EVENT AGENDA
Event times below are displayed in PT.
Data @Scale is an invitation-only technical conference for engineers working on large-scale storage systems and analytics. Building services that serve millions or even billions of people presents a set of complex, and often unprecedented, engineering challenges. The @Scale community is focused on bringing people together to openly discuss these challenges and collaborate on the development of new solutions.
For 2017, we’ll also be looking at how Big Data is transforming machine learning, even as new machine learning techniques are leading to an evolution in infrastructure, hardware engineering and data center design.
Join experts from Facebook, Google, LinkedIn, Microsoft, Pinterest, Uber and Yandex to openly discuss these challenges and collaborate on the development of new solutions.
Event times below are displayed in PT.




This talk will address recent insights in distributed systems design for training machine learning models at scale.

Developing applications is hard, developing globally-distributed applications with data at planet-scale that are fast, scalable, elastic, always available and yet simple - is even harder. Yet it is a fundamental pre-requisite in reaching people globally in our modern world. In this talk, I will describe the next generation of globally- distributed databases at Microsoft that can run on millions of nodes across hundreds of data centers, handling up to trillions of data objects, 24/7 – all backed by industry-leading comprehensive SLAs.

This session walks through the development of ClickHouse, and how an iterative approach to data storage organization resulted in a system that: can ingest clickstream data in realtime, generate interactive reports on non-aggregated data, process 100 billion rows per second on HDDs, scales linearly, supports the SQL language dialect and is open source.

This talk will cover the evolution of storage and serving at scale as Pinterest grows. We started with a Python Django application with Memcached on un-sharded MySQL. We had to have MySQL sharded and introduce Twemproxy (Memcached Proxy from Twitter) into our stack to make both persistent storage and caching horizontally scalable to enable future growth of Pinterest. As we scale the organization, we introduced graph store as a service (Zen) and KV store as a service (UMS) to boost developer velocity to enable rapid product innovations. As the journey goes on, to make Pinterest even more relevant, even more real-time, the team takes on the journey to build a machine learning serving platform with C++, Folly, FB Thrift and RocksDB to address new challenges on how to efficiently serve feeds with complicated machine learned ranking models, huge number of features scattered across many data sets with very low latency to deliver delightful experiences.

Cadence is an open source solution for building and running microservices that expose asynchronous, long-running operations a scalable and resilient way. It borrows a lot of ideas from AWS Simple Workflow service. It is written in Go and relies on Cassandra for storage.

