- WATCH NOW
- 2025 EVENTS
- PAST EVENTS
- 2024
- 2023
- 2022
- February
- RTC @Scale 2022
- March
- Systems @Scale Spring 2022
- April
- Product @Scale Spring 2022
- May
- Data @Scale Spring 2022
- June
- Systems @Scale Summer 2022
- Networking @Scale Summer 2022
- August
- Reliability @Scale Summer 2022
- September
- AI @Scale 2022
- November
- Networking @Scale Fall 2022
- Video @Scale Fall 2022
- December
- Systems @Scale Winter 2022
- 2021
- 2020
- 2019
- 2018
- 2017
- 2016
- 2015
- Blog & Video Archive
- Speaker Submissions







Systems @Scale Spring 2022
MARCH 23, 2022 @ 10:00 AM PDT - 12:00 PM PDT
MARCH 30, 2022 @ 10:00 AM PDT - 11:30 AM PDT
MARCH 31, 2022 @ 10:00 AM PDT - 12:30 PM PDT
Designed for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges.
ABOUT EVENT
Systems @Scale Spring 2022 is a technical conference for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The Systems @Scale Spring 2022 series will be hosted virtually. Joining us are speakers from Microsoft, Google, Open Source Cassandra, and Meta. The event spans three weeks, with talks themed around reliability, resiliency, efficiency and storage at scale.
Starting March 23rd, for three weeks, we will livestream a recorded session followed by live panel discussion on Wednesdays.
March 23 – Storage Platforms
March 30 – Storage Platforms and Applied Privacy
March 31 – Reliability, Resiliency, Efficiency
March 23
Storage Platforms
March 30
Storage Platforms and Applied Privacy
March 31
Reliability, Resiliency, Efficiency
SPEAKERS AND MODERATORS
Niket Agarwal is a Software Engineer in the Infrastructure team at Meta. His interests... read more
Niket Agarwal
Meta
Dan Schatzberg is a Research Scientist in the Core Systems Team at Meta working... read more
Dan Schatzberg
Meta
Johannes is a Linux kernel engineer of over a decade, with a focus on... read more
Johannes Weiner
Meta
Jacob is a software engineer at Meta where he’s had several roles, including tech... read more
Jacob Lacouture
Meta
Dinesh is a Committer & PMC member on the Apache Cassandra project and has... read more
Dinesh Joshi
Apache Cassandra
Aarti Basant has been working as a Software Engineer at Meta since 2017. She... read more
Aarti Basant
Meta
Ivan Santa Maria Filho is the dev manager of SCOPE, Microsoft’s internal analytics engine.... read more
Ivan Santa Maria Filho
Microsoft
Shiv is a software engineer working in privacy infrastructure at Meta as part of... read more
Shiv Kushwah
Meta
Haozhi Xiong is a Software Engineer at Meta Privacy. He has been with Meta... read more
Haozhi Xiong
Meta
Kumar Mrinal has been working at Meta for close to 2 years now. While... read more
Kumar Mrinal
Meta
Binbin is a Software Engineer at Meta based in the Seattle area. She is... read more
Binbin Lu
Meta
Yuri Grinshteyn strongly believes that reliability is a key feature of any service and... read more
Yuri Grinshteyn
Google
Jie joined Meta in 2018 and spent her first couple years working on ZooKeeper.... read more
Jie Huang
Meta
Chris is a Production Engineer from Meta's Core Systems team. Having lived at the... read more
Christopher Bunn
Meta
Osama Abuelsorour is a technology veteran and entrepreneur with experience spanning networking, AI/ML and... read more
Osama Abuelsorour
Microsoft
Amr Mahdi is a software engineer with a passion for large-scale distributed systems. He... read more
Amr Mahdi
Microsoft
Jason Flinn is a Meta software engineer building the distributed systems that manage Meta’s... read more
Jason Flinn
Meta
Arushi Aggarwal is a Meta software engineer building the distributed systems that manage Meta’s... read more
Arushi Aggarwal
Meta

