










At Meta, we manage a planetary-scale AI training fleet comprising thousands of GPUs used for training a variety of models across Meta and its products, including Instagram, Facebook, and Whatsapp. To ensure we can effectively and efficiently use this hardware while continuing to improve our products at the pace AI platforms and services are moving forward, we had to rethink how to plan capacity at Meta, keeping AI training front and center. In this blog post, we will share how Meta manages this AI training fleet in the new Capacity Planning paradigm, and how products such as Threads use this end-to-end (E2E) system to plan for their growth and expansion.
Meta Capacity Planning: A brief intro!
In Meta Capacity Planning (MCP), we take into consideration usage and cost attribution when planning for our product suite (Facebook, Instagram, and Whatsapp). Simply put, MCP is an E2E system that allows Products, Platforms, and Infra to speak a common language and to ensure product growth and usage is accounted for when planning fleet expansion and GPU refresh.
Internally at Meta, we divide our users into three key personas:
- Products such as Instagram (IG) and Facebook (FB).
- Platforms that offer services such as Compute and Storage.
- Infra: This includes Capacity infra teams like ours.
Prior to establishing MCP, Infra’s job was to forecast product growth and keep up with the increasing demand from P roducts. We could evaluate the cost to run a platform, but we didn’t know how much of this cost was attributed to specific products. In this new MCP paradigm, however, the jobs for these three personas have changed:
- Products forecast capacity: They tell us what they want, how much of it, and where.
- Platforms tell us what is needed to deliver each unit of capacity and how they are pricing these units.
- Infra no longer does the forecasting but is instead responsible for making and fulfilling capacity promises and maintaining the common-capacity management stack.
E2E flywheel
Let’s look at this paradigm as an E2E flywheel. The cycle begins with products forecasting demand. Platforms, on the other hand, need to instrument calls across the stack to accurately report usage and attribution. The Infra Capacity team is responsible for tooling and for the process needed to build a quarterly plan incorporating infra constraints and finance-budget limits. Once this plan is locked, it is reviewed with leadership, where ROI trade-off decisions are made, and we receive approval for a plan of record. After the leadership review, we place orders for additional resources such as servers and racks. Once the racks are received, they are set up and brought online based on demand, and Platforms can start vending resources and metering usage. As illustrated in Figure 1, this whole process is orchestrated by the central Infra Capacity team.
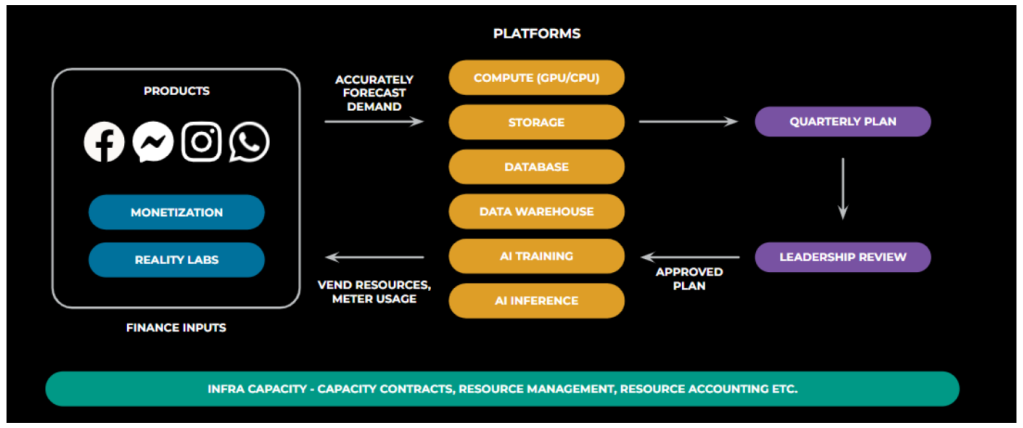
Why MCP: Growth and complexity in AI training
Like many of our industry counterparts, Meta products saw a pandemic-era growth in usage resulting in a capacity crunch that has continued post-pandemic. Our growth and complexity came from four key areas:
- Organic growth: The growth of our global footprint through new and more advanced data centers.
