EVENT AGENDA
Event times below are displayed in PT.
This year’s event featured technical deep dives from engineers at Airbnb, Amazon, Databricks, Dropbox, Facebook, Flipkart, GE, GitHub, Google, Instagram, LinkedIn, Netflix, NVIDIA, Oculus, PayPal, Pinterest, Slack, Spotify, Uber, YouTube and more. This year there were four tracks: Data, Dev Tools & Ops, Mobile, and Hot Topics (think machine learning and video). The full conference lineup is below.
Event times below are displayed in PT.
Jay Parikh, head of Engineering and Infrastructure at Facebook will kick off the event with a welcome keynote.

Himagiri (Hima) Mukkamala is in charge of building the platform that connects software and sensors to machines and the machines to the cloud, collecting as much as 50 million data variables from 10 million sensors. It's an open, global network that connects people, data and machines. In his keynote, Mukkamala will discuss how GE has approached their scale technical challenges and how the scale and industrial communities have a lot they can learn from each other as scale companies begin to create their own marriages of software and machines.

When creating graphics in the browser, there’s no consensus on what language or API should be used. From markup languages like SVG to OpenGL based APIs like WebGL, the browser provides several different ways for creating visualizations. Through some examples at Uber of both explanatory and high data-dense exploratory visualizations, the talk will cover the available standards, libraries, and the open source stack Uber developed that is used for visual analytics, mapping, and public-facing data visualizations, ranging from SVG and D3 to WebGL and beyond.

No matter how smart you are, your app will crash. At Square, our customers trust us to move money, so we take crashes very seriously. This talk presents our systematic approach to ensuring crashes are rare.

Since the split from eBay in 2015 PayPal has turbo charged DevOps. A key example of this in action is adopting Docker as containerization technology to enhance our developer experience, reduce drift in different environments like test and production and to bring higher efficiency of resource utilization in our data centers. This session will discuss PayPal's journey to docker-ize 2,500 apps and hundreds of thousands of container instances.

Today there are dozens of devices for capturing 360 video, from professional rigs to consumer handheld cameras — all with different specs and quality outputs. As 360 cameras become more prevalent, the range and volume of 360 content are also expanding, with people shooting 360 video in a widening variety of situations and environments. At Facebook we want to ensure a high-quality, consistent viewing experience regardless of the capture device or conditions. This talk will present a new optimization we’ve developed to improve one aspect of 360 video viewing quality across Facebook and the Oculus platform, while preserving (and even improving) upload/playback speed and efficiency.

The year is 1993, and Phil Katz releases its hugely successful compression algorithm, deflate, commonly known as Zip. Thanks to openness and efficiency, served by an excellent industry-grade reference implementation, it is deployed and used within almost every system nowadays. Few pieces of code can claim such longevity, even with trade-off rightly designed for its era. This year is 2016, and the computing world has changed quite dramatically in the past two decades. Could these changes be taken in consideration to create a new, and unconditionally better, algorithm?

In the mobile world, developers aspire to get new features out to people as fast as possible. But how do you speed up your development cycle and drastically cut down on stabilization time without sacrificing quality? In this talk, the speaker will explore how Facebook moved its mobile app releases from monthly to weekly, from implementing high-level principles to building and automating tools that ensure quality at every step of the process.

