









We’ve all experienced it. You tap to start a voice conversation with an AI assistant, and you’re met with silence. It’s the “awkward pause,” that brief but noticeable delay while the connection is established. This fraction of a second is more than just a minor annoyance; it’s a fundamental barrier to natural, human-like conversation. When we talk to another person, the interaction is immediate. For AI interactions to feel truly seamless, that same immediacy is desired. Latency is a primary obstacle.
At Meta, we recognized that this initial connection latency was a friction point. To make AI voice interactions feel instantaneous, we set an ambitious goal: reduce initial connection latency to less than one second for the vast majority of use cases. This meant we couldn’t just optimize the existing process; we had to re-architect how a real-time media connection is established.
This article breaks down the engineering innovations that allowed us to reduce the awkward pause. We’ll explore how we moved from a standard, sequential setup to a parallel one and the educated bet we made on routing that helped make it all possible.
Why standard call setup for AI is too slow
To describe our solution, we first have to diagnose the problem. The traditional method for establishing a real-time media connection is inherently sequential and requires at least two round trips between the client and the server. This design is robust, but it’s also the primary source of the initial delay.
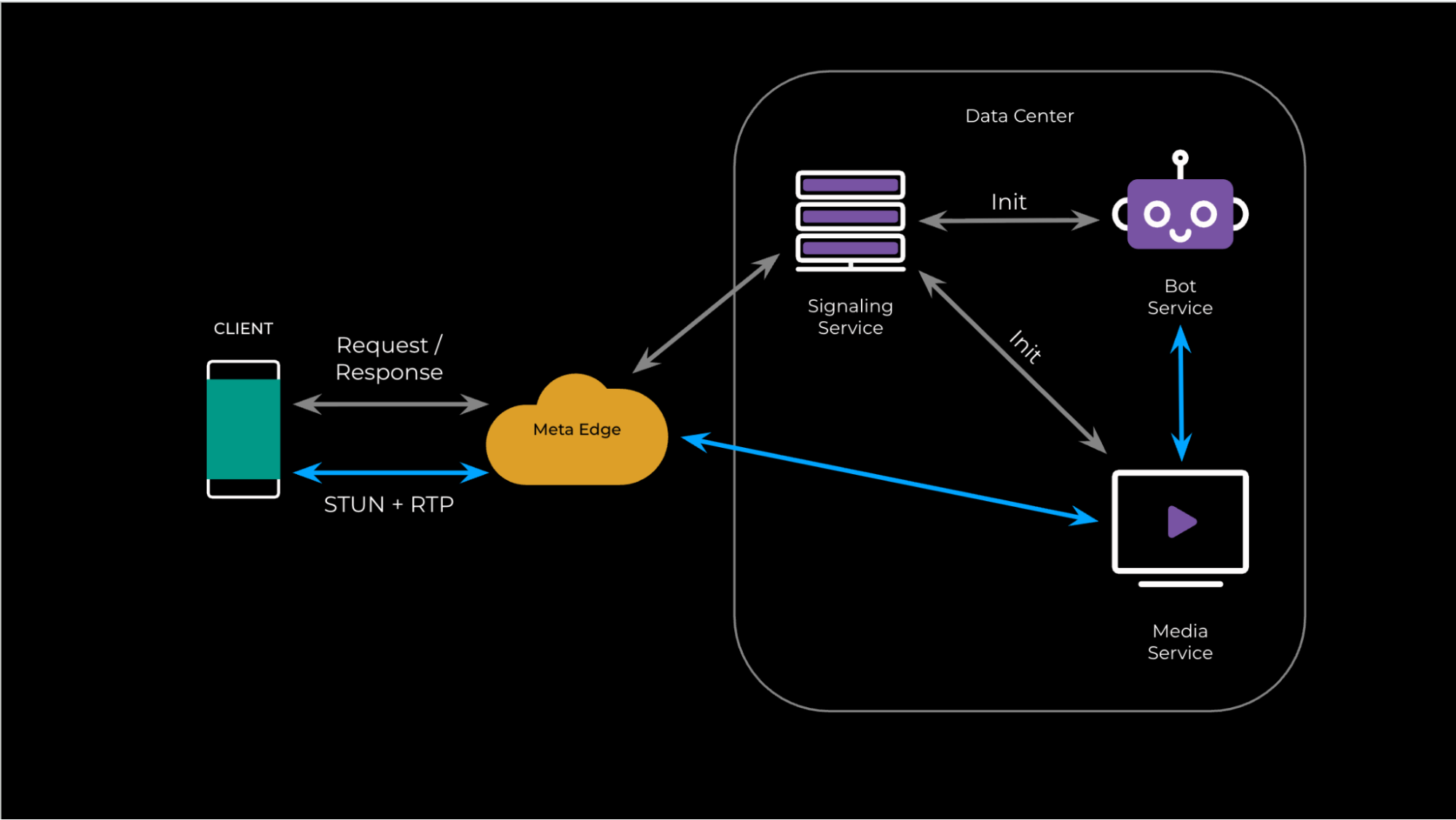
