





Additional Authors: Jocelyn Luizzi and Jingbo Yang
Android development at Meta has been Kotlin-first since 2020, and developers have been saying they prefer Kotlin as a language for even longer.
Adoption doesn’t necessarily entail translation, though; we could simply decide to write all new code in Kotlin and leave our existing Java as is, just as many other companies have. Or we could take it a little further and translate just the most important files. Instead, we decided that the only way to leverage the full value of Kotlin was to go all in on conversion, even if it meant building our own infrastructure to automate translation at scale. So, a few years ago, engineers at Meta decided to take roughly ten million lines of perfectly good Java code and rewrite them in Kotlin.
Of course, we had to solve problems beyond translation, such as slow build speeds and insufficient linters. To learn more about Meta’s broader adoption effort, see Omer Strulovich’s 2022 blog post or Lisa Watkin’s talk about adoption at Instagram.
How much translation is enough?
To maximize our gains in developer productivity and null safety, we’re aiming to translate virtually all of our actively developed code, plus any code that’s central in the dependency graph. Not surprisingly, that’s most of our code, which adds up to tens of millions of lines, including some of the most complex files.
It’s pretty intuitive that if we want to maximize productivity gains, we should translate our actively developed code. It’s a little less obvious why translating beyond that provides incremental null-safety benefits. The short answer is that any remaining Java code can be an agent of nullability chaos, especially if it’s not null safe and even more so if it’s central to the dependency graph. (For a more detailed explanation, see the section below on null safety.)
We also want to minimize the drawbacks of a mixed codebase. As long as we have substantial amounts of Java, we need to continue supporting parallel tool chains. There’s also the much-lamented issue of slower build speeds: Compiling Kotlin is slower than compiling Java, but compiling both together is the slowest of all.
How did we get here?
Like most folks in the industry, we started migrating incrementally by repeatedly clicking a button in the Intellij IDE. This button would trigger Intellij’s translation tool, commonly known as “J2K.” It became clear quickly that this approach wasn’t going to scale for a codebase of our size: We would have to click that button—and then wait the couple of minutes it takes to run—almost 100,000 times to translate our Android codebase.
With this in mind, we set out to automate the conversion process and minimize interference with our developers’ daily work. The result was a tool we call the “Kotlinator” that we built around J2K. It’s now comprised of six phases:
- “Deep” build: Building the code we’re about to translate helps the IDE resolve all the symbols, especially when third-party dependencies or generated code are involved.
- Preprocessing: This phase is built on top of our custom tool, Editus. It contains about 50 steps for nullability, J2K workarounds, changes to support our custom DI framework, and more.
- Headless J2K: The J2K we know and love, but server-friendly!
- Postprocessing: This phase is similar in architecture to our preprocessing. It consists of about 150 steps for Android-specific changes, as well as more nullability changes, and tweaks to make the resulting Kotlin more idiomatic.
- Linters: Running our linters with autofixes allows us to implement perennial fixes in a way that benefits both conversion diffs and regular diffs going forward.
- Build error-based fixes: Finally, the Kotlinator makes even more fixes based on build errors. After a failed build of the just-translated code, we parse the errors and apply further fixes (e.g., adding a missing import or inserting a !!).
We’ll dive into more detail on the most interesting phases below.
Going headless with J2K
The first step was creating a headless version of J2K that could run on a remote machine—not easy, given how tightly coupled J2K and the rest of the Intellij IDE are. We considered a few approaches, including running J2K using a setup similar to Intellij’s testing environment, but after talking to JetBrains’ J2K expert, Ilya Kirillov, we eventually settled on something more like a headless inspection. To implement this approach, we created an Intellij plugin that includes a class extending ApplicationStarter and calling directly into the JavaToKotlinConverter class that’s also referenced by the IDE’s conversion button.
On top of not blocking developers’ local IDEs, the headless approach allowed us to translate multiple files at once, and it unblocked all sorts of helpful but time-consuming steps, like the “build and fix errors” process detailed below. Overall conversion time grew longer (a typical remote conversion now takes about 30 minutes to run), but time spent by the developers decreased substantially.
