






Introduction
Video calling brings people together despite the geographic distance between them. Amidst recent years’ significant growth in RTC usage, new challenges have emerged in scenarios where the network is subpar.
Packet loss is common in computer networking, and it’s a major challenge in computer network resiliency domains. In the context of RTC, loss recovery shouldn’t only occur in real time, but should also utilize as little bandwidth as possible. In this blog post, we will take a deep dive into our recent enhancements to video network resiliency with regard to packet loss scenarios.
Video Freeze
Users won’t tolerate choppy video. Increased video freeze strongly correlates with increased negative user sentiment. We look at video freeze as a measure of the choppiness of a call.
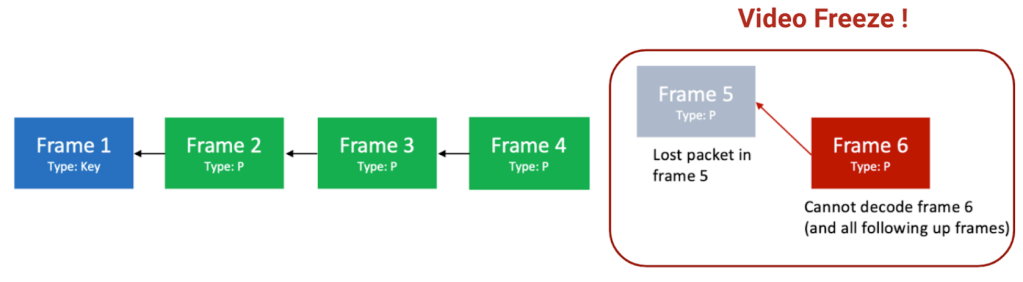
Raw video data is huge, so it requires encoding (i.e., compression) before being sent over the network. For a basic RTC setup, a video frame can be encoded as either a key frame or P-frame. A key frame is larger but can be independently decoded, whereas a P-frame is smaller, but its decoding requires a decodable reference frame.
When packet loss breaks a P-frame decoding chain, the video keeps freezing unless we fix the chain (through retransmission) or start a new chain (using a key frame). From a proactive perspective, providing backup links to the chain—forward error correction, or FEC—can prevent the chain from breaking.
For a typical RTC video network resiliency setup, retransmission, key frame, and FEC work together to prevent video freezes. In the past, optimizing those three mechanisms has yielded remarkable quality-of-service improvements; those didn’t stop us, however, from leaping to the next-generation technologies: long-term reference (LTR) and Reed-Solomon code (RS code) forward error correction (FEC).
Existing Solutions
Retransmission
When the receiver detects a sequence-number gap, it requests retransmission from the sender. Retransmission is highly effective for some networks, but there are two scenarios where retransmission falls short:
- High round-trip time (RTT): The video will pause noticeably before complete recovery. FEC compensates for this.
- Bursty loss: Compared with the high-bandwidth demands of recovering every lost packet, a recovery involving a key frame requires much smaller overhead.
Forward error correction (FEC)
Retransmission does well when network RTT is low, whereas it falls short if the jitter buffer isn’t long enough to allow for the retransmission’s arrival. FEC enables instantaneous loss recovery by sending parity data along with the original data.
As a result, Video FEC has broad applications in RTC:
- Bandwidth probing
- Proactive protection (from unused bandwidth)
- Reactive protection (from media bandwidth)
WebRTC provides a solid implementation of XOR-based video FEC, which is wrapped by FlexFec and ULPFEC (uneven-level protection forward-error correction). From an algorithmic perspective, XOR-based FEC has a fundamental shortcoming: It doesn’t scale well with more data. Recovery performance degrades exponentially as the protection group contains more packets. As an MDS (maximum distance separable) code, Reed-Solomon code has fundamentally better recovery properties and can scale well indefinitely as RTC traffic grows larger.
Key frames
Key frames are important in establishing a new video-decoding sequence. They play an important role in addressing decoder failures and mitigating catastrophic loss events. As such, key frames can be particularly effective in loss recovery. Their ability to directly unblock the decoder eliminates the need for retransmitting all missing packets. For instance, during bursty loss conditions where up to 9 or 10 packets might need retransmission, requesting a key frame can be more efficient, as a key frame may contain only 2 to 3 packets.
