EVENT AGENDA
Event times below are displayed in PT.







AI @Scale is a technical conference for engineers that are interested in solving scalability problems in machine learning. This is an exciting area that brings many challenges in the nexus of distributed system, hardware design and machine learning technique innovations. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
AI @Scale will be hosted virtually. Joining us are speakers from AWS, Microsoft, Salesforce, Fiddler, Outerbounds, Unity, Union.ai, Cruise and Meta. The event will be hosted on September 28, 2022 with talks themed around AI systems implementation at scale.
Event times below are displayed in PT.
In this talk, we delve into how we have designed Meta’s data centers, network, hardware, storage and software systems to support the needs of existing and emerging AI workloads.

Scaling Machine Learning Models from the laptop to production is non-linear. Different rules and laws apply at scale. Ketan Umare (CEO Union.ai, TSC Flyte.org), will cover the three laws for ML at scale. These laws will be grounded using anecdotes that the team encountered while working with some of the top companies utilizing ML in production. The talk will cover the following topics,
– Machine Learning products are resource intensive. Oftentimes the cost of ML projects balloon and access to infrastructure is scarce without predefined ROI.
– ML at scale is a team sport. Production teams need a common platform to collaborate efficiently. Small in-efficiencies in collaboration can slow down an entire organization.
If things can go wrong, at scale they will go wrong. We need a safety net - versioning, reproducibility are important in delivering robust ML products at Scale. To deliver these robust products, just code and data is not enough, it is essential to capture the infrastructure & configuration.

There is a pressing need for tools and workflows that meet data scientists where they are. This is also a serious business need: How to enable an organization of data scientists, who are not software engineers by training, to build and deploy end-to-end machine learning workflows and applications independently? In this talk, we discuss the problem space and the approach we took to solving it at Netflix. We wanted to provide the best possible user experience for data scientists, allowing them to focus on parts they like (modeling using their favorite off-the-shelf libraries) while providing robust built-in solutions for the foundational infrastructure: data, compute, orchestration, and versioning.

In this talk I will present the machine learning infrastructure that supports the large scale data preparation and training at Cruise. And how it enables the model improvements in an effective, reliable, continuous and automatic fashion.

This talk will be walking through the development life-cycle of OPT-175B, the first 175B-parameter language model that has been made publicly available for research-use in May 2022. Topics covered will include limitations of transferring results from small-scale experiments, working around hardware failures compounded at scale, numerical instabilities that may occur mid-way through training, amongst others.

Computer vision has made huge strides recently, helped by large-scale labeled datasets. However, these datasets had no guarantees or analysis diversity. Additionally, privacy concerns may limit the ability to collect more data. These problems are particularly acute in human-centric computer vision for AR/VR applications. An emerging alternative to real-world data that alleviates some of these issues is synthetic data. However, creating synthetic data generators is incredibly challenging and prevents researchers from exploring their usefulness. To promote research into the use of synthetic data, we release a set of data generators for computer vision. We found that pre-training a network using synthetic data and fine-tuning on real-world target data results in models that outperform models trained with the real data alone. Furthermore, we find remarkable gains when limited real-world data is available. These freely available data generators should enable a wide range of research into the emerging field of simulation to real transfer learning for computer vision.

Microsoft’s AI @Scale encompasses multiple dimensions. It gives customers access to state-of-the-art large-scale AI models, training and inferencing optimization tools, and supercomputing resources; It provides cross-platform AI runtime that enables customers to infuse AI into every aspect of their platforms and products, across cloud and edge. In this talk, I will give an overview of Microsoft AI @Scale. I will focus on the roles that AI software plays, and discuss the challenges we are facing and the areas for potential collaborations between AI software and hardware.

This talk will explore how AWS customers use a combination of pyTorch and the managed SageMaker platform to perform efficient and easy-to-use training of large models – and how we built a SageMaker-specific distribution backend.

Inference of single-model applications has, in recent years, become a multi-stage process, combining online Feature Stores with specialized model-hosting runtimes like ONNX and Triton. Less simplistic AI applications such as those in chatbots, mixed-mode recommenders, and search engines fold "candidate retrieval" steps into the mix. As these applications get more sophisticated, they typically now require all of feature-hydration, semantic encoding/embedding, candidate selection, and candidate re-ranking (not to mention any pre/post-processing or "format massaging" in between any of these steps). While for batch and streaming applications, composable DAG engines and DSLs have been developed to allow these applications to become arbitrarily deep, in the on-demand/realtime world, DAG engines which are open source / open-specification are few and far between, even though they are sorely needed.

What makes PyTorch beloved makes it hard to compile. This is a unique challenge faced by an eager-first ML framework like ours. In this talk, we will demonstrate the feasibility of funneling any PyTorch models through the compilers with minimal user intervention and the exciting possibility of a compiler-accelerated PyTorch. And we will share promising early results on our new solution, TorchDynamo.

Artificial Intelligence is increasingly playing an integral role in determining our day-to-day experiences. Moreover, with the proliferation of AI-based solutions in areas such as hiring, lending, criminal justice, healthcare, and education, the resulting personal and professional implications of AI are far-reaching. The dominant role played by AI models in these domains has led to a growing concern regarding potential performance drift and bias in these models, and demand for model transparency and interpretability. Model Monitoring has become a prerequisite for building trust and adoption of AI systems in high-stakes domains requiring reliability and safety such as healthcare and automated transportation, and critical industrial applications with significant economic implications such as predictive maintenance, exploration of natural resources, and climate change modeling. In this talk, we will be talking about how Fiddler.AI is building Model Performance Management that solves this problem by continuously monitoring AI algorithms for performance and bias issues and reports actionable insights with explanations to the entire organization. For more information, you can visit www.fiddler.ai or follow us on Twitter @fiddlerlabs.

