- WATCH NOW
- 2025 EVENTS
- PAST EVENTS
- 2024
- 2023
- 2022
- February
- RTC @Scale 2022
- March
- Systems @Scale Spring 2022
- April
- Product @Scale Spring 2022
- May
- Data @Scale Spring 2022
- June
- Systems @Scale Summer 2022
- Networking @Scale Summer 2022
- August
- Reliability @Scale Summer 2022
- September
- AI @Scale 2022
- November
- Networking @Scale Fall 2022
- Video @Scale Fall 2022
- December
- Systems @Scale Winter 2022
- 2021
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- Blog & Video Archive
- Speaker Submissions







Systems @Scale Fall 2021
OCTOBER 13, 2021 @ 9:00 AM PDT - 11:00 AM PDT
OCTOBER 20, 2021 @ 9:00 AM PDT - 10:20 AM PDT
OCTOBER 27, 2021 @ 9:00 AM PDT - 11:00 AM PDT
Designed for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges.
ABOUT EVENT
Systems @Scale is a technical conference for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The 2021 fall series will be hosted virtually. Joining us are speakers from AWS, BigSpring, Confluent, Databricks, Lyft, Twitter, and Facebook. The event spans three weeks, with talks themed around capacity/efficiency, reliability/testing, and challenges at scale in the context of large-scale distributed systems.
Starting October 13th, for three weeks, we will livestream a recorded session followed by live panel discussion on Wednesdays.
October 13
October 20
October 27
SPEAKERS AND MODERATORS
Ippokratis Pandis
Amazon Web Services
Andy Newell
Facebook
Lohit Vijayarenu
Twitter
Akanksha Bansal
Facebook
Richard is an engineer in the Capacity Infrastructure org with a focus on resource... read more
Richard Cornew
Meta
Behrooz Badii
Lyft
Paul Marinescu
Facebook
Arun Nagarajan
BigSpring
Aliisa Roe
BigSpring
Raghunathan Modoor Jagannathan
Facebook
Sulav Malla
Facebook
Parimala Kondety
Facebook
Jos Visser
Confluent
Jasmit Kaur Saluja
Facebook
Dillon George
Facebook
Jeff Pang
Databricks
Tyler Petrochko
Facebook

EVENT AGENDA
Event times below are displayed in PT.
October 13
October 20
October 27
October 13
09:00 AM
-
09:20 AM
Amazon Redshift Reinvented

The success of Amazon Redshift inspired a lot of innovation in the analytics industry which in turn has benefited consumers. In the last few years, the use cases for Amazon Redshift have evolved and in response, Amazon Redshift has delivered a series of innovations that continue to delight customers. In this talk, we take a peek under the hood of Amazon Redshift, and give an overview of its architecture. We focus on the core of the system and explain how Amazon Redshift maintains its differentiating industry-leading performance and scalability. We then talk about Amazon Redshift’s autonomics. In particular, we present how Redshift continuously monitors the system and uses machine learning to improve its performance and operational health without the need of dedicated administration resources. Finally, we discuss how Amazon Redshift extends beyond traditional data warehousing workloads, but integrating with the broad AWS ecosystem making Amazon Redshift a one-stop solution for analytics.

Speaker
Ippokratis Pandis,Amazon Web Services
09:20 AM
-
09:40 AM
RAS: A Resource Allowance System for Perpetual Region-Wide Resource Allocation

Facebook is undergoing a massive design shift in capacity management and service placement to scale the efficiency of our datacenter resources. At the core of this shift is the Resource Allowance System (RAS) that continuously optimizes for the assignment of service demand to capacity supply. RAS ensures available capacity to all services despite challenges of random failures, correlated failures, maintenances, and overloading shared resources. Additionally, the quality of assignment determines how efficiently datacenter resources can be used which is critical at our scale. Please attend to the talk to learn about the challenges we are faced with, and the solution that we have already deployed for 80% of all servers at Facebook.

Speaker
Andy Newell,Facebook
09:40 AM
-
10:00 AM
Log Events @ Twitter: Challenges of Handling Billions of Events Per Minute

At Twitter, hundreds of thousands of microservices emit important events triggered by user interactions on the platform. The Data Platform team has the requirement to aggregate these events by service type and generate consolidated datasets. These datasets are made available at different storage destinations for data processing jobs or analytical queries. In this presentation we discuss the architecture behind supporting event log pipelines which can handle billions of events per minute with data volumes of tens of petabytes of data every day. We discuss our challenges at scale and lay out our solution using both open source and in house software stack. This presentation describes our resource utilization and optimizations we had to do at scale. Towards the end we also introduce our improvements to move our event log pipeline to event stream pipelines. We show a use case which uses these event streams for real time analytics.