A significant challenge with key frames, however, is their size, which is typically much larger than that of P-frames. This presents a dilemma: Transmitting a full-size key frame instead of P-frames could exacerbate network congestion, while compressing the key frame may lead to substantially reduced quality. Such compression can cause video flickering, potentially degrading the user experience.
LTR frames offer a viable solution. They provide similar efficiency in loss recovery as key frames but with a much smaller size and better quality. In the next section, we will delve into the concept and high-level design of LTR, exploring how it addresses these challenges.
Long-term reference frames
LTR frames are a feature that allows a codec to keep some frames in memory to be used as references for encoding future frames. This concept is used in various video codecs, including H.264, H.265 (HEVC), and VP8.
LTR provides an efficient new method to recover from loss. As illustrated in Figure 2, if a decoder is blocked due to a missing packet in Frame 5, the receiver can request a P-frame (LTR-P) from the sender based on the latest decodable LTR it received (in this case, from Frame 3). After the receiver receives the LTR-P (from Frame 7), it can continue decoding Frame 7 based on the LTR from Frame 3..

Compared with key frames, LTR-P has a smaller size but higher quality. LTR-P can be 40% to 50% smaller than the key frame, but it provides similar video quality as the P-frame (if not very far from the LTR). The following images illustrate the potential difference between a key frame and a P-frame:
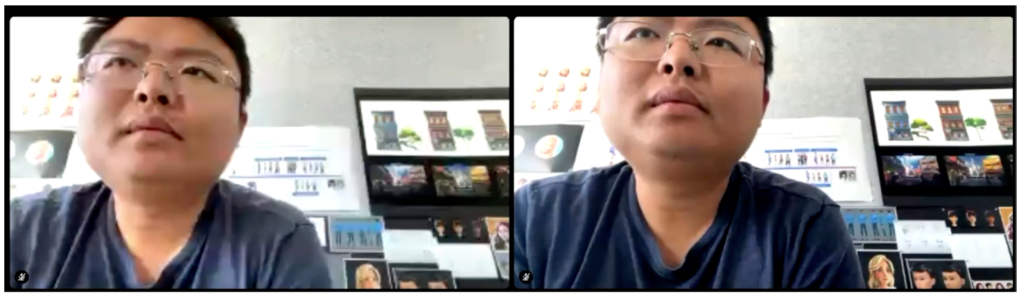
Given the qualitative difference, the LTR-P can be a building block for improved loss recovery. No longer must there be requests for retransmission for every missing packet; now the receiver can request a LTR-P based on the last decodable LTR frames. In a high-loss network, this can be far more efficient than retransmission.
High-level design
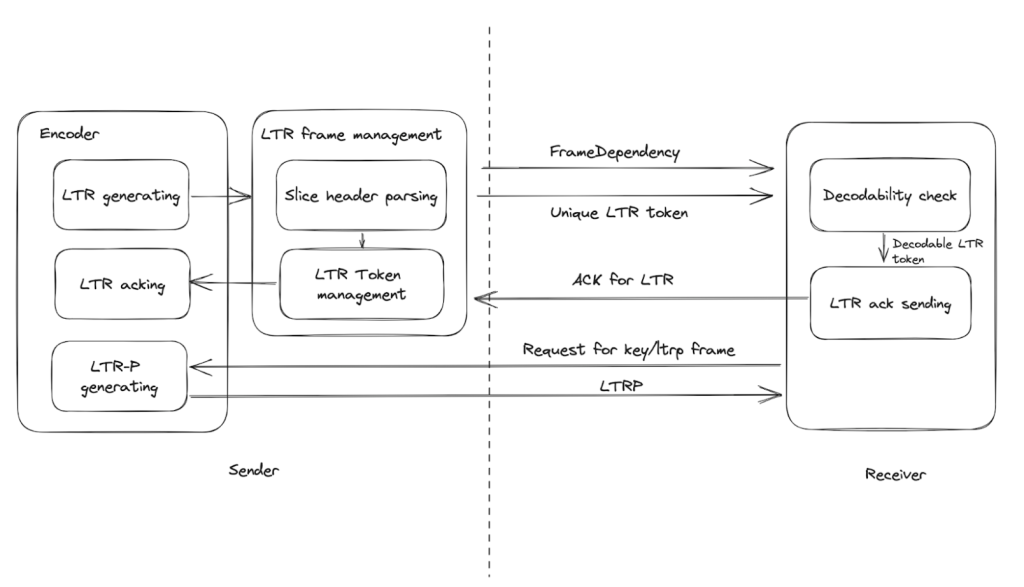
Figure 4 shows the high-level design of LTR. Note that basically, the LTR usually works by involving the following process (for both the hardware and software H.264 encoder):
- The encoder generates the LTR periodically.
