






Additional authors: Vincent Jiao, Qi Cai, and Tianxiang Dong
Video consumption has exploded across Meta’s platforms, fundamentally reshaping how billions of users engage with digital content. According to Meta’s 2024 Q1 earnings report, video represents more than 60% of time spent on both Facebook and Instagram—and this number continues growing at an unprecedented rate. Video has become an important lever that helps drive user engagement and retention for Meta’s entire ecosystem.
As the backbone infrastructure provider, our Media Foundation team processes and delivers billions of videos daily across Meta’s family of apps (FoAs), including Facebook, Instagram, Meta AI, WhatsApp, and emerging platforms. Our mission is clear: to ensure optimal video quality and user experience for every piece of content that flows through our systems, regardless of its original quality or the device it’s viewed on.
Over the past few years, we’ve invested in cutting-edge encoding technologies to improve delivered video quality. These investments include deploying next-generation codecs like AV1 and HDR encoding, leveraging Meta internal designed MSVP hardware video processor, implementing adaptive bitrate-streaming optimizations, and developing sophisticated quality-measurement systems. Recently, we’ve expanded our focus beyond traditional compression techniques to embrace AI-assisted technologies that enhance video quality at the source level. This includes leveraging generative AI models to create high-quality content and deploying video super-resolution (VSR) and enhancement technologies to improve quality of user-generated content.
In this blog post, we will describe our end-to-end strategy for deploying video super-resolution (VSR) technology at scale to enhance video quality. We’ll provide a high-level overview of different VSR solutions across different platforms, including the optimization techniques for reducing process latency and data-model support for managing multiple versions of enhanced videos. Through these use cases, we will also demonstrate how we leveraged extensive subjective quality evaluation to identify reliable objective quality metrics and co-horts of videos that benefit from VSR.
The challenge: Low-quality video sources
When we looked at where the low-quality videos come from, we identified three primary sources in our ecosystem:
- User-generated content captured with low-quality cameras or in poor lighting conditions, or that were heavily compressed during upload due to lower bandwidth.
- Cross-posted content downloaded from other platforms and then uploaded to Meta’s platforms.
- Legacy content from our inventory, originally created with lower resolution.
For these videos, we can leverage video super-resolution and enhancement technology both on our backend servers and client devices to improve resolution and quality.
Our comprehensive super-resolution strategy
Super resolution (SR) is a technique that enhances the quality of an image or video by increasing its resolution beyond its original capabilities. Nowadays, most of the state-of-the-art super-resolution technology often uses sophisticated AI models trained on vast amounts of video data. Advanced super-resolution techniques can transform grainy and blurry videos and images into sharper, clearer ones, making low-resolution content look much better on modern high-resolution screens. They can also effectively remove artifacts commonly appearing in heavily compressed videos.
At Meta, our approach tackles the problem at two points. Fig. 1 illustrates a high-level processing pipeline and highlights where super-resolution technology can be used.
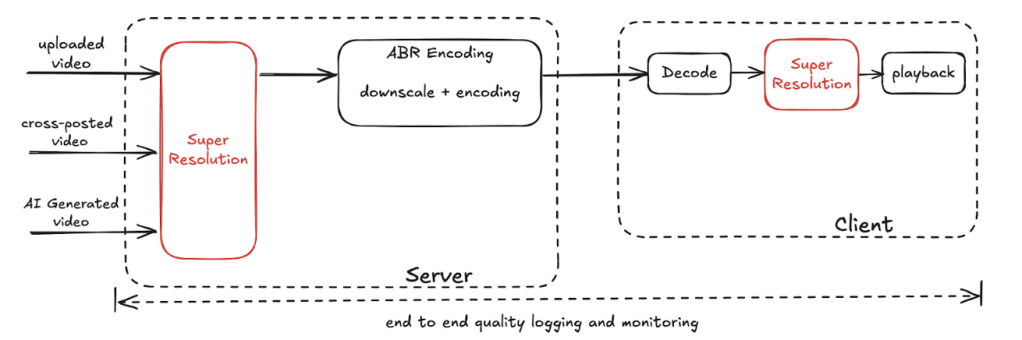
- Server-side enhancement: We can apply advanced super resolution during video ingest to create high-resolution and high-quality source videos for downstream ABR encoding. This approach leverages our robust server infrastructure to run computationally intensive models to maximize quality improvements.
