







AI voice assistants are ubiquitous, helping us stay organized, gather information, increase productivity, or even entertain. With a significant increase in global voice assistants usage, Meta has been at the forefront, integrating AI into its family of apps and wearable devices. Anyone who’s used a voice assistant knows, however, that a simple conversation can quickly go awry due to everyday interferences like background noise, side conversations, or acoustic echo, all of which can falsely trigger the bot.
To address these common frustrations and make interactions with AI feel more natural and intuitive, Meta has developed a robust multilayered audio AI stack. In this blog post, we will describe how Meta has developed that multilayered audio AI stack to enable more natural and intuitive interactions with AI voice assistants.
Beyond basic AI: Hands-free, full-duplex interactions
Our goal is to enable truly hands-free, full-duplex conversations with AI. Imagine an AI that’s “always-on,” understands exactly who is speaking, and responds with perfect timing and relevance. Achieving this requires a different approach than is needed for human-to-human communication. For example, unlike human-to-human communication, where there is little to no tolerance for artifacts such as echo and noise, in human-to-machine communication we can accept a small degree of such distortions to ensure the user’s voice is always prioritized without affecting the model’s response.
To that end, we’ve optimized our architecture for immediate connection, lower latency, and enhanced resilience to packet loss. We have advanced our large language models (LLMs), making them robust to interference by training them with augmented data that includes real-world background noise, overlapping speech, and echo conditions.
From human-human to human-bot, real-time communication (RTC):
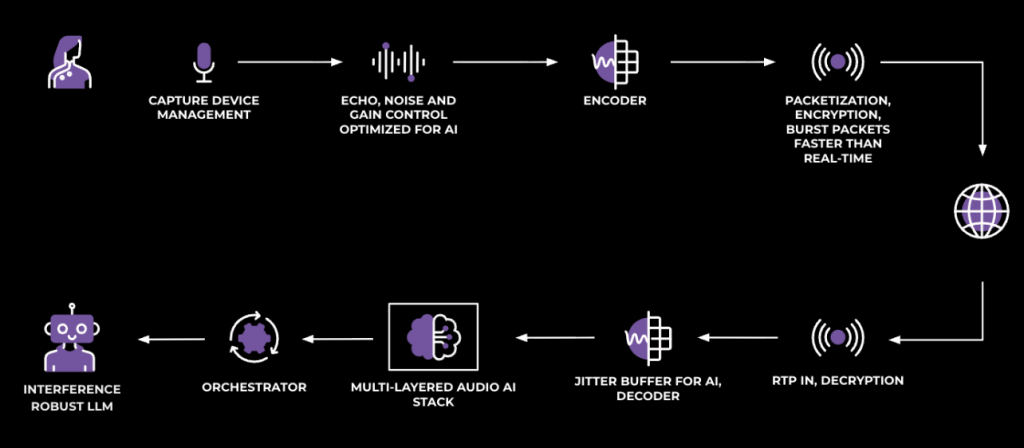
Classical real-time communication (RTC) is built for people talking to people: AEC/NS/AGC → codec → RTP → jitter buffer → decoder → playback. Please see our previous RTC@Scale blog post on this topic.
For bots, the requirements and priorities are different. Those include:
- Immediate recording and bursting: Unlike in human-human calls, where there is a ringtone and where some delay while waiting for the call to get connected is expected, in human-bot calls users usually expect to be connected immediately to the bot when the voice session begins. To achieve this, as soon as the user hits the call button and confirms the intent to talk to the bot, we start recording and buffering audio, even before the connection to the server is established. Once the connection is created, we burst buffered audio to the server faster than real time (i.e., faster than 50 packets/second).
- AI-tuned jitter buffer: Unlike in human-to-human communication, the bot needs not be obliged to receive packets every 10 or 20 ms. It also does not need to compensate for network jitters as humans do for understanding. Therefore, we tuned for loss recovery and brief delay, not human conversational rhythm.
- AEC/NS tuned for double-talk: We prioritize preserving the user’s voice to help with the bot’s understanding, even if that results in a tiny bit of echo/noise. This is particularly important when the user interrupts the bot’s response.
These transport and client-side audio-processing optimizations trim down the perceived latency and increase the system robustness. While we train the backend on augmented data (including noise, overlap, echo, and off-mic speech) so that the LLM learns to ignore distractors, this alone is not sufficient. Failures are hard to localize, human feedback is hard to incorporate, and iteration slows. So, we took a page from engineering history and adopted a modular approach.