- Unique tokens that identify the LTR and its dependency are sent to the receiver. Decodable LTR frames are acknowledged from the receiver to the sender.
- When needed, the encoder generates a LTR-P that refers to the ACKed LTR frame.
While the high-level design looks straightforward, there were challenges we needed to address to make it work. Below, we’ll go over some challenges we faced when deploying the LTR.
Challenges in deploying LTR at Meta
While long-term reference is considered a replacement solution for the key frame, it’s important to understand that LTR is not an exact replica of a key frame. A key frame is fully self-decodable, whereas LTR still requires the corresponding reference frame to be in memory for correct decoding. This distinction means that if any edge case is not covered, it may result in a prolonged period of no video. For instance, during A/B tests with LTR, we observed a significant regression (of approximately 2%) in the no-video rate, indicating that there are still gaps between LTR and key frames in terms of the capability to recover from packet loss. Here are some of the major challenges we had to overcome to successfully roll out LTR:
Deep understanding of the internal behavior of the OpenH264
OpenH264 offers comprehensive API support for implementing most functionalities related to LTR (e.g., LTR generating and acknowledging), which greatly simplifies our design and implementation process. However, applying these APIs without a thorough understanding of their underlying workings can lead to deployment challenges. For example, one notable issue we encountered stemmed from an internal encoder behavior that disregarded LTR-P requests, producing P-frames until a new LTR was explicitly acknowledged after generating a key frame. This led to a deadlock, with the receiver continuously requesting LTR-P while the sender sent undecodable P-frames. We resolved this by resetting the acknowledged LTR status in the encoder wrapper post-IDR generation.
Understanding the interaction between WebRTC and LTR
Integrating LTR into WebRTC is intricate, requiring a detailed understanding of how WebRTC handles reference frames. Mismanagement or inadequate understanding can cause problems. For instance, we initially send acknowledgement of the LTR after receiving the frame (and before the frame is decoded). However, we found it led to occasional long freezes. We later discovered that these freezers were due to LTRs being discarded in the frame buffer before reaching the decoder and causing the sender to generate an LTR-P based on the LTR that is not in the receiver’s buffer. We rectified this by acknowledging LTRs only after they were decoded. After that, we no longer observed long-freeze issues with LTR.
Optimizations built around key frames
While we successfully achieved seamless operation of LTR, its deployment presented challenges due to the numerous key frame-specific optimizations developed over time. When LTR replaced key frames, we noted regressions across various media metrics. A particularly significant issue was a noticeable audio/video (A/V) sync regression during LTRP that did not happen with key frames. An in-depth analysis revealed that this issue stemmed from a proprietary optimization that cleared the retransmission list following key-frame transmission, significantly enhancing A/V sync. The lack of this optimization for LTR resulted in noticeable A/V sync discrepancies. This scenario exemplifies the need to identify impactful optimizations and fixes that have been applied to key frames, ensuring that LTR incorporates similar features for equal or superior performance.
By overcoming these three challenges, we successfully deployed LTR without compromising any major quality metrics. This led to a nearly 20% reduction in key frames under packet-loss conditions, without any increase in video freezing.
Reed-Solomon code video FEC
In addition to the XOR-based FlexFEC, incorporating the Reed-Solomon error correction code greatly improved video stream’s performance on packet loss recovery. The advantage is not only clear on benchmarking, but also reflected on video freeze metrics in production testing.
