EVENT AGENDA
Event times below are displayed in PT.
Machine Learning @Scale is an invitation-only technical conference for data scientists, engineers and researchers working on large-scale applied machine learning solutions. ML is critical to a broader range of systems than ever before: from augmented reality to language technology and everything in between. Today’s ML practitioners face daunting scale challenges since their systems and services may be used by millions if not billions of customers. Join ML experts from Bloomberg, Clarifai, Facebook, Google, Instagram, LinkedIn and ZocDoc to openly discuss these challenges and collaborate on the development of new solutions.
Event times below are displayed in PT.
The majority of the experiences and interactions people have on Facebook today are made possible with AI. Well over 1 billion people enjoy unique, personalized experiences on Facebook that are powered by a wealth of AI and machine learning algorithms. AI is an incredibly fast-moving field: engineers and researchers across the company are turning the latest research breakthroughs into tools, platforms, and infrastructure that make it possible for anyone at Facebook to use AI in the experiences and products they build. This talk will look at how Facebook is conducting and applying industry-leading research to help drive advancements in AI disciplines like computer vision, language understanding, speech and video. We will also talk about building an infrastructure that anyone at Facebook can use to easily reuse algorithms in different products, scale to run thousands of simultaneous custom experiments, and give concrete examples of how employees across the company are able to leverage these platforms to build new AI products and services.

Providing effective search for the financial markets has significant challenges: the data is diverse, usage is sparse, accuracy and speed are important, and ground truth is hard to come by. While the data sets are not web-scale, they are too big and complex to be effectively solved via conventional enterprise search. At Bloomberg, we addressed these challenges by working to improve an existing open source software suite -- Solr. In this talk, I will go through the changes we made to improve Solr's scalability, the ways we augmented it with state-of-the-art machine learning, and how this lead to our successful search infrastructure.

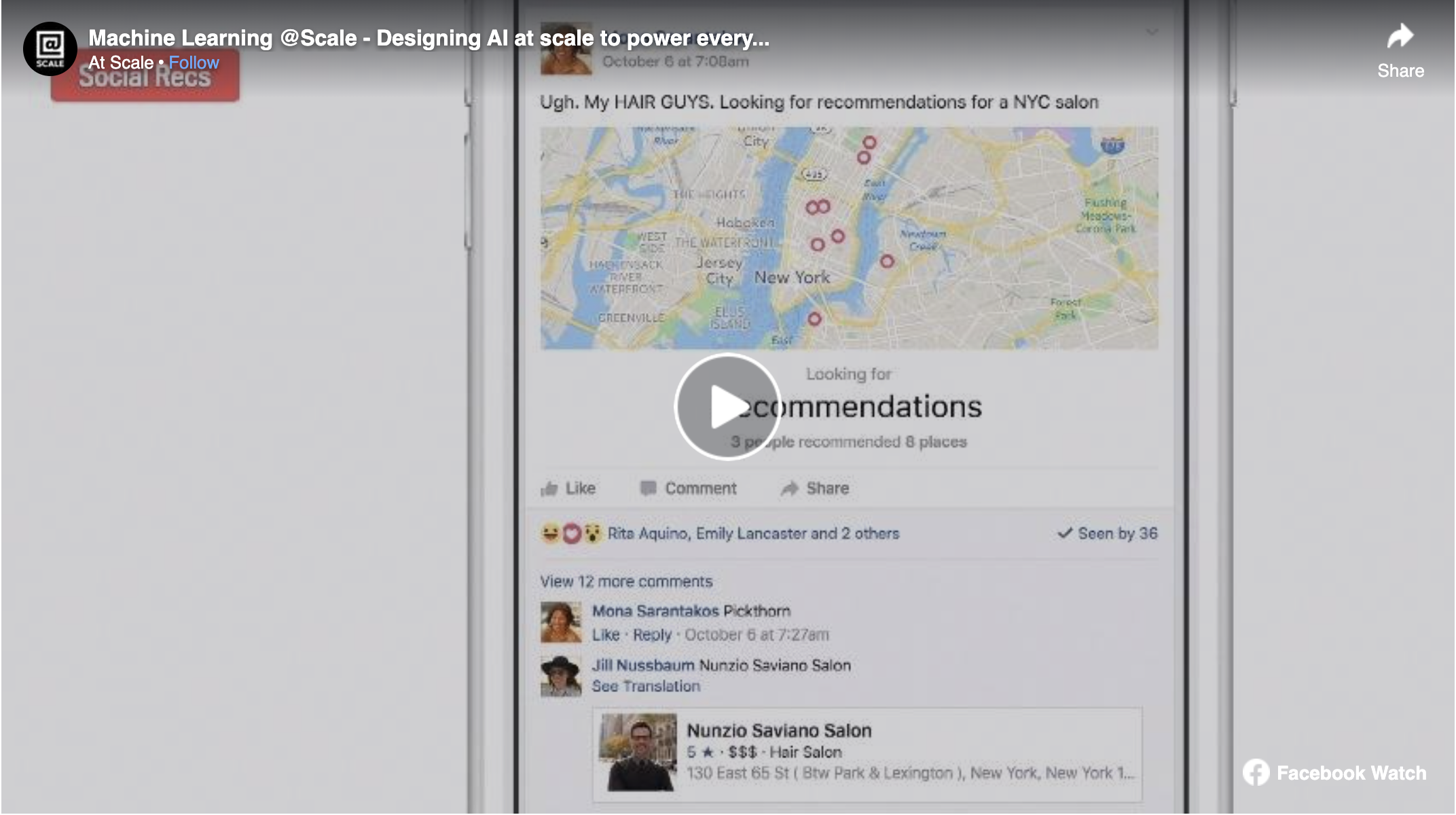
LinkedIn members care about the contents (e.g. papers and patents) they created that reflect their professional credentials, but it is often cumbersome to add them to profiles manually. In this talk we will present a recent project in which such contents are crawled from the web and authors or inventors are matched to LinkedIn members automatically. The matched contents are sent to LinkedIn members as a notification on LinkedIn's mobile platform which provides recipients with an opportunity to add a content piece with ease.