Presented by: Yann LeCun & Ludovic Hauduc (Meta)


I work on AI. My focus is on ensuring that our data center, network,... read more

Ketan Umare is the TSC Chair for Flyte (incubating under LF AI & Data).... read more

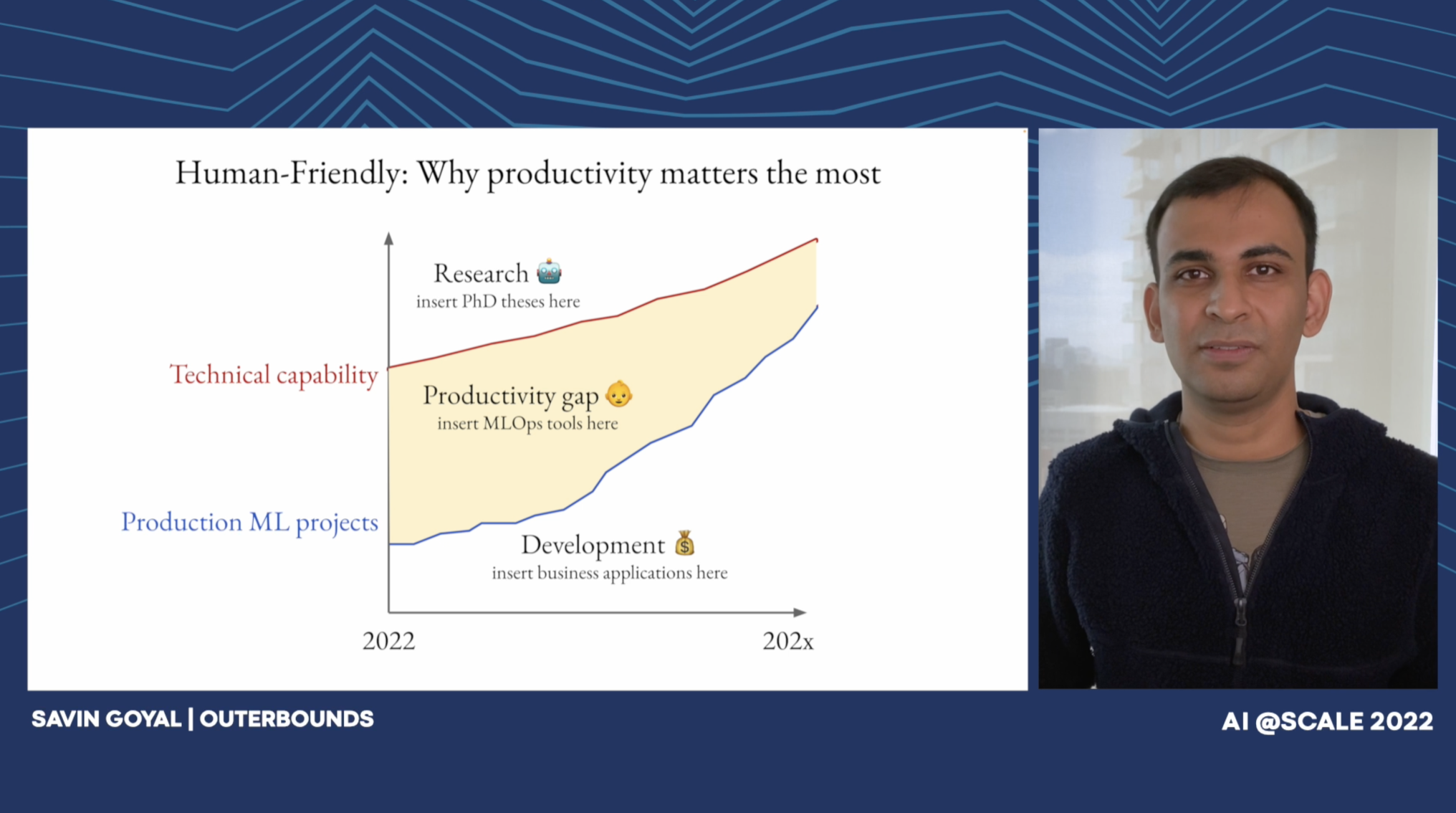
Savin is the co-founder and CTO of Outerbounds - where his team is building... read more


Alexander Sidorov is Sr. Staff Software Engineer @ Cruise with over a decade of... read more

Susan Zhang is a Research Engineer at Meta read more

Sujoy Ganguly is the Head of Applied Machine Learning Research and Computer Vision at... read more

Yuan Yu is a Technical Fellow at Microsoft. He leads Microsoft’s AI Frameworks team,... read more

Andrea is a Senior Principal Engineer at Amazon Web Services. He is the Chief... read more

ML Engineer and system architect who's spent the past couple decades working on scalable... read more

Dr. Peng Wu is the engineering manager of the PyTorch Compiler team at Meta.... read more

Krishna Gade is the Founder/CEO of Fiddler.AI, a Model Performance Monitoring startup. Prior to... read more

Yann LeCun is VP & Chief AI Scientist at Meta and Silver Professor at... read more

Ludo Hauduc supports the AI Infrastructure team at Meta, with the mission to design,... read more