Open-source XOR-based FEC solution
WebRTC provides matured implementation for XOR-based FEC such as FlexFec and ULPFEC. They both use heuristic rules to cover different packet-loss scenarios and work reasonably well as an open-source solution. There are two shortcomings, however, that motivated us to move towards using the Reed-Solomon code FEC:
- High-traffic overhead: It takes a significant amount of bandwidth for XOR-based FEC to achieve acceptable packet-loss coverage. Media traffic often suffers from low-quality and low-resolution oscillation.
- Suboptimal recovery rates. With k source packets, XOR-based FEC theoretically needs O(2^k / k) protection packets to guarantee recovery.
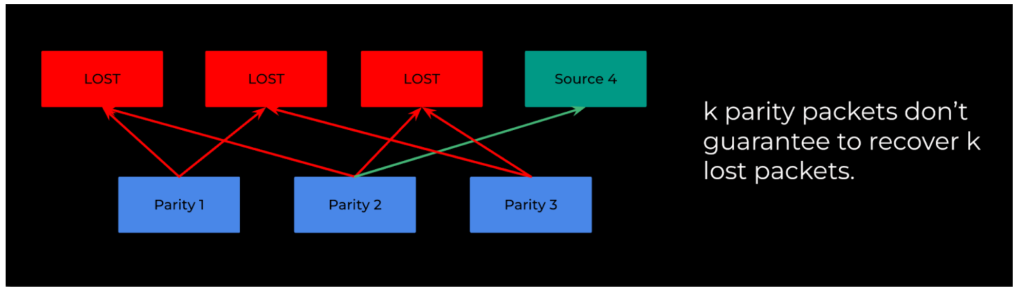
XOR-based FEC doesn’t scale
Assuming we are splitting the bandwidth 50/50 between video and FEC, then for k video packets there are k FEC packets encoded by XOR. This is also called (k, 2k) encoding.
Each FEC packet can recover O(k) loss scenarios, and there are O(2^k) lost scenarios in total. As a result, XOR-based FEC has a recovery rate bounded by O(k^2/(2^k)). As k grows beyond 5, the recovery rate exponentially decreases. In other words, as modern RTC applications evolve into higher media quality with higher traffic, XOR-based FEC doesn’t scale.
Reed-Solomon code FEC scales well
Reed-Solomon code steps in with fundamentally superior properties than XOR-based video FEC. With the same (i.e., k, 2k) encoding, RS code has a constant 100% recovery rate that scales indefinitely as traffic rates increase.

Deploying Reed-Solomon code to Meta Messenger
Meta uses an internal proprietary Reed-Solomon code implementation to fuel its RTC video FEC algorithm. To deploy the RS code on mobile clients, we made careful decisions about the implementation algorithm, codec configuration, codec-memory optimization, and codec-runtime optimization.
We carefully engineered the integration into existing Network Resiliency (NR) systems, so that RS code and FlexFec can dynamically switch with each other as well as be compatible with temporal layering.
Conclusion and future work
As we reflect on our journey to enhance video-streaming quality in lossy environments, we’re encouraged by the effectiveness of the strategies we’ve implemented. Our efforts in rolling out long-term reference frames and Reed-Solomon codes have laid solid groundwork for ongoing improvements and have provided valuable insights for future endeavors.
Looking ahead
The complexities of dealing with packet loss underscore the need for continuous innovation. It’s clear that a one-size-fits-all approach is insufficient and that we need to adapt our algorithm based on different user scenarios and network conditions. Some areas of future improvement include:
- Expanding LTR coverage: We plan to extend LTR support beyond OpenH264 to other codecs, such as AV1 and iOS hardware encoders, broadening our impact across various platforms.
- Dynamic selection of a NR approach: Our current focus is on integrating LTR as a fundamental component. One interesting problem that we are eager to explore is how to use it more effectively with other solutions. For example, how should we decide when to request LTR frame, key frame or retransmission under different network loss and RTT scenarios to strike a balance between video freezing and tranmission overhead?
- Video FEC: Meta is contributing its XOR-based, group-call FEC implementation to upstream WebRTC. Other players in the industry can leverage our solution to scale better in their group-call applications. In the meanwhile, we are still actively iterating on video FEC mechanisms to stay competitive under evolving network conditions.