Matthew Zeiler is an artificial intelligence expert with a Ph.D. in machine learning from NYU. His groundbreaking research in visual recognition, alongside renowned machine learning pioneers Geoff Hinton and Yann LeCun, has propelled the image recognition industry from theory to real-world practice. As the founder of Clarifai, Matt is applying his award-winning research to create the best visual recognition solutions for businesses and developers and power the next generation of intelligent apps.

In this talk I will describe the challenges of learning in repeated auctions for revenue maximization. While the problem is similar to standard regression, the loss function associated with revenue maximization presents several challenges. Most notably it's stark discontinuity. I will dig into the details of how to provide learning guarantees for this problem. I will then present algorithms to optimize the empirical revenue and again describe the challenges that the discontinuity of the loss impose in this optimization problem.

Users of Instagram are both the audience and producers of content. Because audiences are able to interact with photos, we see so-called "network effects", where A/B tests targeted towards audiences unintentionally affect content producers. In this talk, we'll use the launch of Instagram's feed ranking as a working example to talk through issues in quantifying network effects. Along the way, we will explore unusual A/B testing techniques such as country-level tests, testing on balanced graph partitions and author-side experiments.

A deep dive into a system capable of interpreting location signals coming from mobile devices @scale. This case study exposes challenges we faced designing and productionizing a system that understands people's spatio-temporal movements in a physical world and powers a series of location-aware products at Facebook. The journey takes us from client-side signal collection, through server-side inference layers, to data quality and measurement challenges. Many components of this modular system rely on accurate ML models. Complexity of dependencies, implicit assumptions and biases, lack of quality training data, and the real-time nature of the system are some of the aspects that make the problem even more challenging but also more interesting.


To direct users to booking with the right medical specialties, how can search queries from users be mapped into specialties? At Zocdoc, we use machine learning to solve that problem -- both for selecting results returned and for the ranking of the results.