EVENT AGENDA
Event times below are displayed in PT.
March 23
Storage Platforms
March 30
Storage Platforms and Applied Privacy
March 31
Reliability, Resiliency, Efficiency
March 23
Storage Platforms
10:00 AM
-
10:20 AM
Transparent Memory Offloading @Meta
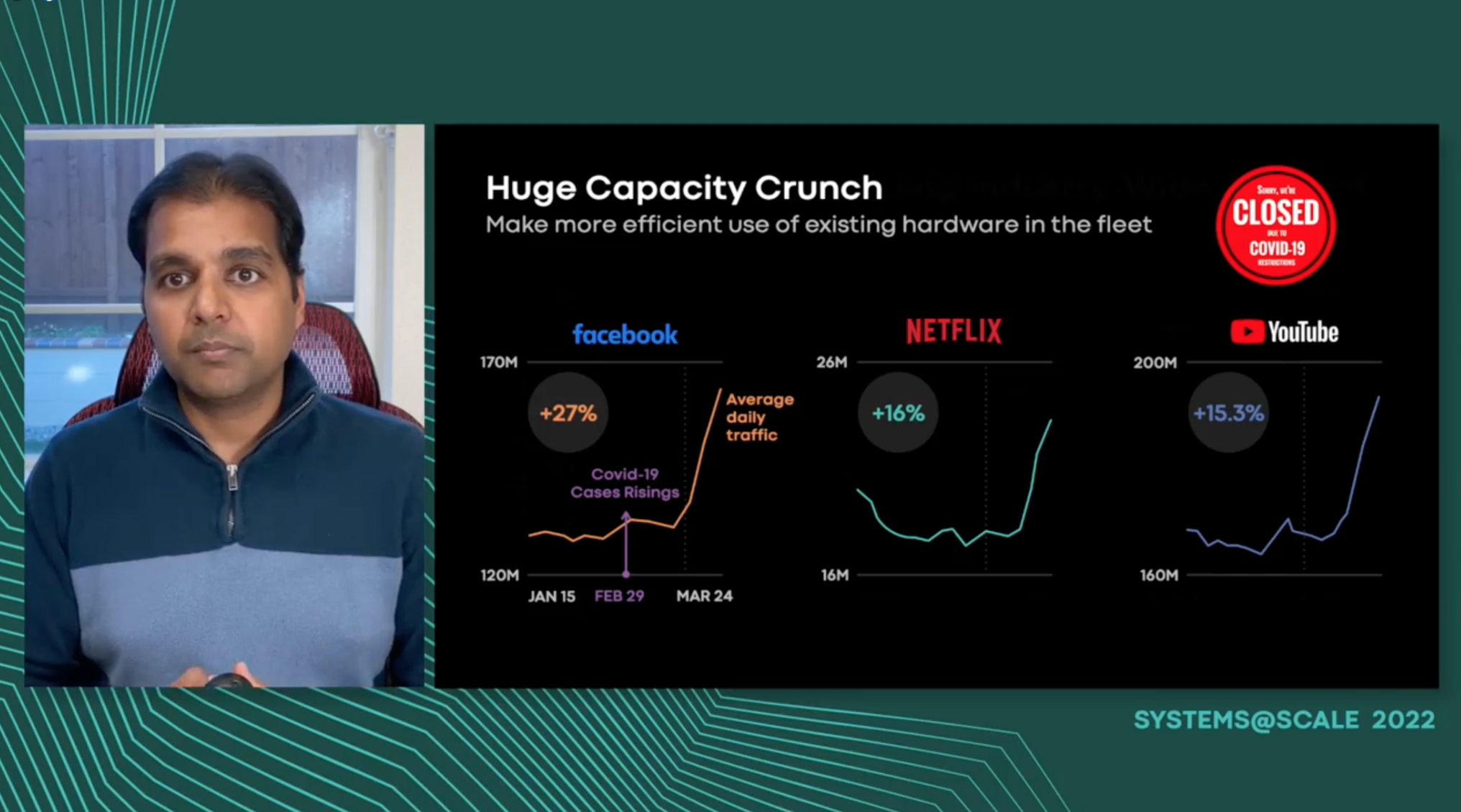
The unrelenting growth of the memory needs of emerging data center applications, along with ever-increasing cost and volatility of DRAM prices, has led to DRAM being a major infrastructure expense. Alternative technologies, such as NVMe SSDs and upcoming NVM devices, offer higher capacity than DRAM at a fraction of the cost and power. One promising approach is to transparently offload colder memory to cheaper memory technologies via kernel or hypervisor techniques. The key challenge, however, is to develop a datacenter-scale solution that is robust in dealing with diverse workloads and large performance variance of different offload devices such as compressed memory, SSD, and NVM. In this talk, we will present TMO, Meta’s transparent memory offloading solution for heterogeneous data center environments. TMO introduces a new Linux kernel mechanism that directly measures in real time the lost work due to resource shortage across CPU, memory, and I/O. Guided by this information and without any prior application knowledge, TMO automatically adjusts how much memory to offload to heterogeneous devices (e.g., compressed memory or SSD) according to the device’s performance characteristics and the application’s sensitivity to memory-access slowdown. TMO holistically identifies offloading opportunities from not only the application containers but also the sidecar containers that provide infrastructure-level functions. TMO has been running in production for more than a year, and has saved between 20-32% of the total memory across millions of servers in our large datacenter fleet. We have successfully upstreamed TMO into the Linux kernel.

