EVENT AGENDA
Event times below are displayed in PT.







This year’s event features technical deep dives from engineers at a multitude of scale companies. Adobe, Amazon, Cloudera, Cockroach Labs, Facebook, Google, Microsoft, NASA, NVIDIA, Pinterest, and Uber are scheduled to appear. The day has three tracks: Data, Dev Tools & Ops, and Machine Learning. We also have our scale system demonstration area back for a third year so engineers can interact with the latest tech. Keep an eye on this page – we’ll add videos of the presentations soon.
Event times below are displayed in PT.
The end of Dennard scaling and Moore’s law are not problems that must be solved but facts that, if accepted, offer breathtaking opportunities. High-level, domain-specific languages and architectures aided by open source ecosystems and agilely developed chips will accelerate progress in machine learning. We envision a new golden age for computer architecture in the next decade, with dramatic gains in cost and energy security as well as in performance.


In this talk, we’ll discuss our production-level, end-to-end infrastructure and workflows to develop AI for self-driving cars. We’ll explore the platform that supports continuous data ingest from multiple cars (each producing TBs of data per hour) and enables autonomous AI designers to iterate training new neural network designs across thousands of GPU systems and validate their behavior over multi PB-scale data sets. The obstacles faced by self-driving cars aren’t limited to the world of autonomous driving. We will share how the problems we’ve solved in building this infrastructure for training and inference at scale are applicable to others deploying AI-based services.

Amazon Aurora is a relational database service for OLTP workloads offered as part of Amazon Web Services (AWS). In this talk, we describe the architecture of Aurora and the design considerations leading to that architecture. We believe the central constraint in high throughput data processing has moved from compute and storage to the network. Aurora brings a novel architecture to the relational database to address this constraint, most notably by pushing redo processing to a multitenant scale-out storage service, purpose-built for Aurora. We describe how doing so not only reduces network traffic but also allows for fast crash recovery, failovers to replicas without loss of data, and fault-tolerant, self-healing storage. Traditional implementations that leverage distributed storage would use distributed consensus algorithms for commits, reads, replication, and membership changes, and amplify the cost of underlying storage. We will describe how Aurora avoids distributed consensus under most circumstances by establishing invariants and leveraging local transient state. These techniques improve performance, reduce variability, and lower costs.

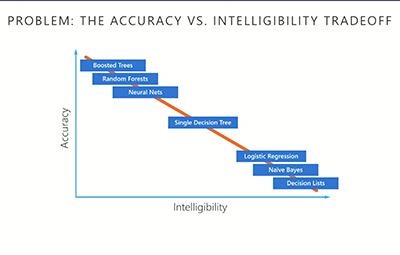
In machine learning, often a trade-off must be made between accuracy and intelligibility: The most accurate models usually are not very intelligible (e.g., deep nets), and the most intelligible models usually are less accurate (e.g., linear regression). This trade-off often limits the accuracy of models that can safely be deployed in mission-critical applications such as health care where being able to understand, validate, edit, and ultimately trust a learned model is important. I have been developing a learning method based on generalized additive models (GAMs) that is often as accurate as full complexity models but even more intelligible than linear models. This makes it easy to understand what a model has learned, and also makes it easier to edit the model when it learns inappropriate things because of unanticipated problems with the data. Making it possible for experts to understand a model and repair it is critical because most data has unanticipated landmines. In the talk I present a case study where these high-accuracy GAMs discover surprising patterns in data that would have made deploying a black-box model risky. I also briefly show how we are using these models to detect bias in domains where fairness and transparency are paramount.

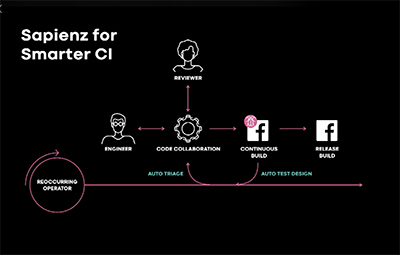
Sapienz designs system tests that simulate user interactions with mobile apps. It automatically finds apps' crashes, then localizes, tracks, and triages them to developers. This talk will cover how Sapienz is deployed at a large scale at Facebook, including its continuous integration with Facebook's development process, fault signals boosted by Infer's static analysis, and cross-platform testing on both Android and iOS.