Speaker
Lohit Vijayarenu,Twitter
10:00 AM
-
10:20 AM
End-to-End Resource Accounting Leveraging Distributed Tracing

Transitive Resource Accounting (TRA) is a system that builds on top of Facebook’s distributed traces platform, Canopy, with the goal of capturing end-2-end request cost metrics and attributing them back to the originating caller. This data is pivotal in attributing capacity usage and understanding the efficiency of our infrastructure as a whole. Let’s say that a product is going to grow by 20% in the coming year. By how much do its backend service dependencies need to grow to support this added demand? To determine this we must understand what percentage of demand to the dependent services is driven by the product. Attributing this demand becomes increasingly more difficult as a distributed system grows and becomes ever more complex. Service owners can collect service specific data about who is calling them and who they are calling but this is a very narrow view that provides little insight about capacity & efficiency for the system as a whole. With the power of distributed tracing TRA measures the cost of the request from start to finish through every hop in the request path. We can then attribute the source of demand at any depth in the system.
Speaker
Akanksha Bansal,Facebook

Speaker
Richard Cornew,Meta
10:20 AM
-
11:00 AM
Live Q&A Session With Speakers
09:00 AM
-
09:20 AM
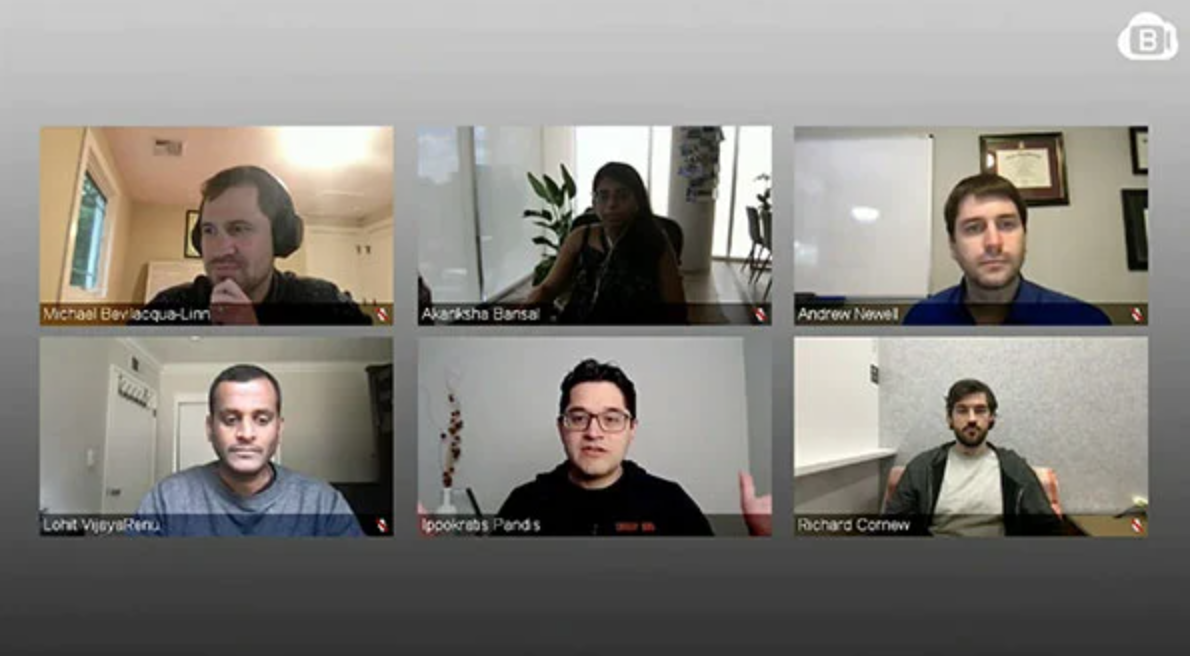
Blaming in a Blameless World
Attribution of reliability in a microservice architecture can be solved, and has been solved, in very different ways due to how services are cataloged across the industry. Our hypothesis at Lyft was that service catalogs can become stale, but ownership derived from an on-call rotation will be significantly more reliable for attribution. We'd like to share our journey through combining Envoy, Pagerduty, and an organizational hierarchy to identify reliability concerns across Lyft through standardized SLOs and Director-level rollups.

