





Facebook has billions of users across numerous products, including Messenger, Newsfeed, Instagram, Watch, Marketplace, WhatsApp, and Oculus. Thousands of interconnected services support these core products. Each service engages in a constant state of improvement: optimizations get made, bugs and security vulnerabilities patched, and new features added.
Teams must frequently roll out new versions of code to these production services as safely as possible. For example, when a team or external researcher identifies a security exploit, affected teams must roll out a patch quickly to protect against bad actors. Likewise, infrequent deployments result in a large number of changes landing at once, making debugging breakages difficult. With countless developers working across a single monolithic codebase, bugs represent an unpreventable aspect of the software lifecycle. To be resilient, Facebook’s tooling should catch these bugs early and prevent them from breaking production.
In this blog post, we describe how Facebook’s unified Continuous Deployment (CD) system, Conveyor, powers safe and flexible service deployment across all services.
Conveyor Platform
Conveyor, a scalable CD solution, boasts the capability to achieve over 100k deployments each week across a diverse range of services. Note that the name “Conveyor” refers both to the Conveyor Platform and the team supporting it. In contrast, a “Conveyor pipeline” refers to a deployment pipeline supported by the Conveyor Platform. Each pipeline consists of various “nodes”, each performing one aspect of the deployment for a single service. Each version of a service’s code passes through the Conveyor pipeline as a “bundle” containing a packaged binary. Conveyor’s naming draws inspiration from industrial conveyor belts, where automation passes bundles of raw materials to various stations to create a final product.
The most frequent nodes include:
- Build, which compiles, unit tests, and packages an application at regular intervals. Conveyor does not perform the compilation and execution of unit tests. Instead, Contbuild, Facebook’s Continuous Integration (CI) system, handles these tasks. Upon a successful build with passing tests, the Build Node creates and packages a binary in one of a few formats. Common formats include .rpm, or fbpkg, Facebook’s blob distribution service based on BitTorrent. Upon success, a new bundle gets created, and proceeds to the next node.
- Canary, which temporarily deploys a packaged binary to either a testing environment or a subset of production and detects regressions through A/B testing.
- Push, which incrementally deploys the binary to production
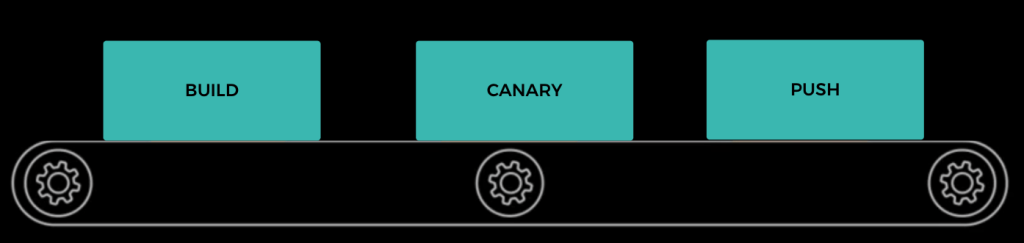
A Conveyor Config defines a Conveyor pipeline, allowing users to specify the nodes that make up their pipeline. Each node has a type, along with additional configuration information specific to that node type. Conveyor is generic, allowing teams to implement their own nodes. These nodes typically verify the binary contained within a bundle functions correctly through load or End-to-End tests. However, the Conveyor team offers a few “core” nodes out of the box, which comprise most teams’ Conveyor pipelines: Build, Canary, and Push. Build nodes always occur first, as they integrate with CI to create bundles, while Push nodes are usually last.
An example Conveyor Config might be:

This post explores the final stage of the deployment process: Push, wherein a new binary is “pushed” to the service in gradual steps. To learn more about other aspects of Conveyor, like Build or Canary, check out this previous Systems @ Scale discussion.
Services
At Facebook, we loosely define the term “service” as a collection of processes, available over a network, implementing some functionality. This includes back-end services running on Facebook’s container system, Twine, like those that power Facebook’s Newsfeed back-end. However, Facebook’s notion of services extends to code running on bare metal machines or other devices. It further extends to a more abstract class of services. Hosted stream-processing applications, as one example, power real-time analytics on large streams of Scribe data.
