






‘IFR in IMC over SLI into LGB on the VOR and ILS in a 172 photo D Ramey Logan.jpg’ from Wikimedia Commons by Don Ramey Logan, CC-BY-SA 4.0
Imagine you’re peacefully flying a plane above the clouds. Suddenly, those clouds close in on your flight path. The horizon now hidden, you quickly transition to relying on your instruments, yet you still become disoriented, unable to tell which way is up. The plane, adrift without the proper inputs from its pilot, slowly loses altitude, changes direction, and picks up speed. Without correction, it is only a matter of time before the ground and plane meet.
In the general aviation (GA) world, where training is less rigorous than for commercial operators, and commonly, a single pilot must handle the full workload, this scenario is an all-too-common occurrence. What if the pilot had an always-available, synthetic display of the outside world to increase situational awareness? What if the pilot becomes disoriented or incapacitated, pressing a single button on the instrument panel would carefully recover and maintain the plane in straight and level flight? Could technology and improved human factors yield a step-function change for safety in GA?

Cirrus Perspective (by Garmin) instrument panel for SR20/SR22/SR22T from Wikimedia Commons by Dbreemeersch, CC-BY-SA 3.0
A company believed so if only it could navigate a daunting, three-dimensional execution challenge:
- Innovate: Transform the typical analog cockpit into a fully integrated digital system with a real-time, redundant data bus connecting newly designed displays, radios, GPS receivers, an autopilot, and sophisticated control-surface servos with position, speed, and torque control—the precision capabilities required to ensure the autopilot could safely recover from unusual attitudes without overstressing the airframe.
- Short Time-to-Market: Beat out much larger competitors in a time-to-market race. The company shared its vision with several airplane manufacturers in a bid to win original equipment manufacturer (OEM) avionics contracts. The airplane manufacturers, in turn, disclosed these innovative ideas to the company’s much larger competitors, amplifying schedule pressure.
- Reliability: Satisfy aviation’s regulatory mandates to certifiably prove the reliability and safety of all this new technology.
Conventional wisdom is that strong delivery across all three dimensions isn’t possible without hard trade-offs. Working for this avionics company years ago, what I found out and reconfirm daily, building hyper-scale infrastructure for Meta, is that this conventional “wisdom” isn’t always right.
In this blog post, I will discuss how the lessons I learned from my experience working in aviation—where reliability is not an option—are applied at Meta to achieve high reliability along with innovation and a short time to market.
Framing the Problem

What does avionics have to do with Reliability@Scale? While the stakes are higher in avionics—a matter of life and death—the optimization problem we face building these hyper-scale systems is much the same: We need to build innovative solutions in a competitive environment that requires a short time to market while achieving high reliability. There is, however, one key difference. In tech, we treat the reliability dimension differently than the others.
Despite a slew of highly visible reliability failures (Google, August 2024; CrowdStrike, July 2024; Meta, October 2021) that have caused large economic and reputational harm, reliability in the tech space is usually sacrificed to deliver on innovation and speed to market. In the aviation industry, regulatory entities—such as the Federal Aviation Association (FAA) and European Union Aviation Safety Agency (EASA)—enforce a high-reliability bar, and that usually comes at the expense of either innovation or execution speed. During the five-year period I worked on avionics, none of these compromises would lead to the company’s success. This makes my experience a great case study for understanding methods for improving reliability while still meeting all other business requirements.
In the remainder of this article, I’ll briefly describe how this ambitious avionics program fared, the key lesson I extracted from working on it, and cultural and technical strategies for applying that lesson yourself.
The Setup

Work on this avionics system was split evenly across two divisions, each with a unique execution model. This created an almost perfect A/B test of optimization strategies.
One division—Team A—believed that the best execution path satisfied reliability requirements late. Move fast to build up your product first. Only once “feature complete” did the engineers fully engage with the certification process by hiring contractors to backfill tests and requirements, perform independent reviews, and develop certification artifacts. The rationale went something like this: Why invest in any of that certification stuff while we’re building since the product may change?
The second division—Team B—adopted “continuous certification.” Apart from some prototyping work used to develop requirements or evaluate competing algorithms, software was validated and documented to certification standards in lock step with its development. In essence, the code base was always in a state of certifiable and known correct software, with developers responsible for never landing changes that broke this invariant.
Charting the Race
Any guesses on the faster approach?

