









Motivation/History
Configerator is a system that rapidly distributes service configuration files across the server fleet. Changes are distributed to all servers in only a few seconds. This can be problematic when a bad change is introduced, as it can quickly trigger global misbehavior. When a change also affects the internal tooling needed to find and unwind the issue, resolving that issue and restoring our products to normal working order can take even longer. In this post, we’ll review the evolution of Meta’s configuration change safety systems and describe how it helps quickly recover even when a bad change makes it through validation into production.
To detect and prevent this type of failure, the Facebook web application leverages its independent deployment model to examine the behavior of a new configuration in a real-life environment before applying it globally. Our global deployment is split into logical and physical groups. Originally, these were “clusters,” specific sections of a given data center that could be independently monitored at low levels (machine utilization and health) and very high levels (user engagement). We have since moved to a “regional” architecture—such that a given region is mostly self-contained and can be independently monitored (and drained).
For a number of years, our web tier has run special pre-deployment checks every time a config that it consumes is changed. For each change, a region is selected at random, and the configuration is temporarily applied to this region’s web hosts. Our automated health-check system then compares the selected region to the rest of the fleet across a number of low- and high-level health metrics. If there is any indication the change has caused one of these metrics to regress, the configuration change is automatically rejected. Otherwise, it’s propagated across all deployments.
This was relatively simple to do on the web tier; web servers are a relatively small fraction of the overall footprint in a given region, so comparatively fewer servers needed to receive an experimental change. Our application-level monitoring frameworks also allowed us to transparently aggregate metrics by cluster and region, meaning that existing health checks for the entire fleet could be independently compared across its composite deployments. Web’s cluster canary system provided a template that we could later extend to validate configs unrelated to our web application.
Regional Config Validation
To validate configuration beyond just our web application, we use regional config validation (RCV). In RCV, instead of running our tests on just a particular service in a cluster, we are able to expand our tests to the scale of a data center, using a data center region as our “canary.”
In the industry, we call this type of “percent of production” test a “canary,” referencing the phrase “canary in the coal mine,” where miners would bring a canary, a bird that they were willing to sacrifice, into a mine to determine if there were noxious gasses and thus to save miner’s lives. While nobody intended to hurt the canary, its death provided a reliable early warning signal that the miners would be in trouble soon if not evacuated.
During RCV, which is the final step of our config deployment validations, we send a new configuration value to a randomly selected data center to test whether it has any negative impact on our major products. This is possible because we have over 20 data center regions, as shown in Figure 1, many of which run our major products (Facebook, IG, WhatsApp, and Messenger), and we operate our data centers to be redundant: A single data center can go down without affecting the end-user experience on Facebook, Instagram, WhatsApp, or Messenger.
After a change deploys to a single region, we measure the RCV metrics in that region. Importantly, all of these metrics are aggregated and sliced by region, letting us determine the health of every region independently. These metrics include
- Errors and fatals from Facebook, Instagram, WhatsApp, and Messenger. If we are returning a 500 error to our users on requests, then we know the product isn’t working.
- Service binary crashes. If the services that power our major products are crashing, then they’re unable to serve any requests.
- Topline business metrics from our offerings, such as revenue and engagement metrics. If the change has a significant negative revenue impact or causes a large change to engagement (e.g., a sudden drop in the number of likes or comments), then we block the change.
- System indicators like response payload size. If the change affects the type of response that the server sends—for example, causing the number of bytes sent to decrease or dramatically change the bandwidth required for an individual request—this likely indicates that the change has unintended consequences.
The key properties of these metrics are
- Metrics should only detect catastrophic outages. Because RCV stops changes from landing throughout the fleet, metrics should be high signal and very low noise.
- Metrics should be maintained constantly. After a false positive, we analyze the event and make tweaks (e.g., adjusting thresholds or rewriting alerts).
- Metrics need a 24/7 response. These metrics indicate a possible site outage and, when they fire, the need for an incident responder to immediately do a root-cause analysis, including providing runbooks and guarantees on investigating and fixing the issue.