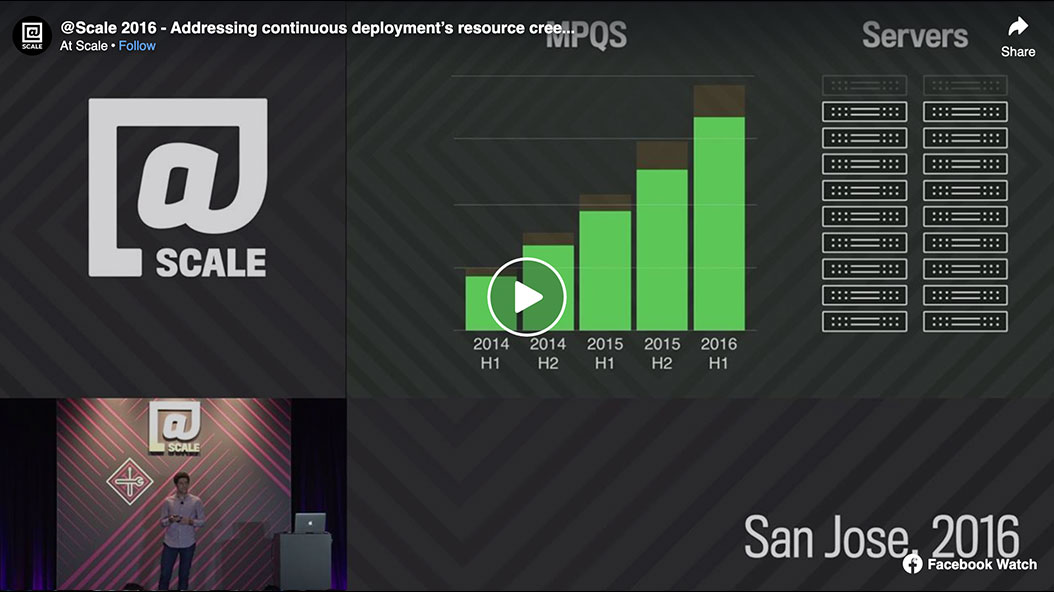
Resource creep is one disadvantage of continuous deployment. Small changes, on average, have smaller incremental resource demands (CPU, memory, network, disk IOPS, etc.). The additional resource demands may seem reasonable or inconsequential when viewed in isolation. However, over time they add up. This causes increased demands on computing infrastructure that may not be dealt with until it becomes a problem, which typically means significantly after software has been released. Some of the additional resources needed are legitimate — in support of the product enhancements — but others are inefficiencies that need be optimized. This talk will describe Facebook’s approach to dealing with resource creep at scale. Facebook employs two philosophies: 1) in order to keep product developers as productive as possible, resource creep is handled by a separate team, entirely focused on the problem; and 2) Facebook scales its engineering through tools and automation rather than by adding people. Facebook will describe the tools and approaches that are used to identify and correct resource creep for the company's PHP developers with regressions on the online data storage and access infrastructure.

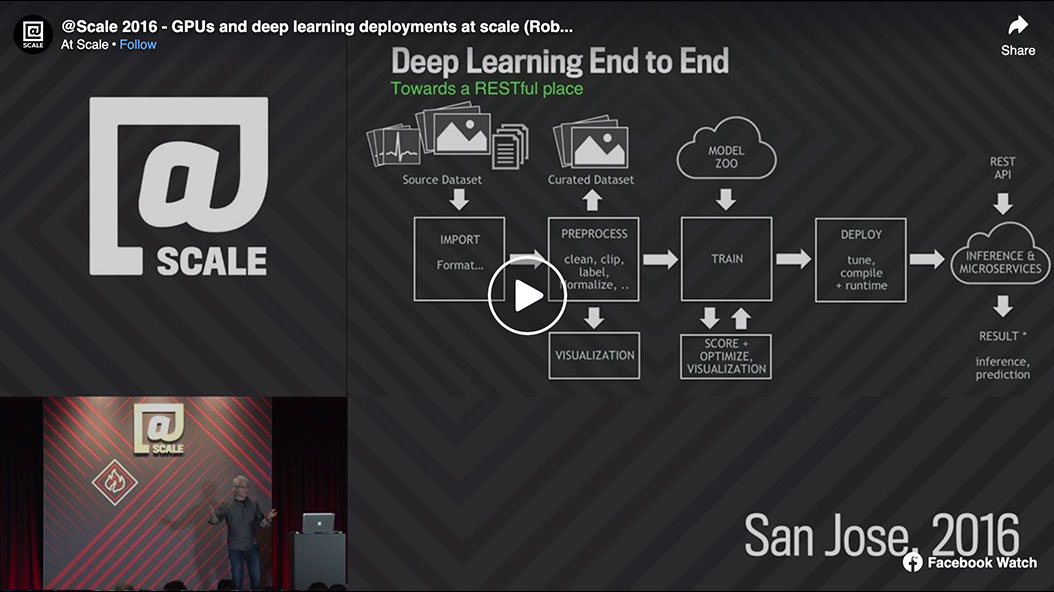
GPUs are already important compute engines in the HPC top 500, but GPU evolution has also made them a great fit for scale workloads like deep learning and inference. Recent increasing complexity of neural nets has created an exponential computation demand, requiring the use of GPUs for real time and high throughput inference / prediction, not just training. We’ll talk about GPU architectural evolution, changing neural net computation demands, and development flow from training to inference deployment as a utility in the datacenter. We’ll also cover data from large scale GPU deployments, and platform evolution for utility use, where predicting ExaFlop/s (that’s 10^18) capability is no longer a crazy number.

