






Additional Author: Raman Sukhau
AI training is scaling faster than ever, and with it, the demands on data center network infrastructure are increasing exponentially. Training large models no longer means just moving bigger datasets—it means moving them rapidly and more frequently.
Checkpoint sizes have ballooned from gigabytes to terabytes—and sometimes even petabytes—making rapid reloads essential. Whenever a crash or restart occurs, massive checkpoints must be reloaded within seconds to prevent thousands of GPUs from sitting idle, which would waste both time and money. To support this scale, Meta’s networking infrastructure must keep pace with evolving hardware generations such as H100, GB200, and beyond, each offering distinct performance profiles.
Complicating matters, our fleet isn’t homogenous, and it is evolving rapidly. Some servers still run with two NICs (network interface cards) while others have four, and not just more ports but also much faster ones (200G and greater). As the hardware advances, we want our workloads to scale with it—automatically. But that’s not easy when AI jobs span such a diverse fleet. The solution must be as transparent as if we had a homogenous fleet. Otherwise, if every AI application has to be rewritten to keep up with hardware changes, progress will grind to a halt.
In this blog post, we’ll walk you through how we tackled this important bottleneck by using transparent multi-NIC routing, to build efficient, future-proof network infrastructure for AI workloads.
Real-world bottlenecks in AI training infrastructure
Most AI applications are agnostic to the underlying hardware. When terabytes of training metadata and parameters are injected, however, the data can easily choke the ingress path—especially if only one NIC is used, despite multiple NICs being available on the host.
Similarly, during checkpointing, pushing large volumes of data out through a single NIC can overwhelm the network, increasing overall checkpoint and data-injection times and leaving GPUs idle.
Another major challenge is hot sparing. To recover from failures with minimal delay, hot sparing relies on the most recent checkpoint data. Any delay in checkpointing forces the system to fall back on older data, wasting valuable GPU compute cycles.
So whether the bottleneck is checkpoint I/O or data ingestion, the result is the same: GPUs go idle, recovery slips, and there’s low ROI.
Solution: The four principles of transparent multi-NIC routing
To eliminate network bottlenecks and make full bandwidth available to every application, we focused on four foundational principles:
- Aggregate all available NICs: Transparently combine the bandwidth of every NIC on a host, so applications benefit from a single high-capacity “funnel” instead of isolated “pipes.”
- Application and hardware agnosticism: Data scientists and engineers never need to re-compile code or reconfigure IP addresses. The same code runs seamlessly on both development and production hardware, regardless of NIC count.
- NUMA-aware routing: Outgoing data is sent through the NIC closest to the CPU or GPU, minimizing latency by keeping packets on their “home island” and avoiding cross-socket DMA transfers.
- No switch reconfiguration: Top-of-rack (ToR) switches use ECMP (equal-cost multipath) load balancing to distribute traffic across all physical NICs, with no need for disruptive network changes.
By following these four principles, we effectively turn all NICs on a host into a single, massive 800G link. This enables large-scale jobs (4,000 to 8,000 GPUs) to checkpoint frequently and recover from failures with minimal delay, saving substantial resources and costs.
Implementation of foundational principles
At Meta, nearly all large-scale AI workloads run inside containers. This approach provides strong security boundaries, resource isolation, and operational flexibility. But it also introduces unique networking challenges—especially when maximizing bandwidth across multiple physical NICs.
