






Additional author: Boris Grubic
Think of how you push new releases of anything, whether at work or on some other project. Maybe a release is automated through CI configs, or someone set up a powerful Spinnaker setup. Maybe there’s a release guru, who every X units of time decides, “It’s time to cut a release, so let’s ensure we’re in a good spot.” Maybe there’s a runbook lying around with this guidance: “Here’s the command to run in bash; just let us know in the team chat when you’re about to do it.” Or maybe your deployment experience looks like one of the hundreds of memes created about nightmarish deployments.
How does any of this scale? Let’s consider:
What if one engineer notices a severe bug, and creates a fix? This fix passes code review and is merged into the codebase! The deployment guru is on break, though, and messing with the deployment seems riskier than releasing the bug fix, since even though the process is well documented, it’s still pretty scary to create a release.
Here’s another: Something is broken in the new release of a service, but the effects are only seen in another service. You ping the team responsible for it, suggesting that they consider reverting their service, but they don’t have an on-call—they never thought they’d need one. You crawl through their team’s chats and gasp in horror: They don’t have a documented release process, it’s all tribal knowledge. You’re blocked, unless you can figure out how to hotfix your own service.
And one more–though of course all of these scenarios are just the tip of the iceberg: Your service has thousands of engineers committing code to a new release every day. You cut this week’s release, but as you’re about to deploy it, someone requests something to be hotfixed, since they didn’t realize their service is broken. It’s only one engineer, so what can go wrong? Well…suddenly, 20 people start asking…then 40…then a hundred. How do we even keep up?
In our 2023 Systems@Scale talk, we presented Conveyor, Meta’s Continuous Deployment Solution, and the features we required to drive universal adoption of it. This blog post will focus on actionability, on how we built out Conveyor, as well as dive into the specifics of the challenges we faced and how we dealt with them.
Building Conveyor–and confidence in the concept
At Meta, we stick to the philosophy to “release early, release often.” This allows for the tightest feedback loop between a developer committing code and the code’s features or the fixes making it into production. Not abiding by this has bitten us in the past—in 2014, there was a widely publicized Facebook site outage. Two months before the outage, however, a developer had already committed the fix, but no deployment had happened during those two months. At the time, we committed resources to ensuring our front-end service would have a continuous-deployment pipeline set up. This worked wonderfully—for one service. Over time, we realized that if we wanted other services at the company to adopt this mindset, we’d require more confidence in continuous deployment, and for that, we’d have to provide a feature-rich, safety-minded solution.
At first, Conveyor was essentially a bundle of scripts that set up some cron jobs that would then periodically poll our continuous-integration system for new binary versions and set up the same deployment pipeline for each service. This didn’t allow for any real flexibility for services—some would want to deploy new versions in different ways, such as first deploying to test tiers before production, and others might want to do more fine-tuned rollouts. Our solution was then a second version of Conveyor, creatively named Conveyor2. Conveyor2 allowed service owners to provide a configuration that specified a set of actions that should be performed on new versions of service binary. We allowed for a limited set of artifacts, or external objects within a deployment pipeline—namely a subset of binary formats supported at Meta, as well as commit hashes.
For 94% of services, this worked. Service owners could set up their pipelines to build code, run tests and automated jobs, and create custom canary/deployment solutions. They could also create custom actions by implementing an API. However, there were three main problems with Conveyor2:
- It did not allow for generic/arbitrary artifact types. Integrating new artifacts to deploy required creating new code in the core of our deployment system, and many services used bespoke artifact types to serve their deployment. This wouldn’t scale, since each integration would take at least a month of an engineer’s time.
- All pipelines had to be defined linearly. Conveyor2 didn’t have a way of parallelizing work within a single pipeline. For instance, we might want to run tests on binaries in multiple environments at the same time, such as iOS and Android. In Conveyor2, we’d have to wait for these actions, causing large amounts of latency.
- We didn’t have a method for discovering unique releases generically. Our release creation methods were also all hard-coded and tightly coupled with our core system. This created a problem, as each release creation mechanism therefore would have to be aware of each artifact type, and vice versa.
This resulted in many simple services being happy users of Conveyor, but our largest (and usually most critical services) would still have to rely on custom tooling since they couldn’t onboard onto Conveyor. Thus, we proceeded to create a new version of Conveyor, creatively titled…Conveyor3!