If we end up detecting that a regionally measured metric has violated our health checks after testing a change in that region, then we’re able to block the change from going any further to all regions. While the single region might be in an unhealthy state, requiring, in some cases, a manual recovery, we are able to drain any remaining user traffic from the region and successfully prevent all products globally from becoming unhealthy.
In the case where a change is blocked, we might have at least one region in an unhealthy state. Since we can tolerate having only a single region down, we can’t “canary” that change a second time, as that would risk having two unhealthy regions at once, which would be a difficult situation to recover from. This means we need to utilize an automatic kill switch to prevent those configs from being canaried a second time and thus prevent a retry from bringing down two regions. Once this kill switch is in place, the system pages a human, who needs to investigate and remedy the issue to allow config changes to resume.
This final stage of config deployment takes only ten minutes to run to collect enough signals to determine whether a config change is catastrophic and subsequently block the change. In addition to this final stage, we run another initial stage with service-specific health checks that take about ten to 20 minutes. You can read about the way we measure service health in Anton’s post [LINK to Anton/Chris H’s @Scale 2024 post]. With these two stages as our validation, the majority of our config changes—more than 95 percent—are able to reliably deploy to production in under 30 minutes.
A Real-World RCV example
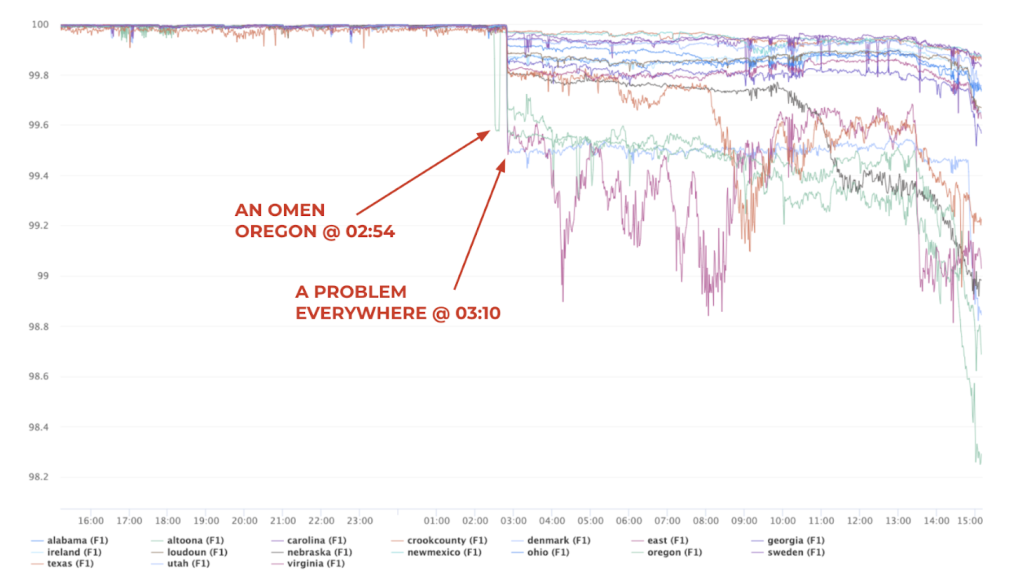
Here’s an incident during which RCV prevented a site outage: An engineer initiated a problematic change, decreasing a timeout below a suitable threshold. This broke logins in one of our regions, affecting that region completely. RCV detected the breakage in the region and prevented the change from deploying everywhere, restoring site health nearly immediately. Figure 2 shows the timeline of landing, detecting, and reverting this bad change.

This type of story has played out at least half a dozen times since we started rolling out this protection a couple of years ago, successfully preventing major site outages by limiting the blast radius of a bad change to only one region.
An Added Advantage: Venn
Even when our canary protections fail to keep misconfiguration from production, they give us important clues for tracking down bad changes and undoing them. This works because we run canaries in several stages. Application-specific canaries are first, including our web cluster-level canaries described at the beginning of this post. Next, we run RCV. Finally, we land and distribute the config. Each of these steps could be visible on some timeseries or other monitoring. For example, we might see some services become unhealthy in one region for around ten minutes, followed by recovery, followed quickly by another region becoming unhealthy, and finally all regions becoming unhealthy.