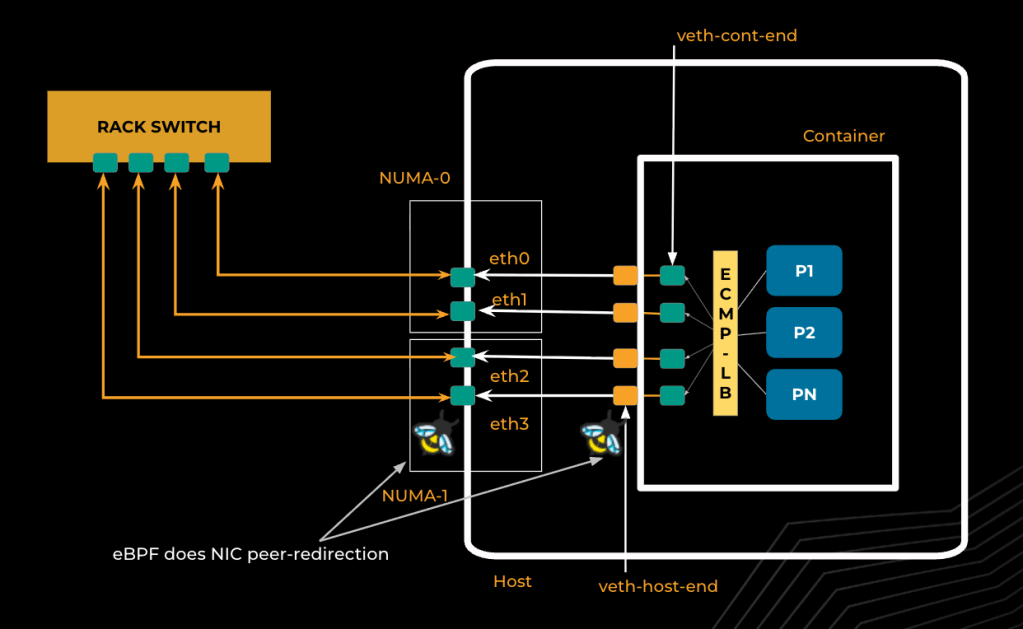
Every container is provisioned with its own set of virtual Ethernet (veth) interfaces. For each physical NIC on the host, we create a lightweight veth pair. One end is attached to the host’s physical NIC, and the other is exposed inside the container as a virtual NIC. Containers see multiple network interfaces, each mapping directly to a physical NIC, but remain isolated from the host and other containers.
To distinguish traffic and manage routing per container, we assign an unique IP address to every container in the fleet. With multiple NICs exposed to AI workload containers, we allocate a unique IP per veth NIC of the container, which results in multiple IPs pointing to a single workload container. This enables fine-grained control over traffic flows and simplifies network management, ensuring that each NIC can be independently addressed and utilized.
Achieving line-rate performance with eBPF acceleration
Container isolation via virtual NICs introduces network-performance bottlenecks due to extra stack traversal. To address this, we leverage eBPF (extended Berkeley Packet Filter) for traffic acceleration.
With eBPF, incoming packets are efficiently redirected at the physical NIC to the correct container’s veth interface, while outgoing packets from containers are sent directly to the physical NIC, bypassing unnecessary layers in the network stack.
Additionally, to maintain both efficiency and correctness we exclude traffic destined for the local host from eBPF-based routing. This approach allows us to achieve near line-rate performance for container networking, combining strong isolation with high throughput and low latency.
Egress routing: Scaling out with ECMP
Effectively utilizing all available NICs for outgoing traffic is a common challenge in multi-NIC environments. The goal is to maximize bandwidth without requiring changes to application code or manual NIC selection. As shown in Fig. 1, our architecture combines eBPF and ECMP routing to seamlessly distribute outbound traffic across multiple NICs, both inside the host and within containers. This approach ensures optimal bandwidth aggregation and simplifies network management for workloads.
ECMP default route setup
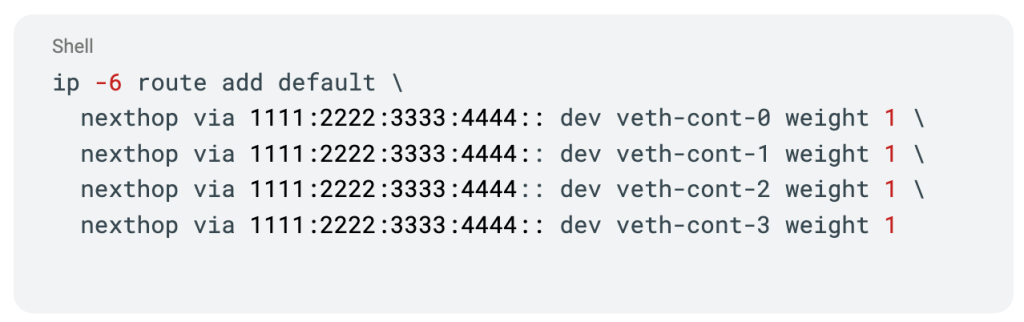
Configuring containers with an ECMP default route enables efficient traffic distribution across multiple veth NICs. By setting up the network stack so that each veth NIC is a next hop with equal weight, the Linux kernel can use the flow’s 5-tuple (source and destination IP, protocol, source and destination port) to select a NIC for each flow. This ensures that traffic is evenly balanced across all available interfaces, as shown in the routing table settings in Fig. 2.