Push
At Facebook, a push entails a long-running workflow which deploys a new version of a service. Most pushes get scheduled through Conveyor and are “hands off”, although a command line tool may also start pushes. This can be helpful in the event of a breakage. If a team’s core service breaks, they may need to roll out a fix quickly. Landing the fix and waiting for Contbuild and Conveyor to “pick up” the new version of code induces additional latency. Instead, users might prefer to build the code themselves to deploy immediately through our command line.
To avoid wasting developer time, code deployments should be extremely automated. To achieve this, they must also be safe. If a service owner trusts that regressions won’t break production, they won’t have to continuously monitor each deployment. Instead, service owners should be able to land their code without thinking about deployment. However, if our system can’t safely deploy a version due to a regression, we should notify the relevant service owners.
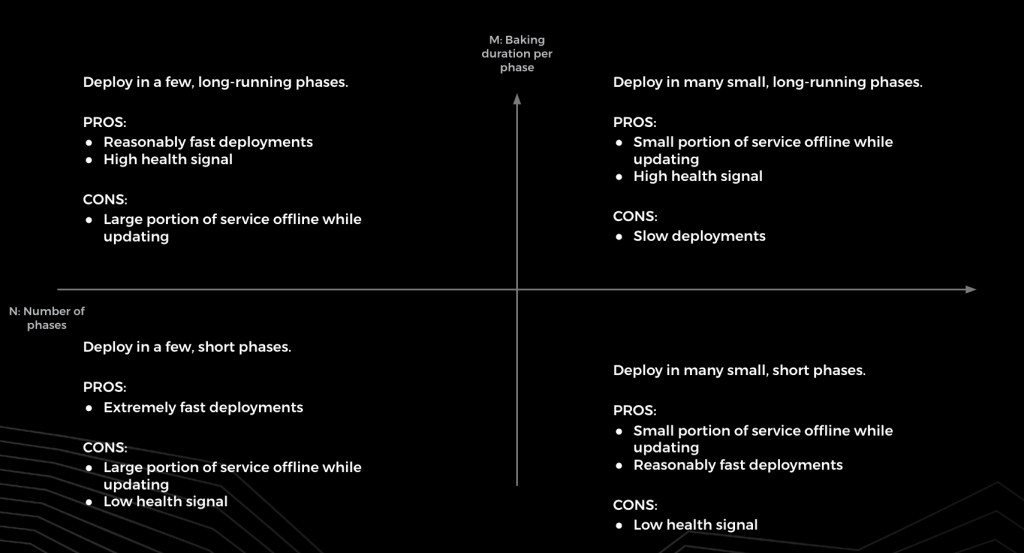
So, in order to prevent regressions from breaking production, pushes should be carried out incrementally. If something breaks, it should only break a small part of the service. With upstream retries/failover many systems at FB consider a partial breakage within a confined time frame acceptable. Teams that can’t tolerate even small breakages might instead run new versions of code against “shadow” traffic in a tier isolated from production traffic.
Pushes consist of N phases, where N represents a user defined positive integer. Each phase involves sending and monitoring the success of updates. Each phase also includes a “baking” period of duration M, which allows our system to assess the healthiness of the system. Push duration correlates with N * M, and tweaking these variables provides flexibility for service owners.
