EVENT AGENDA
Event times below are displayed in PT.
Systems @Scale is a technical conference for engineers that manage large-scale information systems serving millions of people. The operation of large-scale systems often introduces complex, unprecedented engineering challenges. The @Scale community focuses on bringing people together to discuss these challenges and collaborate on the development of new solutions.
The 2021 summer series will be hosted virtually. Joining us are speakers from AWS, Alibaba, Google, Microsoft, Netflix, Uber, and Facebook. The event spans four weeks, with talks themed around Reliability, Cluster Management, Capacity and Provisioning @Scale, Scalability and Performance in the context of large-scale distributed systems.
Starting June 9th, for four weeks, we will livestream a recorded session followed by live panel discussion on Wednesdays.
Event times below are displayed in PT.
At AWS, we build systems using a variety of complementary strategies for maintaining predictable, consistent performance in the face of overload. In this talk, we describe techniques such as implementing layers of protection, preventing retry storms, prioritization, and fairness in multi-tenant systems. We also cover architectural approaches that isolate uncorrelated workloads, such as shuffle-sharding, and the per-request isolation model in AWS Lambda.

As companies grow and the number of services and the traffic to those services increases we often rely on hand tuning and developer experience to increase reliability and resilience. It feels at times like an endless amount of adding functionality, noticing new system behavior, tuning services, and closely monitoring impact. Even still, there’s always a new way our systems can fail leading to the need to revisit our carefully tuned system parameters. This constant battle slows progress, but at Netflix we rely on a low barrier to entry “paved road” which allows developers to build new services in minutes which adapt to runtime behaviors. These services leverage a suite of dynamic algorithms which automatically learn system behavior, reacting to outages, slow responses, and sudden changes to upstream and downstream traffic patterns. In this talk, we’ll dive into some of those dynamic approaches and show the result of various common failure scenarios which Netflix engineers no longer need to think about. These approaches are so good we’ll even see how in some situations they make calling remote services more reliable than in process code.

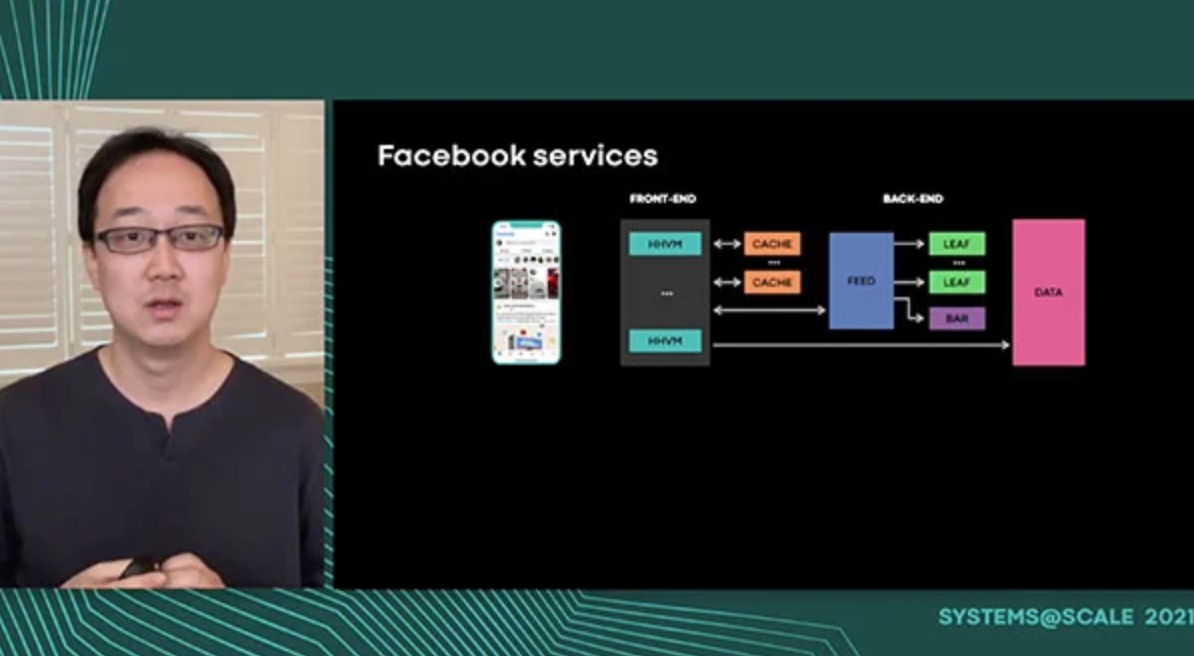
Facebook is made up of hundreds of heterogeneous services in geographically distributed data center regions. To reliably run, providing a sufficient amount of capacity for all sub-systems and services is crucial. However, understanding and measuring service’s maximum servable load presents challenges. We further need to validate the entire ecosystem across multiple services to ensure sufficient capacity for Facebook product. However, measuring max load and verifying capacity at Facebook-scale involves a few challenges: 1) The workloads are constantly evolving and changing as the user base grows and new products are launched. 2) Software constantly changes as each service deploys new versions. 3) The interdependencies across services contain inherent complexity. To address these challenges, we developed a load testing framework leveraging live traffic in production systems: 1) service-level load testing to measure the maximum servable load of individual service; 2) region-level load testing to verify the capacity of a product. We’ll share how we scaled service-level load testing to a large number of services, overcoming service diversity and how we improved data quality despite noisiness of a live traffic. For regional-level load testing, we will focus on how we safely conduct such large-scale load testing. We will also share findings and learnings from the regional-load testing such as load balancing issues and the scalability of individual services. We have been leveraging both types of load testing in Facebook for over five years. For service-level load testing, 80,000 tests are running across hundreds of services every day. The number of machines allocated for those services is more than one-third of the entire capacity. To maximize the value of load testing, we are actively working on increasing load testing coverage. For service-level load testing, we work with stateful and storage services to explore the best options for applying & leveraging load testing. For region-level load testing, we work with a broader set of products to generalize the idea of region-level load testing across all products. With the increased load testing coverage, we expect to serve our Facebook users with even greater reliability.