This approach allows containers to transparently aggregate bandwidth from all NICs, maximizing throughput without requiring any changes to the application code. Flow stickiness can be controlled via the /proc/sys/net/ipv6/fib_multipath_hash_policy flag, giving fine-grained control over how flows are distributed. The result is improved bandwidth utilization and efficient load balancing, all managed at the kernel level.
Flow distribution and kernel-path selection
As the kernel maintains a cache of flow-level tuples, it ensures that packets for the same connection always use the same NIC, preserving packet order and reliability. By adjusting the hash policy, we can consistently select the same route for each unique flow, piggybacking on the kernel’s built-in mechanisms.
With this approach, multiple flows are distributed across all NICs according to kernel-path selection rules, allowing us to fully utilize the available hardware bandwidth.
By combining ECMP with kernel-level path selection, we could finally balance the load evenly across all NICs. However, as our workloads and models continued to grow, another challenge emerged: scaling data ingestion for ever-larger AI training jobs.
Ingress routing: Multipath data ingestion
In a typical setup, incoming traffic is funneled through a single NIC based on the IP routing next-hop configured at the switch. This creates a bottleneck just before data reaches the training job, limiting the ability to fully utilize available bandwidth.
To overcome this, we transform the single trail into many lanes by introducing two key components that enable efficient data ingestion across all NICs:
Extended virtual IP (VIP) model
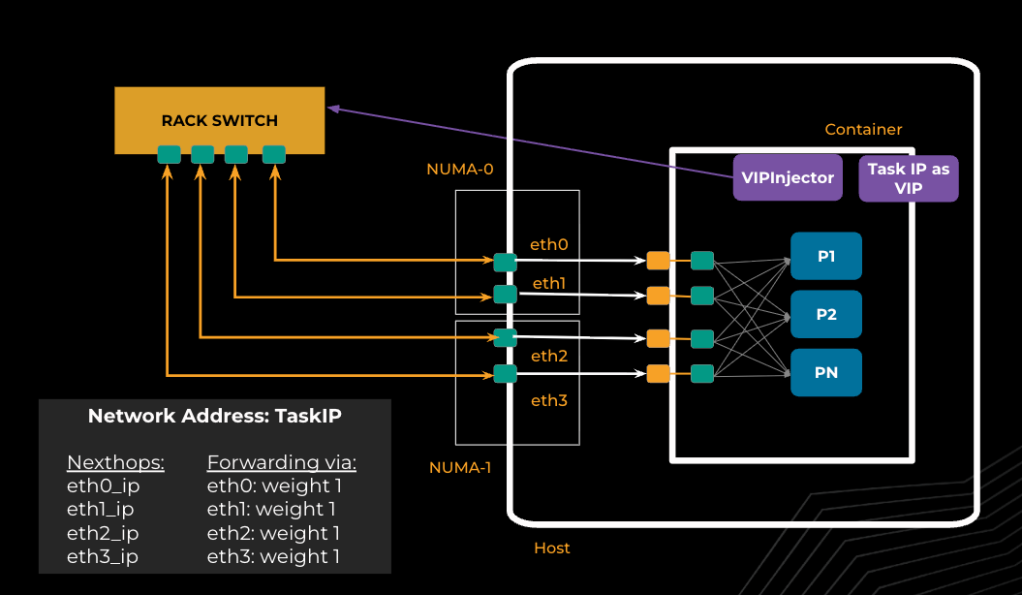
Traditionally, VIPs are abstract addresses decoupled from physical interfaces, used for high availability and load balancing. In our GPU servers, each training job is assigned a task IP derived from the host’s physical subnet. We treat this task IP as a VIP, decoupling it from any specific NIC. This abstraction allows us to dynamically assign multiple physical NICs as next hops, enabling ECMP forwarding for incoming traffic.
