EVENT AGENDA
Event times below are displayed in PT.
Systems @Scale Winter 2022 is a technical conference designed for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The Winter 2022 series will be hosted virtually. Joining us are speakers from Expedia, AWS, LinkedIn, Google, and Meta. The event spans two weeks, with talks themed around building and managing systems at scale.
Starting December 7th, for two weeks, we will livestream a recorded session followed by a live panel discussion on Wednesdays.
Event times below are displayed in PT.
Building Systems for Planetary Scale
Managing Production Environment @ Scale
Building Systems for Planetary Scale
Let’s go beyond bin packing and look at strategies for effective use of physical resources. Whether you run your own bare metal or use Cloud-based infrastructure, this talk will show you how to get more out of your systems.

A talk about the architectural changes in Meta’s event driven asynchronous computing platform that enabled easy integration with multiple event-sources. We share our learnings from handling various types of workload and how to tackle trade offs made with certain design choices in building the platform.


How do you build and operate one of the largest global networks at scale? At Meta, we believe it starts with automation. In place of traditional network scripts and manual checklists, we here at Meta have opted for Workflows within our Network. Workflows are a composition of steps which perform some desired network operations. Teams solve complex network problems by designing, building and executing Workflows on our platforms.
Whether it’s network deployment, operations or lifecycle management, each day, tens of thousands of Workflows are executed. Executing these Workflows across an ever growing fleet of network devices, while also providing a robust platform for engineers and network operators to develop and scale their Workflows poses a unique set of challenges.
Achieving scalability in this space requires more than just load balancing. Internally our systems scale by employing strict resource constraints and offering a secure multi-tenancy environment. This is achieved through the use of Linux Cgroups, POSIX Signals and Processes. Leveraging a torrent based package management system decouples users’ business logic from core framework logic. Users are free to build, deploy and scale their Workflows independent of the framework and other users. It’s this modularity and decoupling that allows us to scale Workflows reliably from the tens to hundreds to tens of thousands!


At Expedia Group we are building our on-road experience that includes a common runtime compute platform for a target scale of more than 15 thousand applications, running across a fleet of tens of thousands of nodes on Kubernetes.
In this talk we will present our chaos engineering platform, a part of our platform on-road experience, which aims to enable execution of chaos experiments for thousands of engineers. We will touch upon the importance of a great developer experience, scaling the platform through integrations with continuous delivery mechanisms, and operational aspects such as monitoring and runbooks. We will also present our learnings from promoting the platform through GameDays, byte-size videos, and success stories. Finally, we will demonstrate our recent work on closing the feedback loop between reliability best practices and tools through our reliability hub.

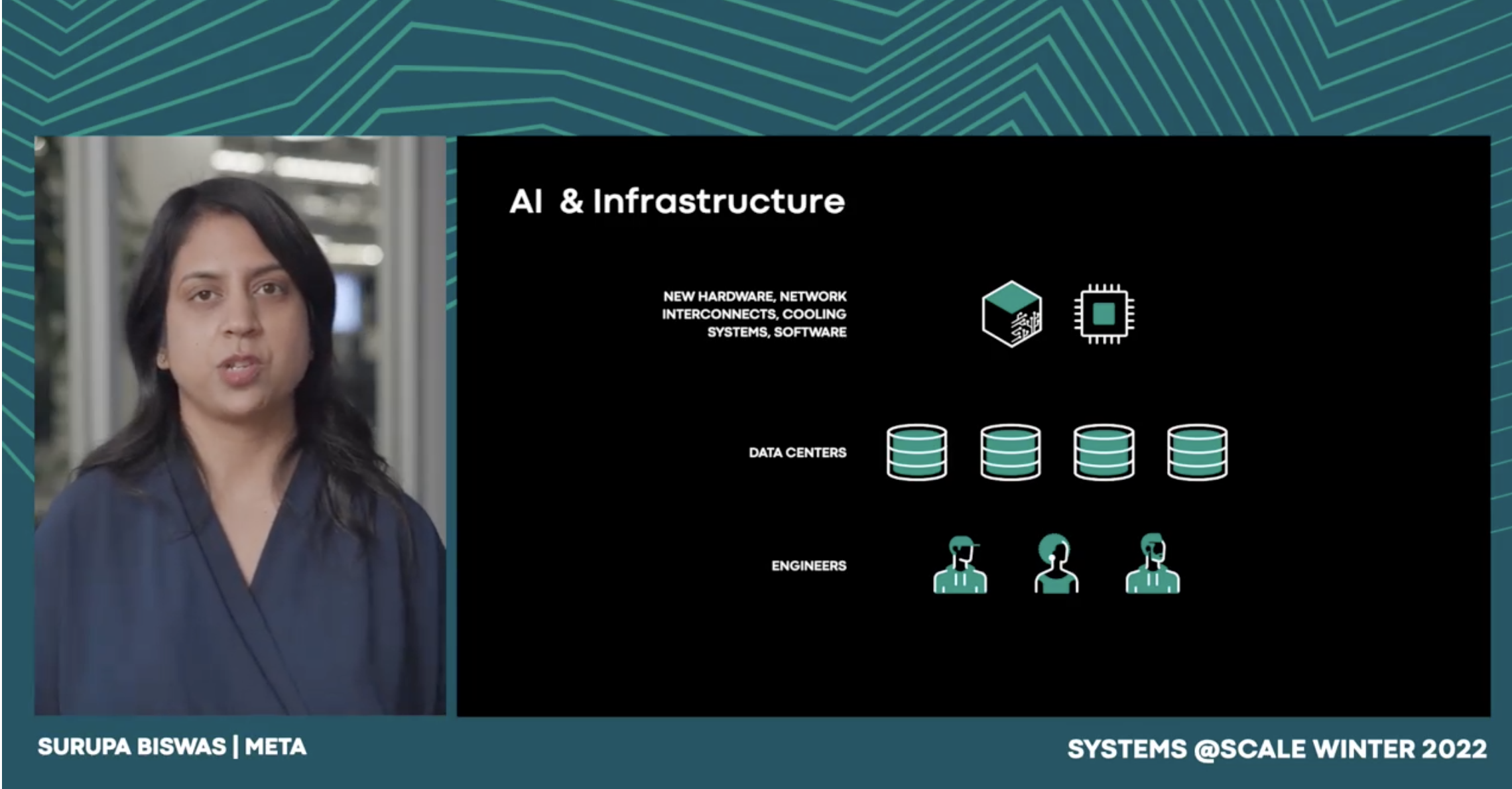
Infra Cloud is Meta’s Internal effort to apply lessons from successful public clouds and deliver a tailored solution for our unique needs, building and running some of the most used apps on the planet. Learn why this direction is both important and urgent at this juncture of Meta’s journey, why it’s challenging to achieve, and our approach to tackling it.