Of course, going headless presents another conundrum: If developers aren’t clicking the button themselves, who decides what to translate, and how does it get reviewed and shipped? The answer turned out to be pretty easy: Meta has an internal system that allows developers to set up what is essentially a cron job that produces a daily batch of “diffs” (our version of pull requests) based on user-defined selection criteria. This system also helps choose relevant reviewers, ensures that tests and other validations pass, and ships the diff once it’s approved by a human. We also offer a web UI for developers to trigger a remote conversion of a specific file or module; behind the scenes, it runs the same process as the cron job.
As for choosing what and when to translate, we don’t enforce any particular order beyond prioritizing actively developed files. At this point, the Kotlinator is sophisticated enough to handle most compatibility changes required in external files (for example, changing Kotlin dependents’ references of foo.getName() to foo.name), so there’s no need to order our translations based on the dependency graph.
Adding custom pre- and post-conversion steps
Due to the size of our codebase and the custom frameworks we use, the vast majority of conversion diffs produced by the vanilla J2K would not build. To address this problem, we added two custom phases to our conversion process, preprocessing and postprocessing. Both phases contain dozens of steps that take in the file being translated, analyze it (and sometimes its dependencies and dependents, too), and perform a Java->Java or Kotlin->Kotlin transformation if needed. A few of our postprocessing transformations have been open-sourced here.
These custom translation steps are built on top of an internal metaprogramming tool that leverages Jetbrains’ PSI libraries for both Java and Kotlin. Unlike most metaprogramming tools, it is very much not a compiler plugin, so it can analyze “broken” code across both languages, and does so very quickly. This is especially helpful for postprocessing because it’s often running on code with compilation errors, doing analysis that requires type information. Some postprocessing steps that deal with dependents may need to resolve symbols across several thousand unbuildable Java and Kotlin files. For example, one of our postprocessing steps helps translate interfaces by examining its Kotlin implementers and updating overridden getter functions to instead be overridden properties, like in the example below.
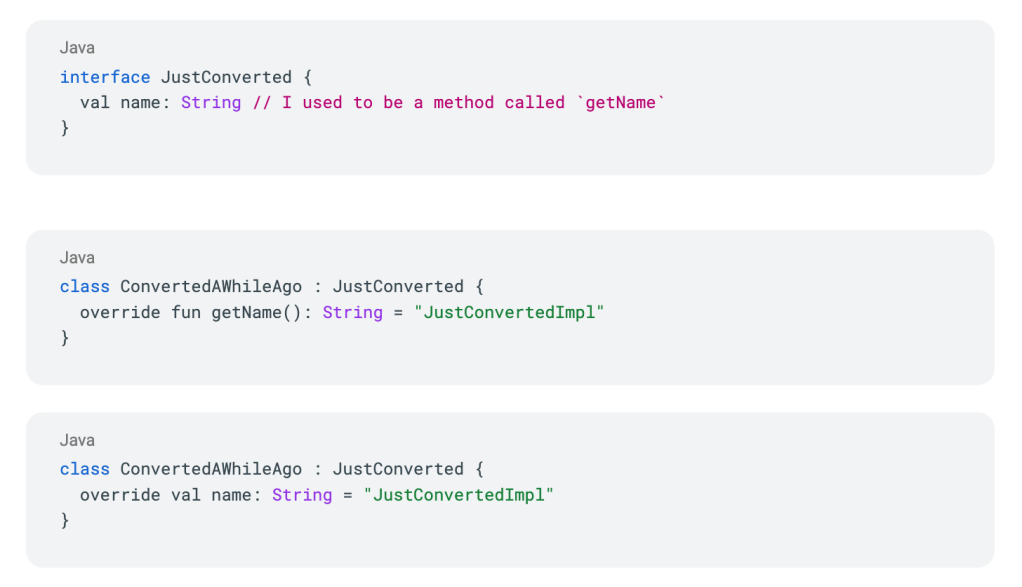
The downside to this tool’s speed and flexibility is that it can’t always provide answers about type information, especially when symbols are defined in third-party libraries. In those cases, it bails quickly and obviously, so we don’t execute a transformation with false confidence. The resulting Kotlin code might not build, but the appropriate fix is usually pretty obvious to a human (if a little tedious).