VipInjector: BGP sidecar for dynamic routing
To make dynamic routing possible, each container runs a lightweight BGP peer called VipInjector as a sidecar service. VipInjector establishes and manages BGP sessions with the top-of-rack (ToR) switch. It advertises the task IP as a VIP to the ToR switch, with multiple equal-cost next hops—each representing a physical NIC.
The ToR switch then builds an ECMP forwarding table, as shown in Fig. 3, using consistent hashing to assign incoming flows to dedicated NICs. This evenly spreads traffic across all available NICs, maximizing ingress bandwidth and eliminating the bottleneck at the host.
Resilience and failover
High availability and seamless failover are essential in multi-NIC environments, where any single point of failure can disrupt critical workloads. Our solution is designed to provide robust resilience by leveraging the intelligence of the network layer, all while keeping things effortless for application developers.
When an NIC experiences a failure, the ToR switch instantly detects the issue and removes the affected link from the ECMP group. Flows that were previously routed through the failed NIC are automatically rehashed and redistributed among the remaining healthy NICs, ensuring that data continues to flow without interruption.
This entire process is handled transparently at the network layer—applications remain completely unaware of the underlying changes and require no code modifications or manual intervention, even in the face of hardware failures.
Scalability: Hierarchical address aggregation
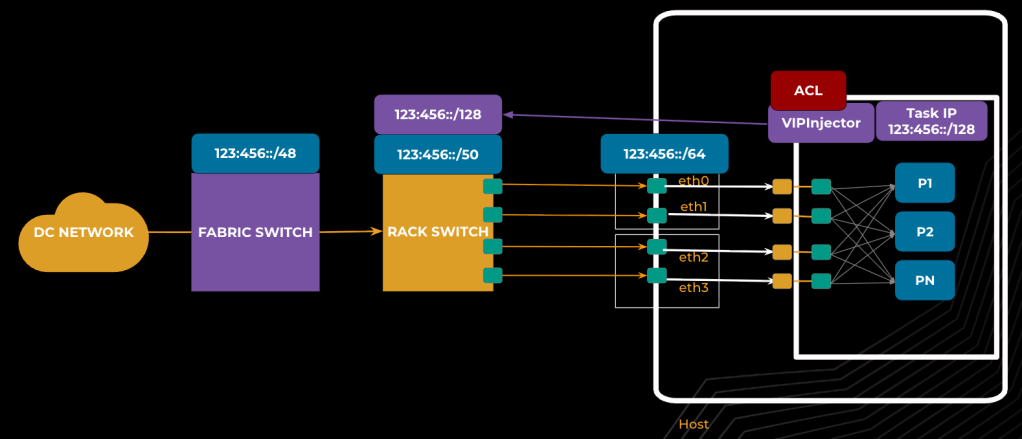
Managing thousands of simultaneous training jobs presents a significant challenge for routing table scalability. To address this, our data center network employs a hierarchical strategy for address allocation, aggregating address space from the region level all the way down to individual NICs. This approach means that, rather than propagating routes for every task IP, we can rely on aggregated routes between network layers. Task IPs are allocated within NIC subnets, making them easily routable through this aggregation.
After VipInjector announces a task IP to the ToR switch, routing policies ensure that these routes do not propagate beyond the ToR, keeping the broader network free from unnecessary route churn. The ToR switch itself uses longest-prefix match (LPM) to prioritize task IP routes over NIC subnet routes, maintaining both efficiency and scalability. Fig. 4 illustrates how this address aggregation path streamlines routing and supports massive scale.
Security and policy enforcement
Security is a foundational aspect of our networking architecture. VipInjector enforces strict access controls, ensuring that only the legitimate training job can announce its task IP and preventing any possibility of traffic hijacking. BGP sessions are continuously monitored for health and correctness, which helps maintain robust connectivity throughout the infrastructure.