- Inorganic growth: The launch and usage of new apps such as Threads, which already has more than 175 million active monthly users.
- Industry changes: The introduction of large-language models (LLMs) and artificial general intelligence (AGI) efforts further increased industry-wide demand for the most expensive hardware–GPUs.
- Constraints: Budget and financial constraints post-pandemic.
With the above industry changes driven by the AI boom, GPUs became the most constrained hardware resource. Specifically, the reasons why we had to rethink our AI-training and capacity-planning paradigms together are:
- AI training is the fundamental building block for all LLM and AGI efforts.
- AI training uses computationally expensive resources—GPUs—and GPU providers are not able to keep up with demand.
- A combination of cost-prohibitive hardware and reduced supply leads us to a heterogeneous hardware mix, and today we operate a fleet composed of Nvidia, AMD, and Meta’s own silicon.
- Training is a much more complex ecosystem than inference or other non-AI workflows. Since AI training requires a unique set of supporting services for storage, and since these hardware accelerators and services need to be in the same region, decisions about where to place racks and how to train models are interlinked to ensure we don’t have to replicate cross-region data or have a bunch of fragmented AI zones.
Meta’s AI training strategy
So how does Meta enable efficient usage of AI training hardware at scale? Meta’s Capacity Infra had to rethink the entire E2E workflow for training AI jobs and for how it connects to Capacity Planning. We shifted our AI Training Capacity Management strategy to a model whereby we capture the Product’s intent for capacity (such as use cases for AI training needs), and Infra provides them with solutions that balance efficiency and fungibility, depending on the use case provided.
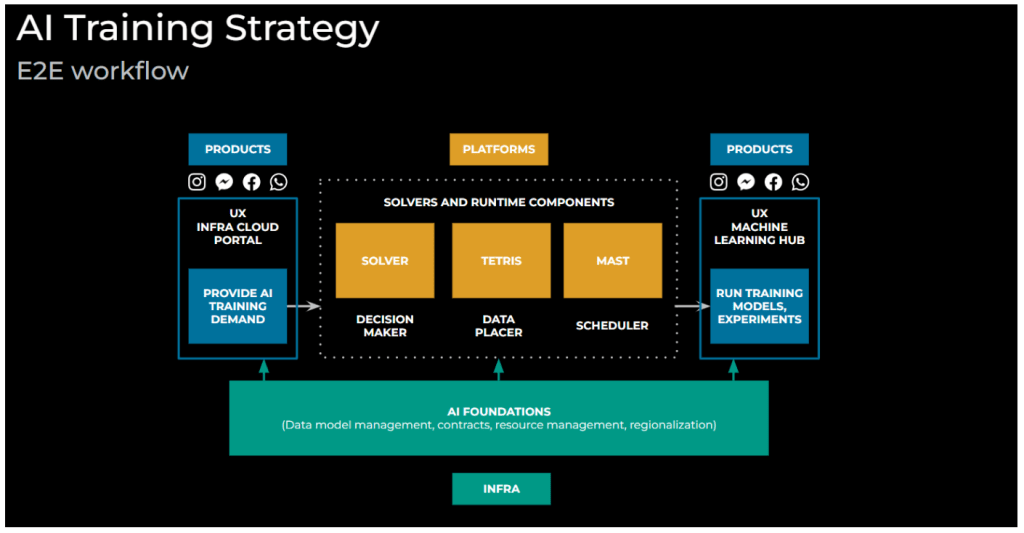
As illustrated in Figure 2 above, the E2E Workflow for AI Training Capacity Management involves collaboration among our three main personas (Product Groups, Platforms, Infra Capacity).
- Products provide their forecasted, multi-year, AI training-related hardware demand into our tooling, Infra Cloud Portal.
- Platforms’ resources are managed through the middle pipeline. The solvers and runtime components help process their resources, co-locate data, and schedule ML training jobs on Meta’s internal computing infrastructure.
- Products will then run their AI training jobs and experiments on Meta’s ML Hub.
- Infra Capacity provides the AI Foundations for all of the above to run on, playing a part in almost all stages of the pipeline.