Speaker
Behrooz Badii,Lyft
09:20 AM
-
09:40 AM
Automatic Test Generation for Generation for Backend Service at Scale
Developing at speed and scale across Facebook’s many services requires testing frameworks that help developers iterate on features quickly and with minimal friction, while helping to catch bugs early. Learn why we’ve built our own integration testing framework for services and how we combine it with ideas from fuzzing to enable fully autonomous testing.

Speaker
Paul Marinescu,Facebook
09:40 AM
-
10:00 AM
Scaling Testing at a Startup: Integration Testing GraphQL Services with Jest

BigSpring is a mobile first platform for lifelong skilling with measurable ROI. We use GraphQL to power our services. We would love to talk about how we use Jest to integration test our resolvers and other business logic built in our TypeScript Node.js code base. We'll cover how we setup test data, mock connections and collect code coverage as part of our CI/CD process on Github Actions. Being a global and a business critical app, reliability and development velocity is key and we hope to share some hard earned lessons in introducing comprehensive testing to an existing GraphQL repo.

Speaker
Arun Nagarajan,BigSpring

Speaker
Aliisa Roe,BigSpring
10:00 AM
-
10:20 AM
Power Loss Siren: Making Facebook Resilient to Power Outages
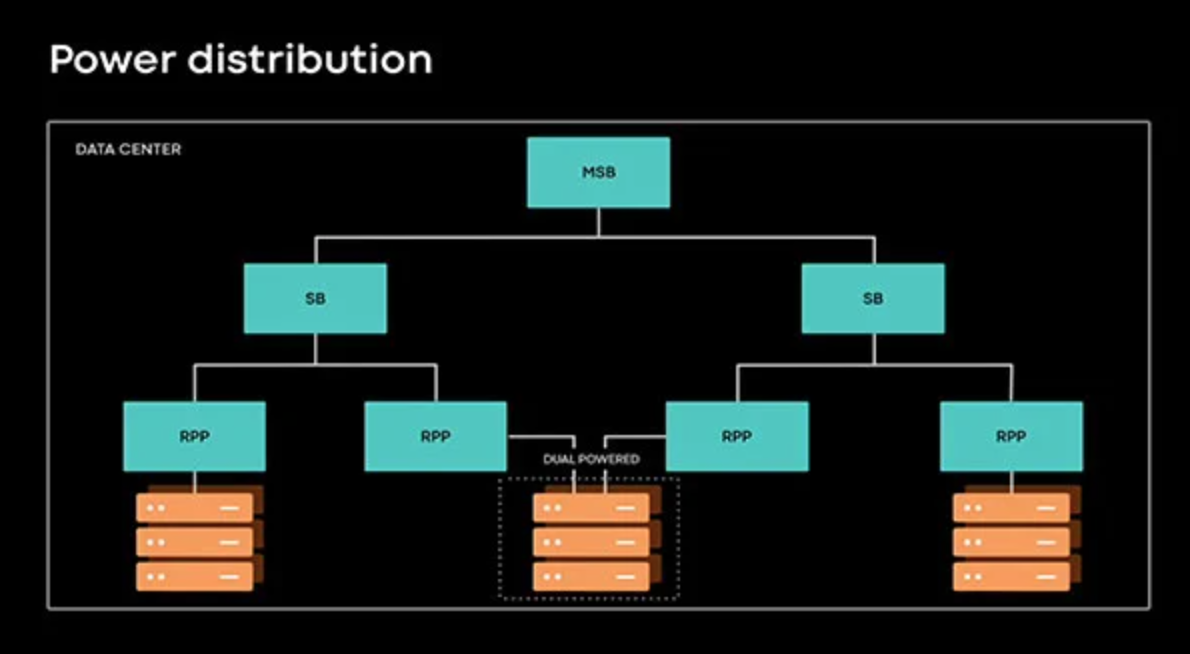
Power outages cause the majority of unplanned server downtime in Facebook data centers. During a power outage, thousands of servers can go offline simultaneously for several hours, which can lead to service degradations. At Facebook, all data center racks are equipped with batteries that can provide backup power for a few minutes after power outages. Power Loss Siren (PLS) is a rack level, low latency, distributed power outage detection and alerting system. PLS leverages existing in-rack batteries to notify services about impending power outages and helps mitigate the impact of power outages on services. Typical mitigations include promoting remote database secondaries when primaries are experiencing power outages, routing requests away from hosts experiencing power outages, flushing memory to disk, etc. PLS also helps simplify physical infrastructure management by not requiring additional power source redundancy for critical services.