Out of the gate, Team A started landing code while Team B invested time in optimizing the workflow for certifying in concert with development. Even when Team B started landing production code, its pace was slower than Team A.
This changed dramatically at the point where work was considered “feature complete.” For Team B, progress followed a similar trajectory as they worked toward certification. This period involved final flight testing to verify simulation fidelity and minor adjustments for gaps that this verification phase uncovered. In contrast, Team A’s certification work uncovered missing or incorrect requirements and software defects that were expensive to resolve.
Not only did this rework cause the schedule to slip, but schedule risk remained high all the way to the end. By deferring the certification work, the team had no idea what issues it would find and have to correct after they thought (at feature-complete time) they were almost done.
In the end, neither team hit the planned program schedule. Team B slipped only about 15 percent—well within the margin for a successful outcome. Team A, however, took almost double the time of their initial estimate, completing work long after the first competitor released their product. With the output from both teams required to ship, the company lost the time-to-market race and didn’t win any OEM contracts.
One Weird Trick…
Team B’s success was far from certain. The key “trick” that made it possible was placing certification and all the verified reliability standards that brings on equal footing with all the other engineering problems to solve. Reliability was a hard requirement.

‘Construction_warning_sign.jpg’ from Wikimedia Commons by Victor Adrian, https://bestformyfeet.com, CC-BY-3.0
Why does this matter? Engineers thrive when challenged. Give them a set of hard requirements and they will work tirelessly to deliver against them. But, allow even the hint that some aspect of the problem space is optional and they will attempt to use that to their advantage. Can the problem be solved without doing that work? The first to go is proactive reliability items unless it is mandated and rewarded.
In case you hadn’t guessed, I worked on Team B. At the start, I wasn’t sold on the proactive certification approach. Writing good tests is hard work, and, as an over-confident coder, I assumed continuous validation would add little value. What I didn’t anticipate is how just knowing of the testing requirements would significantly influence and improve the software. The team naturally shipped modular software with clean application programming interfaces (APIs) and component contracts because they were easier to test. There were larger investments in and use of standardized shared components because duplication incurred more certification cost and there was no risk incurred by taking on a dependency known to be highly reliable. Team B developed high-quality testing frameworks and tools because its engineers naturally optimized workflows they had to repeatedly perform.
The extensive test coverage also simplified development. We started the work day with known good software. If some test broke after we made changes, the source of the failure was almost certain. Ninety-nine percent of the time, the new code introduced a defect or violated a subtle requirement the programmer had forgotten about. We all came to trust the defensive measures built into the development environment, enabling development speed to accelerate without compromising correctness.
Can you achieve this same result without setting reliability standards? Do you always complete the 10k steps your doctor says you should walk daily? This challenge is much the same. Only teams with both positive past experience and the self-discipline to execute this way will do it by default. Even these teams will be challenged if incentives are not aligned with this mode of operation. Some structure is required to consistently operate this way.
Making this Actionable

Lemon_batteries_circuit_1390001_nevit.jpg from Wikimedia Commons by Nevit Dilmen, CC-BY-SA 3.0
Breadboard_counter.jpg from Wikimedia Commons by RoySmith
Rostock_Power_Station,_SW_view.jpg from Wikimedia Commons by Radomianin, CC-BY-SA 4.0
The reliability spectrum spans projects with almost no reliability requirements, to safety-critical applications where reliability is mandatory. In our industry, we rarely build certified software. And, I’m not suggesting that this level of process rigor is required to get these benefits (e.g., Meta’s systems are well to the right of center on the scale, but some distance away from software developed under the DO-178 aviation certification process).
Instead, I want to motivate you to shift your current development methodologies to the right on the reliability spectrum and give you some concrete examples of things I’ve taken from executing a certification process and now apply at Meta.
The Three Culture Pillars
The first aspect is changing the expectations embodied by your software development culture. There are three required pillars to implementing this type of culture shift.