Speaker
Niket Agarwal,Meta

Speaker
Dan Schatzberg,Meta

Speaker
Johannes Weiner,Meta
10:20 AM
-
10:40 AM
Manifold: Storage Platform Consolidation
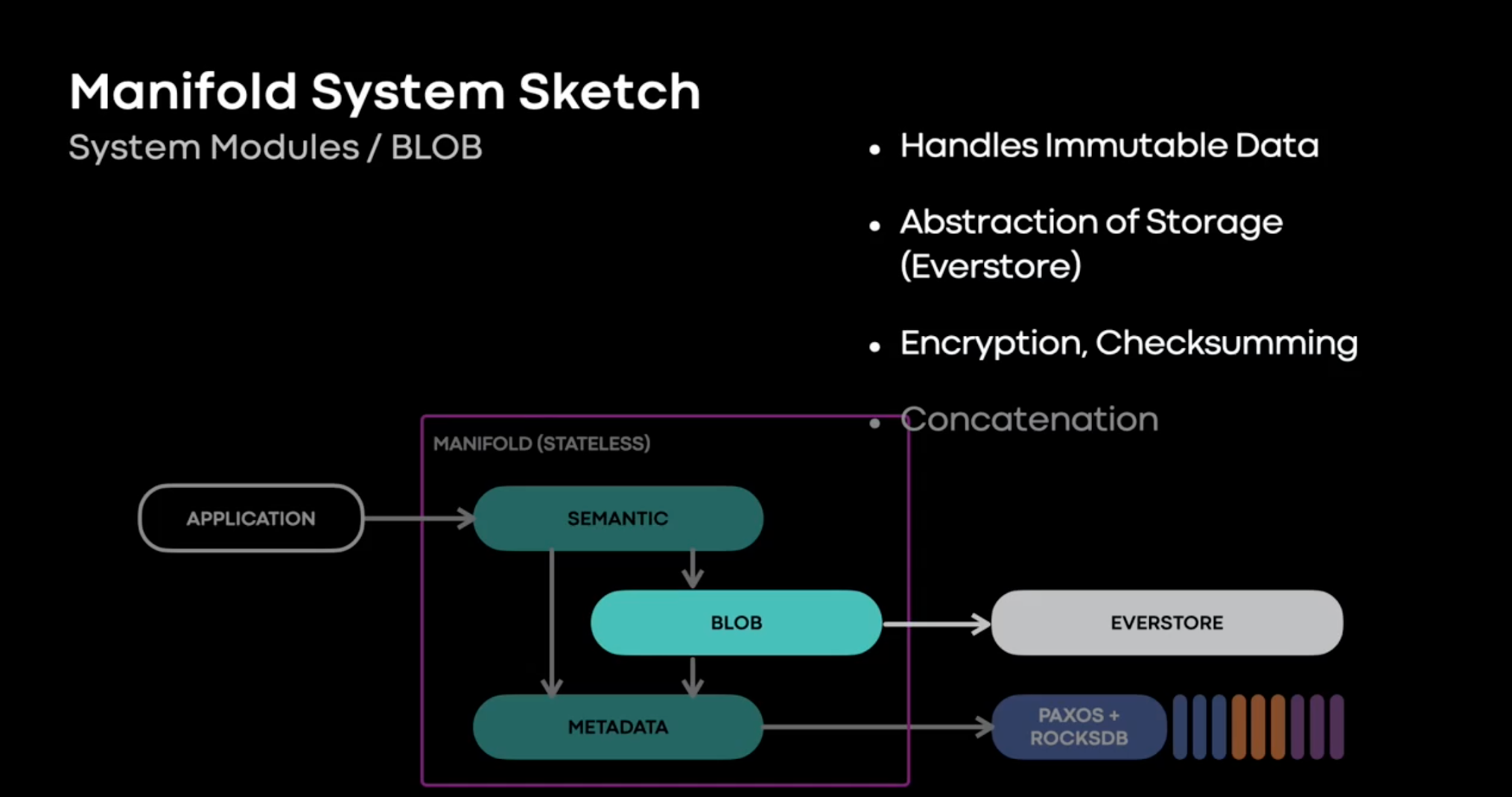
Since 2016, we’ve built, deployed, and scaled a new BLOB storage platform at Meta, called Manifold. Manifold builds on existing BLOB storage infrastructure, but provides a richer, higher-level, general purpose API, and thereby enables teams using storage at Meta move faster. Moreover, by creating a stronger abstraction between storage consumers and storage infrastructure, Manifold enables storage infrastructure teams to move faster too, but realizing this vision requires migrating thousands of production workloads totaling exabytes of production data, and rebuilding multiple systems. We’ll describe our approach.

