






We will host a talk about our work on Optimizing video storage via Semantic Replication during our virtual Systems @Scale event at 11am PT on Wednesday, March 3rd, followed by a live Q&A session. Please submit any questions you may have to systemsatscale@fb.com before the event.
Managing video at large-scale requires building storage systems that can handle exabytes of data. Content uploaded to Facebook is stored into a storage system called Everstore, which specializes in efficiently storing Binary Large OBjects (BLOBs). Majority of the bytes stored are video data, which continues to increase at a rapid rate. The number of videos uploaded to Facebook has increased every year, with the past year recording the largest increase. Improved cameras, cheaper compute costs, better network speed and the use of higher quality video formats have all led to an increase in average video size.
To keep apace with this growth in video data, we need to reduce the amount of storage space required for each video, with minimal degradation in user experience. Today, we’ll describe a new technique we developed called semantic replication that enables saving over 30% of our video storage by reducing the number of copies we need to keep.
What’s special about videos?
First, let’s consider what’s different about videos that might enable more efficient storage:
- Videos are typically larger in size than other content types (ranging from a few megabytes to gigabytes).
- Content can be uploaded over a period of time. Supporting this requires ability to read data as it is being written (streaming writes & reads).
- For playback, videos often require random access to byte ranges.
- Typically when videos get uploaded to Facebook, they are re-encoded into many different resolutions and codecs (at upload or delivery time) to better support various players on different platforms.
- Videos have temporal affinity: most playbacks of most videos occur during the first few days of their upload. Beyond that period, the chance that someone views the video reduces exponentially with time.
Typical video storage layout
As discussed, multiple encodings can get generated for each video. Each such encoding can be large in size (depending on encoding parameters used and video length) and get split into a number of smaller chunks while encoding. To abstract away how chunks are determined, how and where they are stored, we use the OIL abstraction layer. This internally stores these chunks as independent BLOBs from a storage system point of view. To stitch together those chunks and serve the encoding, OIL stores additional metadata that maps the encoding to individual chunks & offsets. This approach helps us store sub-parts of the encoded file while being uploaded/processed. It also provides a close approximation of streaming writes, thus reducing the amount of data we are forced to buffer in memory.
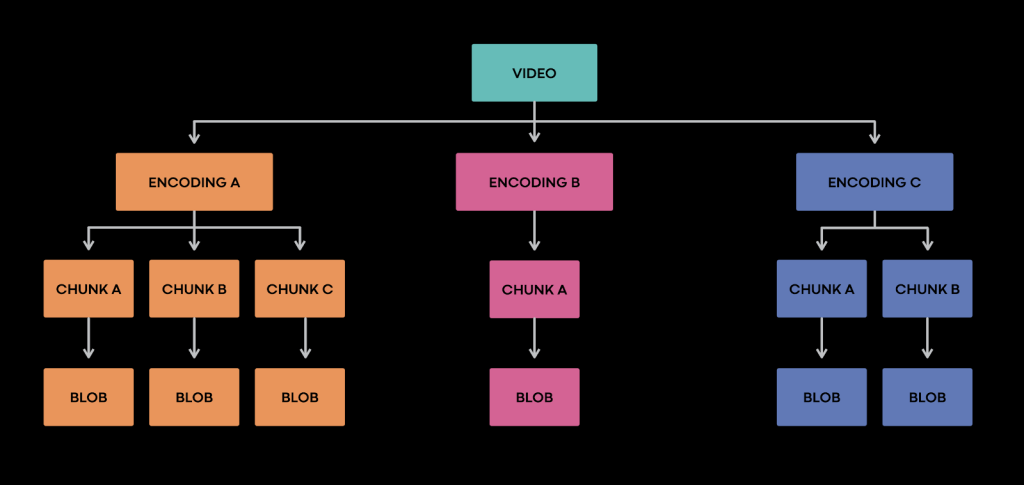
Semantic replication
The key idea of semantic replication: although video encodings are split and stored as distinct objects from the perspective of our storage system, they are logically equivalent since they are just different resolutions of the same video. Any of these encodings can be served to the user and will be viewed as a playback of the expected video. That is, a human describing these video encodings would use the same words and talk about the same objects and actions, and derive the same meaning or semantics. They would be able to distinguish between different resolutions though. We’ll call such distinct objects that are simply a different representation of the same logical object semantic replicas. Just as placing different bitwise copies (physical replicas) of a BLOB into different failure domains increases availability of the BLOB, placing distinct semantic replicas in distinct failure domains increases overall availability of a video, assuming that each semantic replica can be offered as an alternative for the other.
Having more semantic replicas means that instead of needing 2 physical replicas for each encoding in order to ensure disaster tolerance, we can have only one physical replica for each encoding so long as we put each physical replica in different failure domains. If one of the encodings’ replicas are unavailable, we can just serve one of the other encodings. Doing so, potentially saves us 50% of our storage!
Sounds too good to be true, right? Two potential catches we need to be careful about:
- Different encodings have different resolution so substituting a lower quality encoding can adversely affect the user experience.
- Availability of individual physical replicas at Facebook is an order of magnitude lower than the replica set, due to region unavailability. Single region downtime is not limited to disasters because we actually simulate disasters on a regular basis for testing. Painful experience has taught us that if we do not do this, when a real disaster comes, our systems may not work correctly.
Combined, these mean that the simple strategy of reducing physical replicas per encoding will incur a substantial decrease in average video quality of videos shown to users. We find this unacceptable in practice so we need some way to decrease the amount of experienced video quality loss.
Restricting semantic replication to cold videos
As described earlier, most views for videos occur close to upload time. After that, they rarely get watched again and are considered cold. Cold videos also constitute the majority of storage space used. These factors make such videos ideal candidates to be stored with reduced physical replication and save large amounts of storage space with minimal impact to the experience.
To classify videos as cold, we built a video lifecycle management system that tracks when videos get watched, how many views they get, etc. Since a video contains many encodings (semantic replicas), this system also manages what to retain when a video becomes cold. It applies policies to trigger removal of replicas that provide little value and to modify replication on the ones we want to retain. Conversely, if the video exceeds a threshold for the number of views when cold, the system triggers a replica increase and regenerates other encodings as needed.
The policy to apply on cold videos gets chosen based on the tradeoff between storage space and availability. We experimented with two configurations:
- In one configuration, we retained 2 semantic replicas: a low quality encoding (SD) with two physical replicas and a high quality encoding (HD) with one physical replica. We selected this configuration given the HD encodings’ much larger size (4x) over the SD encodings, and as some of our players cannot handle switching encodings midstride. Here, we achieved higher availability for the video (three replicas, over two) at the cost of some extra storage space (~10% as calculated below):