In the standard flow (as shown in Fig. 1), here’s how things work:
- Signaling round-trip: To initiate a call, the client sends a request to a central signaling service. This service then has to coordinate and initialize two separate backend components: a bot service for the AI logic and a dedicated media service to handle the audio stream. Only after these resources are allocated does the signaling service send connection details (i.e., the media service’s IP address, ports, security credentials, etc.) back to the client.
- Media connection round-trip: The client can’t do anything until it receives that signaling response. Only then can it begin sending media packets (such as STUN for connectivity checks) to the specified Media Service IP. This second exchange finally establishes the actual voice connection.
The entire time the client is waiting for that first signaling round-trip to complete is dead time. The user has initiated an action, but the media channel can’t even begin to form. This built-in delay is the connection bottleneck we were determined to eliminate.
Running signaling and media in parallel
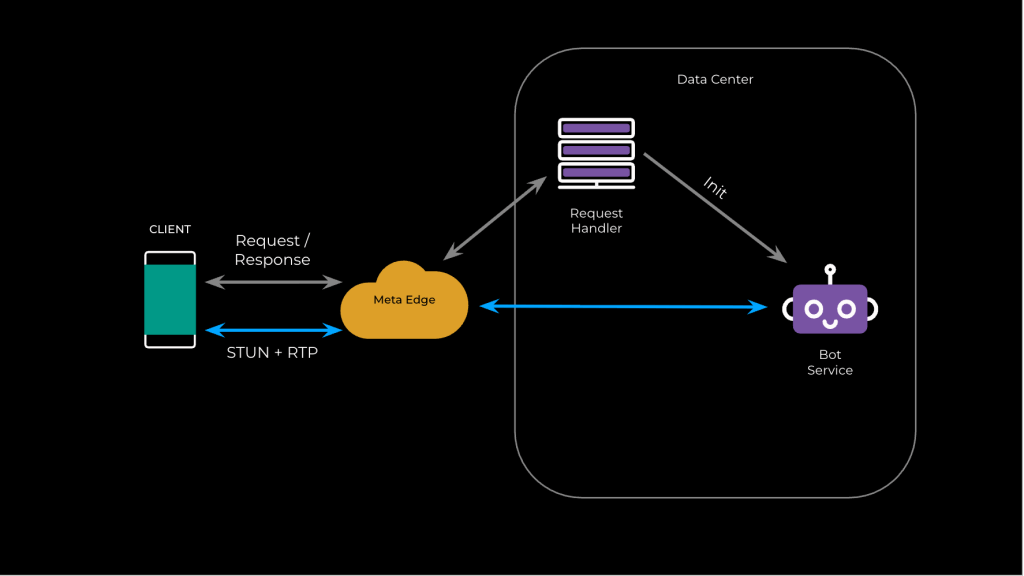
Our core breakthrough was a simple but powerful idea: What if we didn’t wait? Instead of a sequential process, our “ultra-low latency connect” (ULLC) system initiates the signaling request and the media connection simultaneously. By running these tasks in parallel, we effectively eliminate the first round-trip time (RTT) from the critical path, saving hundreds of milliseconds.