Presto is an open source, high-performing, distributed relational database system targeted at making SQL analytics over big data fast and easy at Facebook. It provides rich SQL language capabilities for data engineers, data scientists, and business analysts to quickly and interactively process terabytes to petabytes of data. Presto is widely used within at Facebook for interactive analytics with over thousands of active users. We're using Presto to accelerate a massive batch pipeline workload in our Hive Warehouse. Presto is also used to support custom analytics workloads with low-latency and high throughput requirements. As an open source project, Presto has been adopted externally by many companies, including Comcast, LinkedIn, Netflix, and Walmart. In addition, Presto is being offered as a managed service by vendors such as Amazon, Qubole, and Starburst Data. In this talk, we’ll outline a selection of use cases that Presto supports at Facebook, describe its architecture, and discuss several features that enable it to support these use cases.

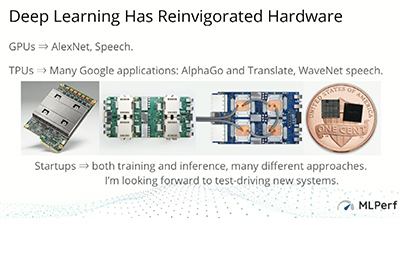
The MLPerf effort aims to build a common set of benchmarks that enables the machine learning field to measure system performance for both training and inference from mobile devices to cloud services. We believe that a widely accepted benchmark suite will benefit the entire community, including researchers, developers, builders of machine learning frameworks, cloud service providers, hardware manufacturers, application providers, and end users.

Uber's dual app experience introduces an interesting challenge for mobile functional testing. This talk introduces methods of doing mobile E2E testing while orchestrating multiple apps. We will discuss the pros and cons of each method and how we scaled them to run with speed and stability.

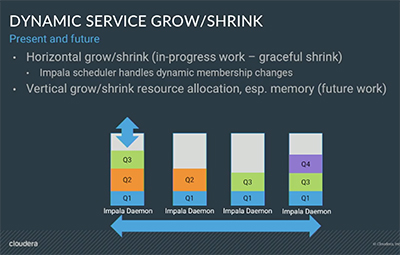
Apache Impala is a highly popular open source SQL interface built for for large-scale data warehouses. Impala has been deployed in production at over 800 enterprise customers as part of Cloudera Enterprise, managing warehouses up to 40 PB in size. HDFS, cloud object stores, and scalable columnar storage engines make it cheap and easy to store large volumes of data in one place rather than spread across many siloes. This data attracts queries and, soon enough, contention for resources arises between different queries, workloads, and organizations. Without resource management policies and enforcement, critical queries can’t run and users can’t interactively query the data. This talk will discuss the challenges in making resource management work at scale for SQL analytics and how we are tackling them in Apache Impala.

Machine learning sits at the core of many essential products and services at Facebook. This talk describes the hardware and software infrastructure that supports machine learning at global scale. Facebook machine learning workloads are extremely diverse: Services require many different types of models in practice. This diversity has implications at all layers in the system stack. In addition, a sizable fraction of all data stored at Facebook flows through machine learning pipelines, presenting significant challenges in delivering data to high-performance distributed training flows. Computational requirements are also intense, leveraging both GPU and CPU platforms for training and abundant CPU capacity for real-time inference. Addressing these and other emerging challenges continues to require diverse efforts that span machine learning algorithms, software, and hardware design.

Adobe Analytics’ underlying query API handles thousands of complex reporting queries per second across a user base of hundreds of thousands. Our engineering team has significantly increased the quality and frequency of our releases over the past few years by mirroring production API traffic to our test builds and running regression analysis that compares the API responses of our production and test builds. Our novel approach allows us to test millions of API permutations using real traffic, without “mocking” any portion of the system and without also affecting the availability of our production systems.

Goku is a highly scalable, cost-effective and high-performant online, time-series database service. It stores and serves a massive amount of time-series data without losing granularity. Goku can write tens of millions of data points per second and retrieve millions of data points within tens of milliseconds. It supports high compression ratio, downsampling, interpolation, and multidimensional aggregation. It can be used in a wide range of monitoring tasks, including production safety and IoT. It can also be used for real-time analytics that make use of time-series data.