Completion
The completion pillar defines what needs to be delivered to claim impact. The typical definition in most work environments is landing a change and shipping it to production. Moving to the right on the reliability spectrum requires additional deliverables to ensure a change does not degrade reliability, and that reliability can be maintained for the lifetime of the software. Some items you might include in your “definition of done” could be: requirements development, creation of or updates to documentation, failure risk analysis, and various types of software verification.
Standards
The quality of work product has an outsized impact on reliability. The standards pillar defines the quality bar across all deliverables. Coding standards likely first come to mind, but standards matter for everything from how the team performs code review (including, for example, reviewer response service-level agreements (SLAs), tests independently reviewed and held to the same bar as code, maximum change size, content of change summaries) to verification (including minimum test coverage, maximum test-execution time, expectations for automation and repeatability), and the content of service contracts.
It is easy to fall into the trap of standardizing everything. This approach can stifle creativity and make your team feel like they are being forced to live by a set of arbitrary rules. Instead, when I feel the desire to define a new expectation for how work is performed, I always ask, Is this a quality of our workflow that needs to be consistent so developers can rely on it to improve reliability and/or execution speed? If the answer is no, there’s no need to add it to your standards.
Accountability
The final pillar is about ensuring the work product meets expectations and that all developers operate on a level playing field. Needing to “hold the bar” may seem obvious, but if accountability lapses, inconsistency quickly follows. Even the perception of inconsistency can quickly undermine the culture: That team never writes tests, uses that extra bandwidth to claim more impact by shipping additional features, and always gets the best performance ratings! This is why any effective culture needs both enforcement and incentive mechanisms that support accountability and are seen to be applied equitably.
Where possible, using quantitative metrics is the best way to manage this pillar because they are impartial measures of compliance. Items to consider here are tracking regressions in mean time to recovery (MTTR) and mean time to detection (MTTD) of production failures, software-defect escape rate, percentage of code covered by tests, test quality (e.g., percentage of flaky or broken tests, test execution speed), and team velocity metrics (e.g., average time to author and land software or configuration changes, surveys of developer sentiment).
Like “Mom and apple pie,” you probably feel that all three culture pillars are obviously nice things to have but perhaps are too expensive or impractical to do. Implemented inconsistently, that is almost certainly true. For example, if that one team member who believes in testing writes most of your tests, you get partial test coverage that can’t be relied upon to catch new defects and an employee who resents that no one else seems to care. If instead, this testing burden is a shared responsibility and requirement, the whole team is motivated to make testing easier.
During my time working on avionics, a key concern was ensuring certification work didn’t block developer progress. This led Team B to dedicate the first two hours of each workday to certification processes that required independent review. Developers aligned on a highly effective natural rhythm of submitting new changes each evening and getting actionable feedback less than 24 hours later. This is just one example where consistent expectations motivated a bottoms-up solution—no manager suggested this change—to increase team productivity.
Invest in Tooling
Similarly, on the tech side, strong requirements drive innovation. At Meta, we’ve developed lots of different tools to accelerate software validation. Here, I want to describe a method you probably haven’t thought practical before: randomized, deterministic state-space exploration and validation. That’s quite a mouthful, so let me better explain what this method does.
Let’s say you’re concerned that your complex system has some hidden failure modes that are triggered only by specific sequences of events. How do you find and debug this type of long failure chain? If we represent the system under test as a collection of state variables and defined state transitions, we want to know if there is a system state that results in failure, and the steps we took to enter that state.
The test needs to exercise the system with randomized sequences of state-transition events to explore the universe of possible failure chains, performing some state validity checks after each step to detect any failures. This is a daunting challenge, but fortunately there is some prior art to guide us.
The Morpheus system described in “Effective Concurrency Testing for Distributed Systems” (ASPLOS ‘20) leverages capabilities of the Erlang programming language to enable this type of testing. Similarly, in “Foundation DB: A Distributed Unbundled Transactional Key Value Store” (SIGMOD ‘21), the developers utilized “Flow,” a set of custom async programming primitives built on C++, to achieve a similar result. At Meta, we’ve embraced C++ standard coroutines and the folly::coro library, which make this method even more accessible.
The components of the test are:
Controlled-execution order
Developing against C++ coroutines enables control of most program state transitions. This is possible because all coroutine scheduling is managed by a user-space scheduler, the “coroutine executor.” For test runs, we replace the production scheduler with one that takes a random seed and uses this to deterministically and serially execute all outstanding work in a randomized fashion. This essentially allows us to randomize the sequencing of any parallel work at the granularity of coroutine suspension (i.e., any co_await location in the code).
Single-executor execution
We mock things like the network and timers to ensure all processing goes through the single executor. Any dependency that operates using its own threads for concurrency must be adjusted to execute through the single executor provided by the test environment.
Validation
Three different types of validation are required:
- Determinism: We execute multiple runs using the same execution seed value, record certain aspects of execution state that are sensitive to execution order for each run, and fail the test when the execution state differs across runs. We do this to ensure we catch any changes to our dependencies that affect the reproducibility of the test—for example, introducing concurrency that occurs on an independent/uncontrolled executor.
- Invariants: These are checks to ensure the program state is consistent with correctness and other requirements. Debugging is easier when validation occurs after every execution step, but when validation costs are high, we coarsely sample by default but can increase granularity when doing a root-cause analysis of a failure.
- Coverage: Did the test cover a sufficient amount of the state space and transitions of interest? To stimulate coverage, we can change the probability of simulated faults, network delays, and other events. The test is then run until a sufficient number of interesting scenarios have been executed.
A Worked Example
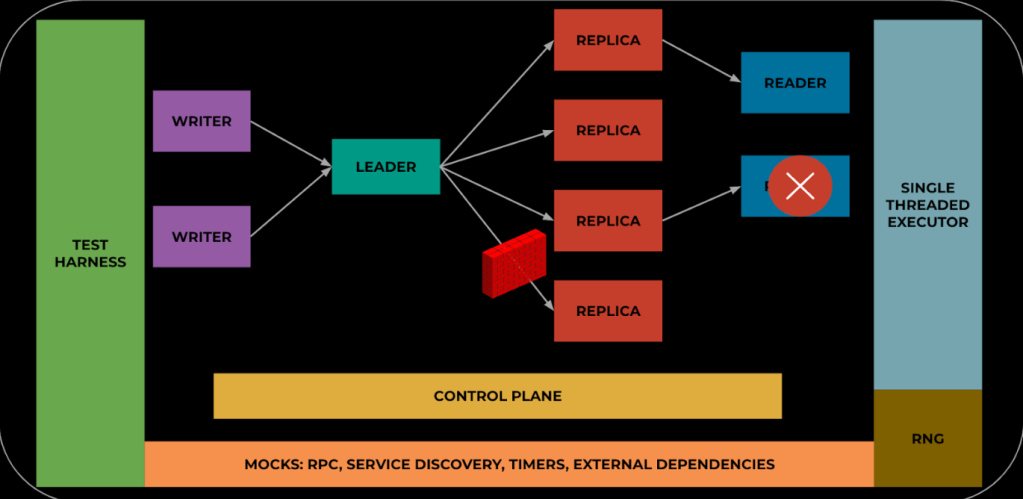
To make these concepts more concrete, I’ll apply this strategy to a hypothetical Pub/Sub system. This is a distributed system serving the same kind of mission as an Apache Kafka or a similar system. Data is produced by one or more writers, ordered by a stable “stream leader,” replicated to a quorum of replicas to ensure data durability, and served to readers from replicas. In production, each of these roles is executed in a separate process, potentially running on an independent server.
The implementation for all roles—writer, leader, replica, reader, control plane—must conform to the test execution-environment requirements. In practice, this means that each role can be instantiated either within a main function of a process (as is done in production) or in the single process of a test run, and that there are no built-in assumptions about concurrent execution between roles.
The test harness contains the special executor, a representation of a machine cluster for placing roles, and a set of injectable event types with assigned probabilities. The simulation is initialized with a random seed and an initial system configuration derived from that seed (e.g., a leader connected to a set of replicas). From that point on, the probabilistic injection of the different event types drives the simulation. On every execution step, the executor picks a random work item to execute until it hits a coroutine suspension point. At the end of the step, the test harness decides what if any events to simulate: add a new writer, restart a reader, add or remove a replica, simulate a network partition, gracefully replace a leader, etc.
The three types of validation are handled as follows:
- Determinism: The test run is repeated five times using the same initial random seed. At the end of each of these five runs, the final cluster state is hashed and compared to that of the previous run. If they differ, the determinism invariant has been violated. Cluster state in the context of this test includes all role-specific states, including, for example, any inflight writes held at writers and leaders, durably recorded writes in all replicas, and pending reads at readers.
- Invariants: The majority of invariant coverage is provided by a standard assert framework developers are already familiar with (e.g. XCHECK in the folly library). This is supplemented by more expensive and comprehensive state validation routines that are built into the test harness. Because the entire system state is available for introspection and frozen by the serialized executor when these checks are made, correctness tests that would be impossible or too expensive to perform on the production system can be developed.
- Coverage: The production code is instrumented with various stats for operational observability. We use these same stats to check that events and conditions of known interest have occurred in the test. For example, a leader was activated, the replica membership for a leader has changed, records were delivered to readers while the cluster was operating at minimum quorum, readers reached the end of available data and waited until new writes arrived, and so on.
Making this Scale