Originally we added these custom phases to reduce developer effort, but over time we also leveraged them to reduce developer unreliability. Contrary to popular belief, we’ve found it’s often safer to leave the most delicate transformations to bots. There are certain fixes we’ve automated as part of postprocessing, even though they aren’t strictly necessary, because we want to minimize the temptation for human (i.e., error-prone) intervention. One example is condensing long chains of null checks: The resulting Kotlin code isn’t more correct, but it’s less susceptible to a well-meaning developer accidentally dropping a negation.
Leveraging build errors
In the course of doing our own conversions, we noticed that we spent a lot of time at the end repeatedly building and fixing our code based on the compiler’s error messages. In theory, we could fix many of these problems in our custom postprocessing, but doing so would require us to reimplement a lot of complex logic that’s baked into the Kotlin compiler.
Instead, we added a new, final step in the Kotlinator that leverages the compiler’s error messages the same way a human would. Like postprocessing, these fixes are performed with a metaprogramming that can analyze unbuildable code.
The limitations of custom tooling
Between the preprocessing, postprocessing, and post-build phases, the Kotlinator contains well over 200 custom steps. Unfortunately, some conversion issues simply can’t be solved by adding even more steps.
Originally we treated J2K as a black box—even though it was open sourced—because its code was complex and not actively developed; diving in and submitting PRs didn’t seem worth the effort. That changed early in 2024, however, when JetBrains began work to make J2K compatible with the new Kotlin compiler, K2. We took the opportunity to work with JetBrains to improve J2K and address problems that had been plaguing us for years, such as disappearing override keywords.
Collaborating with JetBrains also gave us the opportunity to insert hooks into J2K that would allow clients like Meta to run their own custom steps directly in the IDE before and after conversion. This may sound strange, given the number of custom processing steps we’ve already written, but there are a couple of major benefits:
- Improved symbol resolution. Our custom symbol resolution is fast and flexible, but it’s less precise than J2K’s, especially when it comes to resolving symbols defined in third-party libraries. Porting some of our preprocessing and postprocessing steps over to leverage J2K’s extension points will make them more accurate, and allow us to use Intellij’s more sophisticated static-analysis tooling.
- Easier open sourcing and collaboration. Some of our custom steps are too Android-specific to be incorporated into J2K but might still be useful to other companies. Unfortunately, most of them depend on our custom symbol resolution. Porting these steps over to instead rely on J2K’s symbol resolution gives us the option to open-source them and benefit from the community’s pooled efforts.
But first, null safety!
In order to translate our code without spewing null-pointer exceptions (NPEs) everywhere, it first needs to be null safe (by “null safe” we mean code checked by a static analyzer such as Nullsafe or NullAway). Null safety still isn’t sufficient to eliminate the possibility of NPEs, but it’s an excellent start. Unfortunately, making code null safe is easier said than done.
Even null-safe Java throws NPEs sometimes
Anyone who has worked with null-safe Java code long enough knows that while it’s more reliable than vanilla Java code, it’s still prone to NPEs. Unfortunately static analysis is only 100% effective for 100% code coverage, which is simply not viable in any large mobile codebase that interacts with the server and third-party libraries.
Here’s a canonical example of a seemingly innocuous change that can introduce an NPE:
MyNullsafeClass.java

Say there are a dozen dependents that call MyNullsafeJava::doThing. A single non-null-safe dependent could pass in a null argument (for example, MyNullsafeJava().doThing(null)), which would lead to an NPE if a dereference is inserted in the body of doThing.
Of course, while we can’t eliminate NPEs in Java via null-safety coverage, we can greatly reduce their frequency. In the example above, NPEs are possible but fairly rare when there’s only one non-null-safe dependent. If multiple transitive dependents lacked null safety, or if one of the more central dependent nodes did, the NPE risk would be much higher.