Over the past decade, the bulk synchronous processing model has been proven highly effective for processing large amounts of data. However, today we are witnessing the emergence of a new class of applications — AI workloads. These applications exhibit new requirements, such as nested parallelism and highly heterogeneous computations. To support such workloads, we have developed Ray, a distributed system, which provides both task-parallel and actor abstractions. Ray is highly scalable, employing an in-memory storage system and a distributed scheduler. In this talk, I will discuss some of our design decisions and the early experience with using Ray to implement a variety of applications.

As Facebook's user base and family of applications grows, we need to ensure correctness and performance across many hardware and software platforms. Managing all these combinations for testing would be an operational impossibility for small teams focused on a particular service or feature. To make testing scalable and reliable, we built a resource management system called One World to allow teams to dependably request the platforms required via a unified API, no matter its type or location.

Modern businesses serve customers around the globe, but few manage to avoid sending far-flung customer requests across an ocean (or two!) to application servers colocated with a centralized database. This presents two significant problems: high latencies and conflicts with evolving data sovereignty regulations. CockroachDB is a distributed SQL database that solves the problem of global scale using a combination of features, including geo-replication, geo-partitioning, and data interleaving, which together allow a customer's data to stay in close-proximity while still enjoying strong, single-copy consistency. This talk will briefly introduce CockroachDB and then explore how it is able to achieve low latency and precise data domiciling in an example global use case.

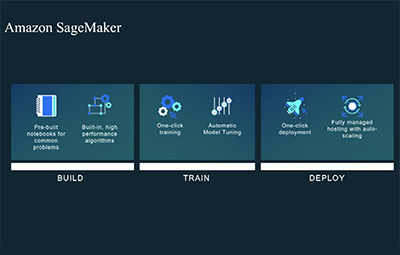
Organizations are using machine learning to address a series of business challenges, such as recommendations, demand forecasting, customer churn, and medical research. The process of machine learning includes framing the problem statement, data collection and preparation, training and tuning, and deploying the models. In this session, we will talk about how Amazon SageMaker removes the barriers and complexity associated with building, training, and deploying machine learning models at scale to address a wide range of use cases.

Machine Learning is infused all around us, including a lot of Google products such as Google Home, Search, Gmail, and more, as well as in systems such as those used by self-driving cars and fraud detection systems. A tremendous amount of effort is being made to improve people’s experiences using products throughout the industry, where products are powered by machine learning and AI. However, developing and deploying high-quality, robust ML systems at Google's scale is hard. This can be due to many factors, including but not limited to distributed ownership, training serving skew, maintaining privacy and proper access controls of data, model freshness, and compatibility. In the face of such challenges, we started an ML productivity effort to empower developers to move quickly and launch with confidence. This effort encompasses building infrastructure for reliability and reusability of software as well as extraction of critical ML metrics that can be monitored to make informed decisions through the ML life cycle. In this talk, we will discuss a few examples where these efforts may be applicable.

Akkio is a locality management service layered between client applications and distributed data store systems. It determines how and when to migrate data to reduce response times and resource usage. Akkio primarily targets multi-data-center geo-distributed datastore systems. Its design was motivated by the observation that many of Facebook’s frequently accessed data sets have low R/W ratios and not well served by distributed caches or full replication. Akkio’s unit of migration is called a µ-shard. Each µ-shard is designed to contain related data with some degree of access locality. At Facebook, µ-shards have become a first-class abstraction. Akkio went into production at Facebook in 2014, and it currently manages approximately 100 PB of data. Akkio is portable: It currently runs on five data store systems.

As computer vision gets mature and ready for real-world applications, we set on a mission to scale and democratize it via cloud services. Starting by integrating some of the latest computer vision work from Microsoft Research, we quickly learned that building such a service at scale requires not only state-of-the-art algorithms but also deep care of customer demands. In this talk, we will walk through some of the challenges we faced, including data privacy, deep customization, and bias correction, and discuss solutions we have built to tackle these challenges.

