EVENT AGENDA
Event times below are displayed in PT.
November 23-24: AI @Scale is an invitation-only technical conference designed for engineers interested in solving machine learning scaling problems. Topics to be discussed at this year’s virtual conference include: latency improvements for training workflows; how to improve the resiliency of ML training; improving the developer experience for ML engineers; and scaling, sustaining model quality, machine efficiency, among others. The AI @Scale community focuses on bringing people together to discuss these challenges, share ideas and collaborate.
Event times below are displayed in PT.
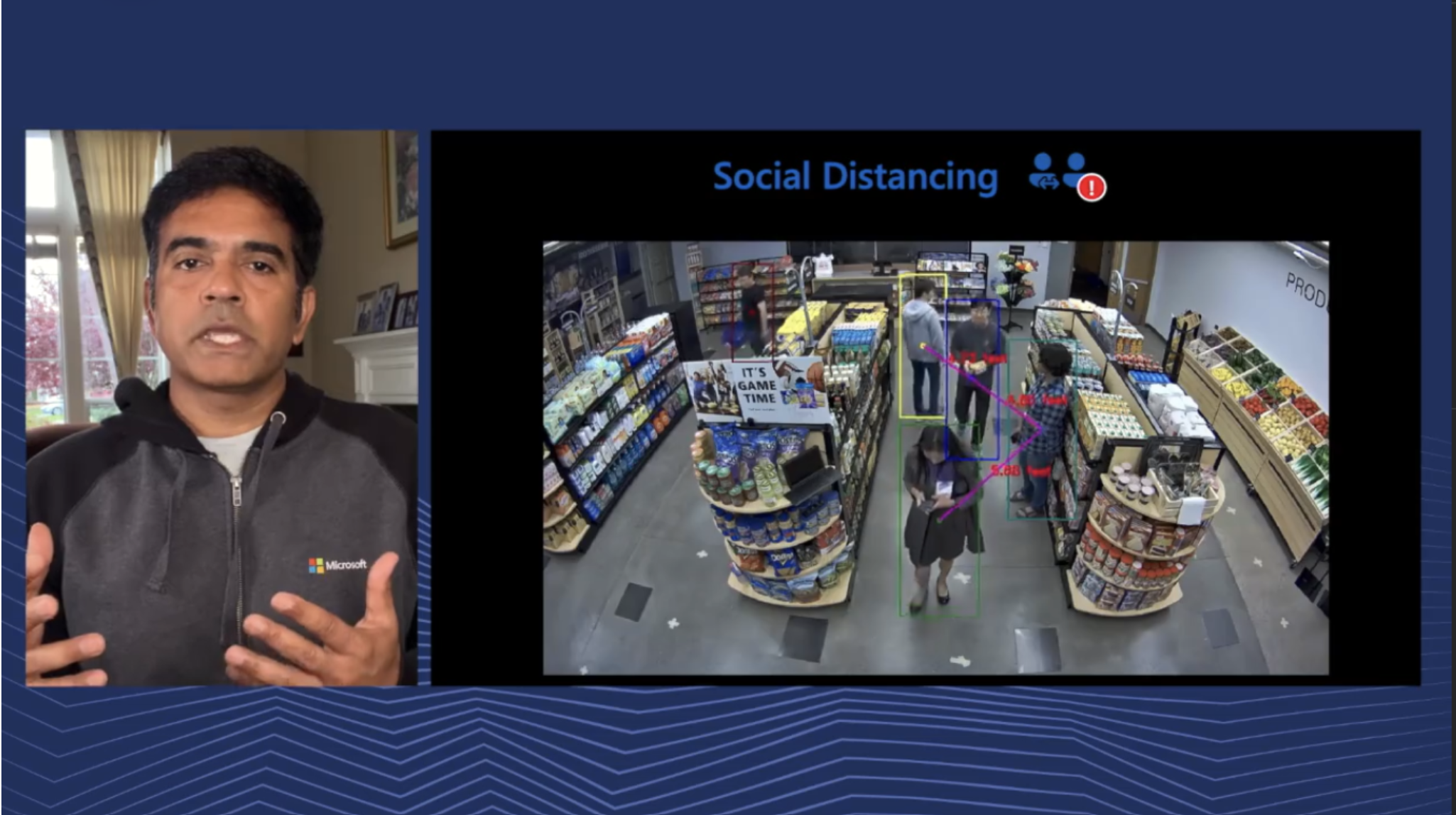
Azure Cognitive Services sits at the core of many essential products and services at Microsoft for internal and external workloads. Anand’s talk describes the hardware and software infrastructure that supports Ai services at global scale. Azure Cognitive Services workloads are extremely diverse: services require many different types of models in practice. This diversity has implications at all layers in the system stack. In addition, the computational requirements are also intense, leveraging both GPUs and CPUs for real-time inference. Addressing these and other emerging challenges continues to require diverse efforts that span algorithms, software, and hardware design. In this talk, Anand also walks through some of the challenges, including data privacy, deep customization, and bias correction, and discusses solutions they have built to tackle these challenges.