Speaker
Jacob Lacouture,Meta
10:40 AM
-
11:00 AM
Cassandra@Scale: A Deep Dive into Apache Cassandra 4.0

At almost two years in the making Apache Cassandra 4.0 is here. With a focus on performance and stability, it is full of interesting features. This talk takes you through a tour of the new features and performance improvements. From Zero Copy Faster Streaming support to Virtual Tables and Audit Logging, learn how Apache Cassandra 4.0 has departed from previous major releases to be focused on the features required by the most demanding users. Attendees will not only gain an understanding of new features in Apache Cassandra, but understand what drove their creation and therefore have a better idea of how to best use these features in their own systems.

Speaker
Dinesh Joshi,Apache Cassandra
11:00 AM
-
11:15 AM
Scaling Data Ingestion for ML Training at Meta

AI models drive several Meta products like News Feed, Ads, IG Reels, language translation to name a few. Our ranking models consume massive datasets to continuously improve user experience on our platform. In this talk, we discuss our experience of building infrastructure to serve massive scale data to the 1000s of AI models driving our products. Further, we present AI training data pipeline workload characteristics and challenges in scaling these systems for industry-scale use cases. Inefficiencies in these pipelines result in expensive wasted GPU/accelerator training resources in our data centers. In this talk, we outline our experience in optimizing these data ingestion pipelines and our plans to continue innovation in this space.