- Client-side enhancement: On the playback side, depending on the network bandwidth, users may only receive a low-resolution and low-quality encoding; in this case we can apply super resolution to upscale it and improve its quality for playback. When it is enabled on the client-playback side, super resolution allows users to enjoy high-quality content without needing a high-bandwidth internet connection, as it enhances the video quality locally on their device. Given the power and compute limitation, it is still very challenging to enable advanced super-resolution technologies on typical mobile platforms on the consumption side. The solutions deployed on the client side have to be lightweight and do not consume huge amounts of battery power. We often leverage built-in solutions from mobile SoC vendors to avoid high-power consumption.
Similar to any other technologies we deployed in the past, we also enable end-to-end quality logging and monitoring to measure quality improvement from super resolution.
Increasing the resolution of the source videos on the server side will increase the bitrate of downstream ABR encodings and thus egress. In contrast, upscaling on the client-playback side does not incur any bandwidth increase. Thus, there are questions about whether super resolution should be enabled on the server side before ABR encoding or on the client-playback side. To answer these questions, we have conducted extensive studies to evaluate the impact of combined super resolution on both the server and client sides to the end-to-end quality and compression efficiency. Our study’s high-level insight can be summarized as the following:
- Advanced super-resolution algorithms on the server side can significantly improve subjective quality and compression efficiency even after subsequent ABR encoding. When the client side enables upscaling algorithms, using conventional upscaling algorithms, such as Lanczos, on the server side can still give us extra efficiency gain, but the gain is lower than using advanced super-resolution algorithms.
- Regardless of whether server-side super resolution is enabled or not, using better upscaling or super-resolution filters on the client-playback side can always improve playback quality. When server-side super resolution is enabled, the improvement from better upscaling algorithms on the playback side will be smaller.
From this study, we can see that server-side and client-side super-resolution technologies compliment each other.
For the rest of this blog post, we will focus mostly on technologies deployed on the server side at the ingestion and creation stages. As an infrastructure provider, we want to support a range of super-resolution algorithms with different quality and complexity tradeoffs, so the product teams can choose the best solution.
The growing demand for AI-powered features across our product portfolio means GPU resources demand increases, so we are interested in seeking alternative processing approaches. Our partnership with Intel enabled us to deploy advanced super resolution on standard x86 CPU infrastructure. By adopting Intel’s iVSR SDK, we’re leveraging a middleware stack that abstracts away the complexity of AI-based video processing while offering seamless integration via a plug-in for FFmpeg. The iVSR SDK supports multiple video-enhancement filters that come with several high-performance, pre-optimized super-resolution models, including EDSR, TSENet, and BasicVSR, among others. The ability to deploy these advanced AI models, on standard x86 CPUs using Intel’s OpenVINO toolkit, eliminates our dependency on scarce GPU resources. This unlocks both operational scalability and cost efficiency across our infrastructure. Hence, partnering with Intel enables us to democratize high-quality video upscaling across all environments, bringing AI-powered super resolution to products that were previously bottlenecked by limited GPU availability.
On the other hand, we can also still deploy advanced VSR models that can run on GPUs for use cases that require close integration with other GPU models and lower end-to-end latency.
Production deployment: Real-world impact
Recently, we have deployed VSR in the Meta Restyle feature. Meta Restyle represents the cutting edge of AI-powered content creation. It allows users to transform photos and short video clips by changing outfits, backgrounds, lighting, and artistic styles using preset options or custom prompts, available in the Meta AI app and Instagram Edits app and on AI glasses. The MovieGen model is used to generate restyled videos from the original user-input videos, and needs to be executed on dedicated GPU hosts. Fig. 2 illustrates a high-level pipeline process flow. First, the input video will go through a pre-processing stage, in which the video will be converted into a certain format for MovieGen model inference. After the new video is generated by the MovieGen model, it will go through the post-processing stage, in which, depending on the users’ request, we can apply frame-rate conversion as well as super resolution to improve the resolution and quality of generated video.
Input Video: Input.mp4
Output Video: Output.mp4



In Fig. 3’s side-by-side comparison, we can observe that video processed by the super-resolution model is sharper and crisper.


Figure 3. Side-by-side comparison of conventional upscaling solution versus super resolution for a MovieGen-generated video
In the Restyle use case, to reduce end-to-end processing latency, we need to run the super-resolution model together with the MovieGen model on the same GPU host. To further reduce the latency, we can split the video into multiple segments, process them in parallel on multiple GPUs and then merge them together at the end. (See Fig. 4.)