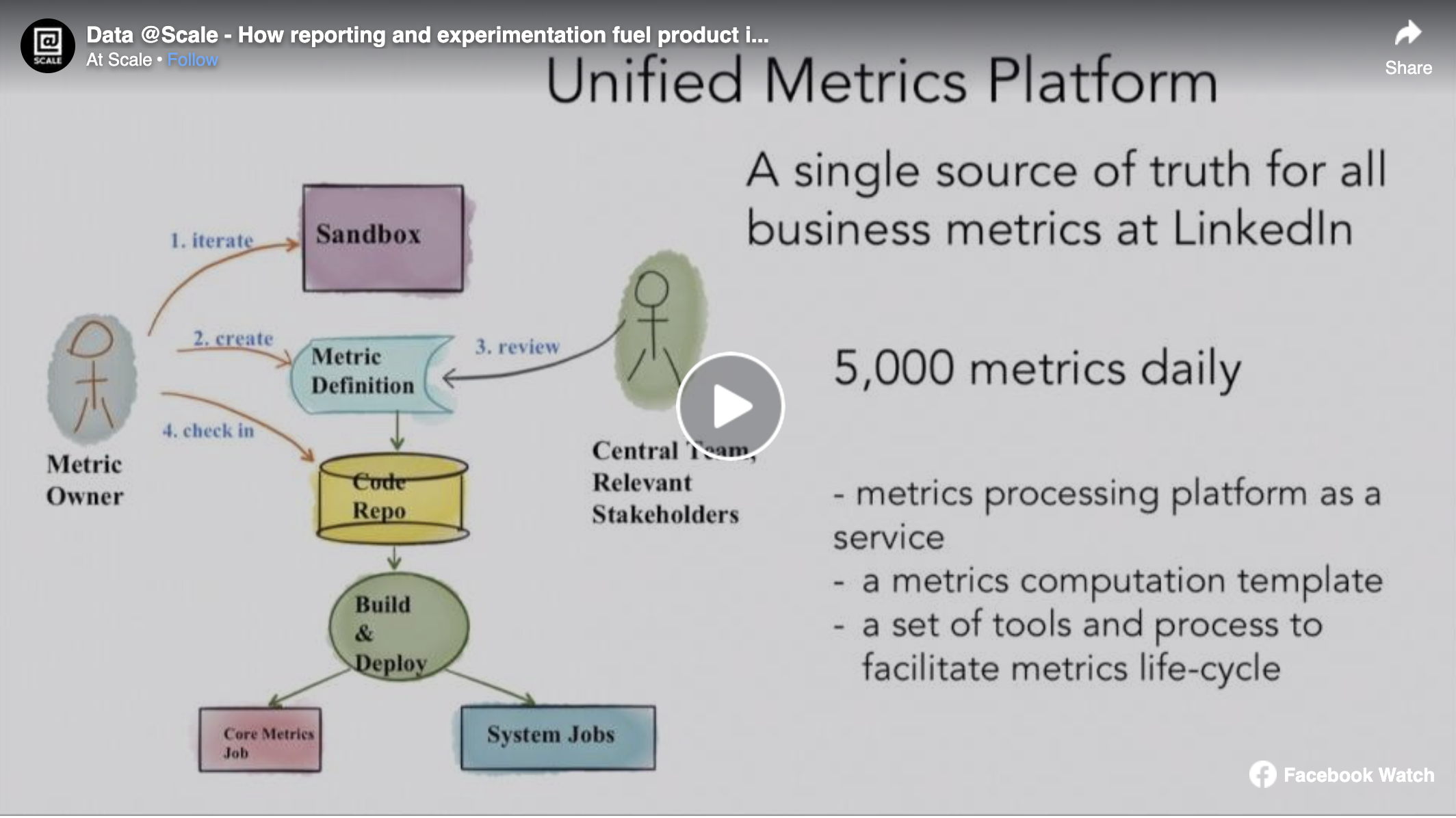
LinkedIn is a deeply data driven organization where metrics measurement and experimentation plays a crucial role in every product decision. In response to our experience at LinkedIn, we built UMP and XLNT, platforms for metrics computation and experimentation, respectively. Over the last few years, these platforms have allowed us to perform measurement and experimentation very efficiently at scale, while preserving trust in data.

Spanner is a globally-distributed data management system that backs hundreds of mission-critical services at Google. Spanner is built on ideas from both the systems and database communities. Initially, Spanner focused on the systems aspects such as scalability, automatic sharding, fault tolerance, consistent replication, external consistency, and wide-area distribution. More recently, we have been working on turning Spanner into a SQL DBMS. In this talk, we describe distributed query execution in the presence of resharding, query restarts upon transient failures, range extraction that drives query routing and index seeks, and the improved blockwise-columnar storage format. We touch upon migrating Spanner to the common SQL dialect shared with other systems at Google. The talk is based on a paper published at SIGMOD'17.

The incipient end of Moore’s Law will drive a paradigm shift in our systems and architectures. Ever increasing computational needs, driven in part by big data and machine learning, will force our systems to become more heterogeneous. We must change how we think about large-scale systems, with new stacks and new interfaces. I will describe some of Microsoft’s efforts along these lines, one of which is large-scale deployments of programmable hardware in our cloud, including both the hardware and the resource management interfaces.