Consider a flow-chart illustrating the lifecycle of a single push:
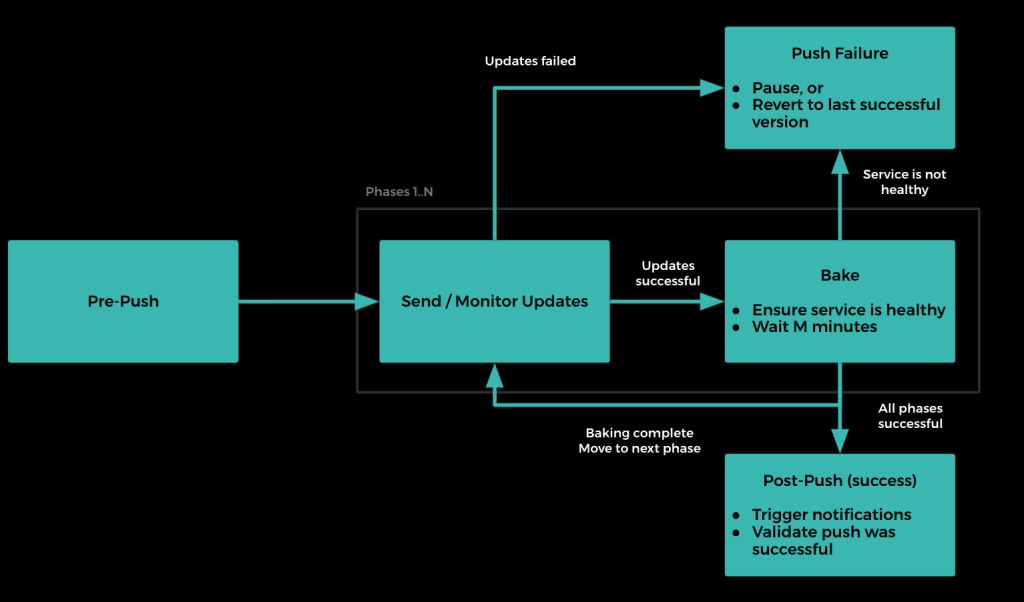
While a push should be a relatively hands-off process, Push offers various ways in which service owners can interact with the deployment through a User Interface. Users can perform the following actions on a Push: pause, resume, cancel, revert, skip phase(s), skip healthcheck(s), skip baking.
Push Infrastructure
Various components comprise the Push System, a subset of the Conveyor system: Push Infrastructure
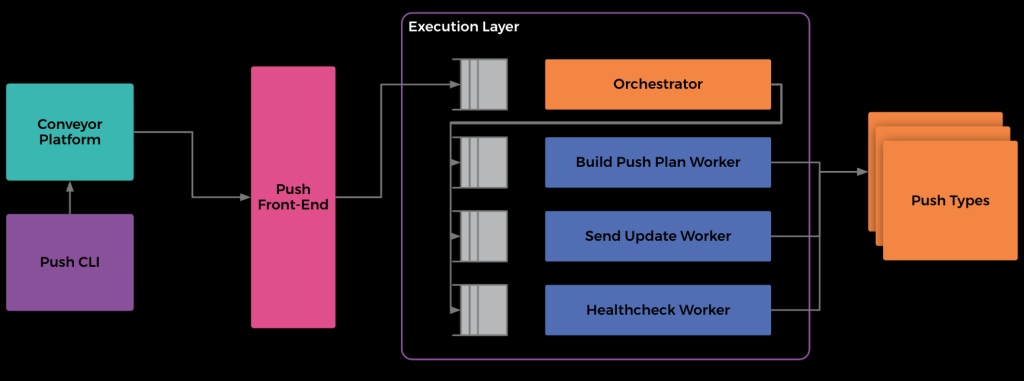
- The Push Command Line (CLI) tool, which we roll out to developers’ development servers. It allows users to start, stop, and pause pushes, as well as skip healthchecks or baking. This lightweight command line primarily interacts with Push through an API provided by Conveyor.
- The Conveyor platform itself is responsible for scheduling / starting pushes. It provides a User Interface where service owners can visualize code moving through their deployment pipeline in bundles. The Conveyor Platform interacts with Push Front-End to perform similar operations to CLI, e.g. starting/stopping a push.
