EVENT AGENDA
Event times below are displayed in PT.
Systems @Scale is a technical conference for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The 2021 Winter series will be hosted virtually. Joining us are speakers from NVIDIA, and Meta (Facebook). The event spans two weeks, with talks themed around efficiency and reliability in the context of large-scale distributed systems.
Starting December 8th, for two weeks, we will livestream a recorded session followed by a live panel discussion on Wednesdays.
Event times below are displayed in PT.
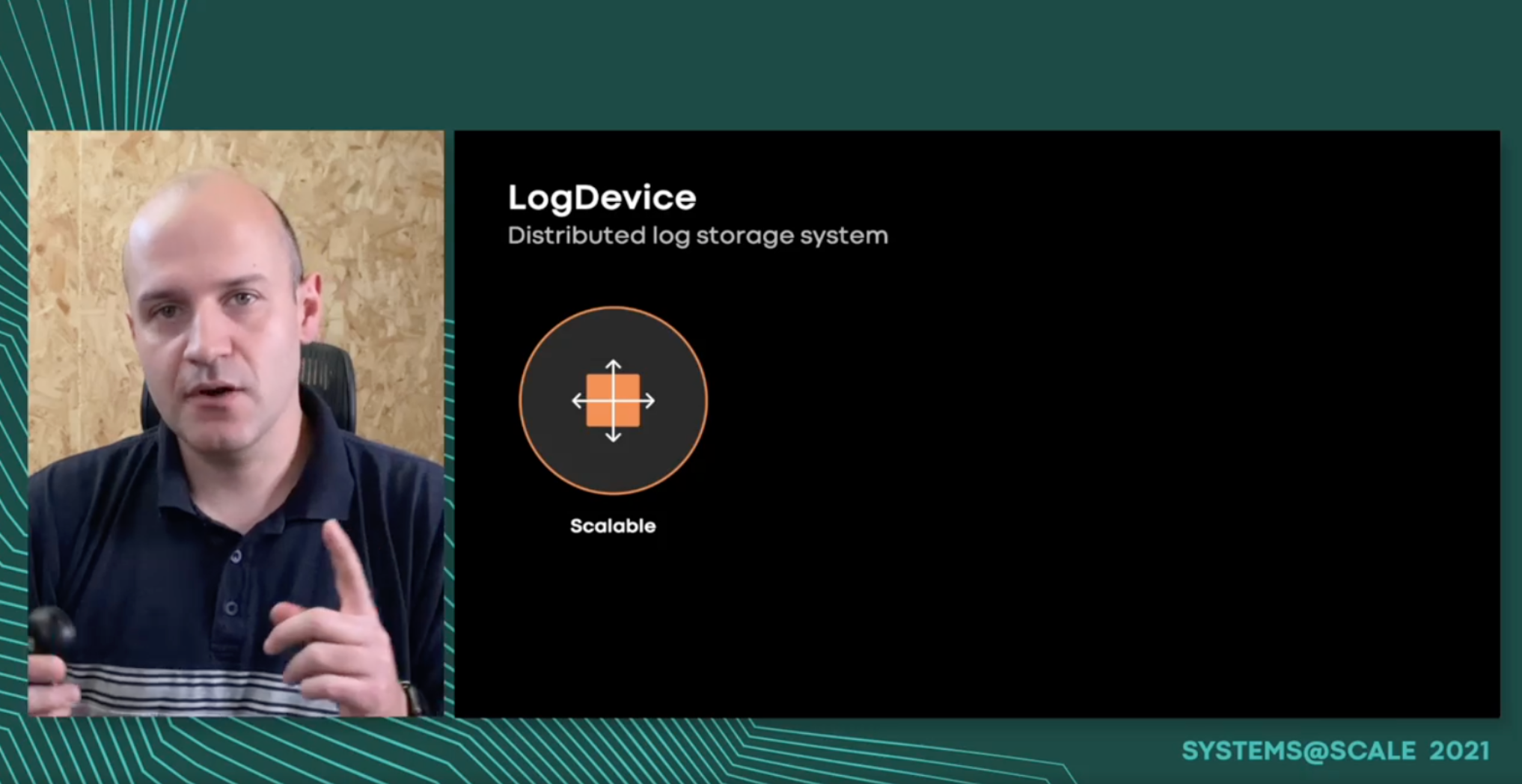
Meta uses a strongly consistent distributed log storage system to broadcast updates in graphs, deliver signals to ML training pipelines, and collect data for analytics. All of these cases require the underlying log system to be highly available, especially on the write side since we don't have any other place to store generated data. This talk will cover some optimizations in the consensus algorithm we are using that are required at Meta's scale to make its systems even more reliable in the presence of hardware maintenance and organic failures.


At Meta, a large part of our data is ephemeral in nature, such as Instagram or Meta Stories which need to be deleted after a specific time regardless of the action taken by the user. This is sometimes referred to as Time to Live (TTL). Deletions may be registered to start at an arbitrary point of time in the future. Developers can achieve this at object creation time by virtue of creating an object of a type under TTL. The Deletion Infrastructure team at Meta built the Schedule Deletion (SD) Infrastructure, that allows us to Schedule and Track massive volumes of deletions from days to years in future.
Live Q&A Session with Miroslav Crnic, Nick Sukhanov & Sneha Padgalwar. Hosted by Sajal Jain.

SLIs (Service Level Indicators) and SLOs (Service Level Objectives) are industry-standard concepts to measure the long-term reliability of systems. In this presentation, we are going to talk about SLICK, the central SLO tracking platform at Meta. We’ll highlight the challenges with reliability tracking at the company historically, and how SLICK is solving these. Afterwards, we are going to walk through SLICK’s high-level architecture, with a focus on how the major pieces are connected with the user workflows. We’ll also talk about how SLICK has introduced SLOs into the culture at Meta, and how our services have improved their reliability as a result.


In this talk we present how we trained a 530B parameter language model on a DGX SuperPOD with over 3,000 A100 GPUs and a high speed Infiniband interconnect, and how we can scale to even larger models. We explore three types of parallelism: data, tensor, and pipeline and how these different types can be composed to achieve maximum efficiency. Our approach allows us to perform training iterations on a model with 1 trillion parameters at 502 petaFLOP/s on 3072 GPUs (per-GPU throughput of 52% of theoretical peak). We discuss challenges that we faced when training the 530B Megatron-Turing NLG model and give practical advice on how to successfully train very large language models.

Efficient software and hardware failure remediations are the foundations for sustaining high fleet availability at large-scale environments such as Meta. In this talk, we will describe the general architecture that we use to maximize fleet availability -- by identifying and remediating software issues as well as faulty assets which might require manual intervention from a datacenter technician. We’ll start by presenting FBAR (Facebook Auto-Remediation), the platform used by our main customers (IG, Messenger, etc) for writing event-based software remediation workflows that are executed to mitigate software issues. We’ll then focus on presenting what happens when issues are instead hardware related, how we detect those faults at scale and how we empowered our repair workflow with a decision engine, called RepairBrain, which helps identify and track which of the repair actions might speed up the mitigation, as well as providing a platform for deploying custom repair actions.


Live Q&A Session with Dávid Bartók, Filip Klepo, Jared Casper, Antonio Davoli & Leandro Silva. Hosted by Ahmad Mamdouh Abdou.














@Scale engineers pencil blogs, articles, and academic papers to further inform and inspire the engineering community.