Attacks relying on the space-time complexity of algorithms implemented by software systems are gaining prominence. Software systems are vulnerable to such attacks if an adversary can inexpensively generate inputs that cause the system to consume an impractically large amount of time or space to process those inputs, thus denying service to benign users or disabling the system. The adversary can also use the same inputs to mount side-channel attacks that aim to infer some secret from the observed space-time system behavior. Our project, ISSTAC: Integrated Symbolic Execution for Space-Time Analysis of Code, has developed automated analysis techniques and has implemented them in an industrial-strength tool that allows the efficient analysis of software (in the form of Java bytecode) with respect to space-time complexity vulnerabilities. The analysis is based on symbolic execution, a well-known analysis technique that systematically explores program execution paths and also generates inputs that trigger those paths. I will give an overview of the project and highlight scalability challenges and how we addressed them in our project.

Michelangelo is the machine learning platform that we have built at Uber. The purpose of Michelangelo is to enable data scientists and engineers to easily build, deploy, and operate machine learning solutions at scale. It is designed to be ML-as-a-service, covering the end-to-end machine learning workflow: manage data, train models, evaluate models, deploy models, make predictions, and monitor predictions. Michelangelo supports traditional ML models, time series forecasting, and deep learning. In this talk, I will cover some of the key ML use cases at Uber, the main Michelangelo components and workflows, and some of the newer areas that we are developing.

Orbital Insight is a geospatial big data company leveraging the rapidly growing availability of satellite, UAV, and other geospatial data sources to understand and characterize socio-economic trends at global, regional, and hyperlocal scales. This talk discusses the satellite imagery domain, how it’s evolving, and the various advantages and challenges of working with such imagery. You will see several example applications demonstrating how machine learning is disrupting this space.

Concurrency is hard and inevitable, given the evolution of computing hardware. Helping programmers avoid the exotic and messy bugs that come with parallelism can be a productivity multiplier but has been elusive. Implementing such a service via static analysis and at the scale of Facebook may sound too good to be true. In this talk, I will discuss our efforts to catch data races, deadlocks, and other concurrency pitfalls by deploying two analyzers based on Facebook Infer that comment at code review time, giving programmers early feedback.

Surabhi leads Engineering for Airbnb's Homes business. Her teams are responsible for guest and... read more

Shan is a senior data visualization engineer at Uber. She is a coder, a... read more

As Vice President for Data Center Strategy, Rachel Peterson oversees Meta’s global infrastructure expansion... read more

David Patterson is a computer science professor emeritus at UC Berkeley, a distinguished engineer... read more


Clement Farabet is VP of AI Infrastructure at NVIDIA. His team is responsible for... read more

Sailesh Krishnamurthy is a General Manager at Amazon Web Services where he runs engineering,... read more

Rich Caruana is a Principal Researcher at Microsoft. Before joining Microsoft, Rich was on... read more

Ke is a software engineer at Facebook. Prior to Facebook, he was the CTO... read more

Vaughn is a 15+ year veteran of the tech industry and a graduate of... read more

Cliff Young is a member of the Google Brain team, whose mission is to... read more

Leslie Lei is a software engineer at Uber, leading the Mobile Test Infrastructure team,... read more

Tim likes to build high-performance systems for scale-out computation. Tim currently works on Apache... read more

Kim Hazelwood leads the AI Infrastructure Foundation efforts at Facebook, which focus on the... read more

Trent Davies is a Principal Scientist at Adobe Systems Inc., where he has worked... read more

Dr. Tian-Ying Chang is a Sr. staff engineer and manager of Storage and Caching... read more

Jinghan has been tech leading Pinterest user growth for the past few years and... read more

Ion Stoica is a Professor in the EECS Department at the University of California... read more

Evan is a Production Engineer for Developer Infrastructure at Facebook. She relocated to London... read more

Peter has been in the software industry for just over two decades. During his... read more


Manasi Joshi is a director of software engineering at Google, where she is currently... read more

Victoria Dudin is an Engineering Manager in Core Data organization at Facebook. The projects... read more


Corina Pasareanu is an Associate Research Professor at Carnegie Mellon University CyLab, working at... read more

Jeremy Hermann leads the Machine Learning Platform team at Uber. Before Uber, he led... read more

Adam Kraft comes from Orbital Insight, where he works on large scale computer vision... read more

Nikos is currently working with the Infer team at Facebook London, helping develop the... read more