- The Push Front-End represents the “entry point” to the push process and handles authentication, validation, and initialization of the push. For example, teams shouldn’t be able to push other team’s code, and our system shouldn’t start misconfigured pushes. Once the Push Front-End completes authentication and validation, it starts a push through the Execution Layer
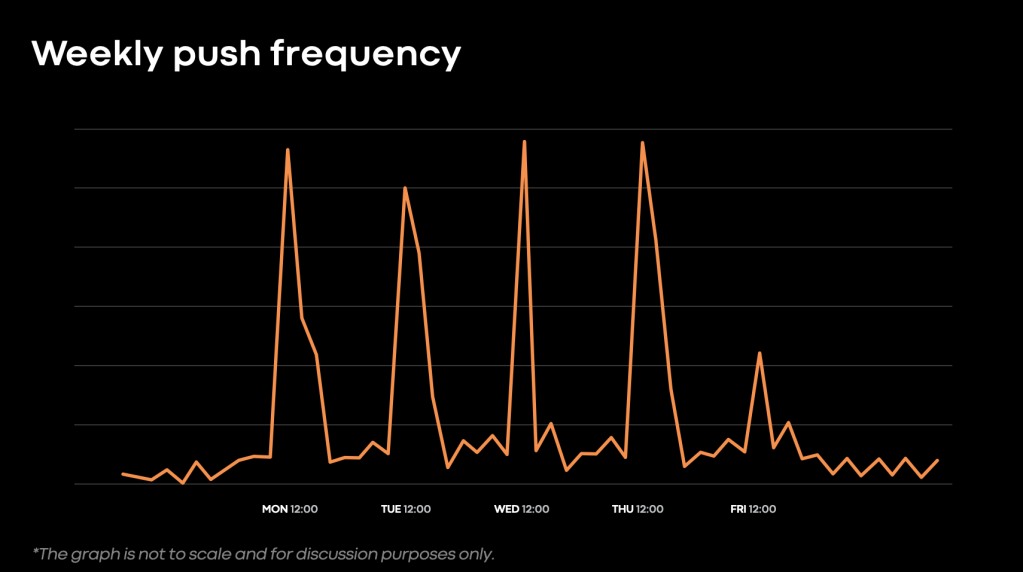
- Push’s Execution Layer is implemented as a CWS workflow. The execution layer consists of an orchestrator, or “decider.” This carries out the decision-making of each push (whether to proceed to the next phase, whether to send updates, when to retry various failures etc.), and workers to carry out the individual steps of the push. Queues “protect” the orchestrator and workers, allowing for graceful degradation of push performance during load spikes. Our system requires this, given frequent load spikes. This spikiness is a product of company work-habits, given that most teams push around Noon Monday-through-Thursday in the Pacific Time Zone
Push Types, microservices which integrate with various hosting solutions, carry out the finer details of the push. Every push at Facebook associates with one push type. Twine Push Type, the most frequently used (covering >95% of pushes), integrates with Facebook’s Container System, Twine.
Pushing Diverse Services
Facebook assumes a highly diverse notion of services. As a result, Push must be generic enough to work with many types of deployments while providing minimal work for the “average” service owner. We strike this balance of flexibility and usability through a few features.
Push Types
In addition to standard containerized Twine services, Facebook has other notions of services. One such class of services includes Widely Deployed Binaries, or WDBs. These applications, running on millions of machines at Facebook outside containers, get configured through Chef. Example WDBs include the Twine Agent, which hosts individual containers, or config caches operating at a machine level. Beyond Twine and WDB services, many other service types exist.
Push is flexible enough to support all of these deployment types through a common Thrift interface called a “Push Type”. Each push type gets implemented as a microservice that extends this common interface. This interface relies on a few abstractions that hold true for most classes of services:
- Configuration. Each type of service has some notion of what settings a user can apply during the deployment process. These configuration files are transparent to the push system. They are arbitrarily serialized in user configs and passed through the system to the Push Types, which interpret them. In Twine’s case, configuration includes which containers should be updated as part of the push as well as other Twine-specific options, like how many containers may be updated at once during a large update.
- Units. Each service consists of logical units, or things that are deployed to. In Twine’s case, units represent “jobs”, or logical groupings of replicated containers. For bare metal deployments, this could be individual hosts or machine tiers consisting of many hosts
- Subunits. For some services, units may get broken down into smaller pieces. In Twine’s case, these subunits amount to individual containers within a job. Not every push type uses the notion of sub-units
- Updates. Each type of service has its own unique way of updating these units. For Twine, this involves sending updates to Twine’s Front-End API.
- Versions. Each unit, and optionally subunit, runs some version of code identified by a string value.