Managing demand driven infra cost regarding product growth is essential to a company’s expansion. Demand and Efficiency management is key to enable services to scale reliably and efficiently. COVID-19 caused unexpected growth on user traffic and shortage on hardware supply, making demand and efficiency management more critical than ever.
Multi-tenant services have its unique challenges in demand and efficiency management in terms of attribution (especially interweaving social graph services) and holding all users accountable.
Meta has tens of large multi-tenant services, and each is used by hundreds of Meta teams. Using Meta web tier as an example, every day there are thousands of code changes and feature roll outs. Managing demand and efficiency at this scale and development pace is challenging. To tackle that, we built a one-stop shop to cover end to end management flow including (1) quota management/enforcement and admission control as a safe net to manage the overall demand (2) pre-production and production regression detection to prevent adding new cost (3) optimization framework to reduce existing cost. In this presentation, we will introduce this toolkit, how it supports web demand and efficiency management, and how we scale the tooling and process to manage demand across Meta large multi-tenant services.


Meta’s graph store TAO, like many other distributed data stores, has traditionally prioritized availability, efficiency, and horizontal scalability over strong consistency or isolation guarantees to serve its large read-dominant workloads. As product developers built diverse applications on top of this system, we have seen an increasing desire for transactional semantics. In this talk, we first characterize developer desires for transactions that emerged over the years and describe the current failure-atomic (i.e., write) transactions offered by TAO. We highlight the need for atomic visibility in a read transaction API with a measurement study on potential anomalies that occur without stronger isolation for reads. We then present the RAMP-TAO protocol, a variation based on the Read Atomic Multi-Partition (RAMP) protocol, that ensures atomic visibility for a read-optimized workload and an eventually consistent system. We demonstrate that this protocol results in minimal overhead, and our design can be feasibly deployed in production.