Going modular: Multi-layered audio AI stack
We’ve developed a modular audio stack. This design (depicted in Figure 1) allows for easier debugging and faster iteration, filtering interference up front, before the LLM.
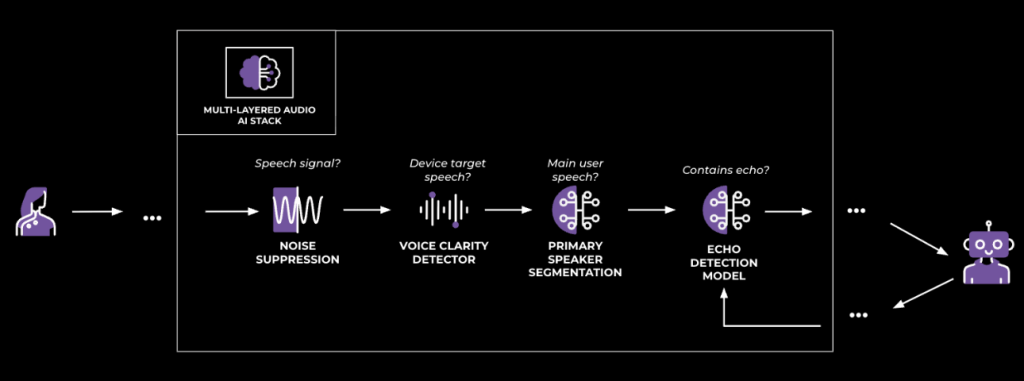
The stack’s key modules, as shown in Figure 2, include:
1. Near/far speaker detection:
This is done by our voice clarity detector (VCD) module. It identifies the proximity of the speaker, distinguishing a near-field user from far-field ones, such as other speakers or a TV. This is the first gate against side speech. The detector looks at spectral cues that correlate with distance and direct-to-reverb energy. This DSP-forward module combined with a deep-learning-based denoiser determines, without biometrics, “Is this speech? And is it clear enough to be potentially directed at us?” It uses features such as:
- Energy: Measures the overall power of the speech signal.
- Spectral centroid: Represents the “center of mass” of the audio spectrum, correlating with sound brightness.
- Clarity: A unique feature that quantifies the direct-to-reverberation ratio by analyzing signal self-similarity. This tells us how close the speaker is and the impact of reverberation.
How near/far speaker detection works: During an initial training phase (just the first 0.5 seconds of detected speech), the system uses the extracted features to create a lightweight, multivariate Gaussian Mixture Model (GMM) of the primary speaker’s acoustic profile. During ongoing inference, each audio frame is then analyzed against this model to determine the likelihood that the speech originates from the primary speaker, effectively filtering out background noise. The system is remarkably adaptive, with a dynamic relearning mechanism triggered by significant changes in acoustic properties (e.g., microphone switching), using a one-sided cumulative sum control chart (CUSUM) algorithm to monitor clarity values. This system can be deployed on the server side for robust processing or on the client side for immediate responsiveness, and can be combined with noise-suppression systems for even greater accuracy.
2. Primary speaker segmentation (Who speaks when?):
To keep track of speakers in real time (without enrollment), we use a lightweight time-delay neural network (TDNN) backbone with causal, multi-scale convolutions over MFCCs fast enough for streaming and rich enough to separate voices. On top sits an iterative peeling module, designed to iteratively extract speaker embeddings.
Traditional speaker diarization systems often suffer from significant drawbacks: They can be computationally intensive, require offline processing, or demand explicit speaker enrollment. Furthermore, many systems process all detected speech, even if it’s just irrelevant background chatter.
Our primary-speaker segmentation (PSS) system tackles these challenges with a suite of innovative approaches:
- Intelligent foreground filtering: A preprocessing step, our foreground/background classifier (which is the voice clarity detector) ensures that only speech explicitly targeting the device is passed to the diarization engine. This saves computational resources and improves accuracy by ignoring irrelevant sounds.
- Resource-adaptive processing: Our system intelligently switches between a lightweight deep neural network (DNN) for powerful devices and a purely DSP-based (MFCC) pipeline for resource-constrained hardware.
- No enrollment needed: Our system adaptively learns speaker models on the fly, recognizing new speakers without any prior setup.
- Dynamic clustering and merging: We employ adaptive thresholds and a “candidate cluster” approach to identify new speakers, ensuring stability and merging any duplicate clusters in real time.
- Privacy-aware multi-speaker UI: When multiple speakers are active, our system doesn’t automatically process all audio. Instead, it can prompt the user, asking if they wish to include other speakers’ audio for further processing. This respects user privacy and provides a clearer user experience.
