






Background
As the significance of AI continues to grow, it is fueling a wide array of products and services encompassing recommendation systems, generative AI, fraud detection, image classification, and beyond. An inference platform manages the deployment of trained machine learning (ML) models and provides predictions at serving time.
Here is a typical inference workflow:
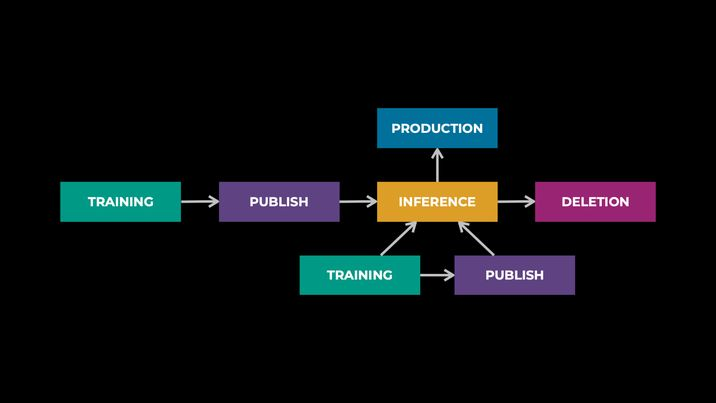
ML engineers publish trained models to be deployed in the inference platform, optionally doing post-training optimizations and validations. These deployed models are subsequently queried (aka serving) for predictions within various products and services. Throughout its serving lifetime, a model can undergo continuous training and updates. Ultimately, a model may be replaced or deleted if it is no longer in use.
While the overarching workflow may appear similar across various use cases, it is important to acknowledge the substantial diversity and heterogeneity that exists among them from multiple perspectives.
- The model architectures could vary widely. They could have a range of complexity, performance behavior, and bottlenecks.
- The hardware types could also vary. ML inference uses different types of hardware, such as CPU, GPU, and MTIA, which create extra complexity for the system.
- The user requirements can vary significantly across different use cases. Factors such as latency, availability, model freshness, and model consistency may vary from one application to another.
Vision
IPnext is a unified platform to manage the entire lifecycle of model deployments, from publishing to serving.
- Its modular design allows us to orchestrate a wide range of complex workflows under a single system. For example, different model architectures needed for ranking or generational AI use cases can be supported under one platform.
- It provides a global and highly automated capacity management that is quite important for inference at scale. It supports model deployments across numerous data center regions, with heterogeneous hardware such as CPUs and GPUs.
- It is important for any system at scale, especially AI inference systems, to provide high reliability and low latency for both request serving and model updates.
Architecture
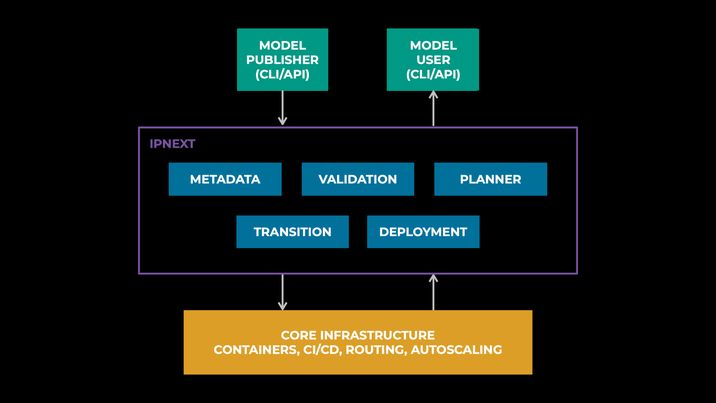
At the top of the diagram above, we show users who interact with IPnext through interfaces such as APIs or CLIs. On the left side, we have an ML engineer who publishes a newly trained or refreshed model. On the right side, we have a product engineer who wants to integrate this ML model in a product such as ranked feed. IPnext supports CRUD operations on the models, and it provides appropriate metadata needed for prediction-request serving.
At the bottom, we show core infrastructure (ICSP) that provides foundational cloud services such as container management, CI/CD, autoscaling, and much more.
In the middle is the new IPnext platform utilizing a collection of composable modules that work together to enable diverse workflows:
- Metadata: fetches dynamic model metadata, including new model snapshot versions, from upstream training systems. It ensures that the platform stays up to date with the latest model changes made during the training process.