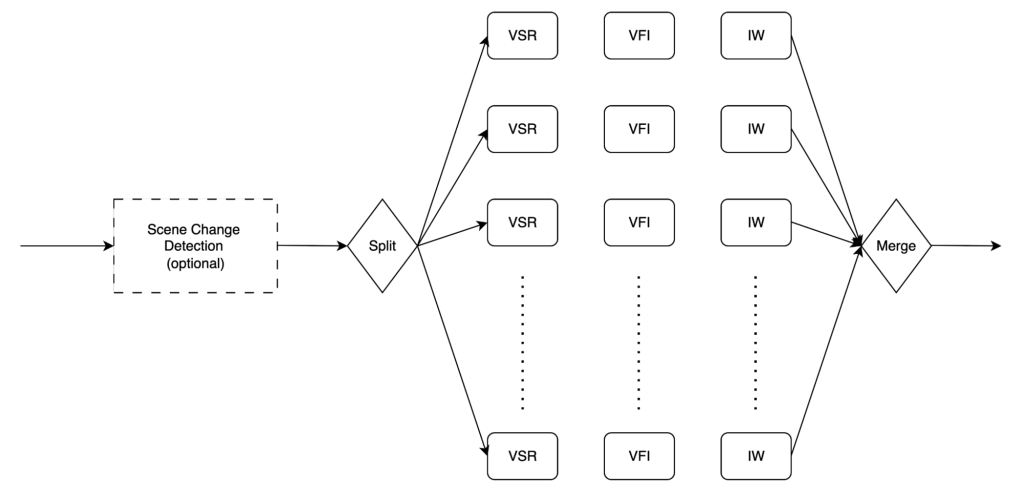
The integration of super resolution into this pipeline demonstrates how enhancement technologies can augment generative AI capabilities.
Scaling challenges and solutions
Multi-variant support for VSR deployment
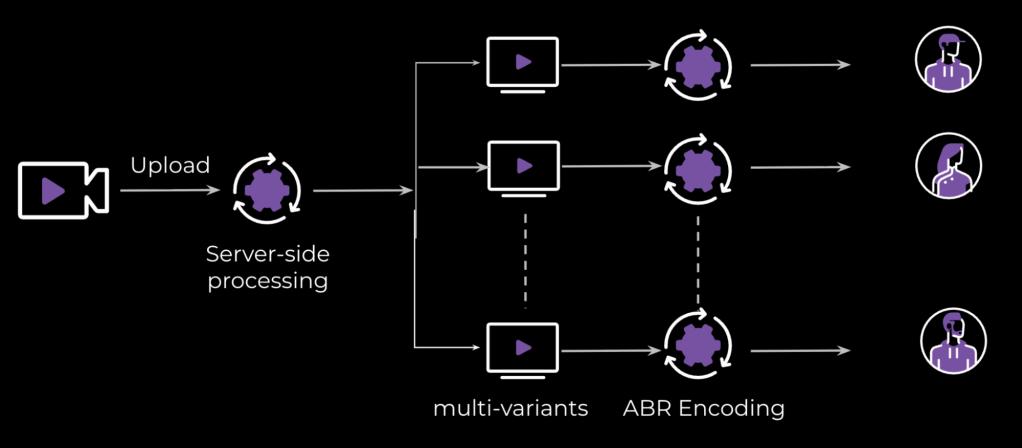
For every video that’s user created, we create a data model in the backend to manage the video over the course of its lifetime. When we apply super-resolution or video enhancement to a video, we are not creating a new video but rather a different version of the same one. To control the processing and delivering of the different versions, we improve the existing data-model implementation with multi-variant support. With this new feature, we can apply different enhancement technologies for the same video to create multiple variants as the new source; then we can control which variant should be encoded and delivered to end users. (See Fig. 5.)
Subjective evaluation at scale
When we need to deploy super resolution at scale in production, we face many challenges. From a quality point of view, we need to select which VSR model to use. There are many super-resolution solutions, so we need to evaluate their quality and complexity to select the proper ones to deploy. And unlike the video-compression domain, in which there are well-established quality metrics and methodology that can be used for benchmarking different codecs, for VSR there are no reliable quality metrics for measuring quality improvement. Last, there is also no mechanism for detecting potential artifacts that could be introduced by super resolution. There are many production use cases that can leverage super resolution, and they have different requirements regarding how to opt into this technology. As we enable AI-driven enhancements, we want to make sure VSR preserves the creator’s intent without fundamentally changing the original content.