This session will share the real-world lessons from reliability engineering work on the Exposure Notifications Server - A project from Google and Apple in an effort to slow the spread of COVID-19. The work from Google SRE includes using Service Level Objectives, alerting configurations, and alert delivery.

Azure Kubernetes Service (AKS) manages Kubernetes clusters on behalf of customers. AKS stays agnostic to the customer workload and manages the accessibility, performance, and reliability of these clusters without requiring full knowledge of the infrastructure configurations and policies put by the customers. In this talk, I will share various challenges the service faces and our auto detection and auto remediation approaches to tackle them at scale.

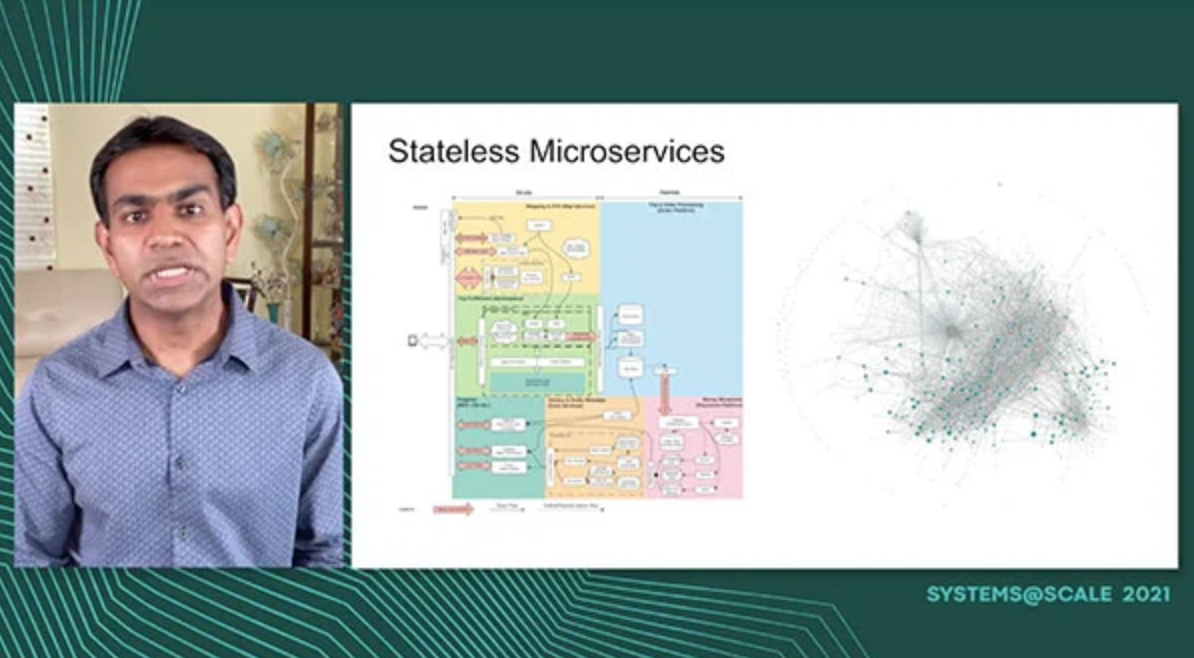
Uber infrastructure broadly supports 3 kinds of workloads: stateless microservices, big data (batch) and stateful, each running on its own hardware silo. Morcor aims to reduce the cost of infrastructure through co-location of stateless and non-guaranteed batch jobs. Morcor is deployed successfully at Uber allowing us to free up hundreds of thousands of cores from stateless services and use those for running tens of thousands of batch jobs daily. In this talk, we will describe our approach to co-location, the problems we solved and what lies ahead for us.