Because the config-write rate is high, and there may be some time delay between config being written and a service reacting to it, correlating any of these stages to a given change is quite difficult. There may be hundreds of candidate configurations for each stage. Luckily, each config mutation is tested independently. This means that the number of configs that progress through the same regional sequence as our bad config is usually small.
Venn is an internal tool built to crawl through configuration test logging and identify configs that underwent a particular testing sequence. This reduces the search space from hundreds of changes to a much smaller number (with one rollout step, there are typically ten to 20 configs. With two steps, there are typically one to five configs). Venn accepts an input of a list of region and time pairs and optionally a final timestamp when the engineer expects a configuration landed. The tool builds sets of configs for each timestamp: Each set consists of the configs that were canaried (or landed) in the given region at that time. It then intersects the sets to find only the configs that underwent this exact sequence. This reduced list of configs is much easier for an engineer to skim to find the bad change.
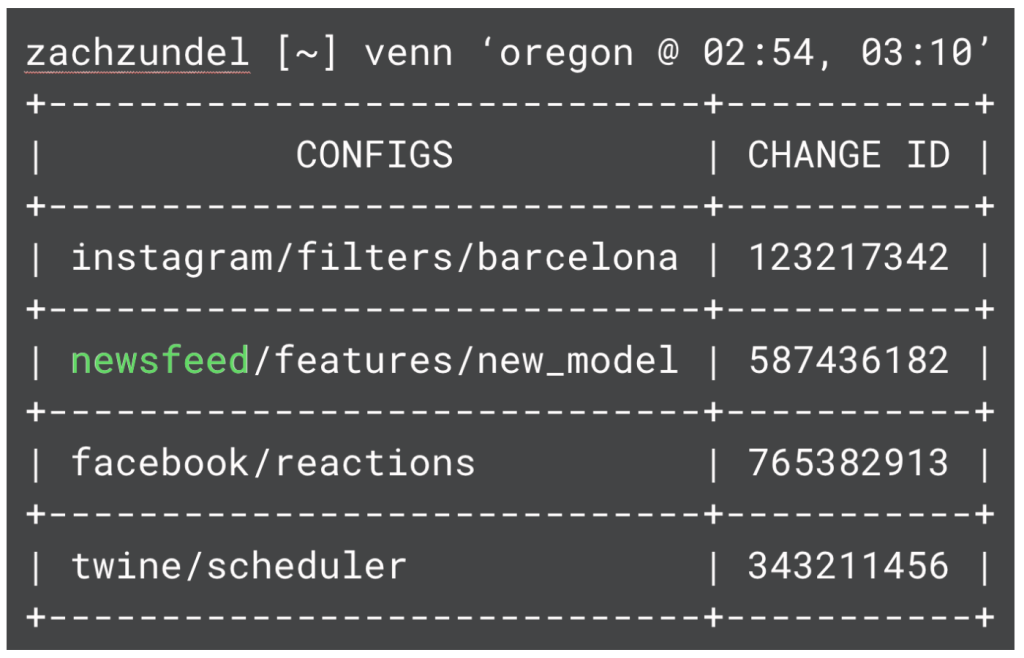
Using Venn has sped up dozens of incident investigations. It was originally most useful in the web tier. Since that tier had a pre-existing canary spec, web configs would go through longer canary pipelines, which means there were more possibilities for a given config’s rollout sequence. As more configs are onboarded to RCV and more services build independent regional canaries, it has proven generally useful for speeding up the investigation and mitigation of config-caused incidents.
Extending RCV and Venn
As we increasingly adopt RCV to be more effective, we are also working on extending the same approach to other areas. For example, we’re experimenting with deploying to multiple regions on every deployment to do root-cause analyses of bad changes even faster. When we know a change is safe on our top-line business metrics in a single region, instead of continuing to 100 percent of production, we can stagger the deployment to more regions to generate a unique “fingerprint” of multiple regions.
This will also help us automate the rollback of any suspect configs by automatically detecting a region fingerprint pattern in a metric and reverting the possible culprit changes.
A maximalist version of this idea that we’ve considered is to stagger a deployment across all of our regions. However, it can be challenging to collect metrics fast enough to make this possible; we also know that a reasonable upper limit for delaying the average configuration is about 30 minutes.