This approach also allowed us to simplify our backend. The new Bot Service now handles the media connection directly, removing the need to coordinate with a separate media service.
Here is the unified “happy path” flow, showing how signaling and media work together in one fluid motion (as shown in Fig. 2):
- Client initiates in parallel: The moment the user starts the call, the client kicks off two actions at once.
- Media path: The client performs a DNS lookup for a new global endpoint to get the IP of the nearest edge cluster—our first entry point for media traffic at Meta’s edge network. The client then uses pre-generated local and remote SDPs to immediately start sending STUN pings to this IP.
- Signaling path: Simultaneously, the client sends a Session Creation Request through a highly efficient, persistent API gateway our client is already connected to. This request contains pregenerated local SDP, along with the security credentials needed for the call and, critically, the edge IP the client is currently pinging.
- Server processes in parallel: Both requests travel from our edge network into a data center, where they are processed concurrently.
- (Media path): The STUN pings arrive at the edge, which forwards them to the nearest data center based on a routing algorithm.
- (Signaling path): The Session Creation Request arrives at a request handler, which calls the GenAI Bot Service to create a new session instance. The service stores the session’s connection details in a high-speed, in-memory, key-value store.
- Connection established in milliseconds:
- After arriving at the data center, the incoming STUN packets use the same cache to look up the session.
- Finding a match, they’re immediately forwarded to the correct Bot Service instance.
- The Bot Service service validates the packet and sends a response, establishing the media connection. The user can now speak to the AI without ever perceiving a delay.
Unifying routing with latency maps
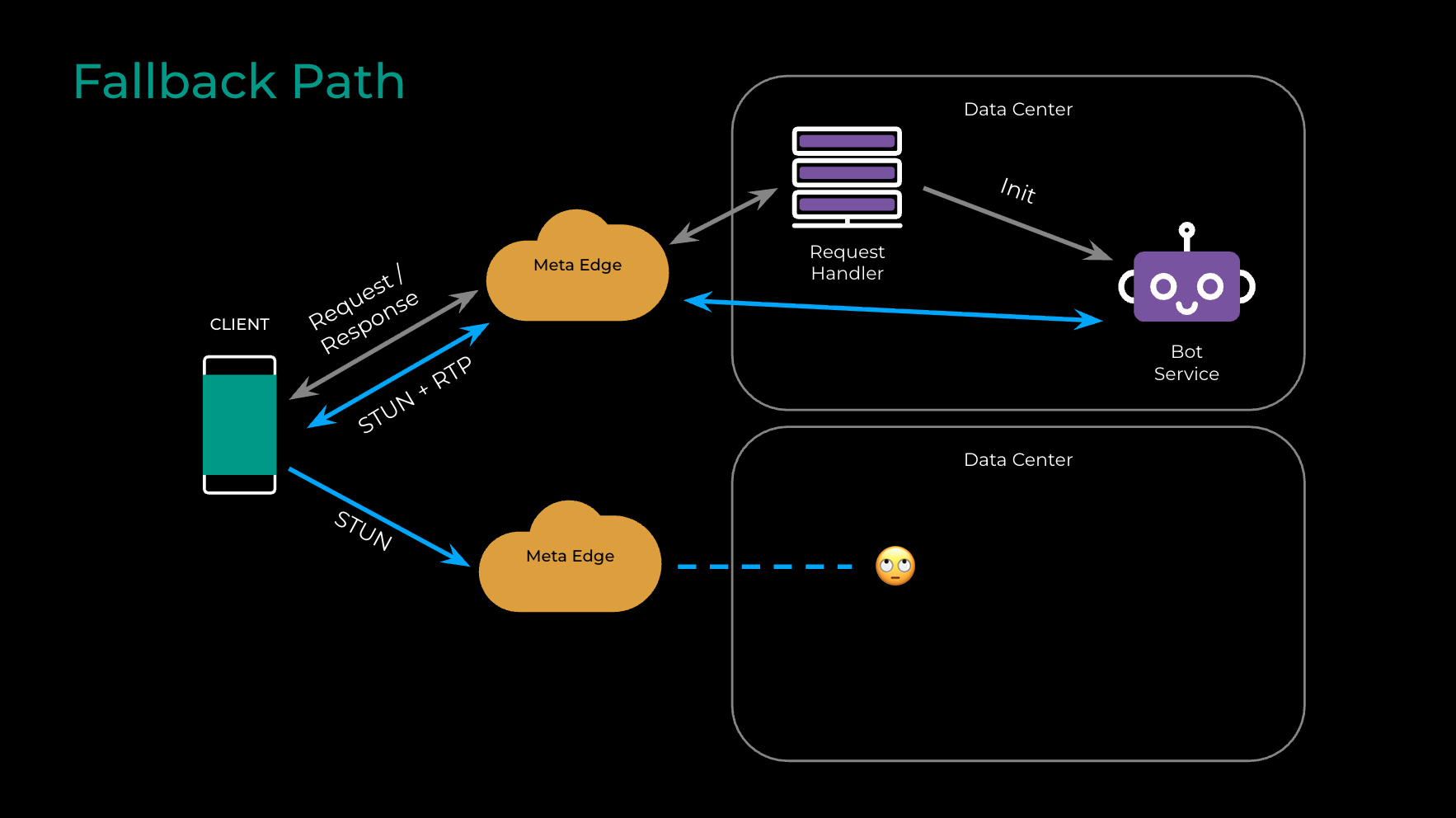
The parallel approach introduces a significant challenge: The signaling request (via the messaging gateway) and the STUN pings (to edge) are two completely separate streams. For the connection to work instantly, they must be routed to the same data center (DC) where the Bot Service session is being created. If the media packets arrive at a DC where no session exists for them, the connection will fail (as shown in Fig. 3).
Our solution is an “educated bet”—an optimistic approach that works in the vast majority of cases by ensuring both paths independently choose the same destination.
- The idea is a single piece of shared information. As mentioned, the client includes the resolved edge IP in the signaling request.