To address these challenges, we rely on large-scale subjective evaluation to help us answer the following questions:
- Can we leverage subjective evaluation to evaluate the impact of super resolution? How do different super-resolution algorithms compare in terms of quality improvement?
- How do objective metrics correlate with the subjective quality evaluation of SR? Which objective metric can be leveraged for SR monitoring at scale, or for intelligent deployment of super resolution?
- Can we evaluate the risks of super resolution, such as artifacts on edge-case videos, by leveraging subjective evaluation at scale?
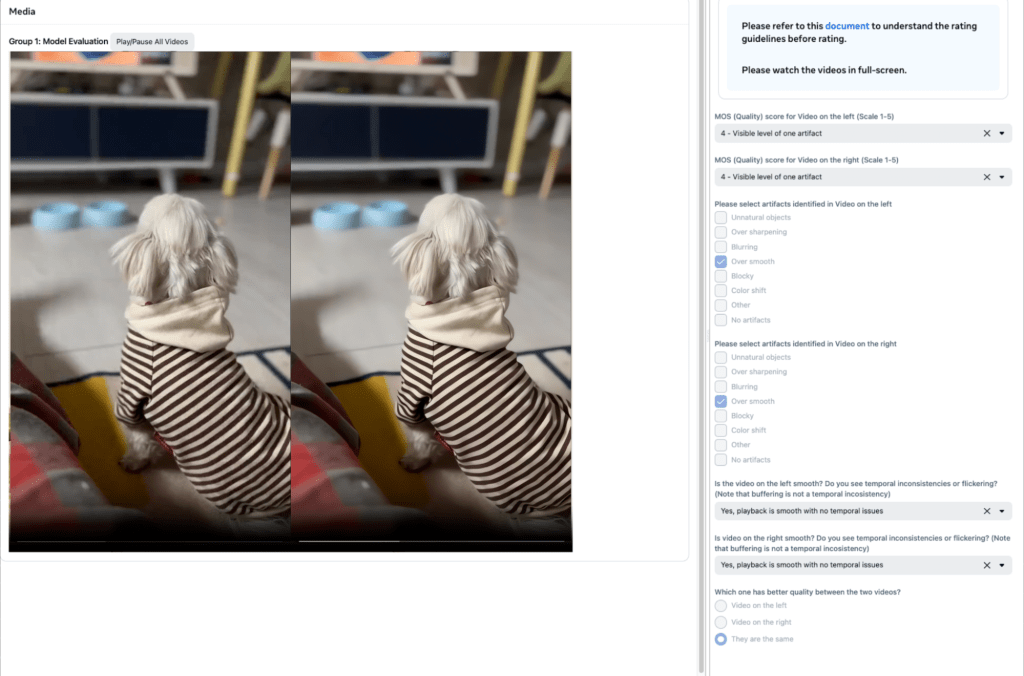
As illustrated in Fig. 6, for subjective evaluation, we build the automated framework to show videos processed by different VSR algorithms side by side; we then ask raters to provide an MOS score for each video and also to indicate their preference. We also ask raters to label any artifacts they observed in the video. After gathering all of the raw rating results, we leverage the state-of-the-art SUREAL MOS recovery method to analyze the data. The subjective evaluation is systematically platformed to speed up the model iteration.
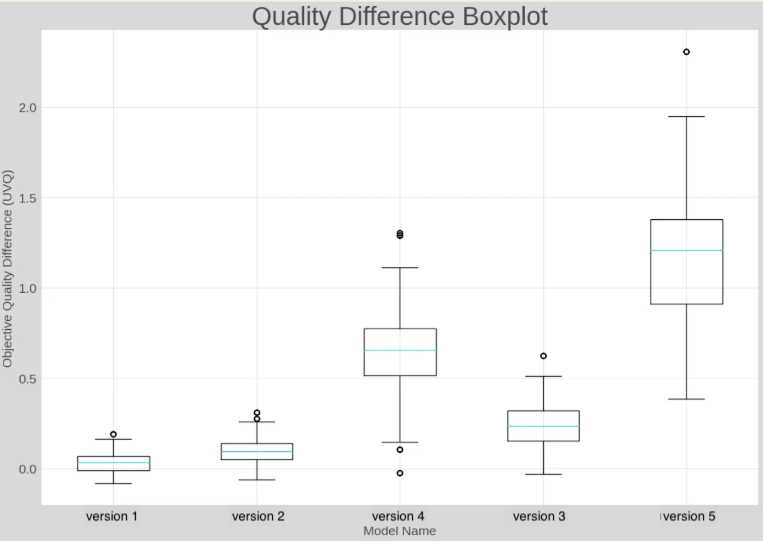
After many rounds of subjective eval, we have identified an effective, objective, quality metric, UVQ, developed and open sourced by Google, that shows very good correlation with human subjective rating. In Fig. 7, the left side shows the MOS improvement score of different super-resolution algorithms, and the right side displays the delta UVQ scores. As you can see, the order for the VSR quality improvement measured by delta UVQ aligns well with the one measured by subjective evaluation. This means UVQ can be used to predict which VSR model has better quality.