In contrast to previous big data systems, Apache Spark was designed to offer a unified engine across diverse workloads, such as SQL, streaming, and batch analytics. While this approach may seem counterintuitive, it has some key benefits — most important, applications can combine workloads in ways that are not possible with specialized engines, and users benefit from a uniform management environment. The talk will cover how having a unified engine enabled new types of applications based on Spark (such as interactive queries over streams), and how Databricks designed Spark's APIs to enable efficient composition. It will also sketch the newest unified API in Spark, Structured Streaming, which lets the engine run batch SQL or DataFrame computations incrementally over a stream of data.

Quip is available across eight platforms, all of which share a single HTML5/JavaScript editor. This talk will go over the architecture behind Quip's editor, its evolution as the company adopted React, and how it connects to its native iOS framework.

Decisions Netflix made early on facilitated later choices. In this talk, we will discuss how decisions have built upon one another and led to a highly resilient service. But the architecture isn't perfect. We'll talk about some of the complexities and future work that may ultimately simplify and streamline dependencies.

React and FLUX are groundbreaking technologies and approaches that have taken the web development world by storm. The Oculus Home team has taken the lessons and philosophies learned by these technologies and have applied them to building impactful UI in VR. The team was able to build a fast, stable, disciplined and scalable VR product from the ground up and will share their approaches in doing so.
Take a break to meet with speakers for Q&A from the previous track sessions. Office hours will occur just outside the presentation rooms in designated areas. Follow the signs to meet with: Data Track Speakers: Shan He at Uber, Yann Collet at Facebook, and Matei Zaharia at Databricks. Mobile Track Speakers: Scott Goodson at Pinterest, Anne Ruggirello at Facebook, and Yunjie Ma at Quip. Dev Tools/Ops Track Speakers: Jigar Desai at PayPal, Adrian Zgorzalek at Facebook, and Dianne Marsh at Netflix. Hot Topics Track Speakers: Johannes Kopf at Facebook, Robert Ober at NVIDIA, and Khoi Nguyen at Oculus.
This talk will be a deep-dive into Amazon Aurora — a relational database service reimagined for the cloud. Amazon Aurora is a disruptive technology in the database space, bringing a new architectural model and distributed systems techniques to provide far higher performance, availability and durability than previously available using conventional techniques. Amazon will present an under-the-hood view of some of the key innovations behind Amazon Aurora, e.g., reduction in disk IO and network traffic, latch-free implementation of different key components (lock manager, query cache, etc.), and asynchronous processing, that have helped it achieve up to 5x higher throughput vs. MySQL, scale to thousands of user sessions, and handle up to 15 replicas with millisecond latencies. Amazon will also discuss how its log structured distributed storage architecture helps it archive near instantaneous crash recovery, zero-impact continuous backup, and point-in-time restore irrespective of the size of the database and the associated storage volume. Amazon will also share interesting use cases from thousands of customers who are running production workloads on Amazon Aurora.

GraphQL is a query language that is powering a lot of Facebook applications. Mobile developers at Facebook use GraphQL to describe the data they need to render their view. Server developers use GraphQL to expose the server's data model to mobile developers. This talk will cover what it takes to connect the two worlds together, including our code generation tools that create native classes used for representing GraphQL query responses. We'll also share some of the lessons and best practices that we learned the hard way.


Client-side rendering is gaining in popularity which presents new challenges for measuring and optimizing end-to-end performance on the web. BrowserLab provides a controlled, consistent environment for collecting timing metrics which is capable of detecting regressions as small as 20ms. This talk will cover techniques that we apply to handle highly dynamic content, isolate server variance from client-side performance, deal with non-deterministic code, and enable engineers to understand performance implications of their changes.

Facebook is powered by machine learning. From advertising relevance, news feed and search ranking to computer vision, face recognition, and speech recognition, Facebook runs ML models at massive scale, computing trillions of predictions every day. We'll talk about some of the tools and tricks we use for scaling both the training and deployment of some of our deep learning models at Facebook. We'll also cover some useful libraries that we've open-sourced for production-oriented deep learning applications.