The scale and breadth of ML applications have increased dramatically thanks to scalable model-training and serving technologies. Builders of enterprise ML systems often have to contend with both real-time inference and massive amounts of data, prompting increasing investment in tools for MLOps and ML Observability. Data logging is a critical component of a robust ML pipeline, as it provides essential insights into the system’s health and performance. However, performant logging and monitoring for ML systems has proven ineffective within existing DevOps and data sampling approaches. Alessya will discuss the WhyLabs solution to this problem: using statistical fingerprinting and data profiling to scale to TB-sized data with an open-source data logging library, whylogs. She will present the WhyLabs Observability platform that runs on top of whylogs, providing out-of-the-box monitoring and anomaly detection to proactively address data-related failures across the entire ML lifecycle.

We will discuss the next generation feature framework in development at Facebook. This new framework enables efficient experimentation in building machine learning features to semantically model behaviors and intent of users, and leverages compiler technology to unify batch and streaming processing of these features in an expressive language. It also automatically optimizes underlying data pipelines and applies privacy enforcement at scale.





Netflix's unique culture affords it's data scientists extraordinary freedom of choice in ML tools and libraries. At the same time, they are responsible for building, deploying, and operating complex ML workflows autonomously without the need to be significantly experienced with systems or data engineering.
Metaflow, our ML framework (now open-source at metaflow.org), provides them with delightful abstractions to manage their project's lifecycle end-to-end, leveraging the strengths of the cloud: elastic compute and high-throughput storage.
In this talk, we present our human-centric design principles that enable the autonomy our users enjoy.
Google BigQuery is a petabyte-scale serverless cloud data warehouse that enables scalable machine learning using SQL. In this talk, we take a look at how enabling data analysts and other SQL users to perform machine learning tasks can accelerate business decision-making and intelligence. We also present challenges in democratizing ML in large scale data warehouses such as BigQuery. We describe how a combination of general purpose SQL query engine and dedicated machine learning infrastructure can create a robust infrastructure for performing machine learning tasks.

We will discuss a novel model development process and tools we introduced to ads ranking machine learning teams, where a single model can be concurrently developed by dozens of engineers, whose changes to the model are centralized collected, combined, tested and launched.


Google BigQuery is a petabyte-scale serverless cloud data warehouse that enables scalable machine learning using SQL. In this talk, we take a look at how enabling data analysts and other SQL users to perform machine learning tasks can accelerate business decision-making and intelligence. We also present challenges in democratizing ML in large scale data warehouses such as BigQuery. We describe how a combination of general purpose SQL query engine and dedicated machine learning infrastructure can create a robust infrastructure for performing machine learning tasks.

Flyte is the backbone for large-scale Machine Learning and Data Processing (ETL) pipelines at Lyft. It is used across business critical applications ranging from ETA, Pricing, Mapping, Autonomous etc. At its core it is a Kubernetes native workflow engine that executes 1M+ pipelines and 40M+ containers per month.
Flyte abstracts complex infrastructure management from its users and provides a declarative fabric to connect disparate compute technologies. This increases productivity and thus product velocity by enabling them to focus on business logic. Flyte has made it possible to build higher-level platforms at Lyft, further reducing the barriers to entry for non-infrastructure engineers.
The talk will focus on:
Motivation and tenets for building Flyte, and parts of the Data Stack tackled by it.
Architecture of Flyte and its specification language to orchestrate compute and manage data flow across disparate systems like Spark, Flink, Tensorflow, Hive etc.
Use-cases where Flyte can be leveraged
Extensibility of the Flyte and the burgeoning ecosystem.












Ketan Umare is the TSC Chair for Flyte (incubating under LF AI & Data).... read more