- Healthchecks. Functionality exists to assess each unit as “healthy” or “unhealthy” at any given time.
We tie each deployment at Facebook to exactly one Push Type, of which several dozen exist. As a simple example, consider a service owner that runs binaries on bare metal hosts and updates these machines through SSH. Assume various libraries exist to update and healthcheck machines by hostname.
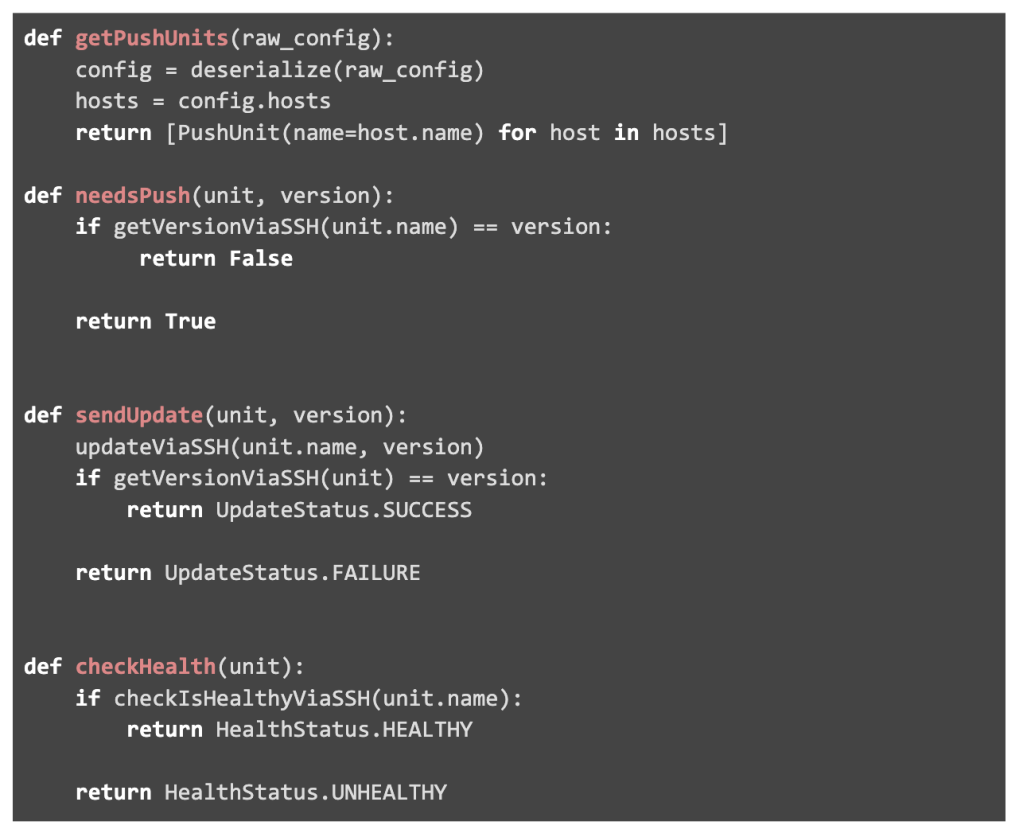
This service would be hosted as a microservice at “my.push_type”. With this custom push type running in production, Conveyors can now get configured to deploy with this Push Type.

Once a bundle containing a new version of code, e.g. “my.fbpkg.foo:12345”, Push will carry out the following steps:
- Invoke the Push Type’s getPushUnits endpoint to determine push units. The Push Type will deserialize the config specified in the conveyor config and return the names of the two hosts.
- Build an execution plan from the available units and Push Plan Config. This execution plan consists of a single phase which updates both units in parallel.
