- WATCH NOW
- 2025 EVENTS
- PAST EVENTS
- 2024
- 2023
- 2022
- February
- RTC @Scale 2022
- March
- Systems @Scale Spring 2022
- April
- Product @Scale Spring 2022
- May
- Data @Scale Spring 2022
- June
- Systems @Scale Summer 2022
- Networking @Scale Summer 2022
- August
- Reliability @Scale Summer 2022
- September
- AI @Scale 2022
- November
- Networking @Scale Fall 2022
- Video @Scale Fall 2022
- December
- Systems @Scale Winter 2022
- 2021
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- Blog & Video Archive
- Speaker Submissions







Systems @Scale Summer 2022
JUNE 08, 2022 @ 10:00 AM PDT - 12:05 PM PDT
JUNE 15, 2022 @ 10:00 AM PDT - 11:50 AM PDT
JUNE 22, 2022 @ 10:00 AM PDT - 11:30 AM PDT
JUNE 29, 2022 @ 10:00 AM PDT - 11:30 AM PDT
Designed for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges.
ABOUT EVENT
Systems @Scale Summer 2022 is a technical conference for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The Systems @Scale Summer 2022 series will be hosted virtually. Joining us are speakers from Alibaba, Confluent, Google, HashiCorp, Meta, Microsoft, and Rockset. The event spans four weeks, with talks themed around performance, reliability, efficiency, and managing services at scale.
Starting June 8th, for four weeks, we will livestream a recorded session followed by live Q&A sessions on Wednesdays.
Week 1 – June 8: Performance, Reliability, and Efficiency
Week 2 – June 15: Reliability
Week 3 – June 22: Managing Services: Part 1
Week 4 – June 29: Managing Services: Part 2
June 8
Performance, Reliability, and Efficiency
June 15
Reliability
June 22
Managing Services: Part 1
June 29
Managing Services: Part 2
SPEAKERS AND MODERATORS
My name is Lu Pan. I am a Software Engineer at Meta. During my... read more

Lu Pan
Meta
Jun Rao is a co-founder of Confluent, a company that provides an event streaming... read more
Jun Rao
Confluent
I am a software engineering manager supporting the ZooKeeper team within Meta. I have... read more
Ali Zaveri
Meta
I am a Software Engineer at Meta working on building control plane storage systems.... read more
Suyog Mapara
Meta
Rakesh leads the Azure Database for PostgreSQL Flexible and Single server engineering teams at... read more
Rakesh Gujjula
Microsoft
I’m an Engineering Manager at Meta, based in Seattle. Currently I support the Serverless... read more
Ernesto Gonzalez
Meta
Fred Lin is a data science manager at Meta, focusing on sustaining a large-scale... read more
Fred Lin
Meta
Huiba Li is a senior staff engineer at Alibaba Cloud where he has worked... read more
Huiba Li
Alibaba
Kewei is a software engineer at Meta. She works on App Health including reliability,... read more
Kewei Qu
Meta
Craig Box leads Developer Relations for service mesh at Google Cloud. He has worked... read more
Craig Box
Google
Sam Naser is a Software Engineer at Google working on service mesh technologies and... read more
Sam Naser
Google
Amaya Booker is a senior Technical Program Manager in Core Systems at Meta specialising... read more
Amaya Booker
Meta
Joseph is a Production Engineer at Meta. He works in the Ads and Business... read more
Joseph Eley
Meta
Nathan Bronson is a software engineer at Rockset. He is currently focused on query... read more
Nathan Bronson
Rockset
Louis Brandy is currently Director of Engineering at Rockset. Prior to Rockset, Louis was... read more
Louis Brandy
Rockset
Hi there, I'm Patricia McKenzie and I'm a software engineer at Meta. I grew... read more
Patricia McKenzie
Meta
Hi! I've been working at Meta as a Software Engineer for nearly five years... read more
Rohit Ahuja
Meta
Sherry is an engineering manager supporting Efficiency Management Frameworks, FBDetect, and Host Software Efficiency... read more
Sherry Chen
Meta
David is a Software Engineer at Meta helping build our next-generation service platform. He... read more
David Meisner
Meta
As a developer advocate for HashiCorp, Rosemary Wang works to bridge the technical and... read more
Rosemary Wang
HashiCorp
I work on Tupperware (externally called Twine), Meta's cluster management system and container deployment... read more
Kenny Yu
Meta
Ranjith works on building automation for fungible capacity management. He is passionate about distributed... read more
Ranjith Kumar S
Meta
Yun Jin is an Engineering Director in Meta's Core Systems organization, which builds the... read more
Yun Jin
Meta
EVENT AGENDA
Event times below are displayed in PT.
June 8
Performance, Reliability, and Efficiency
June 15
Reliability
June 22
Managing Services: Part 1
June 29
Managing Services: Part 2
June 8
Performance, Reliability, and Efficiency
10:00 AM
-
10:25 AM
Cache Made Consistent – Cache invalidation might no longer be a hard thing in Computer Science