Speaker
Aarti Basant,Meta
11:15 AM
-
12:00 PM
Q&A

Q&A with Niket Agarwal, Dan Schatzberg, Johannes Weiner, Jacob Lacouture, Dinesh Joshi, and Aarti Basant - Moderated by Francois Richard (Meta)
10:00 AM
-
10:20 AM
The Cosmos Big Data Platform at Microsoft: Over a Decade of Progress and a Decade to Look Forward
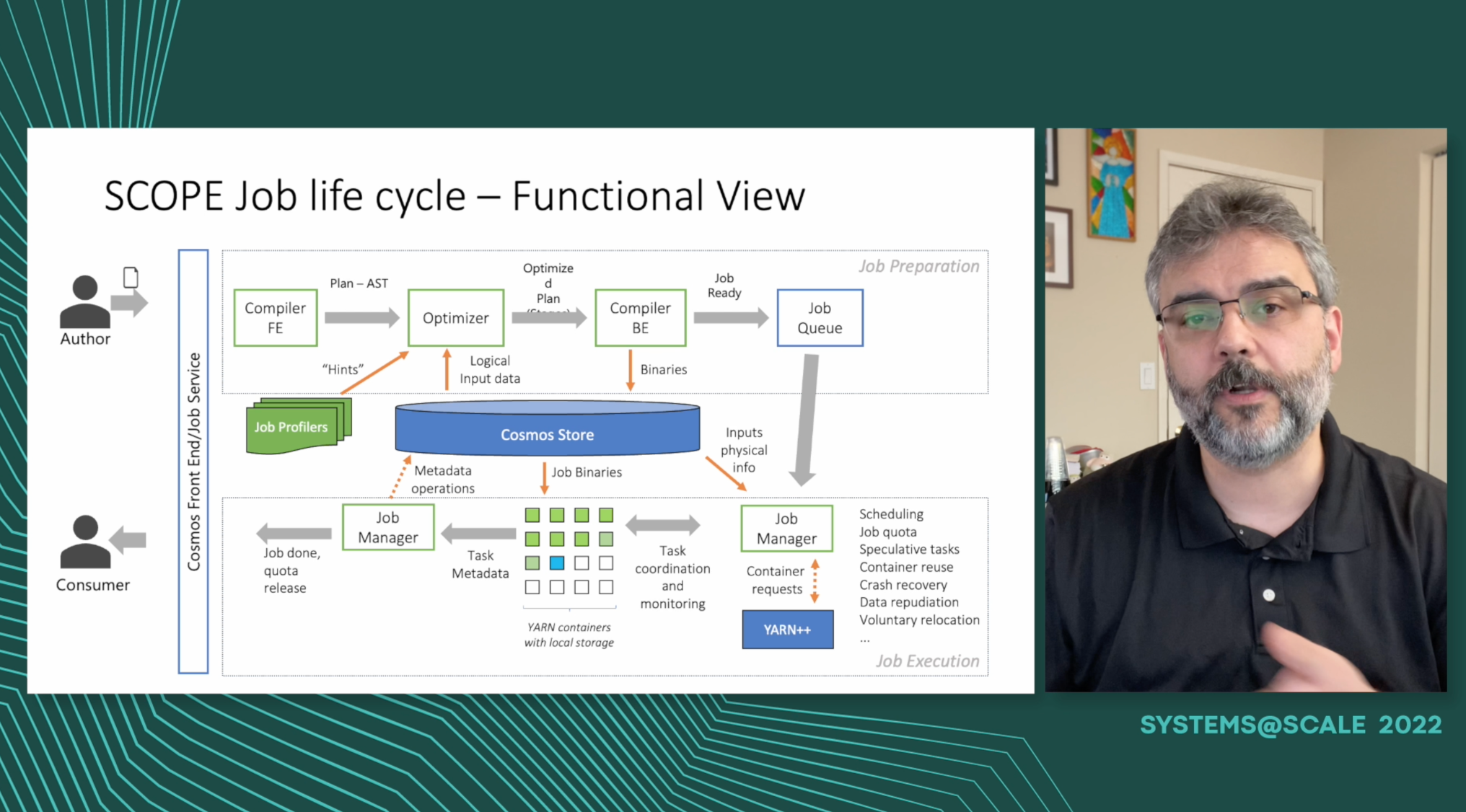
Cosmos is the exabyte-scale big data platform at Microsoft, and SCOPE is its main analytics engine. SCOPE and Cosmos support ETL pipelines, decision support systems, and machine learning pipelines. Applications range from simple performance counter aggregation, to tracking the deployment of Windows to billions of devices, to Azure billing, Xbox gamer reputation, Bing relevance and index creation, to Ads campaign tuning. SCOPE is a mature, feature rich, and highly extensible data querying language and engine. It allows user operators and types written in C#, Python and through those, any other programming language. By transparently splitting the work, it allows users to author simple extensions that are executed in parallel transparently. Cosmos clusters include bare metal machines and VMs, depending on price/performance targets and a wide range of security requirements. In this talk we will demo the SCOPE developer experience in Visual Studio, and explore the system behind it by following the lifetime of a job in production. We will cover the basic functionality and architecture, and how we leverage a vertically integrated hardware and software stack design. We will cover utilization, reliability, cost control and how Cosmos and SCOPE thrived while handling 12x server growth, 188x logical data growth, and 108x job growth over the past decade. You will have a glimpse of a system that completes ~100k tasks per second, reads and writes hundreds of PBs of data per day, and supports jobs with several million containers running in parallel while costing pennies per TB of data processed.

Speaker
Ivan Santa Maria Filho,Microsoft
10:20 AM
-
10:40 AM
ACS: De-Identified Authentication at Scale

Privacy is core to Meta engineering culture, and one of our fundamental principles is data minimization. We strive to collect and create the minimum amount of data required to provide service. One critical space we’ve identified across the industry is to avoid processing user data with identity. Anonymous Credentials Service (ACS) is a service developed by the Applied Privacy Technology Team to provide a solution at Meta scale. ACS enables clients to authenticate in a de-identified manner. By eliminating user-id in authentication, we preserve user security and meet our data minimization goals. We accomplish this by decoupling authentication into a pre-auth phase (aka credential issuance) and a de-identified request phase where the de-identified request is sent with business data. In this talk, we share an overview of ACS design and deployment, learnings from reliably scaling up to heavy workloads, strategies to support multi-tenancy, and a preview of the future work toward integrating de-identified services with Meta products.