- Execute first phase:
- Use needsPush to check if the hosts are already running the correct version of code. If so, the phase will be skipped
- If phase isn’t skipped, issue updates to each push unit via sendUpdate
- Enter a baking loop, where checkHealth is invoked periodically
- After one hour of baking with successful healthchecks, the push completes
Flexible Push Plans
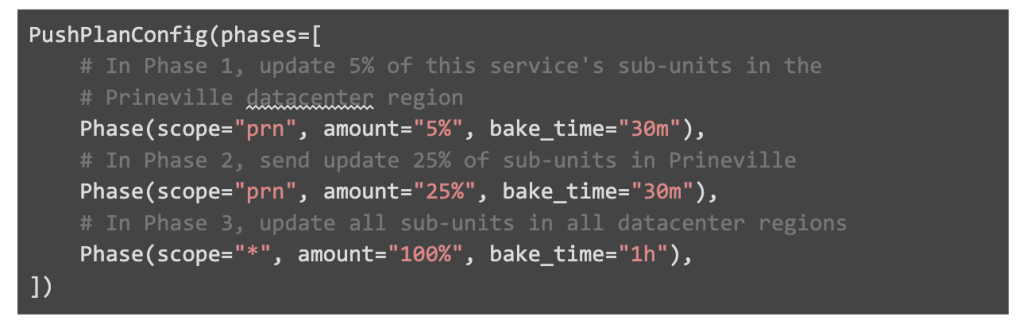
To allow teams to specify how their deployment should be broken down into phases, users may specify a Push Plan Config for their service. Each config exports phases, each containing:
- Scope: a string denoting the units of deployment push-able in this phase. In combination with amount, this identifies which sub-units will be updated in the phase. This can be a datacenter region, machine tier, or wildcard “*” matching all units
- Amount: within the confines of the scope above, for each unit, the number of sub-units to update. For example, a phase could be configured to update 5% of sub-units within each unit in the specified scope
- Bake time: the amount of time to wait to give the system ample time to stabilize and assess health metrics
In addition to the phases provided above, Push always assumes an explicit “completion phase”, akin to target=”*”, amount=”100%” as the last phase of a push. Otherwise, users may misconfigure their Push Plan to only update a fraction of the service. This would leave the service in a partially-pushed state.
Customizable healthchecks
During the deployment process, Push must ensure nothing has been broken by the new version. If production breaks, the service should be reverted to a known “good state,” usually the last successfully-pushed version. But, various teams have different indicators of service health. So, a system must exist to provide a flexible notion of service health.
Facebook solves this with a dedicated Healthcheck Service which integrates with various push types, like Twine. Users write a “Healthcheck Config” specifying conditions under which their service is considered healthy. Multiple push types integrate with this Healthcheck Service, however, we’ll focus our discussion around the Twine integration:
A healthcheck config consists of various checks, each containing various fields:
- Metric: A metric within some datastore which determines the health of containers. This can be exported by the Thrift service framework (e.g. uncaught exceptions, number of client connections), the container agent (crashes, cpu utilization, memory utilization), or the application itself (service-specific metrics)
- Transform / reduce: Various transformations and reduce operations to be applied to the data. This can, for example, reduce noise by averaging data over a certain time window.
- Threshold: An upper or lower bound for the metric once the transformation / reduce operation has been applied.
Two types of checks exist: “simple” and “comparison.” Simple checks compare a metric against an absolute threshold, while comparison checks compare metrics across two parts of the service. We typically do this to A/B test a service during deployment. These comparison checks help isolate issues strictly with the new version of code being deployed.
To illustrate the benefit of comparison checks, consider that a spike in CPU utilization could indicate a bug (such as an infinite loop), but could also indicate a healthy system operating under a load spike. However, if only the new version of code experiences a CPU spike, this strongly correlates the issue with the new version.
When using comparison checks, we compare the threshold against the relative value of the metric, i.e. (new – old) / (old).

When invoking the healthcheck service, Twine Push Type provides a “lookback period.” This, along with the healthcheck config provides a “healthy” or “not healthy” signal for each Twine job.
Users can configure what happens when a healthcheck blocks a push. One team, for example, might want failures to pause the push and alert the oncall. This allows the team to investigate what went wrong and skip any flaky healthchecks without aborting the push. Other teams might configure their push to automatically revert the push upon a healthcheck failure, thereby preventing the regression from damaging prod.
Custom Actions
Many teams want their own customized tooling for their deployment. Custom Push types allow a large degree of flexibility, but this is overkill for deployments. Instead, service owners might want to run custom logic at various points. For example, running complex validations / End-to-End tests post-push, or diverting traffic away from part of the service before updating.