Facebook created and open-sourced a next generation OLTP SQL database on modern Flash storage called MyRocks — a RocksDB storage engine for MySQL. Facebook has used MySQL (InnoDB) for many years, and InnoDB is a great general purpose database and in many cases is the best fit. Facebook wanted more space to write optimized databases that work more efficiently on Flash. There was room to write optimized NoSQL databases outside of MySQL ecosystem, but the company wanted to utilize existing MySQL assets like client programs relying on SQL and MySQL connectors, Replication, and administration tools. To meet these requirements, it created a new MySQL storage engine on top of RocksDB (http://rocksdb.org/) — MyRocks (https://github.com/facebook/mysql-5.6). In this session, the speaker will introduce MyRocks, its architecture, and how Facebook is using MyRocks now.

Developer-driven testing is a great way to scale quality control as your team grows and code churn rises. While most developers are sold on unit testing their code, they are often intimidated by UI testing. Is it worth the effort? Can the resulting tests be fast and stable enough to be executed continuously? In this session, Slack will share its thoughts on why it's worth having developers write UI tests for their features, as well as present practical information on how the Slack Android team approached this problem.

In the six years since it began, Uber’s business has definitely grown, and the same can be said for the size of its engineering team. Every week, Uber ships thousands of code changes to millions of users of its mobile apps. What began with one iOS engineer has grown to a team of several hundred mobile engineers and along with that, many challenges. In the past year, Uber’s Mobile Platform team has made major changes to improve development speed and agility for its engineers, with a focus on stability and meeting a high quality bar for our software. Tooling and infrastructure changes are helping Uber's engineers check their code into master faster than ever before, and the company's recent effort to migrate all code into a monolithic repository using the Buck build tool has laid a foundation for future experimentation and growth in its toolchain.


Steve Robertson (YouTube) makes the case for next generation video delivery today, including an explanation of the fundamentals of video compression, a recipe for deployment in your own service, and ways you can help shape VP9's successor to better meet your needs.

Apache Beam (incubating) is a unified batch and streaming data processing programming model that is efficient and portable. Beam evolved from a decade of system-building at Google, and Beam pipelines run today on both open source (Apache Flink, Apache Spark) and proprietary (Google Cloud Dataflow) runners. This talk will focus on I/O and connectors in Apache Beam, specifically its APIs for efficient, parallel, adaptive I/O. Google will discuss how these APIs enable a Beam data processing pipeline runner to dynamically rebalance work at runtime, to work around stragglers, and to automatically scale up and down cluster size as a job’s workload changes. Together these APIs and techniques enable Apache Beam runners to efficiently use computing resources without compromising on performance or correctness. Practical examples and a demonstration of Beam will be included.

In this talk, Google will cover its pursue of a fair and meaningful Cloud benchmarking framework, PerfKit Benchmarker, from one of its performance engineers' perspective. The talk will cover the challenges and pitfalls the team faced in defining what matters, in addition to common customer challenges, and share how they were tackled. It will also cover sampling challenges, processing, and storage of 3K samples/second, and the challenge to mine and visualize the data in a meaningful way.

Discover Weekly is a personalized mixtape of 30 highly personalized songs that's curated and delivered to Spotify's 100M active users every Monday. It's received high acclaim in the press and reached over 5B streams from 40M users since launch. In this talk we dive into the narrative of how Discover Weekly came to be, highlighting technical challenges, data-driven development, and the machine learning models used to power our recommendations engine.