Config Safety in 2024
We know these protections work, but at the start of 2024, the majority of configuration changes (by volume of changes) did not go through RCV. Meta has 100,000-plus daily configuration changes, many of them coming from automation, and those made up the bulk of changes skipping RCV. In addition, many of the systems skipping RCV were built before the protection was designed, requiring updates to make them compatible with a delay in rolling out configuration to production. Many systems expected their configuration to deploy everywhere, all at once—but we know this can lead to incidents.
In 2024, we had two site outages that made it into the press. Both were triggered by changes that went to production without sufficient validation. Without RCV and Venn running on those changes, we weren’t able to block them, and they were harder to investigate and diagnose once they had reached production.
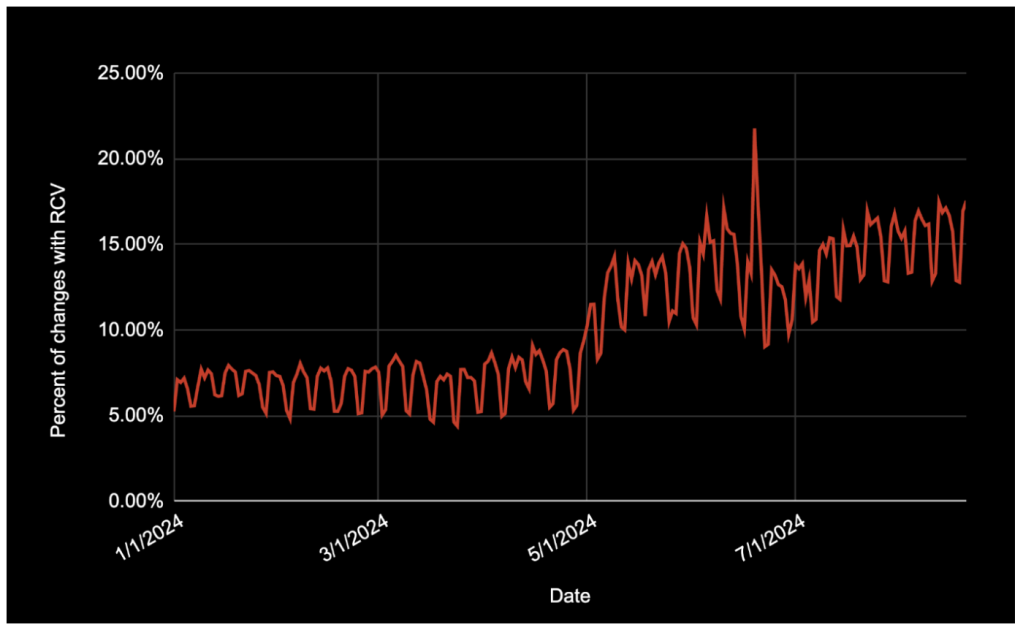
Therefore, we are on a journey in 2024 to turn on RCV and our other safety systems where we can. Since we launched this effort a few months ago, we’ve increased the percentage of configuration changes running RCV from about five percent to over 15 percent, as seen in Figure 3. While the bulk of the changes not running RCV come from a couple of systems, there is a long tail of systems that didn’t historically run RCV and needed to be opted-in over time. Some of the challenges with turning on RCV included migrating synchronous config editors to asynchronous, updating developer-facing flows to surface config landing status, and even rearchitecting how systems read configuration to tolerate divergence across data center regions.
While RCV works, it’s still hard to run it everywhere—and we don’t expect to ever hit 100 percent of changes. Many configuration changes are unable to wait for ten minutes of signal. For example, security configs are time sensitive—you wouldn’t want your front door to lock 20 minutes after you leave the house! Other internal configurations like autoscaling, shard maps, and routing weights are also time sensitive. We need to quickly respond to changing traffic patterns or else we risk overloading our infrastructure. Additionally, some other configs are sensitive with regard to developer productivity. It can be difficult to add a canary to a config used as part of a developer workflow or to orchestrate a feature rollout.
To address those use cases, we’ll need to think beyond RCV. We are working on building the next generation of change safety systems that can enable faster releases and unblock business use cases such as security and AI.