To allow this, Push supports running user-defined Custom Actions during a push. Users may write a binary in any language they choose, package it, and configure it through their conveyor config to run before or after certain push phases.
The Push system executes these binaries in a remote sandbox with various environment variables to convey additional context to the binary. Examples include the names of units being pushed in the phase or the version of code being deployed. The binary’s return code signals Push whether the action was successful or not, so a Custom Action returning non-zero exit code will block a push.
Dynamic Services
Many services are fixed in size, while others are more dynamic. In Twine’s case, jobs can be configured with an autoscaling policy. This allows jobs to add new containers during peak load, and remove containers during off hours. This allows re-use of capacity for elastic compute, e.g. for machine learning purposes.
This resizing presents challenges for push. If a job consisting of several containers should be pushed across multiple phases and the service is upsized midway through the push, Push risks missing updates to the newly-added containers. If the job is downsized mid-push, it risks failing by attempting to update non-existent containers.
To handle upsizes, Twine provides an API to update the binary running on the job as a whole, rather than just the individual containers within it. Issuing a full-job update guarantees that any new containers added to the job will run with the version specified at the job level. By the end of each push, we guarantee that each job receives a full-job update. To handle downsizes, Push continuously checks the size of each job during the deployment process to avoid sending updates to containers that no longer exist.
Furthermore, some services, like Facebook’s CDN, run outside datacenters at various Points of Presence across the world. Hosts are often inaccessible, rendering them not updateable during the push. However, this shouldn’t block the push. So, Push offers a configurable fault tolerance parameter at the phase level. For example, a service can be configured to push as long as 98% of hosts in a given phase are updated.
Reliability
As the primary deployment system at Facebook, the Push system must be highly reliable. Service owners rely on Push to automatically deploy critical security patches and hotfixes in breakage scenarios. Push also deploys the most critical services at Facebook underpinning nearly every aspect of Facebook’s core products. A deployment which unintentionally downsizes a service could disrupt or stop any of these critical services.
We take several measures to protect our system against bugs.
Error reporting and SLOs
We categorize each completed Push into one of three categories: A success means the deployment was carried out to completion. A “good” failure signifies that an expected failure disrupted the deployment, such as a failing healthcheck. Or, a “bad” failure means an unexpected error aborted the deployment, such as a failing dependency or internal bug.
We provide a Service-Level Objective (SLO) that guarantees 99.9% of pushes end in a success or “good” failure and configure team alerts in the event that this SLO is broken.
Isolated Tiers with Synthetic Traffic
The Conveyor Team hosts infrastructure in three isolated environments:
- Release Candidate (RC), which pushes to internal services owned by the Conveyor team. It also hosts ~20 “crash test dummy” services, which constantly update 24-7 to generate additional synthetic traffic on this tier.
- Production 1, which hosts 20% of customer traffic, excluding high criticality services
- Production 2, which hosts 80% of customer traffic, including high criticality services
Each service owned by the Conveyor team deploys first to RC, then Production 1, followed by Production 2. Any environment experiencing an increase in “bad failures” triggers failures on any ongoing deployments on that tier. We maintain isolation at the service and database layer to ensure that a breakage in one environment cannot impede another environment.
Future work
Several high-importance projects exist on the Conveyor horizon.
Latency Tracking
In addition to working correctly, Push should be fast. This means not only tracking Push success, but latency as well. This presents challenges, as Push latency is determined by a few factors:
- Number of phases in the push
- Baking duration of each phase
- Latency of dependencies, like Twine
- Latency contributed by the Push system
Latency metrics should only assess #3 and #4, since #1-2 are a function of the user’s configuration and vary highly from service to service.
Disaster Readiness
Facebook needs to function correctly during disasters that take datacenters offline. In the event of a datacenter becoming unavailable, Push should still work intuitively for users. This could mean skipping over parts of a service in a downed region. Additionally, it could provide a way to automatically update the skipped parts once the region returns online. Without this feature, disasters or mock-disaster events risk leaving Facebook unable to push code.