Cache invalidation is considered one of the hardest things in Computer Science. We, at Meta, operate some of the world's largest cache deployments (e.g. Memcache and TAO), serving more than one quadrillion queries a day. We have developed a systemic approach at diagnosing inconsistencies from cache invalidations at scale.

Speaker
Lu Pan,Meta
10:25 AM
-
10:50 AM
Leveraging Data in Motion in a Cloud-first World

Apache Kafka has emerged to the de-facto standard for event streaming platform in enterprise architectures. Many business applications are moving away from data-at-rest to an event-driven architecture so that they could leverage the data in real time as new events occur. More than 80% of the Fortune 100 are building their businesses on this new platform. In this talk, I will first share the story behind Kafka: how it was invented, what problem it was trying to solve and how it has been evolving. Then, I will talk about how making Kafka Cloud native creates new opportunities for building a system of record and some real world use cases.

Speaker
Jun Rao,Confluent
10:50 AM
-
11:15 AM
Introducing Zelos - Zookeeper API leveraging Delos
In this presentation we will introduce Zelos. Zelos provides the exact same semantics as ZooKeeper but is built using Delos. ZooKeeper forms the foundation of Meta's infrastructure stack and we have been using it over a decade. Over the decade we have improved the performance of ZooKeeper to meet our scale requirement but every such improvement has been non trivial amount of work especially given the monolithic design of ZooKeeper. In this talk we will deep dive into Zelos's architecture and show how it enables to solve some of the scaling limits we were hitting with ZooKeeper. Migrating with 0 downtime has been an important goal and we will give an overview on how we went about doing it.

Speaker
Ali Zaveri,Meta

Speaker
Suyog Mapara,Meta
11:15 AM
-
11:35 AM
Hosting Open Source Relational Databases at Scale on Microsoft Azure
Hosting managed relational database services in the cloud with the level of availability, reliability guarantees demanded by mission critical workloads and doing it at scale presents a set of interesting challenges. This talk will walk you through the evolution journey of Open Source relational database services hosting platform on Azure and how these challenges were addressed while meeting the agility, performance, stability, and cost goals from the business and customers

Speaker
Rakesh Gujjula,Microsoft
11:35 AM
-
12:05 PM
Live Q&A Session


10:00 AM
-
10:20 AM
How Meta Keeps its Large-scale Infrastructure Hardware Up and Running

Internet services like Facebook, Instagram, and Whatsapp rely on large-scale infrastructure to support the various compute, storage, and AI workloads. With the support of data and ML techniques, we can scale our infrastructure successfully by improving the efficiency of our tooling and workflows. In this presentation we’ll share our recent work on hardware remediation, automated anomaly detection and root cause analysis, error reporting interrupt tuning for minimizing performance overhead, near-real time at-scale server reboot detection, and an ML framework for predicting repairs for hardware failures. The data and ML solutions help us engage people less but with more context, so we can focus people on the real challenging work while the repetitive tasks are automated.