The simulation is single-threaded, which significantly limits the speed of state space coverage for any given run. Fortunately, even the most basic computer used by developers has multiple CPU cores, allowing coverage to be increased by simply running multiple simulations, each with a different starting seed, in parallel. Coverage can be further increased by dispatching the test to a larger fleet of machines that are dedicated to Continuous Integration style testing.
To further shorten the feedback cycle for developers, we tweak the test harness to allow it to focus on areas of immediate interest (represented by the circles in Figure 9). A developer working on changes to the consensus protocol used between a Leader and its Replicas to guarantee event ordering can select a package of event types and probabilities tailored to giving good coverage to that portion of the codebase. This avoids wasting simulation time on areas of the system that are unlikely to have been affected by their work. Once the change passes targeted testing, it is subjected to a more comprehensive test designed to ensure overlapping coverage and catch defects that are only visible with longer, wider ranging, failure chains.
How valuable is this type of testing? A team of four engineers recently spent almost two years building a new distributed system at Meta. Given the types of defects caught, we estimate that employing just this testing approach (i.e., not counting unit and integration tests that were also developed) was equivalent to adding two more engineers to the project. This value proposition is reinforced every time a new regression is caught as development continues today.
Certainly, adopting this strategy is easier if you commit to using it from the start of development. In this situation, the added cost is just in developing the test harness, mocks, and a specialized executor. For the system described above—if we don’t count the corpus of validation functions that will naturally grow over time in response to test escapes and improved understanding of the software—it’s less than 5k lines of test code.
Even on existing systems, test coverage can be introduced incrementally as components are modified to run within the simulation environment. Partial system coverage can provide large benefits if you focus on the most critical functions in the system first.
Summing it Up

