







Advertising at Meta
Advertising is the primary revenue-generating product for Meta, producing over $113 billion in revenue in 2022, more than 97% of the company’s revenue. Ads are used by businesses of all sizes to reach potential customers, share products & services, as well as content, and to grow sales. The scale of Meta’s advertising platform is enormous; integrated across all web and app surfaces, including Facebook, Instagram, and WhatsApp. As of April 2023, more than 3 billion people use Meta’s Apps daily, with Meta’s messaging apps sending more than 10 billion messages per day. These products empower creators and help them drive engagement with the consumers of their products and content.
In this post, we will discuss how system reliability matters for our commitment to advertiser value, reliability challenges within Ads & Monetization at Meta, reliability levers and how we structure work around them, and the important role culture plays in achieving intended outcomes on reliability.
Revenue and Advertising Value
The goal of our Ads system is to maximize the total value that our Ads deliver to advertisers and people on the platform. This total value is a function of the “spend” (or bids) that advertisers place in our Ads auction, actions that people take after seeing the Ad (clicking, making a purchase), and the quality of the ad as measured by direct feedback from people who saw it. The goal of the Ads delivery system is to optimize the delivery of Ads to maximize the value objective function, and it does that well.
Based on a recent study from UC Berkeley, each dollar spent on Meta Ads drove on average $3.31 in revenue for businesses through increased purchases, purchasers, and overall conversions by 25%, 13%, and 73% respectively. This is a meaningfully higher return than has been measured on most other ad platforms. The study estimates that across the US, more than $500 billion in economic activity and three million jobs rely on Meta’s Ads platform.
Reliability at Scale is Complex
System reliability issues can negatively impact advertiser experience and the value advertisers derive from the platform. In November 2018, a Site Event prevented advertisers from creating and editing ads, affecting many businesses during a peak business window. Since we operate a large, complex set of systems, such events can happen due to many factors.
The complexity of the ads system comes from thousands of changes per day from a globally distributed engineering team, deployments across multiple data centers around the world, and the scale of tens of millions of queries per second on these services. Additionally, Meta operates one of the most complex Machine Learning (ML) systems with some of the largest known ML models on a heterogeneous hardware stack for real-time serving. Lastly, there is a butterfly effect due to chains of interconnected systems, data flows, dependencies, and even external events (such as the Superbowl or World Cup, during which traffic patterns change rapidly).
The ads system has developed over years and is constantly evolving to offer new features, products, and services to customers. Our processes need to support this evolution cognizant of the fine trade-off between reliability and development velocity.
Analytics Value
Impact of SLA violations can vary widely
Historically, engineering teams across Monetization at Meta have relied on the use of Service Level Agreements (SLAs) to measure the reliability of their services. These SLAs typically serve as goals against which one measures the availability of a service, enabling the computation of service uptime and downtime. Another frequently used metric is the error rate for a service. This type of SLA-based measurement is quite convenient, as it is easy to measure and track once logging is available.
One challenge we were facing, however, was that it was not always clear how to map improvements in SLAs to the actual impact to the business: Improving the availability of Service A by 10% can create a very different impact than improving 10% for Service B.
Around 2019, it was becoming unclear how much improving availability from 99.99% to 99.999% for a given Monetization service would impact the business, which meant we needed to establish a different approach.
Focusing on business outcomes
We use Site Events (SEVs) to drive our incident-management processes and learn to address platform gaps, and in 2019 we started leveraging Site Events (SEVs) to analytically measure the state of reliability across Monetization. SEVs are reliability failures that are significant enough to affect business outcomes in a measurable way. Different SEV levels are attached to each event based on the magnitude of disruption to the business.
In Monetization, we quantify the impact of each SEV affecting its services based on the magnitude of advertiser value that is impacted from the start of the SEV to its full mitigation.
This allows us to establish a bottoms-up quantification of the total impact that all SEVs have on the business, as well as to identify which services have disproportionate impact on business outcomes and are hot-spots across the Monetization space, and to focus investments in those areas.
In addition, since increasing advertiser value is a core part of the mission of Monetization at Meta, we can prioritize reliability investments based on return on investment (ROI) and compare the impact of those investments with impact from product improvements.
Reliability improvements levers
Reducing the value lost due to a SEV can be achieved through three distinct levers:
- Reducing the number and magnitude of reliability failure events in the system through prevention and blast-radius reduction
- Reducing the time it takes to detect new issues after they start (faster detection)
- Reducing the time it takes to mitigate the issue after being detected
Algebraically, we can represent the levers through the following formula:

Next we will take a deep dive into each of the levers.
Prevention Value
Earlier we described the levers of reliability in prevention, detection, and mitigation. Let’s first look at how we structure prevention investments. Preventive work, as the name indicates, is essentially formed by areas that prevent reliability blips. Such work can be broad, so to make it a bit structured, we look at these investments as horizontal and area-wise vertical workstreams.