The biggest change was allowing service owners to define artifacts and actions in a Directed Acyclic Graph (DAG), where the actions are an operation to be executed. While before, Conveyor2 could only take one input artifact—a commit hash—and would operate on the same binaries through the whole pipeline, Conveyor3 now allowed our actions to take input artifacts and produce output artifacts, essentially becoming an orchestration engine.
With great power comes great complexity. In exposing a DAG, we also needed to add complexity to how users configure pipelines for their services, and most notably, instead of having ordering implied, actions now had to explicitly list out their input/output artifacts as well as their dependent actions. Most service owners only use two or three actions in their pipeline, and they don’t have many requirements other than “please build and deploy whenever a new version is available.” Hence, we made sure that this common use case can be configured in just a few lines of code, while allowing for extensible configuration for more complex use cases.
Implementation

At its core, Conveyor can be split into:
- Run Scheduler: a service that figures out when to create releases
- Run Creator: a service that figures out when to run actions
- Run Manager: a service that actually carries out said actions
These three services communicate through our sharded Conveyor Core Database. Run Scheduler figures out when to run actions by periodically querying whether or not any releases (a unique set of artifacts, such as a commit hash and list of diffs) have actions that need to be newly scheduled. It does this by recursively checking conditions of an action, such as artifacts being present, or previous dependent actions having already been run. As a Conveyor service, it’s special in that it only needs to interact with and listen to Conveyor itself; it doesn’t have hooks into it from the outside world. Run Scheduler is also responsible for doing validations of releases while they’re in flight: Do any of the binaries contain known regressions? Have the binaries that we’re attempting to deploy expired?
Release Creator figures out when to create releases. A release object represents an execution of a set of input artifacts against a pipeline consisting of a set of actions. Release Creator interacts with simple mini-services called “Artifact Finders” that each implement an API that surfaces whether or not new artifacts are available. Typically, each artifact type has at least one corresponding Artifact Finder service. The Release Creator then handles deduping releases, so we don’t attempt to create duplicate releases through automation, and adds a row to the Conveyor Core database signifying the new release.
Finally, we have the Run Manager, which interfaces with actions. Each action is a separate service implementing a common API. This API includes methods to handle starting, monitoring, canceling, and cleaning up instances of an action, which we call “runs.” Run Manager will periodically call the action service’s methods until the action has finished. The action’s results are then propagated to the Conveyor Core database.
While from a bird’s-eye view this seems simple, a large part of our work is also maintaining a first-class suite of Artifact Finders and Action Services, as well as maintaining UIs that attempt to abstract as much of the information away from service owners as possible. After all, a service owner shouldn’t need to be an expert in what their pipelines are doing, but they should be aware of how these pipelines work. One other challenge in Conveyor’s world is supporting our users. Often, if one of our dependencies (such as CI, package publishing, cluster management, canaries, or regression testers) go down, the errors first surface in Conveyor, as it’s how most service owners interact with said services. This requires the Conveyor team to maintain close connections with their partners in infrastructure.
Many Conveyor services periodically need to poll the state of all ongoing deployments. At first, we attempted to support all services at Meta through one machine, but we then realized that the sheer amount of load that we were taking on was overwhelming. We then attempted to shard our services by a consistent ID. However, in the case of region drains or machine unavailability, a whole fleet of services would suddenly be unable to deploy new binary versions, which was also unacceptable.