Speaker
Fred Lin,Meta
10:20 AM
-
10:40 AM
DADI @ Scale: Deploying Containers at Scale in Alibaba

Alibaba Cloud offers a comprehensive suite of elastic computing services that are based on container technology. Alibaba Group is one of the key customers of Alibaba Cloud and all of the major applca- tions across its large and diverse set of businesses are run in containers. In this talk, we present DADI, the image system that underpins Al- ibaba’s containers, and share our experience with deploying it at scale worldwide to serve all of Alibaba Group and a large and rapidly grow- ing number of external customers on the Alibaba Cloud. DADI is a block-level image system that replaces the waterfall model of starting containers (downloading image, unpacking image, starting container) with fine-grained on-demand transfer of remote images, realizing in- stant start of containers. DADI relies on a peer-to-peer architecture in large clusters to balance network traffic among all the participat- ing hosts. One of the unique features of DADI is that it is based on the standard block device so that the image system is file system and platform agnostic, enabling one image system to handle the many ap- plication and container platforms that inevitably span very large orga- nizations including Alibaba. The system is high-extensible, allowing us to quickly add features including trace-based prefetching and custom acceleration of container provisioning for different computing services such as serverless computing or Function-as-a-Service (FaaS). As part of this talk, we highlight the ease with which DADI can support new container technologies including those based on Kata Containers, fire- cacker and gVisor. We conclude with a discussion of ongoing efforts towards more secure containers by leveraging the small attack surface of the DADI block device, and decrypting the container image only within the container.

Speaker
Huiba Li,Alibaba
10:40 AM
-
11:00 AM
Scaling End to End Reliability Tracking Across Large Scale, Multiplexed Products and Services
This talk introduces a new user experience-focused reliability measurement that exposes end-to-end reliability guarantees across the vertical service stack used by Meta’s family of Apps. The talk discusses the difference between the new reliability approach versus the industry standard and our successes and what comes next.

Speaker
Kewei Qu,Meta
11:00 AM
-
11:20 AM
Don't Ship the Org Chart: Rebuilding Istio for User Maintainability

While the cry of "breaking apart the monolith" can be heard throughout the industry, the Istio service mesh took a different tack, and consolidated its control plane microservices into one binary. How did we get here? In this talk, Google DA and Istio Steering Committee member Craig Box will talk about how the team building the service mesh designed it based on the internal Google services it was emulating, why that turned out to be the wrong choice, and how the ship was righted. Google engineer and Istio Environments working group lead Sam Naser will talk about how the new model allows for safer upgrades of the mesh, letting users test new versions with a canary model before rolling out to the whole fleet.

Speaker
Craig Box,Google

Speaker
Sam Naser,Google
11:20 AM
-
11:50 AM
Live Q&A Session


10:00 AM
-
10:20 AM
Configuration Safety at Scale with Ads
The Configerator repository provides Meta developers with a way to make changes easily and quickly to production services. By default, it pushes changes to all services at Meta in a matter of seconds, and doesn’t have the traditional safeguards that most services have of being able to do extensive testing before releasing a new version of the service. It is one of the main things that enables Meta’s move-fast culture and lets developers iterate quickly and have fast development cycles. However, if not done properly, this can result in many reliability issues. This talk goes over the reliability issues that the Ads organization has had due to these config changes and how we have improved the reliability over time by investing into various safety measures like build time validations, diff-time testing, and helped develop and use a new service that can gradually push config changes.

Speaker
Joseph Eley,Meta
10:20 AM
-
10:40 AM
Getting from Schemaless Ingest to Fast SQL at Rockset
Rockset provides low-latency SQL access to schemaless data that is ingested in real-time. Immediate access to dynamically structured data is very powerful, enabling rapid development and iteration for products built on top, but it needs to be baked into the design and implementation from the start. Rockset’s architecture incorporates ideas from search engines, OLTP databases, and OLAP engines. In this talk we will present some of the database and low-level C++ programming techniques we use to get excellent performance and efficiency over dynamic data.