Horizontal investments are broadly applicable, substrate projects that apply across functions within Monetization. A non-exhaustive list of these investments includes:
- Testing, generally considered a good engineering practice, follows a more intentional structure here at Monetization at Meta. It comprises multiple sub-streams across back-end, mobile, front-end, ML, and data infrastructure in:
- pre-commit and pre-production testing development stages
- configuration testing: due to their importance to production systems’ behavior, we treat configs the same as code
- AB testing: aims to measure the efficacy of product features and infrastructure changes with respect to planned outcomes
- ML Reliability, a less discussed aspect of ML in the industry, has been a prominent investment theme for us in the last few years. It is structured into:
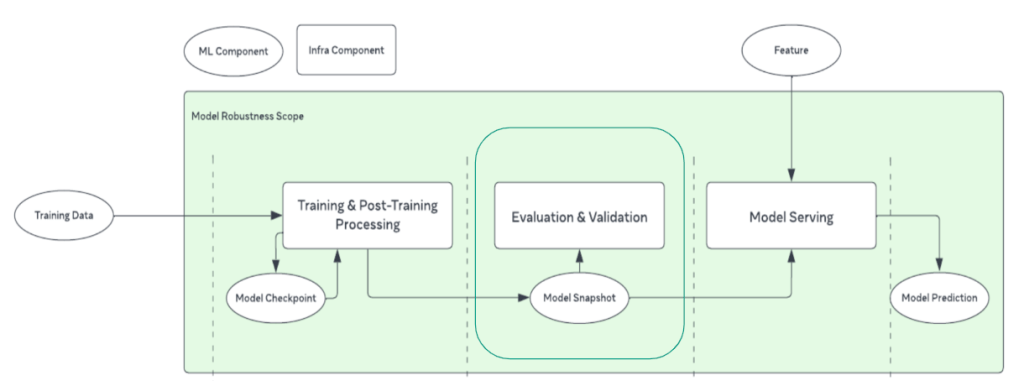
- Model validation: aims to ensure that continuously trained model snapshots are healthy for serving traffic before they roll out to production
- Feature Corruption Detection: systems we’ve built to detect feature drifts, since unexpected feature value changes have a direct correlation with prediction quality
- Training Data Quality: data quality validation systems that ensure models are trained on correct, high-quality feature data and labels
- ML interpretability: an effort to ensure model predictions are reasoned and understood systematically for product-behavior tractability
- Dependency Resilience, which is a suite of projects to ensure production systems are operated reliably at scale. This consists of the following workstreams:
- Auto Scaling/resource management: our systems’ capacity needs are dynamic with traffic changes due to internal and external events such as geographically distributed traffic patterns through the day or special events such as holiday sales events
- Overload protection and graceful degradation: to maintain intended product behavior at all times
- Disaster readiness drills: to prepare our systems for large-scale and widespread events such as data center or infrastructure failures
- Dependency management: with a large interconnect of systems with a complex dependency graph, we implement SLA guarantees across these systems for stable and predictable production quality
- Safe-change rollout, which is a first-of-its-kind-in-the-industry system. It’s deployed at a large scale to evaluate the risk profile of all development changes going into our system to guide efficient development while maintaining top-notch reliability of our stack
Vertical investments, on the other hand, are area-specific challenges, and cover the technical depth of a focused area. The examples here include systems that do:
- Realtime Ads serving: a highly available, large-scale system that orchestrates ranking and real-time delivery of ads across all surfaces and product categories
- Optimization products: consist of systems that drive marketplace dynamics of auctioning, pacing, and value optimization across all categories of Ads products and interfaces
- Data infrastructure: formed of real-time feature serving, events processing, efficient storage of Exabyte scale data, offline batch processing systems for ML, and analytics
We guide these investments with a pretty tight and precise measurement of ROI to ensure meaningful outcomes and to invest our efforts in a value-directed manner for our advertisers and users. SEVs guide short-term investment decisions, so we learn and adapt swiftly from events as they occur, while long-term investment prevention is aimed at bending the advertiser loss curve over a multi-half horizon. We constantly take feedback from our advertiser community and incorporate it into both short-term and long-term planning processes.

Prevention Success Story: Model-Snapshot Validation
As shared above, prevention is one of the key levers to sustainably address reliability issues while keeping operational costs low. Let’s explore a success story that exemplifies our efforts to prevent the deployment of faulty ML models into production.
The Ads delivery system optimizes for the total value that our Ads deliver for advertisers and people on the platform. It does so by building a highly scaled and distributed Ads delivery system where ML plays a pivotal role in optimizing for the outcome for both advertisers and people. Given the complexity of Ads system optimizing for varying outcomes such as clicks, views, app installs, and so on across several placements and user preferences, there are hundreds of ML models deployed in production optimizing for various segments of traffic for different stages of ranking.
The scale and frequency of model-refresh rollouts into production presented an unprecedented challenge to the reliability of our Ads delivery stack’s performance. The non-deterministic nature of the model’s prediction quality magnifies the demand for innovative techniques, as conventional methods, like monitoring for data-distribution changes, prove ineffective due to their low precision and recall rates.