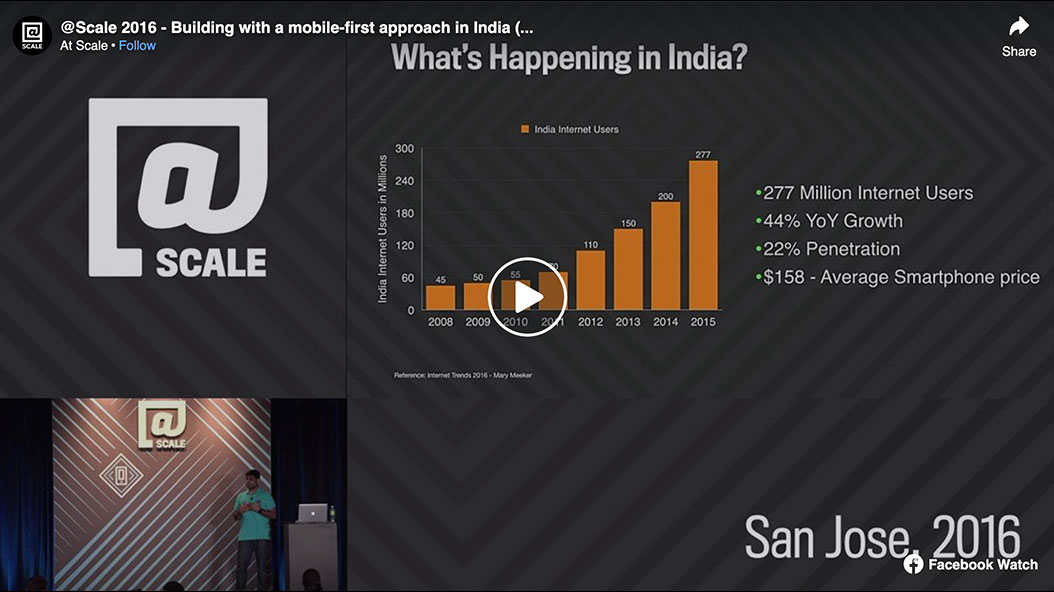
Why is mobile big for India? Flipkart will be sharing some of the challenges this throws at e-commerce businesses and how the company transformed itself and its technology to make things happen for its customers. The company will discuss the technology investments it made while adopting a mobile-first approach to everything it did, and how it helped Flipkart become the first Indian app to cross 50 million downloads in India.

Take a break to meet with speakers for Q&A from the previous track sessions. Office hours will occur just outside the presentation rooms in designated areas. Follow the signs to meet with: Data Track Speakers: Debanjan Saha at Amazon, Yoshinori Matsunobu at Facebook, and Dan Halperin at Google. Mobile Track Speakers: Igor Canadi and Alex Langenfeld at Facebook, Valera Zakharov at Slack, and Amar Nagaram at FlipKart. Dev Tools/Ops Track Speakers: Jeffrey Dunn at Facebook, Alan Zeino and Nick Cobb at Uber, and Ivan Filho at Google. Hot Topics Track Speakers: Andrew Tulloch and Yangqing Jia at Facebook, Steve Robertson at YouTube, and Edward Newett at Spotify.
Efficient use of large-scale data for Machine Learning (ML) research is a challenge. Training and distributing hundreds of models, monitoring performances, and sharing algorithms in a production environment requires tools to simplify the daily tasks of ML engineers. Facebook has developed a family of tools to manage the entire process of training, testing, and deploying ML models. Those include FBLearner Flow and Predictor. The former is a pipeline management system that facilitates experimentation, training, and comparison of models; the latter is an inference framework that uses the models to provide real-time inferences in production. FBLearner Flow is used by more than a thousand engineers per month. In a month, FBLearner is used to train more than 600,000 models, ingesting 2.3 billion data entries per model. These models are then used in production, serving more than six million predictions per second and touching all the major functionality of Facebook, including ranking News Feed stories and matching users to ads.


With HTTP2 push, Facebook has built out a new client/server interaction model, which now makes it possible for the company's Edge/FBCDN servers to 'push' required images and Live streams from the server for a News Feed story or on-going live stream. HTTP2 Server push features are now available to the public. This talk will cover how Facebook leverages HTTP2 to achieve lower latencies.


Most network monitoring relies in the individual network devices themselves telling you that they are healthy or unhealthy via syslog messages, SNMP data, etc. In a Facebook scale network we just can't trust the network devices to accurately report their health in all the possible failure cases that may exist. In addition to the standard network monitoring tools, we also actively probe our network with test traffic to ensure it's behaving exactly as we expect. We can now find the network devices that don't even know they are dropping packets even when they exist several layers deep inside the network.

Project Infinite is one of the biggest evolutions in the Dropbox product since the shared folder, enabling users to see all of the content across their entire team on their local computer without syncing it first (and instead syncing it on demand). This talk will explore how a hack week project turned into a major company initiative, the technical decisions and trade-off in its design, and how Dropbox keeps the quality bar high as it wields deeper and deeper integrations into the filesystem across hundreds of millions of devices.