AI training foundations
Capacity contracts
Capacity contracts are the commitments between Meta Capacity Planning, Platforms, and Products. They are agreements that designate the amounts of resources a product gets for a defined period of time. During the planning period, Products groups submit a demand plan to MCP based on constraints such as budget, data center power, data center space, and more. MCP then makes a commitment—captured in the capacity contract—based on how much of the demand plan can be met with capacity.
Data Structure
An ecosystem-wide data structure for all types of resources, including AI accelerator resources, was put in place to help with uniformity at scale—the abstraction of accelerators behind a data structure allows for flexibility in specifying unique or specialized requirements for AI training, and ensures there are fewer changes needed across the system to support AI-training capacity management. For example, if Nvidia were to release a new accelerator, the data structure would be able to capture this update without a big reformat to the system data models.
The following two data structures for example, were introduced:
1. AI Accelerator Resources
This is MCP’s data structure for AI accelerator resources. It captures information for AI accelerators, including Max Gang Size—the maximum number of accelerators that can be allocated together to support large training jobs. This ensures that the required resources are available to run the job efficiently. Other constraints such as memory requirements, network topology, or other hardware-specific details are also captured in this data structure.
2. AI Training Product Demand Group
This is a higher-level construct to capture AI training-related demand from products. It captures demand on both training-resource type and transitive dependencies:
- Training-resource type: specifies the type of accelerator required for training
- Transitive dependencies: includes supporting services required for training, such as data storage or preprocessing
Note that supporting services are specified as virtual resource amounts associated with a given quantity of accelerators. These can include the storage capacity needed for training data, a logging system to process events, data preprocessing for training large ML Models, and more.
This data-structure abstraction is widely used in ecosystem tooling (Infra Cloud Portal, ML Hub, etc.) and systems (MAST, Tetris, etc.), requiring fewer changes to support AI training-specific needs. By utilizing a standardized data structure, the MCP framework facilitates easier integration and management of accelerator resources across various tools and systems.
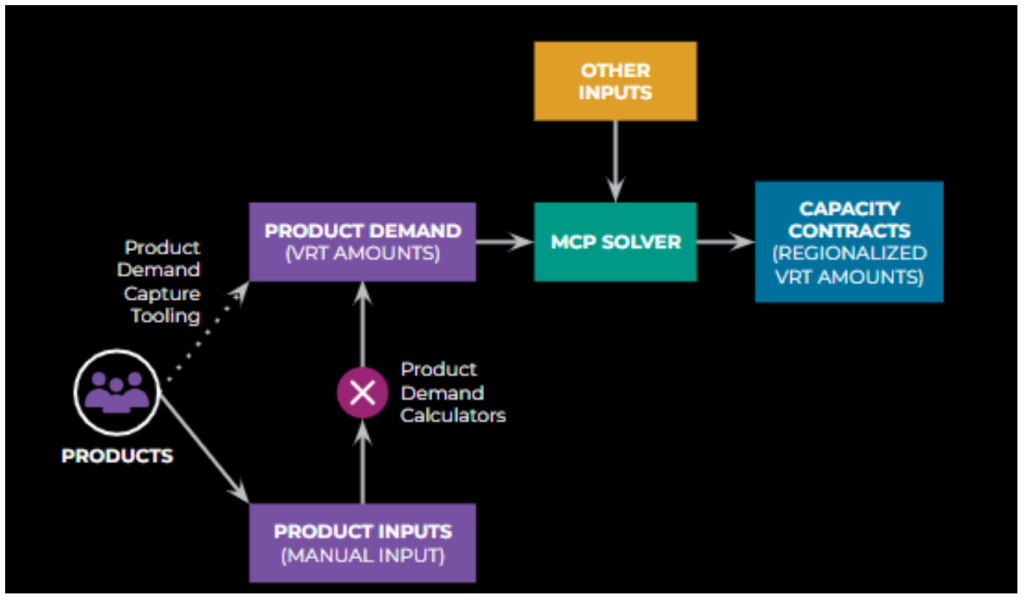
Product Demand Calculators
To increase product control of their resource needs, a number of updates are being made to supporting-service virtual resource types (VRTs). We’ve introduced Product Demand Calculators to simplify the product-demand capture process for AI training (illustrated in Figure 3, below). The high-level idea is that the set of all Product inputs can be consumed by platform-defined calculators to produce virtual resource type amounts as outputs. Platforms can define these inputs and calculators in units that are more familiar to products, and mathematical models are used to combine multiple inputs to produce final VRT values in absolute quantities.