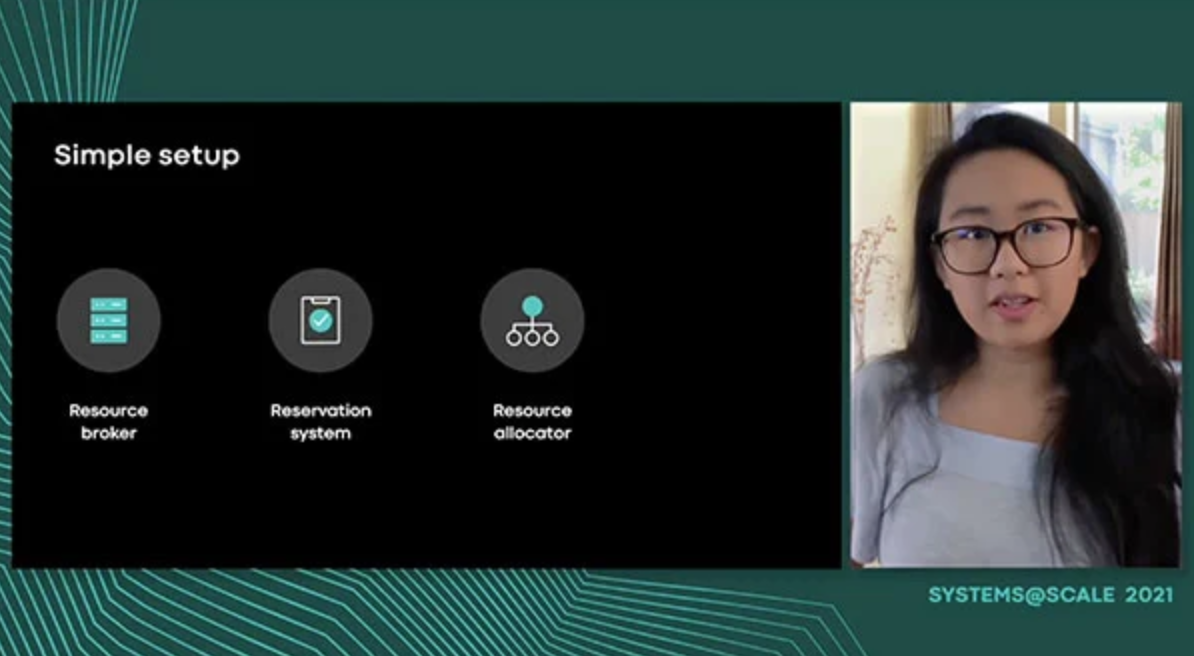
Optimus, our spare capacity leasing system, coordinates capacity allocations on millions of machines to improve global capacity utilization and meet fast growing business needs. Within Facebook's infrastructure, spares are maintained to ensure capacity sufficiency and resiliency for daily peak traffic -- spares remain idle for hours or days until mobilized. We will discuss the characteristics of spare capacity and the opportunities for dynamically leasing them to flexible workloads. We will share how elasticity manifests in our policies for capacity leases, how our models of fleet-wide capacity usage allow Optimus to make probabilistic guarantees on capacity availability, and showcase three workloads that effectively use leased capacity. We will also share some of the lessons we have learned in growing Optimus to its current state.
Alibaba Cloud offers a comprehensive set of storage services, including Object Storage Service (OSS), File Storage Service (NAS) and NoSQL Tablestore with high durability, high availability, high scalability and strong consistency. All these services are built with a layered architecture, including a scalable index layer built with ArkDB key-value engine, and a persistent storage layer provided by Pangu distributed storage system. In this talk, we present the detailed design and implementation of ArkDB, addressing challenges in storage disaggregation, supporting write and range query-heavy workloads, and balancing of scalability, availability and resource usage. ArkDB combines some of key advantages from both LSM tree and recently proposed B-tree variants e.g., Bw-tree and Bε -tree. Its main contributions include shrinkable page mapping table, separation of system and user states for fast recovery, write amplification reduction, efficient garbage collection and lightweight partition split and merge. We share some of our lessons and experiences in building ArkDB key-value engine and demonstrate its performance improvements with experimental results.