Speaker
Shiv Kushwah,Meta

Speaker
Haozhi Xiong,Meta
10:40 AM
-
11:00 AM
Highly Available and Strongly Consistent Storage Service Using Chain Replication (Dumbo)
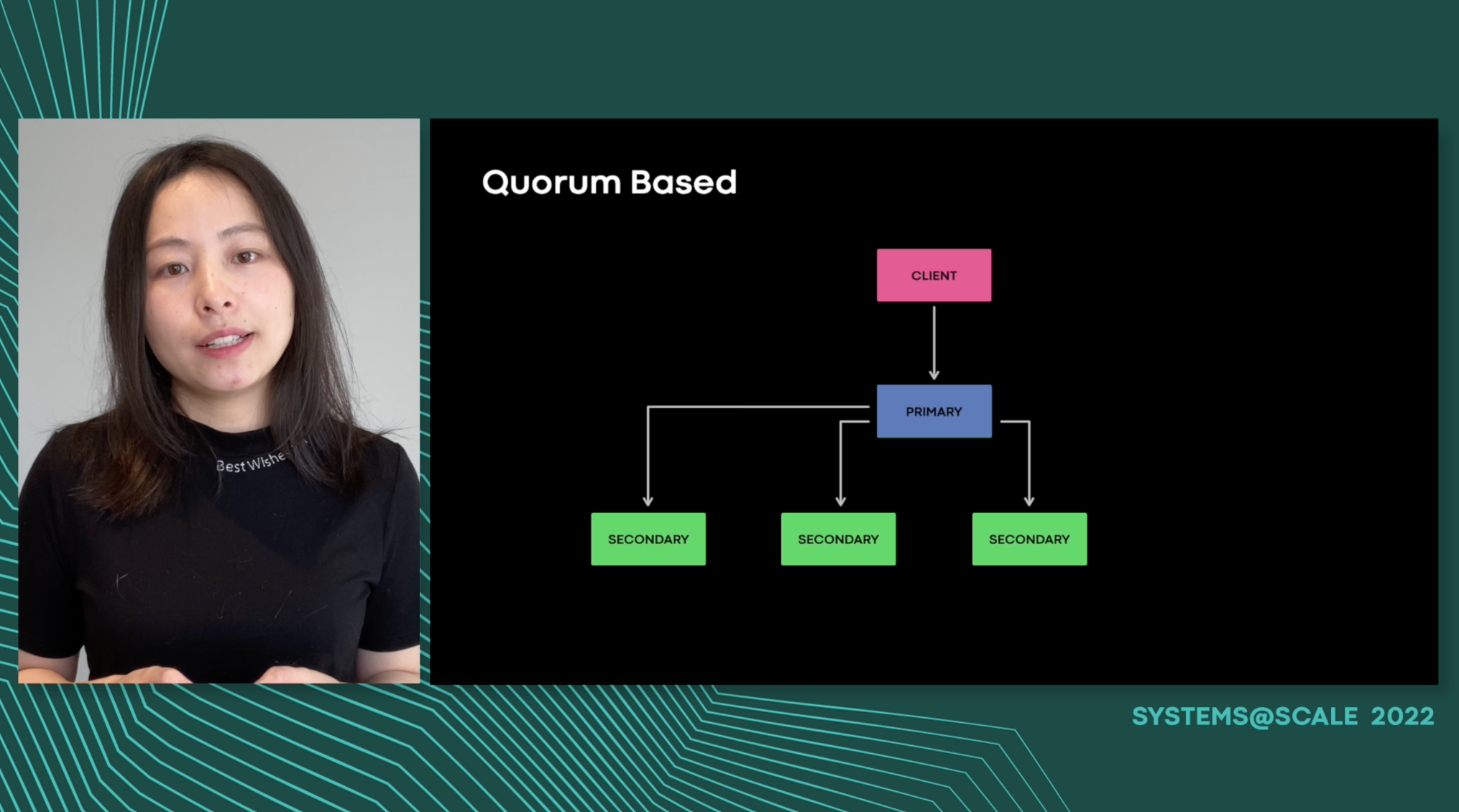
In this talk, we present Dumbo - a simple, reliable, highly available, low dependency object storage system that powers Meta’s build and distribution infrastructure. Dumbo is designed to be extremely simple and have minimal dependencies so as to cater to critical package workloads. This is vital to ensure a seamless disaster recovery and bootstrap strategy. Dumbo leverages chain replication as an approach to coordinate clusters of fail-stop storage servers. We talk about how this compares to classical quorum based solutions in terms of simplicity, performance, consistency and other relevant considerations. We walk-through our journey from a research-paper inspired prototype solution to a fully functional large scale storage service in production. We discuss the milestones, learnings and key observations along the way. We talk about Dumbo’s evolution which started with supporting Meta’s build infrastructure to positioning itself as a gateway to all archival storages within Meta, thereby facilitating the disaster recovery story for core Meta services. We finally wrap with recent feature advancements in our service like cross region replication, backup and restore, recovery provider as a service.