To address these challenges, we built a highly scalable and extensible model-validation service to evaluate model-prediction quality at scale in a pre-production environment. Since model quality is hard to reason about in absolute terms, we devised intelligent algorithms to compare quality across snapshots with greater emphasis on high precision and recall. This model-validation service was built from the ground up with extensibility and scalability as first-class properties, which enabled us to iteratively and “configurable-y” apply various classes of evaluation criteria to effectively detect and prevent faulty models from rolling out into production.
As machine learning continues to advance rapidly, incorporating new modeling techniques and managing a substantial number of production and experimental models, our strategic focus has been to prioritize model onboarding based on the model’s business significance. This has resulted in the reduction of advertiser value impact by hundreds of millions of dollars due to faulty models in production. Furthermore, as our validation service matured, we established it as a fundamental stability practice for the introduction of architecturally new model types as they evolved, securing a consistent high ROI in the long run.
Detection Value
Multiple layers of detection
Since it is not possible to prevent all SEVs, detection plays a critical role in reducing the magnitude of impact from a given issue. The total advertiser value impacted is proportional to the time the issue stays unmitigated multiplied by the instantaneous impact, or burn rate (see Figure 1).
For that reason, we established detection SLAs based on the burn rate: fast and very fast burns have much more stringent SLAs than slow burns. This is quite natural, as fast and very fast burns are usually much more detectable from a business outcome standpoint.
Our detection capabilities are built from three main ingredients:
- Real-time monitoring
- Comparison to forecasts
- Alerting based on anomalies and deviation from expected trends
In order to maximize the recall of issues being caught early by our automated detection systems, we have built multiple layers of detection:
- System-level layer: Each team owning services directly or indirectly impacting Monetization sets up monitoring of the health of their services. This monitoring is expected to be real time and provide the capability to detect issues the fastest.
- Outcome-level layer: A centrally-led, real-time monitoring of the health of the entire Monetization suite of systems. The goal of this monitoring is to detect in real time any issue that may have been missed at the system level.
- Ecosystem-level layer: Another centrally led monitoring of the health of the Monetization ecosystem. This monitoring is focused on slow-burn issues that may be too subtle to be identified in real time by the other two layers. Because more data points may be required to identify such subtle issues, the monitoring is not done in real time. It focuses on monitoring ecosystem-level metrics that are symptoms for these slow-burn issues. Note that in recent years, a majority of advertiser value impact occurred before these slow-burn issues could be detected.
Mitigation Value
Similarly as for detection, quickly mitigating the identified issues will directly translate into advertiser value being preserved.
After an issue is detected, the first critical step is to route the issue to the right team. This is especially important when the issue is detected by a non-system-level layer. After triaging and routing the issue to the right on-call, they need to perform root-cause analysis and attribute the issue to a change impacting the system: This could be a recent launch, a failure from an upstream system onto which the service is dependent, or an external cause (e.g., high load on the system).
After root cause analysis is performed, the team needs the tools to be able to revert the changes and solve the issue.
We have set up SLAs for the time it takes to detect an issue to its full mitigation. Similarly as for detection, the SLA is based on the instantaneous impact of the SEV .
Cultural Value
Creating a culture of reliability
We found that improving reliability across a wide area such as Monetization required a deep commitment at all levels.
First, organization leaders need to clearly call out that the reliability of the engineering stack should be a top priority for their organization, alongside new product development. This means upleveling reliability goals, closely monitoring progress against those goals, and holding teams accountable to maintain a high bar on reliability from the earliest stages of new product design to the release stages and beyond.
We found that holding regular reliability reviews is essential for setting clear expectations across large organizations and helping teams take ownership of the outcome.
One example is SEV deep dives that lead to actionable recommendations for completing follow-up engineering work as well as improving best practices, processes, and tooling.
Prioritization also means making significant investments over years to support such effort, both in terms of headcount and infrastructure resources. Oftentimes, teams may underestimate the engineering effort and resources needed to ship a new service or product that is reliable. Having a “reliability-first mindset” enables accounting for such investments early in the development process and keeping a high bar on the expected product-reliability outcomes.
Then, we need to set up clear ownership and accountability across teams to drive those improvements. This means empowering teams with the right resources and support to achieve more and more aggressive goals across time towards our long-term reliability objectives.
Last, recognition of good reliability work is key. Celebrating and rewarding successes is as important as learning from failures. In Monetization, we created an internal forum to share examples of “SEVs that never were” because of great prevention work. This motivated teams to share their learnings and best practices with the entire organization. In addition, we developed a measurement of the expected advertiser value gained as a result of preventative work, which helped measure the return on investment and the impact of specific engineering workstreams.
What’s next
We have seen a more than 50% reduction in the impact of reliability issues since the program started. However, the journey is not yet complete. Three observations:
- Maintaining good reliability requires prioritization and constant investment: a large number of engineers continuously invest in issue prevention, early detection, and quick mitigation
- Maintaining good reliability requires balancing reliability with supporting other engineering investments across Monetization
- Maintaining good reliability requires investments in providing engineers with tools to help them develop Monetization systems even faster with reduced reliability risk.