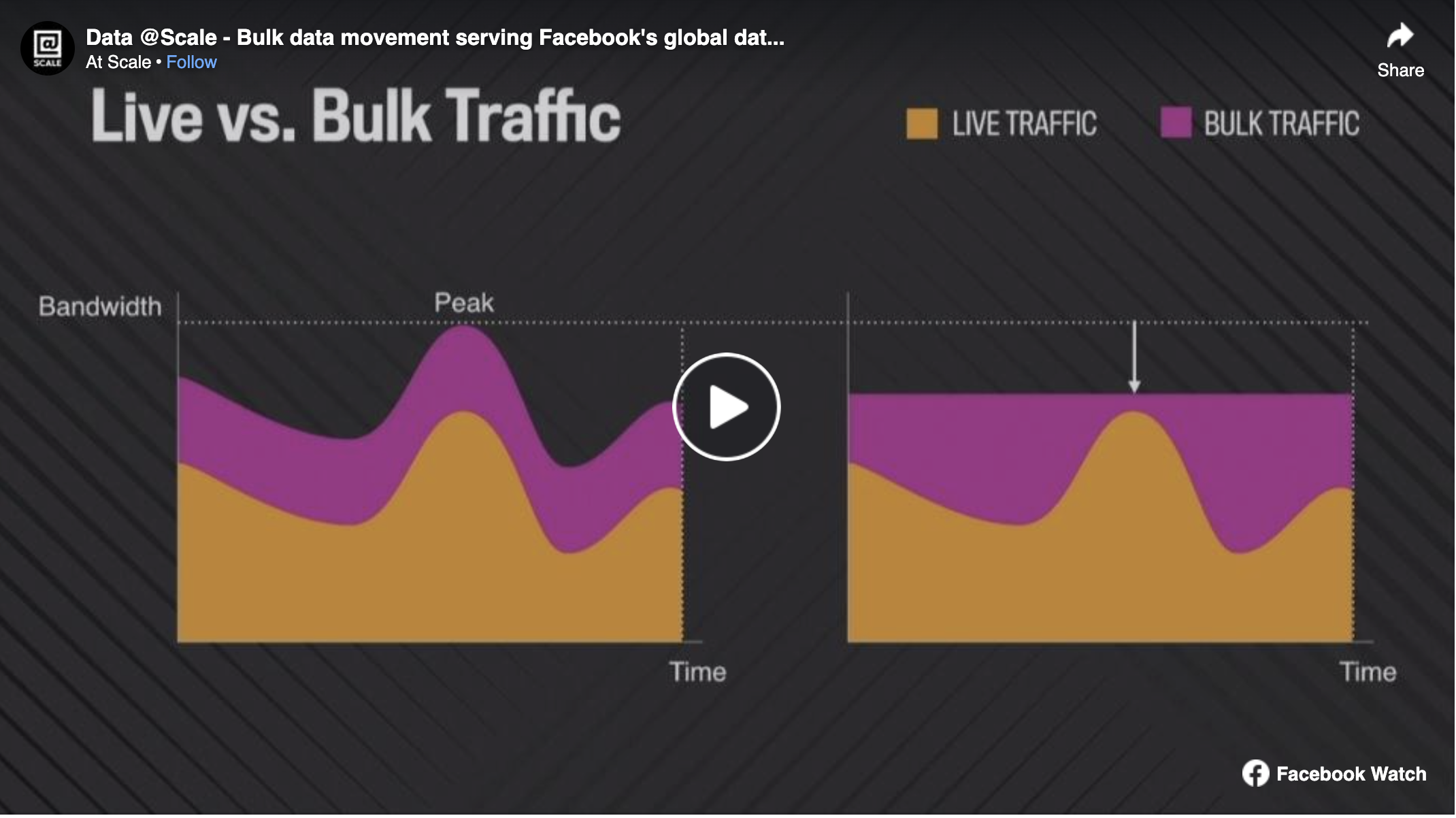
Facebook uses diverse storage systems and compute tools spread across data centers worldwide, together forming a global system for data storage and processing. A bulk data movement service that "just works" helps this global system. Bulk data movement supports use cases such as commissioning / decommissioning, rebalancing, disaster readiness, replication for local availability, and secure backups. While serving these needs, the system must be a "good citizen" to storage systems and the global network. This talk describes Facebook's system for bulk data movement across storage systems worldwide.



Kim Hazelwood is an engineering leader whose expertise lies at the intersection of artificial... read more