Regionalization Strategy
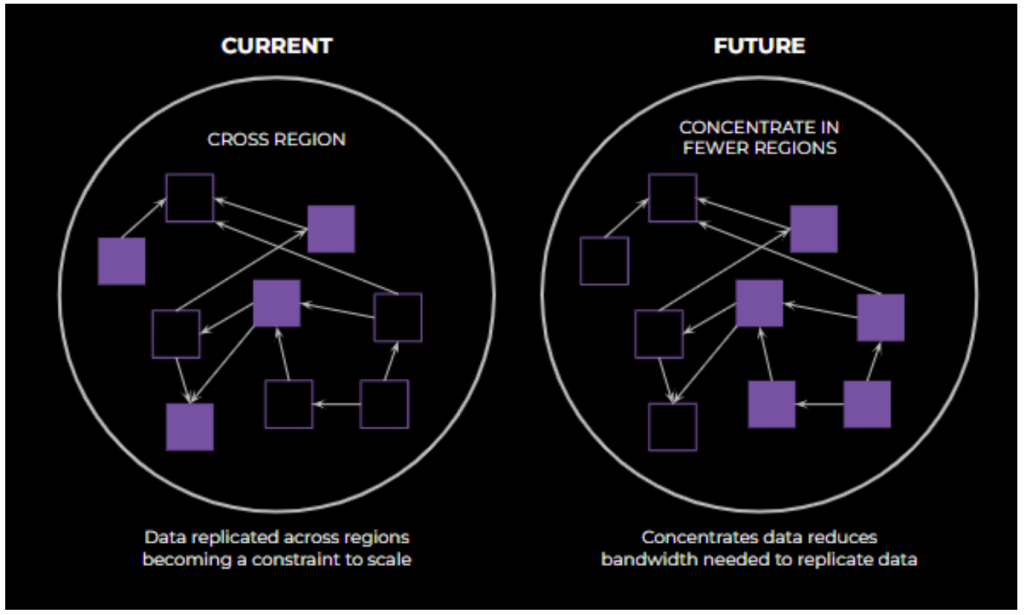
AI training will move from a model of scheduling globally fungible resources to pre-regionalized capacity contracts. This will include AI hardware and supporting services. This enables us to optimize regional placement of accelerators, supporting services, and data in order to minimize costs. This will be done within the constraints of available data center space and power as well as cross-region, backbone-network capacity and hardware. Note that while most product-facing workflows will continue to be global in scope, regionalized capacity contracts will most significantly impact infra-facing components and systems.
To optimize regional placement of the accelerator, the concept of regionalization entity (RE) was introduced and associated with the demand provided by products. RE is used to determine the most suitable region for placing the accelerator, based on factors such as data locality, network latency, and resource availability.
See our paper on Flux for more information.
Resource Management
Infra Cloud Portal will enable Products to understand and control their training capacity (for accelerators and supporting services) via capacity contracts and operational quota in what we refer to as a budget hierarchy. The hierarchy defines how resources are managed and allocated per product.
Machine Learning Hub (ML Hub) will operate on the same hierarchy, enabling Products to understand and control aspects of training workloads that are beyond the scope of capacity; for example, workload runtime inspection and debugging, job priority management, and data management.
Resource Accounting
Infra Cloud Portal will also be the interface to consume resource accounting insights. Attribution, usage, and cost data will be provided at the granularity of budget nodes and model types, based on transitive attribution of supporting services to capacity contracts.
User Experience
We expect product-demand capture for training to be complex, given the considerable number of inputs required due to the heterogeneity of AI hardware, the unbundled model of supporting services, and the need to input quarterly product demand for five years. As a result, we will build out first-class tooling to simplify, reduce, and validate inputs. That tooling will include:
- Infra Cloud Portal: provides unified tooling across the capacity-management space. It is where Products, Platforms, and Infra will go to buy, sell, exchange, replace, and view their capacity.