Speaker
Kumar Mrinal,Meta

Speaker
Binbin Lu,Meta
11:00 AM
-
11:30 AM
Q&A

Q&A with Ivan Santa Maria Filho, Shiv Kushwah, Haozhi Xiong, Kumar Mrinal, and Binbin Lu
Moderated by Francois Richard (Meta)
10:00 AM
-
10:30 AM
Shrinking the Impact of Production Incidents

Shrinking Production Incidents details an organized approach for reducing the overall impact of production outages. Attendees can expect to learn how to prioritize reliability-related engineering tasks based on incident postmortem data, focusing on tasks that 1) Reduce time of detection of the incident, 2) Shorten the time to repair, and 3) Expand the time between failures.

Speaker
Yuri Grinshteyn,Google
10:30 AM
-
11:00 AM
Vacuum Testing for Resiliency: Verifying Disaster Recovery in Complex

Engineers at Meta run thousands of services across millions of machines, and those services all have similar needs that can’t be managed by hand: configuration, deployment, monitoring, routing, orchestration, security. To solve the ever-growing complexities of running in production, we build a lot of infrastructure. But infrastructure is just software, and it has those same needs too. So what powers those systems? We like to imagine a neat, tidy stack of yet more, precisely layered infrastructure, where everything is organized into a faultless, acyclic graph of dependencies. Turtles all the way down. But in reality, the lower in the stack you go, the more you find infrastructure is - needs to be - deeply intertwined. After all, infra systems need to run on millions of servers, just like the rest of production. This can present a scary prospect: if something breaks, how do we know we'll even be able to turn things back on again? In this talk, we'll present BellJar, a new technique we've developed to exercise critical infrastructure in environments where nearly all of Meta's supporting services don’t work. By providing precisely tailored broken environments - each of which is specially vacuum sealed away from the infra we take for granted - we can learn exactly what it takes to bring each system back online during widespread outage. And by incorporating this tooling into our delivery pipeline, we can incrementally bake resiliency back into our ever-growing infrastructure layer cake, even as it continues to evolve.

Speaker
Jie Huang,Meta

Speaker
Christopher Bunn,Meta
11:00 AM
-
11:30 AM
Southpaw: Token-Based Service Load Balancing, Scaling And QoS System

Southpaw is load balancing, scaling and QoS management system for compute-heavy inferencing services. It takes the approach of abstracting services capabilities into tokens and worklanes, where clients are granted tokens that gives them access to service instance worklanes. By adopting this simple abstraction, we can unify how we view work and load in a heterogeneous cluster in terms of tokens supply and demand. We then can push compute efficiency much higher while controlling scaling and end-to-end quality of service. Today, Southpaw has been running all global Microsoft speech workloads for the past 3 years and have contributed to increasing average compute efficiency by 5 times

Speaker
Osama Abuelsorour,Microsoft

Speaker
Amr Mahdi,Microsoft
11:30 AM
-
12:00 PM
Owl

We will describe Owl, a new system for high-fanout distribution of large data objects to hosts in Meta's private cloud. Owl distributes over 700 petabytes of data per day to millions of client processes. It has improved download speeds and cache hit rate by a factor of 2-3 over BitTorrent and other prior systems used for distribution Meta.

Speaker
Jason Flinn,Meta

Speaker
Arushi Aggarwal,Meta
12:00 PM
-
12:30 PM
Q&A
Q&A with Yuri Grinshteyn, Jie Huang, Christopher Bunn, Osama Abuelsorour, Amr Hanafi, and Arushi Aggarwal
LATEST NOTES
@Scale engineers pencil blogs, articles, and academic papers to further inform and inspire the engineering community.
Systems & Reliability @Scale
03/23/2022
Blog for Owl: The Distribution Challenge
Within Meta's private cloud, efficient distribution of large, hot content to hosts is an increasingly important requirement. Executables, code artifacts,...