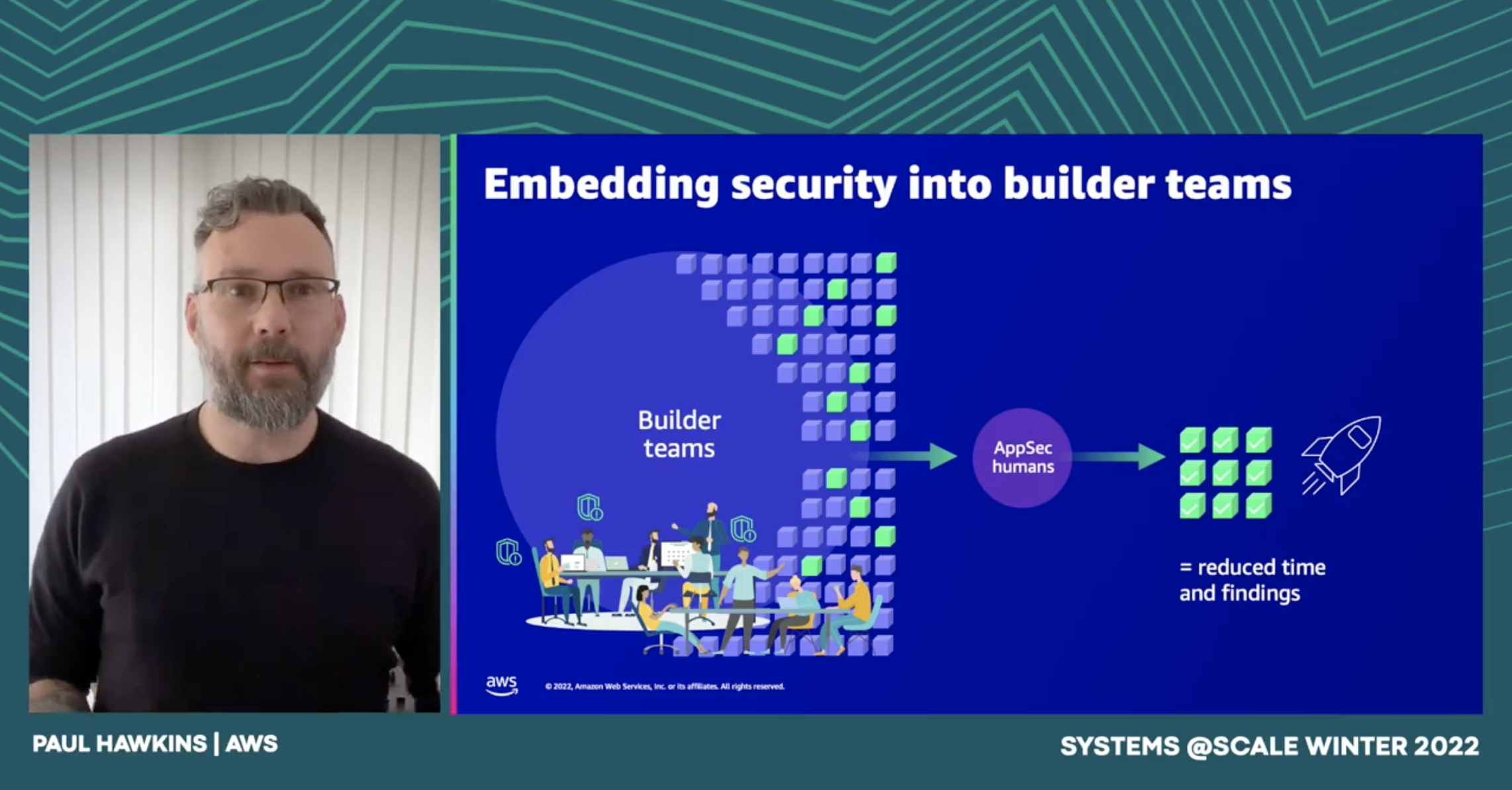
Security is everyone’s job, not just those who have security in their job title. In this session you’ll hear how a positive security culture helps you scale the efforts of your security humans and accelerate the thing that we are all trying to do. Ship securely. You’ll hear some approaches that AWS takes in their distributed environment & how you can apply those to your own organization.

Effective incident management is key to limiting the disruption caused by an incident and restoring normal business operations as quickly as possible. If you haven’t gamed out your response to potential incidents in advance, principled incident management can go out the window in real-life situations. This talk walks through a portrait of an incident that spirals out of control due to ad hoc incident management practices, outlines a well-managed approach to the incident, and reviews how the same incident might have played out if handled with well-functioning incident management. The talk introduces protocols for incident management, typical roles and heuristics for when to declare an incident and form a command post.

LinkedIn uses Terraform as a service(TFaas) to enable infrastructure-as-code uniformly across its teams. In this talk, learn why LinkedIn built its own service. We'll dive into the architecture and see how we solve complex issues at scale around storing state, drift detection, and remediation as we discuss the company-wide adoption strategy. Finally, we'll show you some of the common use cases, including bootstrapping new fabrics and migrating on-prem infrastructure to Kubernetes using this platform.

Salim Virji develops reliable engineering practices and processes for Google’s SRE organization, and has... read more



Sayak is a software engineer in the Serverless Computing infrastructure team at Meta. Previously,... read more

Software engineer with strong experience in development, provisioning and support of reliable high-throughput infrastructure... read more

Tech lead for the Network Automation Team at Meta. Prior to Meta, worked at... read more

Software engineer with 10+ in cloud and infrastructure development. Rookie bass player, novice swimmer,... read more

Nikos is a Senior Software Engineer at Expedia Group. His current focus is on... read more


Anca is a seasoned software engineer with over 11 years of experience at Meta,... read more

Staff software engineer in Meta and has 6 years of experience in managing demand... read more

Sherry is an engineering manager supporting Efficiency Management Frameworks, FBDetect, and Host Software Efficiency... read more

Audrey is a third-year PhD student at UC Berkeley in the Sky Computing Lab.... read more

Paul is Principal in the Office of the CISO in AWS Security. He helps... read more

Ramón is a Staff Site Reliability Engineer at Google where he works on the... read more

Wensi joined the Linkedin TFaaS (Terraform as a Service) team as a software engineer... read more

Liane Praza is a Software Engineer working on the compute infrastructure at Meta. Since... read more