Speaker
Raghunathan Modoor Jagannathan,Facebook

Speaker
Sulav Malla,Facebook
Speaker
Parimala Kondety,Facebook
09:00 AM
-
09:20 AM
Confluent: Operating Cloud-Native Kafka
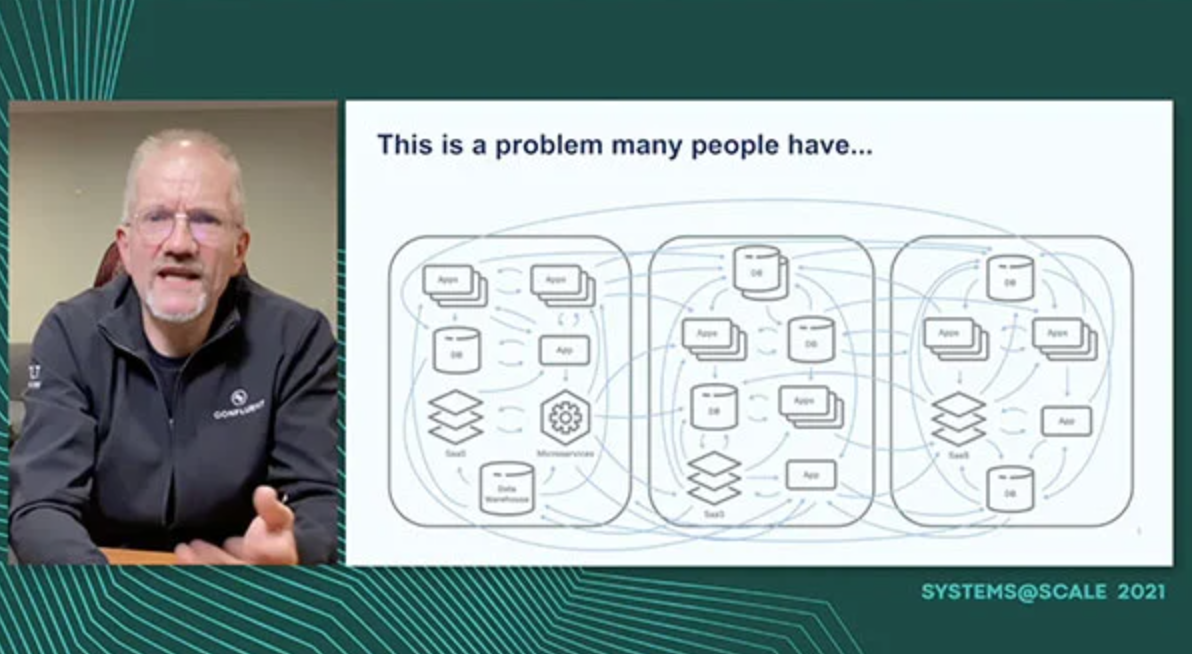
Confluent Inc provides cloud based data stream platforms based on Apache Kafka. Running an open source product like Kafka on the public cloud offerings of Amazon, Google, and Microsoft offers an interesting array of challenges. This presentation gives an overview of these challenges and discusses some of the solutions that Confluent uses to meet them.

Speaker
Jos Visser,Confluent
09:20 AM
-
09:40 AM
Making A Distributed Priority Queue Disaster Ready

Facebook Ordered Queue Service (FOQS) is a distributed priority queue service that powers hundreds of services and products across the Facebook stack. Facebook users have come to rely on its services to remain connected to their friends and families. As such, it is absolutely crucial for Facebook to continue operating with high availability during events which may impact its data centers. Being a core building block of Facebook infrastructure, FOQS is expected to handle loss of a data center gracefully and transparently to its clients. Dillon and Jasmit will talk about how the architecture of FOQS has evolved to be resilient to disasters, the technical challenges of hosting a globally available system, and the operational challenges that came with migrating existing tenants of FOQS to disaster ready installations with zero downtime at Facebook scale.
Speaker
Jasmit Kaur Saluja,Facebook