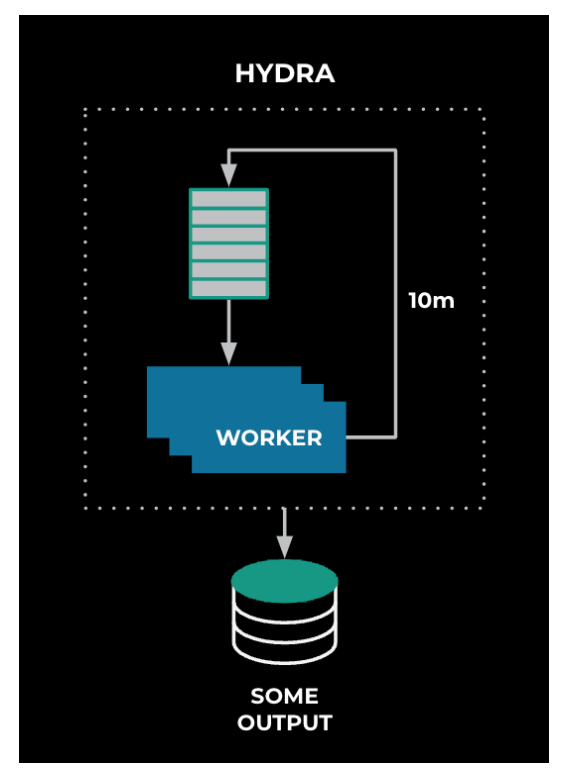
We finally decided upon a framework we call Hydra, named after how the Hydra of Greek mythology can continue to respawn heads even after one of its heads is cut down. In this system, we have a “head”—our Queue Loader—from which the other workers can pick items. The Queue Loader isn’t aware of the workers, nor are the workers aware of each other. The process of jobs being picked off can continue without disruption, even if a worker goes down. The Queue Loader itself is then replicated. If the current “head” goes down, our next Queue Loader can pick up the work from where the previous Queue Loader left off. The services then are in charge of determining whether or not work needs to be done. This allows the Queue Loader to worry about whether or not a service is healthy, and it delegates work instead of trying to manage any deployment state. This allowed us to horizontally scale Conveyor to eventually support everyone’s needs at Meta.
Stopping Known Bugs
Continuous Deployment requires users to be confident that their checks and tests are able to stop deployments when bugs slip through the cracks and make it into source code. At Meta, most shared libraries are statically linked, since they are all a part of our monorepo. A monorepo has huge benefits in that code can be reused across almost the whole codebase. The downside is one bug can affect many services at Meta. We identified that Conveyor was in a prime position to stop these deployments in the case of a bad change being introduced, and thus we created the “Bad Package Detector (BPD).” Given the commit of a bad change, BPD can then identify all binaries that contain the change, and block deployment until a fix is produced.
BPD periodically scans the whole codebase and takes a snapshot of code dependencies up to 14 layers deep. When a bad revision is introduced, BPD will then look through every active release and pause those that contain the bad revision and don’t contain a specified fix revision. If the fix revision isn’t specified yet, all deployments with that package are blocked until one is provided.
This works great, but there are some cases where the blast radius of this can be wide. For instance, remember the NPM Left-pad incident? One package being yeeted basically caused the internet to come to a screeching halt. Some libraries that are used widely can cause most deployments to stop, with no clear remediation other than asking the owners of said libraries to push out a fix, or a revert. This is something we’re still actively working on.
Investigating Current Issues
At the scale of Meta, sometimes it can be challenging to determine what caused a certain regression. While automated tooling such as BPD can help prevent the issue from spreading further, it doesn’t help us when the regression has already reached production. This is where we leverage Landline. Landline is a service where events from the company—test breakages, site events, configuration changes, and Conveyor actions—are pushed to. A user can then use Landline to associate events.
For instance, if a metric suddenly starts going haywire, and a user spots a deployment of their binaries around the same time, it’d be safe to assume that that’s where everything has gone wrong. A user could also take a look at their dependencies, and determine if a new release on one of them is the root cause. This is only possible through unification—with different systems, Landline would have to create an integration with each system, becoming unscalable.
Future Work for Conveyor
Moving forward, one of our challenges with Conveyor will always be usability for every engineer. Not everyone should need to know the inner workings of how all of our systems glue together, but they certainly should be able to know what actions to take when something goes wrong. Currently, the use of Conveyor requires relatively deep knowledge of our packaging system, cluster deployment system, CI, and any other integrations that another engineer may have set up. So, with a company as distributed as Meta, a challenge will always be ensuring that what we present is coherent and simple.
We’d also like to continually speed up Conveyor. We don’t want to reduce developer velocity, so in the future we’d like to replace the “Hydra” framework with an events-based framework, with our polling system as a backup. As we queue fewer events into our polling system, we’ll then be able to run our polling at a higher frequency, speeding up any unneeded latency.
Finally, Conveyor is primed to continually help improve deployment hygiene across Meta, and to raise the bar for all engineers. Deploying new releases can be a daunting task, but with the right tools and processes in place, it doesn’t have to be! At Meta, we developed Conveyor to make continuous deployment a breeze. And we hope that its learnings can be applied by all.