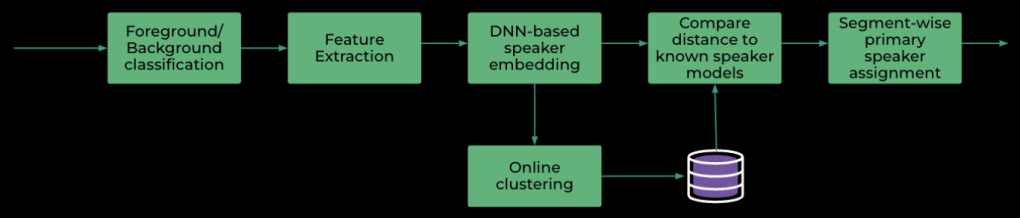
A closer look at how it works:
The foreground/background classification relies on acoustic features such as energy, spectral centroid, and clarity. A simple multivariate Gaussian model, rapidly trained on the initial 0.5 seconds of detected speech, helps identify device-targeting speech.
At the core of the diarization is our lightweight TDNN architecture, designed for real-time streaming. It processes MFCC features, refining them into discriminative embeddings through an “iterative peeling module” that can be viewed as a recurrent network over the distinct speakers. This network is trained with a composite loss function that encourages speaker change identification, clean embedding generation, and proper handling of mixed audio. The net effect: one speaker ↔ one head, stable over time, even through overlaps. The results: fewer false triggers, and faster responses.
Below is the recording of two real MetaAI calls with loud TV in the background, in the first part our PSS solution is not enabled, and the bot is interrupted by the TV voice in the background. In the second part our PSS solution is enabled, and the bot does not get interrupted by the background TV:
PrimarySpeakerSegmentationDemoNew.mp4
3. Echo control:
We combined client-side AEC (to null the acoustic echo path) with server-side echo control to catch stragglers and keep the bot from responding to its own voice. Our system contributes to echo control by identifying TTS (text-to-speech) characteristics and blocking it on the server, using two instances of the primary-speaker segmentation module: one on the microphone input and another on the TTS signal. As an additional safety net, we have implemented a DSP-based echo-suppression module operating in a subband domain aligned with the tokenizer input-signal representation for minimal recognition impact.
Below are two recordings of a conversation with the AI bot: (a) without our echo mitigation, the bot gets interrupted by and responds to its own echo, and (b) with our echo mitigation, the conversation goes smoothly.
These modules, along with an endpointer that helps by using semantic information from the user “turn end” (the point in a human-computer interaction where the user’s part of the conversation or interaction is finished, and it is now the computer’s or system’s turn to respond) give the LLM cleaner, user-centric audio. The endpointer helps further, using semantic information and user speaking patterns to determine the user turn end and prevent the bot from interrupting the user. And because each is observable and tunable, we can iterate quickly when user feedback surfaces a problem.
These advancements have already yielded good results. In internal tests across noisy and conversationally cluttered scenarios, the stack delivered:
- fewer interruptions from background noise and side-speech (e.g., a >50% reduction in certain “AI replied to the wrong thing” categories)
- lower perceived latency, thanks to bursty transport and AI-tuned jitter buffering
- capacity improvements, since the LLM is fed cleaner, shorter prompts
(Your mileage will vary by device, room, and playback level; we continue to track live metrics and user feedback.)
Conclusions and looking ahead
A great voice-user experience doesn’t result simply from a bigger LLM. It requires a holistic effort to optimize the entire system: transport tuned for bots, signal processing that protects the user’s voice, and modular AI that we can inspect and improve quickly. That’s how we get to assistants that listen and respond like people—and know when not to.
We’ve brought these advances to the Meta family of apps (WhatsApp, Instagram, Facebook, Messenger, MetaAI) so that you can ask for help hands-free and get a response that feels natural, even in the real world’s noise.
Future advancements in real-time communication for AI involve developing smarter codecs that prioritize the transmission of semantically relevant information, rather than raw data, to the model. Additionally, there’s a focus on providing richer contextual information at the device’s edge, encompassing device state, proximity, and media awareness, to enable more fluid and natural AI interactions. Finally, promoting interoperability and standardization of human-machine, real-time-communication building blocks will allow for greater flexibility and combinations of modules across different ecosystems. These efforts aim to create standardized codecs for responsive and reliable human-machine communication, enhancing AI’s contextual and situational awareness by efficiently communicating only essential information, potentially in an asymmetric, fast, and responsive manner.