Percentage MOS score improvement compared to baseline
Quality improvement (in Δ UVQ) of different super resolution algorithms against baseline
Figure 7. Correlation between subjective MOS score and UVQ
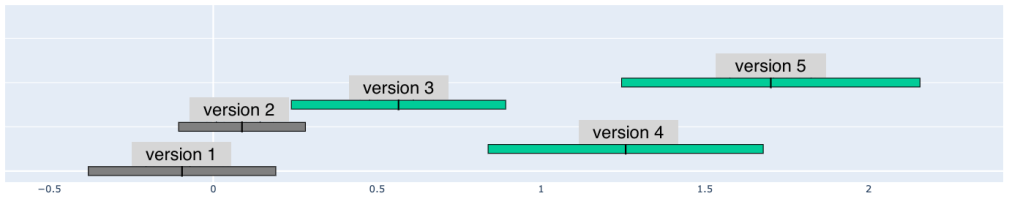
When we further sliced and diced the data, we found out that only videos with medium to high quality can benefit meaningfully from super resolution. If the quality of the input videos is very low, applying super resolution will not show noticeable quality improvement, as illustrated in Fig. 8. This finding can also help us target super resolution to specific cohorts of videos and reduce overall compute cost.
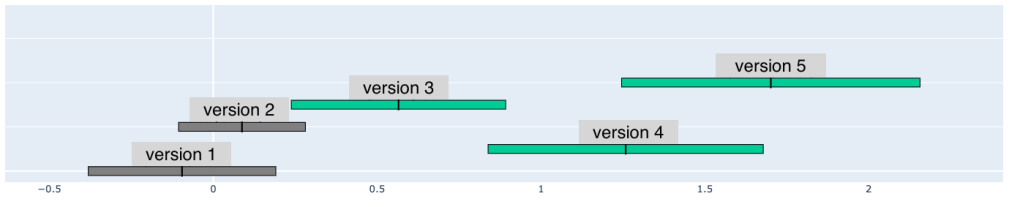

Figure 8. Quality improvement from VSR for videos with different source quality
Based on the human labeling of the artifacts noticed, we can also analyze the risk with different VSR solutions and iterate on model training to improve the quality to mitigate the risk.
Looking forward
Deploying video super resolution at Meta’s scale required overcoming technical and operational challenges. We have worked through many obstacles to identify proper VSR solutions to use for different use cases, and build a robust portfolio of solutions spanning generic CPUs and GPUs. To ensure we continuously deliver the best possible video quality to the end user, we have conducted extensive subjective evaluations to identify reliable quality metrics we can use to measure and monitor quality improvements achieved by VSR, and we’ve gained crucial evidence from use cases indicating that VSR is effective.
Our learnings:
- Combined approach works best: Combine server-side and client-side super resolution for optimal results.
- Quality metrics matter: Reliable objective metrics are essential for production deployment at scale.
- Target intelligently: Focus enhancement on medium- to high-quality source videos for maximum impact.
- Resource optimization: CPU-based solutions can effectively democratize AI-powered enhancement.
We believe that the challenges we are facing are common for anybody who wants to deploy advanced super-resolution or video-enhancement technology in production. We want to share our learnings from this journey to foster collaboration and advance the field of production-scale, video-enhancement technology.
Acknowledgement
This work is a collective effort by the Media Foundation team, Instagram, Monetization GenAI team at Meta, along with our partner at Intel. The authors would like to thank Sameeran Rao, Andrew Borba, Kevin Chang, Kaveh Hosseini, Runshen Zhu, Lu Chen, Russel Lu, John Liu, Nicolas Lepore, and Mark Sim for their contributions, and Shankar Regunathan, Ioannis Katsavounidis, Denise Noyes, Srinath Reddy, and Abhinav Kapoor for support and advice.