My time working on avionics led me to the surprising conclusion—at least for me at that time—that investments in reliability enable consistent delivery of better software, in less time. Achieving these results requires creating a software development culture that both holds teams accountable for consistent performance against reliability requirements and aligns incentives with reliability goals. Based on my experience, shifting away from the status quo, entrenched in the “conventional wisdom” that reliability work always forces some tradeoff with other business objectives, can be difficult. But I hope the story I’ve told here will help you to dispel the mythical “false economy” of how your teams are currently executing, and allow you to reap the benefits of moving a bit to the right on the reliability spectrum.

“Building Meta’s GenAI Infrastructure” Engineering at Meta Blog, March 12, 2024
At Meta, our rightward march continues. The ever increasing levels of scale of our systems amplify the consequences of failures. Achieving our long-term goals is possible only with highly reliable software, so we are continuously investing in all aspects of the software lifecycle to meet this reliability challenge. I encourage you to review our current progress we are sharing today at Reliability@Scale 2024, and to look out for future updates as we progress on this journey.
About the Author
Justin T. Gibbs has spent the last nine years working on distributed infrastructure systems at Meta. His diverse industry experience spans embedded and low-level systems development (FreeBSD’s I/O stack, the ZFS file system, SMB/NAS servers), real-time systems (avionics display and autopilot control, video storage and playback), and user-facing applications (Microsoft PowerPoint). Justin also founded the FreeBSD Foundation, a 501(c)3 non-profit supporting the FreeBSD platform, and currently serves as its president.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}