Importantly, infrastructure VIPs are strictly internal, used solely for routing within the data center and never exposed to the internet or external BGP peers. This layered approach to security and policy enforcement allows us to scale confidently while protecting the integrity of our network.
Performance results: Real-world impact of bi-directional ECMP
As mentioned earlier, a shift in traffic patterns led to a surge of backing data within the region that overwhelmed the host’s NIC and created a severe bottleneck. During the runs, we began noticing severe latency spikes in job read—-from a baseline of eight seconds, up to 300 seconds.
We deployed our implemented bi-directional ECMP solution, for both egress and ingress traffic, to test on a production-scale AI-training job. That proved to distribute the traffic evenly across all the available NICs, aggregated bandwidth for both reads and writes, and adapt to traffic surges and link failures. Fig. 5 shows the observed performance improvement after rolling out the solution:
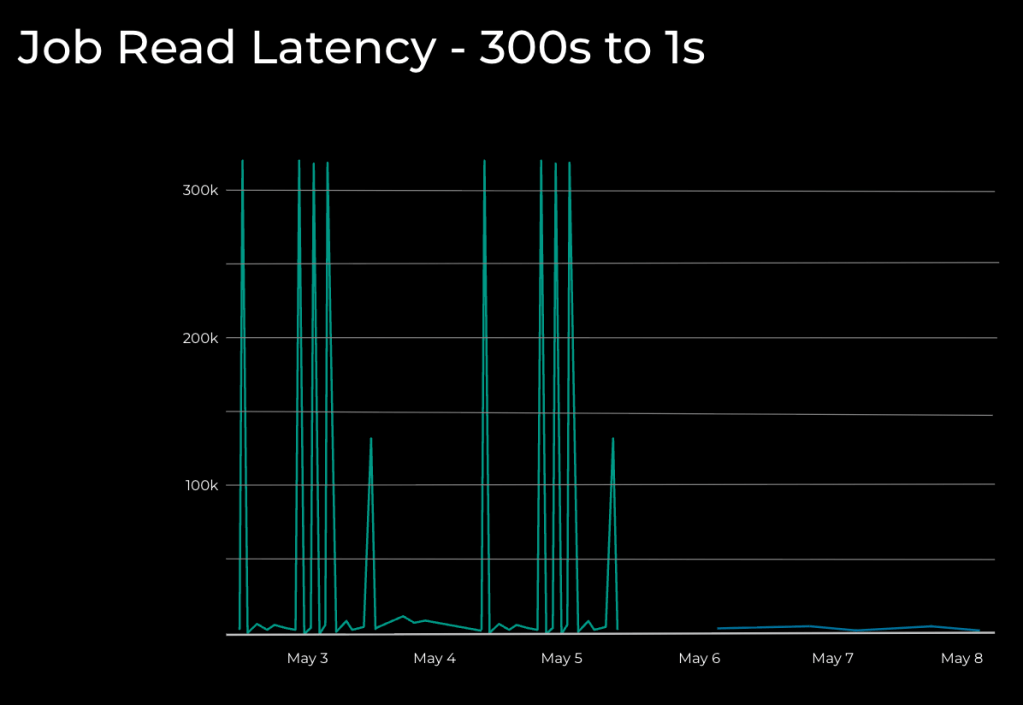
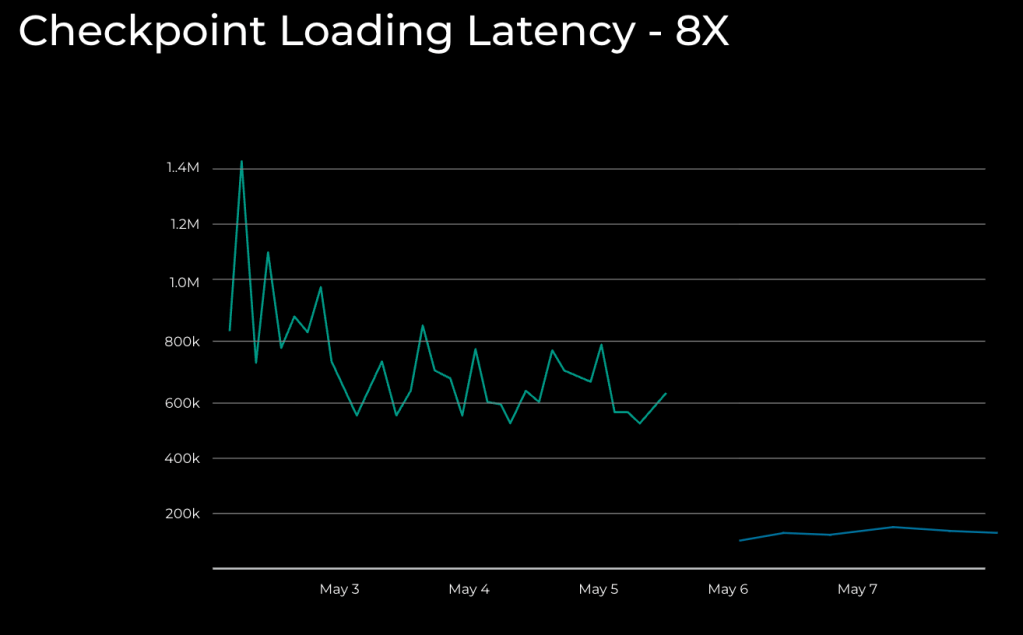
Figure 5. Performance comparison before and after applying the solution
Key highlights
Without the solution in place, latency spiked up to 300 seconds during peak traffic, whereas after deploying the ECMP-based solution, we could see latency drop back to one to eight seconds, even under heavy loads.
Our solution also showed significant improvement—to 8x—in checkpoint loading time, allowing faster recovery and minimizing GPU idle time. The improvement translated directly into lower operational costs and higher overall throughput—key wins for both infrastructure engineers and data scientists.
Future directions: Advancing multi-NIC networking at Meta
As we look ahead, our focus is on further optimizing both egress and ingress paths for AI workloads—making them smarter, faster, and even more transparent. Here’s how we’re pushing the boundaries of data center networking:
- Deepening NUMA awareness for every flow
To further optimize performance, we’re developing per-flow NUMA (non-uniform memory access) awareness. This means every packet will be routed through the NIC closest to its originating CPU or GPU, minimizing cross-NUMA memory and CPU hops—key sources of latency and reduced throughput. By aligning network paths with hardware topology, we expect to achieve lower latency, higher throughput, and more predictable performance, even as cluster topologies evolve.