- Product Demand Capture User Experience (Demand Collection): ensures AI hardware orders are placed within the constraints of available hardware, financial limits, and available data center space and power. We built validations into our tooling to ensure the above.
- Product Demand Calculators: are defined by platforms to output resources.
- Machine Learning Hub (ML Hub): has been the main interface for Machine Learning engineers to interact with their AI training workloads. MLHub provides the functionalities for users to inspect job state and resource consumptions, and to promote or demote certain jobs in the job queue.
Solvers and Runtime Components
We leverage a three-layer approach with our solver and runtime components, where each layer is responsible for solving a particular planning horizon: physical-capacity planning (horizon: days to months), data-placement planning (horizon: hours to days) and real-time workload placement (horizon: minutes to hours).
- Capacity Placement Solver (MCP Solver): Regionalizes AI training capacity and provides capacity contracts.
- Data Placement Solver (Tetris): Produces an optimal data placement plan to colocate AI Training Storage data and supporting services categories with the accelerators for the training demand. It must honor the global limits of per-product capacity contracts and will follow regionalized amounts for AI Training Storage data placement while permitting in-region burstiness.
- Job Placement Solver (MAST): MAST’s real-time job placement components run in real time, responding to jobs in queue in order to minimize scheduling time, meet the model freshness/iteration requirements, and minimize job under-quota wait time. MAST will receive regionalized capacity contracts for each product, which should be respected by the scheduling and ranking decisions. To make real-time decisions for job placement and to finalize scribe category placement:
- MAST determines the ordering of all jobs based on priority and global usage/quota.
- MAST places jobs into regions based on capacity contracts and availability.
The following diagram demonstrates how inputs and signals flow between each layer of solvers from training-capacity regionalization to dataset placement and to real-time job placement.

AI training strategy in action: Threads
Now that we understand the key foundational elements built by the Infra Capacity team to enable AI training and capacity-planning paradigms, let’s look at how those elements could be used by a customer such as Threads.
Step #1: Submit a plan:
Threads as a customer comes into Infra Cloud Portal with the intent of getting capacity to train their ML models when the demand cycle opens. To input their demand, Threads has to tell us which and how many accelerators they need, for how long, and with what supporting services. Our tooling allows the user to pick a set of defaults—if they know what accelerator they want. Most customers will just pick the defaults and go with them. Power users can, however, manipulate the specific supporting services they need or the regional performance requirements. Once the input has been decided, we lock in the plan and submit it for leadership approval.
Step #2: Capacity contracts, ordering, and fulfillment:
Once approved, this plan becomes a capacity contract for Threads—this is the Infra promise to Threads. After this comes the ordering and setup process for new racks. Once the racks land and they are brought up in the fleet, we know how much Threads has asked for. We bundle the accelerator with the required supporting service and co-locate it in a specific region with the help of our solvers.
Step #3: Using this new capacity to train models:
ML engineers working on training models for Threads can now use a heterogeneous set of GPUs and required services to train these models without having to understand the complexity of data placement and scheduling jobs. When an ML engineer runs a training job, they have to choose where to bill this job-run to. Since Resource Accounting and Resource Management systems are built into the capacity-planning process and AI training strategy, we know how to account for usage on these GPUs. Additionally, since capacity planning is built into the training strategy, we are able to train models more efficiently by co-locating services and accelerators as required by our customers.
This is how Infra teams like us deliver on the promises made to products like Threads.
Takeaways
As you have seen throughout this blog post, Meta does things differently. Since we are much closer to our customers and understand their needs better than any public cloud provider could, we run a much leaner cloud operation and ensure we can efficiently use the most expensive hardware, thereby enabling significant growth at scale. Additionally, Meta Capacity Planning, which started as a new paradigm due to post-pandemic capacity crunch, has now become our new working model. It helps leadership make ROI-based decisions, it helps product teams better plan their releases—with guaranteed capacity—and it helps platforms improve their solutions without dealing with individual customers.
It’s an exciting time to be a project manager in the Infra Capacity team. If you are looking for an opportunity to work in an area that has impact at Meta’s enormous scale, please reach out!