What makes Kotlin different
The biggest difference between Null-safe Java and Kotlin is the presence of runtime validation in Kotlin bytecode at the interlanguage boundary. This validation is invisible but powerful because it allows developers to trust the stated nullability annotations in any code they’re modifying or calling.
If we return to our earlier example, MyNullsafeClass.java, and translate it to Kotlin, we get something like:
MyNullsafeClass.kt

Now there’s an invisible checkNotNull(s) in the bytecode at the start of doThing’s body, so we can safely add a dereference to s, because if s were nullable, this code would already be crashing. As you can imagine, this certainty makes for much smoother, safer development.
There are also some differences at the static analysis level: The Kotlin compiler enforces a slightly stricter set of null safety rules than Nullsafe does when it comes to concurrency. More specifically, the Kotlin compiler throws an error for dereferences of class-level properties that could have been set to null in another thread. This difference isn’t terribly important to us, but it does lead to more !! than one might expect when translating null-safe code.
Great, let’s translate it all to Kotlin!
Not so fast. As is always the case, going from more ambiguity to less ambiguity doesn’t come for free. For a case like MyNullsafeClass, development is much easier after Kotlin translation, but someone has to take that initial risk of effectively inserting a nonnull assertion for its hopefully-really-not-nullable parameter s. That “someone” is whichever developer or bot ends up shipping the Kotlin conversion.
We can take a number of steps to minimize the risk of introducing new NPEs during conversion, the simplest of which is erring on the side of “more nullable” when translating parameters and return types. In the case of MyNullsafeClass, the Kotlinator would have used context clues (in this case, the absence of any dereferences in the body of doThing) to infer that String s should be translated to s: String?.
One of the changes we ask developers to scrutinize most when reviewing conversion diffs is the addition of !! outside of preexisting dereferences. Funnily enough, we’re not worried about an expression like foo!!.name, because it’s not any more likely to crash in Kotlin than it was in Java. An expression such as someMethodDefinedInJava(foo!!) is much more concerning, however, because it’s possible that someMethodDefinedInJava is simply missing a @Nullable on its parameter, and so adding !! will introduce a very unnecessary NPE.
To avoid problems like adding unnecessary !! during conversion, we run over a dozen complementary codemods that comb through the codebase looking for parameters, return types, and member variables that might be missing @Nullable. More accurate nullability across the codebase—even in Java files that we may never translate—is not only safer, it’s also conducive to more successful conversions, especially as we approach the final stretch in this project.
Of course, the last remaining null-safety issues in our Java code have usually stuck around because they’re very hard to solve. Previous attempts to resolve them relied mostly on static analysis, so we decided to borrow an idea from the Kotlin compiler and create a Java compiler plugin that helps us collect runtime nullability data. This plugin allows us to collect data on all return types and parameters that are receiving/returning a null value and are not annotated as such. Whether these are from Java/Kotlin interop or classes that were annotated incorrectly at a local level, we can determine ultimate sources of truth and use codemods to finally fix the annotations.
Other ways to break your code
On top of the risks of regressing null safety, there are dozens of other ways to break your code during conversion. In the course of shipping over 40,000 conversions, we’ve learned about many of these the hard way and now have several layers of validation to prevent them. Here are a couple of our favorites:
Confusing initialization with getters

Nullable booleans

The fun part
At this point, more than half of Meta’s Android Java code has been translated to Kotlin (or, more rarely, deleted). But that was the easy half! The really fun part lies ahead of us, and it’s a doozy. There are still thousands of fully automated conversions we hope to unblock by adding and refining custom steps and by contributing to J2K. And there are thousands more semi-automated conversions we hope to ship smoothly and safely as a result of other Kotlinator improvements.
Many of the problems we face also affect other companies translating their Android codebases. If this sounds like you, we’d love for you to leverage our fixes and share some of your own. Come chat with us and others in the #j2k channel of the Kotlinlang Slack.