- Transparent multipath TCP (MPTCP) integration
We’re also working on integrating multipath TCP (MPTCP) to make multi-NIC utilization seamless and robust. MPTCP enables a single TCP connection to use multiple network paths at once, allowing us to aggregate bandwidth across all NICs without requiring any changes to application code.
This integration brings several key advantages. First, it ensures optimal NIC utilization, as every available interface contributes to the connection, maximizing overall bandwidth. MPTCP also enhances resilience: If one NIC or network path fails, traffic is automatically shifted to healthy paths, maintaining uninterrupted connectivity. The approach is remarkably simple, eliminating the need for VIP injection or complex BGP configurations, which is especially beneficial in environments where switch control is limited.
Unlike traditional ECMP routing, MPTCP is congestion-aware. It can detect congestion on individual paths and dynamically adjust traffic distribution, shifting flows away from congested NICs to maintain optimal throughput and minimize latency.
This host-based solution is particularly valuable in clusters or data centers where network switches are difficult to control or reconfigure, making it easier to deliver high performance and reliability for demanding AI workloads.
Where we’re headed next
Meta’s commitment to infrastructure innovation means we’re always seeking new ways to make AI training faster, more reliable, and more scalable. By deepening NUMA awareness and integrating transparent MPTCP, we’re building a future-proof foundation for the next generation of AI workloads. These advancements will help us deliver higher performance and resilience across our data centers, ensuring that our infrastructure keeps pace with the evolving demands of AI.
Stay tuned for more updates as we continue to push the limits of data center networking!
Acknowledgments
We would like to thank our supportive engineering leaders—Burak Gurbuz, Hyojeong Kim, and Sargun Dhillon—who have been evaluating tech stack components and providing feedback as we built this impactful solution.