- Validation: performs various validations to ensure that a model can be successfully deployed, such as verifying that the model file path exists, that holiday freezes are respected, and so on.
- Planner: generates a deployment plan across multiple data centers, while considering heterogeneous hardware and regional constraints.
- Transition: safely and gradually transitions to a new deployment plan or new model versions, shifting the traffic demand and capacity supply in lock-in steps.
- Deployment: generates lower-level infra specifications consumed by core infrastructure to materialize the deployment plan into runtime containers.
We can easily add new modules, and compose a new workflow leveraging a collection of them, towards our vision to provide a flexible platform supporting diverse use cases.
Generalized Data Model
Before we dive deeper into the technical details, we want to introduce the data model used across all the IPnext components.
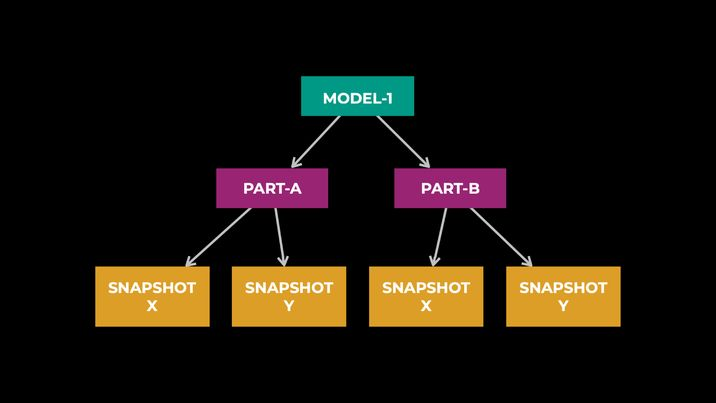
An ML model is decomposed into multiple parts to support various requirements, such as the distributed hosting needed for large models or heterogenous hardware hosting. Each part of the model can further have multiple instances—aka snapshots—representing different versions of a model. Models have different requirements for how snapshot transitions are handled. For example, some models require all their parts as well as their snapshot versions to be synchronized for each inference request, while other models do not require snapshot versions to be synchronized across various parts.
In IPnext, we support a generalized data model that allows us to provide a common set of reusable components, resulting in a rapid development of new serving paradigms and the support of new hardware classes.
Deep Dive
Heterogeneous Model Architectures—aka the Serving Paradigm
Efficiently serving different models poses a challenge when each model performs significantly differently. Additionally, distributed hosting of a model across multiple hosts presents significant technical challenges. Distributed hosting allows us to scale beyond the limitations of a single host (memory or compute) and improve utilization by disaggregating the partitions.
Traditionally, serving a model in a distributed fashion requires a lot of effort from infrastructure support to create a different setup. To address this problem, IPnext allows users to serve models with an arbitrary split and deployment across multiple hosts. Users only need to provide policy as a configuration. A model is handled in the following steps:
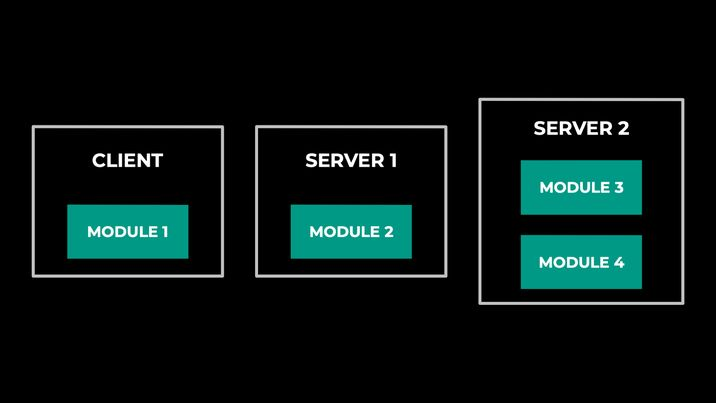
- Split models into different modules:
