everything web-related. Have been doing that since 2008, still have... read more

Keshav is a Production Engineer at Instagram and is passionate about building reliable infrastructure.... read more

Thote Gowda has been working with Meta for close to 4 years. He has... read more

With DevOps and System Admin background, Yi Yu joined the Disaster Recovery team at... read more

Yuri Grinshteyn strongly believes that reliability is a key feature of any service and... read more

I'm Avery, a Production Engineer on the Configuration Management team at Meta. I've been... read more

Joe is currently a production engineer on Meta’s Reliability Engineering initiative. Over the last... read more

Nick joined Meta in 2018 as a Production Engineering manager. He is responsible for... read more



@Scale engineers pencil blogs, articles, and academic papers to further inform and inspire the engineering community.