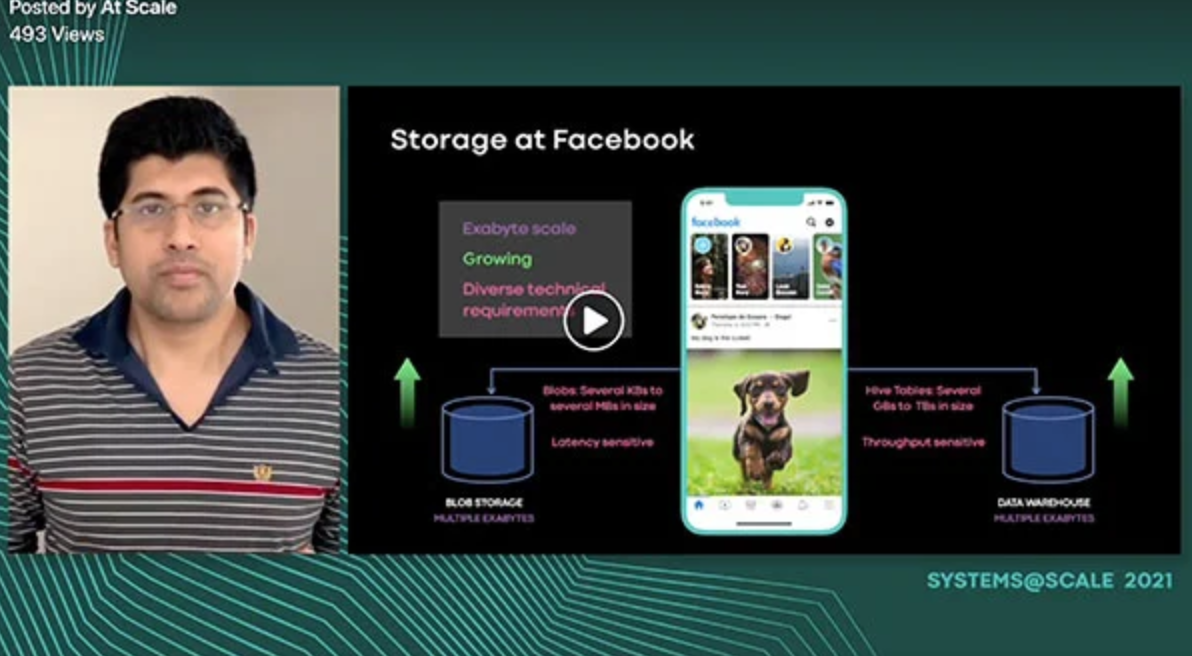
Tectonic is Facebook’s exabyte-scale, datacenter-wide distributed filesystem. Prior to Tectonic, Facebook’s storage infrastructure consisted of a constellation of smaller, specialized storage systems. Blob storage was spread across Haystack and f4. Data warehouse was spread across many HDFS instances. Tectonic consolidates the service-specific systems into general multitenant filesystem instances that achieve performance comparable to the specialized systems. This talk presents motivations behind building Tectonic, high-level architecture of Tectonic, and lessons from rolling out Tectonic into production.

In this talk, we share some of the most exciting achievements of Flink at Alibaba in recent years, including two main topics: one is the architecture evolution of stream-batch unification; the other is the recent efforts to improve high availability for streaming processing. Flink has been greatly improved since its first appearance at Alibaba in 2016 and has become the de facto real-time computing standard. Last year for the first time, Flink’s unified stream-batch processing was officially used in Tmall's big-screen marketing analysis during Double 11 -- one of the Double 11’s core scenarios. We will share the architecture evolution beneath to help us achieve this. In addition, Flink never stops expanding its application spectrum to extreme real-time processing. We will discuss some of the efforts in this area as well.