Speaker
Dillon George,Facebook
09:40 AM
-
10:00 AM
Lessons From Building a Large-Scale, Multi-Cloud Data Platform at Databricks
The cloud is becoming one of the most attractive ways for enterprises to store, analyze, and get value from their data, but building and operating a data platform in the cloud has a number of new challenges compared to traditional on-premises data systems. I will explain some of these challenges based on my experience at Databricks, a startup that provides a data analytics platform as a service on AWS, Azure, and Google Cloud. Databricks manages millions of VMs per day to run data engineering and machine learning workloads using Apache Spark, TensorFlow, Python and other software for thousands of customers.

Speaker
Jeff Pang,Databricks
10:00 AM
-
10:20 AM
Scaling Back-End Deployment @ Facebook
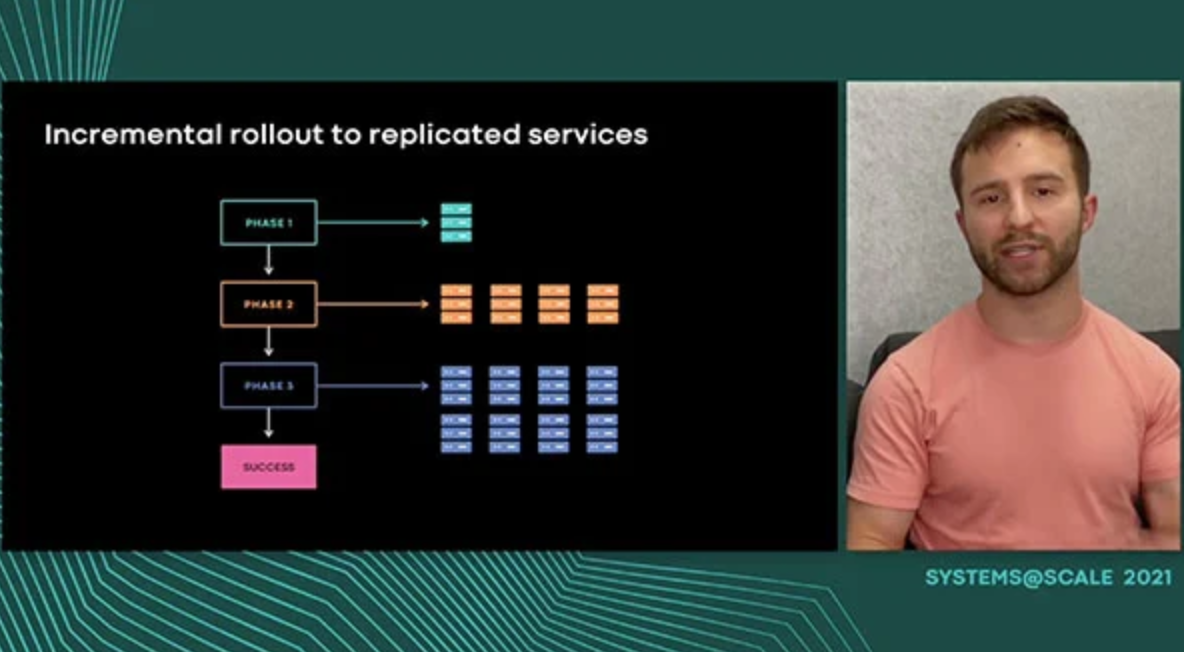
We present how Facebook's unified Continuous Deployment (CD) system, Conveyor, powers safe and flexible service deployment across all services at Facebook. Conveyor enables services owners to build highly customized deployment pipelines from easy-to-use components and supports building, testing, and deploying a diverse range of services. To go further, we explore how Conveyor's deployment system, Push, provides users with tools to deploy new binary versions safely and gradually across the Facebook fleet.

Speaker
Tyler Petrochko,Facebook
10:20 AM
-
11:00 AM
Live Q&A Session with Speakers
LATEST NOTES
@Scale engineers pencil blogs, articles, and academic papers to further inform and inspire the engineering community.
Systems & Reliability @Scale
10/13/2021
Conveyor: Continuous Deployment at Facebook
Facebook has billions of users across numerous products, including Messenger, Newsfeed, Instagram, Watch, Marketplace, WhatsApp, and Oculus. Thousands of interconnected...