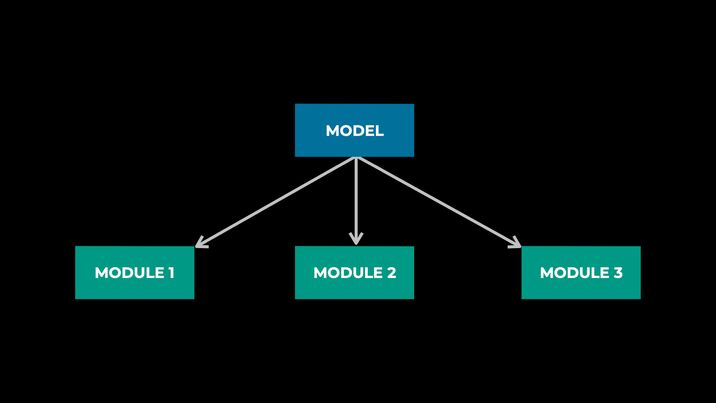
- Deploy modules across different hosts:
- Execute inference request across different modules:
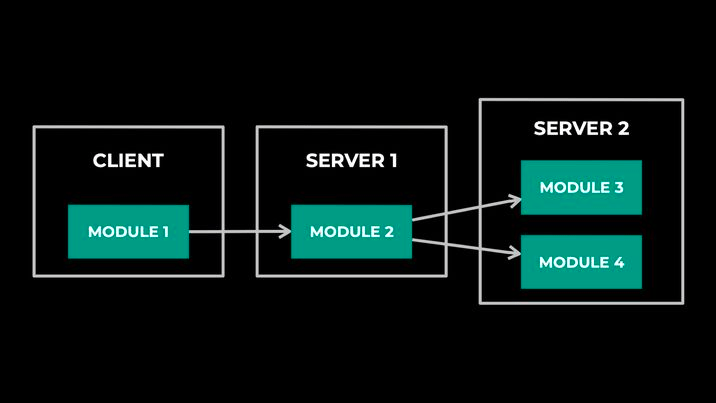
A model will be split to different modules; these modules could be deployed to different places (represented as parts in the data model), and a request could be served across these modules automatically by a predefined DAG across modules. In addition, IPNext could also provide synchronization guarantees among these modules for snapshot transition.
Heterogeneous Hardware Fleet
Effectively managing capacity across multiple data-center regions with heterogeneous hardware poses a significant challenge at scale. This challenge is further compounded by the dynamic nature of traffic demand and capacity supply, which requires constant adjustments to ensure optimal alignment between the two.
IPnext provides global and highly automated capacity management. A model owner provides only global capacity and latency tolerance budgets, and the platform manages the entire deployment process by abstracting out the complexity for the user.
The Planner aims to find a globally optimal placement for a large number of model deployments while respecting the user-provided budgets and infrastructure constraints. The figure below provides a sample output of the Planner.
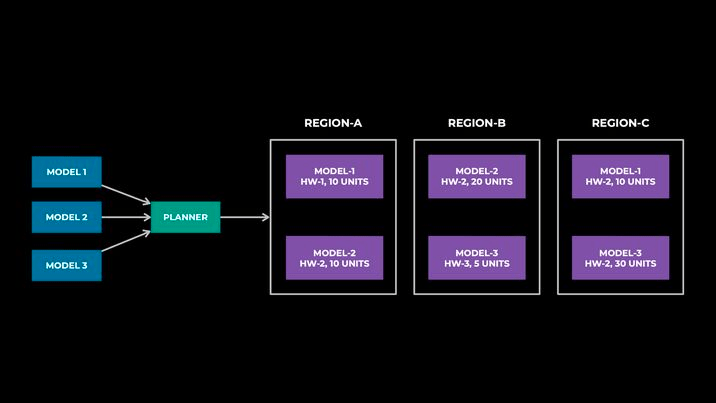
We established a clear separation of responsibilities among components. The placement planner runs every N hours for all the model deployments managed by IPnext, and other dynamic systems such as autoscaling react to real-time changes per model deployment—for example, unplanned traffic-demand changes or disaster scenarios.
Early Learnings and Future Work
IPnext is a new platform, and we are in the early days of building it. As we learn new lessons, we will improve its design accordingly. Here are a couple of things we’ve learned so far:
- Inference at scale needs to support diverse workflows consisting of several moving parts. A unified platform is key to effectively develop and debug such workflows, eliminating fragmentation within the ecosystem.
- The rapid pace of innovation in AI models and hardware architectures is here to stay, making it necessary to have flexibility and extensibility within the platform in order to effectively adapt to and accommodate these advancements.
In our ongoing work, and with an eye toward the future, we are working to onboard state-of-the-art AI models to IPnext. IPnext will also support the GenAI workload and MTIA hardware in production. A scalable and flexible inference platform is the key ingredient to succeed in AI, and our mission is to build that platform in IPnext.