BPF (eBPF) tracing is the superpower that can analyze everything, helping you find performance wins, troubleshoot software, and more. But with many different front-ends and languages, and years of evolution, finding the right starting point can be hard. This talk will make it easy, showing how to install and run selected BPF tools in the bcc and bpftrace open source projects for some quick wins. Think like a sysadmin, not like a programmer

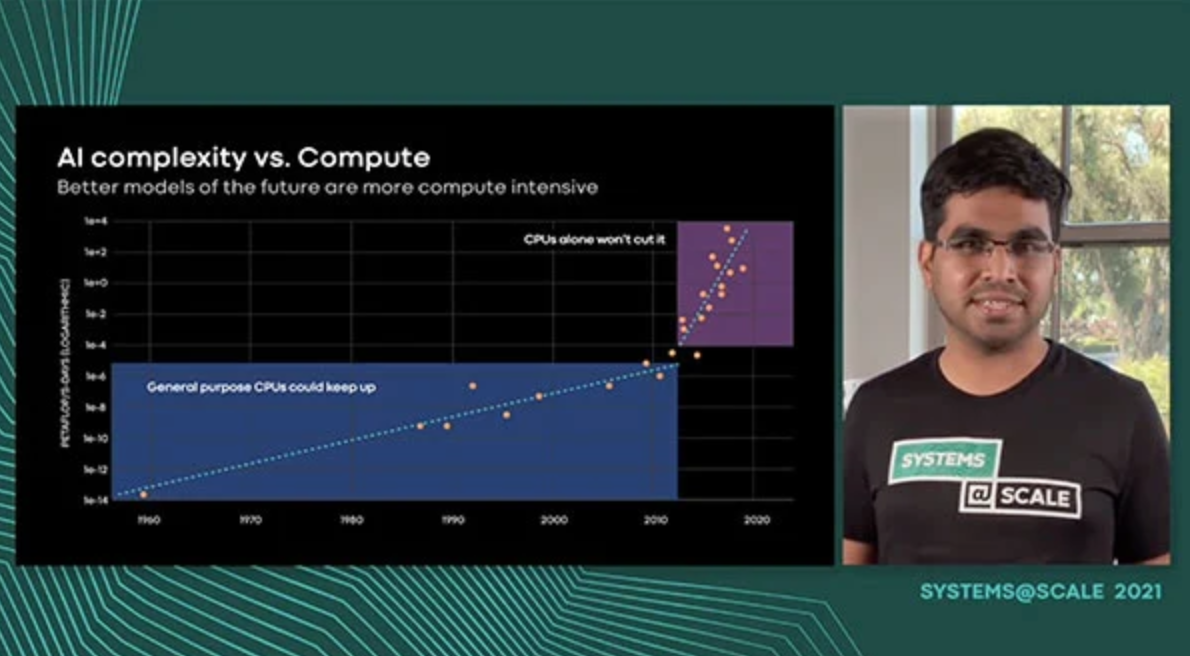
Application specific hardware platforms play a crucial role in meeting the growing latency and compute demands of workloads like deep learning, content understanding and video encoding. However, it is challenging to operate these heterogeneous platforms efficiently at scale. In this talk we introduce asicmon - an observability framework for accelerators. Asicmon offers a simple abstraction for the accelerator to upstream monitoring software. Further, it facilitates ease of development by leveraging a custom built specification language - Asimov. With Asimov we could prototype and onboard new accelerators quickly, reducing the onboarding time from months to weeks. Beyond monitoring, tracing also plays a key part in understanding the performance and interaction between the CPU and accelerator. We developed a tracing framework - atrace to collect and process traces at scale. Atrace provides key insights such as operator profiles and critical path analysis. We also extended the native tracing capabilities by correlating events to the CPU in the open-source Glow and PyTorch software stack. Doing so enabled engineers to close up to a 10% performance gap on pytorch vs caffe2 AI model implementations.

The Facebook cloud supports a variety of workloads including those which are CPU intensive, memory bound, I/O bound, latency sensitive, or a combination of these, on hardware that ranges from smaller single socket servers to load balancers and switches to multi socket hosts with accelerators. This talk is about how we control for resource usage and contention of infrastructure software that runs across this cloud environment, including OS services and proprietary services required for successful operation of primary applications. Such software has significant resource constraints to support our wide variety of collocated workloads, and we frequently encounter trade-offs on the axes of new functionality, efficiency, and reliability. Predictable resource usage for host infrastructure software at scale is one of the core abstractions in the Facebook cloud infrastructure which gives our services the ability to run at high utilization. We will go into details of our resource accounting and measurement infrastructure, processes established to keep levels of resource consumption consistent and predictable, and the technologies that allow core Facebook services to utilize the remaining capacity with minimal contention and high reliability. We will also highlight how our learnings and best practices could be used in similar private cloud environments.