- Both our messaging gateway and edge components use the exact same latency maps to determine the optimal data center for the user. By feeding the same input into the same routing logic, both systems independently and consistently calculate the same destination DC.
Of course, no bet is a sure thing. In the rare case that the two streams are routed to different DCs, a robust fallback path ensures the call still connects reliably. The initial STUN pings to the wrong DC will simply fail. However, the client soon receives the signaling response from the correct DC. This response contains the location of the Bot Service session—a small piece of data that explicitly tells the client which data center to target, eliminating any ambiguity. The client updates its configuration and successfully connects, making the system both incredibly fast on the happy path and resilient on the worst-case path.
How milliseconds translate to meaningful engagement
Our primary engineering goal for this project was to achieve < 1sec connection-establishment latency for the vast majority of use cases. By implementing the parallel architecture and unified routing, we successfully met this goal. But the true measure of success is in the impact on the user experience and product metrics. Our experiments also validated this hypothesis and we observed that reducing connection-establishment latency leads to users being more likely to initiate AI conversations and more likely to be successful in those interactions.
These improvements confirm a simple truth: In human-computer interactions, speed feels like quality. By removing the awkward pause, we made the AI assistant feel more responsive, reliable, and natural. This encouraged users to engage more often and more successfully, demonstrating that even small latency improvements can be significant.
Beyond just AI
The ULLC project taught us that challenging a fundamental, industry-standard RTC assumption—that connection setup must be sequential—can help make meaningful improvements. We shifted to a parallel paradigm, enabled by clever routing synchronization. We didn’t just optimize the old way; we created a new one.
While this project was focused on AI voice, the principles could be broadly applicable to any real-time communication scenario where initial latency is a factor. It proves that our most ingrained “standard procedures” are often the biggest opportunities for innovation. As we build for future platforms such as MetaAI Glasses, where interactions need to be truly instantaneous to feel natural, we’re left with a guiding question: What other foundational assumptions are ready to be challenged in the pursuit of perfectly seamless interaction?