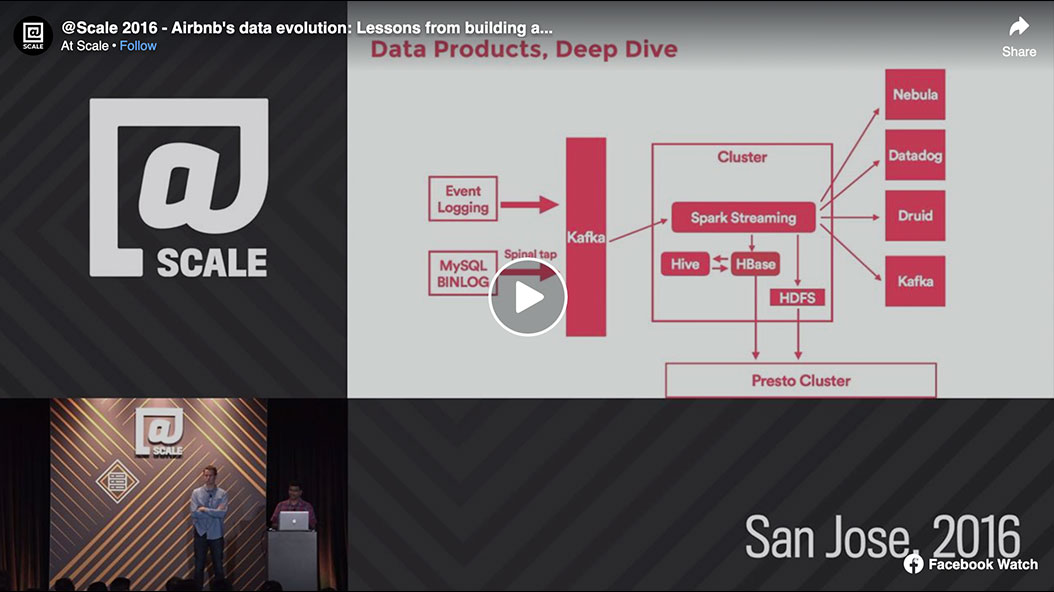
Airbnb's mission is twofold: Empower employees to make data-informed decisions, and ensure that the Airbnb product learns from user feedback. From three years ago to today, the data teams rebuilt every major component of Airbnb's stack, stabilized the foundation of its platform, grew its suite of tools, created canonical data sets, proselytized for correct use of the scientific method, and open-sourced key projects in an effort to give back to the community. They have done this while the company is in the midst of experiencing hypergrowth. It has been quite a journey, and the team is happy to share its experience with the group, and to talk about the next steps it is taking around data products, including machine learning infrastructure.


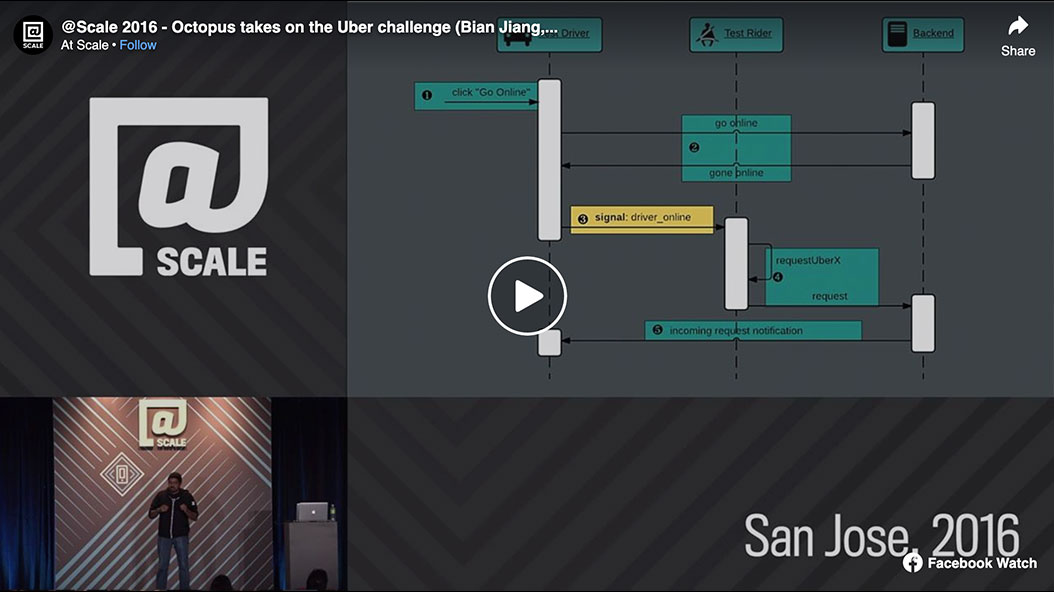
In March 2015, a challenge unique to Uber came up in an investigation of UI testing tools for its mobile applications. Many of the sanity tests require a rider application and driver application to communicate and coordinate their actions in order to complete the end-to-end testing scenario. The focus of this talk will be on the company's platform agnostic solution, called Octopus, and discuss how Uber implemented signaling to coordinate the communication across different apps running on different devices. The company will look back on how Octopus has evolved over the past year as it scaled up the number of tests in its CI to guard its builds. The talk will go over how Uber implemented network record/replay and scenario-based testing for iOS/Android so its tests would run reliably on CI. The talk will cover the challenges faced and the lessons learned on the path to designing Uber's frameworks to ensure that its devs could write predictable and deterministic tests.