Speaker
Nathan Bronson,Rockset

Speaker
Louis Brandy,Rockset
10:40 AM
-
11:00 AM
The Ent Framework: Meta’s Object-Relational Mapping

When you think about Meta’s family of apps, what comes to mind? Maybe the over 6 thousand photos and videos created per second on Instagram, the 5 trillion photos on Facebook, or the 60 million group posts loaded each second. It’s challenging to manage all of the associated databases, schemas, queries and constraints at scale like ours. How do we keep this data consistent? How do we handle who can access or read this data in different contexts with different roles and permissions? How do we make it so engineers across teams can easily understand and onboard to another team’s database model? These challenges are why Meta created the Ent Framework, our Object-Relational Mapping layer. The Ent Framework simplifies development for tens of thousands of engineers by automating and simplifying how they integrate with multitudes of different storage systems. Learn about how Meta keeps databases more secure, code less repetitive and the family of apps more robust via the Ent Framework.

Speaker
Patricia McKenzie,Meta

Speaker
Rohit Ahuja,Meta
11:00 AM
-
11:30 AM
Live Q&A Session


10:00 AM
-
10:20 AM
Infra Cloud Service Platform (ICSP)
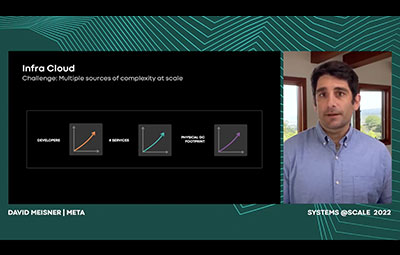
Building and operating a service is challenging and complex. At scale, service owners need to consider a number of responsibilities including how they develop, deploy, scale and monitor their service in production. Each of these concerns may require a service owner to understand, configure, and operate multiple underlying supporting systems to accomplish their goal. Service owners desire a solution that's simpler to develop and manage. Infra Cloud Service Platform (ICSP) is a holistic infrastructure product aimed at reducing the complexity of developing and operating services at Meta. As a platform, ICSP provides an integrated ecosystem that streamlines and orchestrates the pieces for the user. The platform is built on three important pillars: 1) a common configuration and control system (the Control Plane), 2) a logical model of operation (Service Data Model), and 3) code framework (Service Code Experience).

Speaker
David Meisner,Meta
10:20 AM
-
10:40 AM
Lessons Learned from Scaling Infrastructure as Code

You adopted an infrastructure as code tool like Terraform. What started as one person writing some configuration and deploying new infrastructure scales to everyone in the company writing their own infrastructure configuration and deploying their own systems. In this talk, we’ll share some of the lessons learned across the Terraform community when scaling infrastructure as code practices from one team to an entire company and its users. We’ll cover the patterns and practices that help address challenges of updating infrastructure, managing infrastructure modules, maintaining security, streamlining cost, and even upgrading and migrating tools.

Speaker
Rosemary Wang,HashiCorp
10:40 AM
-
11:00 AM
Global Capacity Management at Meta
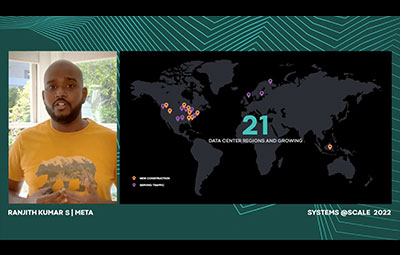
Meta currently operates more than 15 data center regions around the world. This rapidly expanding global datacenter footprint poses new challenges for service owners and for our infrastructure management systems. In this talk, we will present the challenges with managing a global-scale infrastructure and our approach for global service and capacity management. In particular, we’ll focus on the abstractions and guarantees we present to service owners with global capacity, and we’ll walk through our current design and implementation for how we manage our workloads across 10s of regions. We’ll also present our future plans with Infra Cloud as we build towards our longer term vision of transparent automated global capacity management.

Speaker
Kenny Yu,Meta

Speaker
Ranjith Kumar S,Meta
11:00 AM
-
11:30 AM
Live Q&A Session Live Q&A with All Speakers