As a data driven company, Pinterest relies heavily on A/B experiments to make product decisions. How efficiently we run these experiments affects how quickly we can iterate. We'll cover all aspects of experimentation from configuration management, instrumentation, data processing, metrics tracking, realtime monitoring and rolling out technology and processes across the company. Additionally, as we grow our experimentation culture and our service becomes more real-time, we've built stateful online services on replicated RocksDB. With RocksDB, we've created high throughput and low latency online systems operating on multiple large online updated and/or offline generated datasets. These systems have powered many Pinterest products, including personalized Pin scoring, Pin impression tracking, Picked For You feed, and ads delivery tracking. We'll discuss the technical challenges and approaches we've used, as well as the common architecture and shared components of replicated RocksDB based systems. The design philosophy and implementation details of one of the core components, RocksDB replicator will be also presented.


Open source software is fundamental to building a modern tech company. This panel discussion will feature companies widely recognized for running high-quality open source programs. Attendees will gain insight into the tooling, processes, and team structures these companies have built to manage open source programs that keep communities engaged at scale.



Ambry is an open source, geodistributed, highly available, and horizontally scalable object store built at LinkedIn. It is an active-active, immutable, eventually consistent handle store that can be configured to provide stronger read-after-write consistency without additional latency overhead. At LinkedIn, Ambry runs on hundreds of nodes spanning multiple data centers and is the source of truth for media and other immutable content. The focus of this talk will be the architecture of Ambry and how the design decisions help it scale for both large and small objects. It will also cover how Ambry helped solve the main pain points of LinkedIn's legacy media store. Finally, LinkedIn will talk about the roadmap and about getting involved in this open source initiative.


Static analysis improves software quality and saves time by catching bugs early in the development process. Today at Facebook, two small teams build static analysis tools that support thousands of engineers and millions of lines of code. But to continue getting the most value out of static analyzers, we must be able to quickly adapt our tools to prevent the problems of tomorrow. In this talk, I will discuss designing static analysis frameworks that make it easy to add new bug types, analyses, and languages while maintaining the stringent requirement of scaling to Facebook-size code.

Instagram is one of the most popular social apps and has more than 500M monthly active users. We will talk about how Instagram was able to scale its Django/Python web framework by putting the right metric and tooling in place to gain visibility into the stack, fix inefficient code paths, and improve server capacity with increased parallelism in network IO access.

Take a break to meet with speakers for Q&A from the previous track sessions. Office hours will occur just outside the presentation rooms in designated areas. Follow the signs to meet with: Data Track Speakers: Pierre Andrews and Aditya Kalro at Facebook, James Mayfield and Swaroop Jagadish at Airbnb, and Priyesh Narayanan and Holla Gopalakrishna at LinkedIn, Mobile Track Speakers: Ranjeeth Dasineni and Saral Shodhan at Facebook, and Bian Jiang and Madhav Srinivasan at Uber, and Sam Blackshear at Facebook. Dev Tools/Ops Track Speakers: Lisa Guo at Instagram, Richard Sheehan at Facebook, and Chunyan Wang and Bo Liu at Pinterest. Hot Topics Track Speakers: Ben Newhouse at Dropbox, Brandon Keepers at GitHub, Surupa Biswas at Facebook, Jeff McAffer at Microsoft, and Andrew Spyker at Netflix.
Executive Vice President at Microsoft. read more


Shan is a senior data visualization engineer at Uber. She is a coder, a... read more























Ivan Santa Maria Filho is the dev manager of SCOPE, Microsoft’s internal analytics engine.... read more