- In practice, due to the use of Semantic Replication, we see ~35% storage growth rate reduction per video, with 1 physical replica of HD encoding and 2 physical replicas of SD encoding.
- In another configuration, we retain a HD and an SD encoding with one physical replica of each, instead of storing just an HD encoding with 2 physical replicas. This helps us save more storage space: in this case, the size of HD encoding is 3x the size of SD encoding, so we will store (1 * 3x) + (1 * 1x) bytes instead of (2 * 3x) bytes; estimated savings of ~33%. In practice, we have seen ~30% reduction in storage per video.
What encodings get retained and how players react to unavailability also affects the retention policy for cold videos. Our popular video encoding formats can broadly be classified as following:
- DASH: This most common format lets video players switch to using another encoding mid-way during playback. For these, the availability of encodings is additive since encodings are semantically equivalent; that is, if we retain two DASH encodings with one replica each and a replica has 98% availability, the availability of the whole video improves: 1 – (1 – 0.98)^2 = 0.9996
- Progressive download: This cannot switch encodings during playback. In such cases, playback fails if the chosen encoding becomes unavailable and needs to be retried to recover. Here, the availability of the video matches availability of one encoding (0.98).
Video storage requirements
From above, we can see that storage for video using semantic replication has very different constraints compared to other content types. Overall, we can summarize the set of requirements as follows:
- As much as possible, ensure that BLOBs (chunks) belonging to the same semantic replica reside in the same failure domain. This reduces the variance in latencies and playback failures while increasing availability. Example: If we assume availability of a failure domain is 0.99 and we randomly distributed chunks across N failure domains, the probability that the semantic replica is fully readable is (0.99)^N. As N grows, availability drops exponentially. Conversely, the probability of failure would be up to 1-(0.99)^N. This doesn’t sound too bad until one realizes that this would result in a globally correlated loss — all videos would have that probability of failure at the same time. Not the kind of failure one wants to have while making viewers happy.
- Ensure that BLOBs belonging to distinct semantic replicas reside in different failure domains as much as possible. This provides failure isolation and better availability.
- Provide the ability to control the physical replication factor for individual BLOBs. This gives the application control over availability.
Rebalancing where data is stored
If we never had to move data after initially writing it, we could just simply write each new encoding into a different failure domain (region) than any of the already written encodings for that video. We’d do so weighting by the remaining space in each region. Unfortunately, we continuously need to move data around as storage capacity shifts: New data centers come online. Old servers get decommissioned. New racks of storage arrive in existing data centers.
Rebalancing in the presence of semantic replication introduces new challenges. The reason for this is the constraint that semantic replicas of the same video are placed in different failure domains. Additionally, to keep availability high, we must also maintain the constraint that all the chunks of a single encoding get placed in the same failure domain. In other words, we want to ensure (as much as possible) that the loss of one failure domain takes out at most one video encoding. We consider a video encoding down if any of its chunks is unavailable.
How we achieved rebalancing without semantic replication
For efficiency, Everstore groups the objects (BLOBs) it receives for storage into logical volumes (lvols). This logical grouping of data can be considered an Everstore shard, depicted in the figure below.

For each of these lvols, two corresponding physical volumes (pvols) store actual copies of the data, and provide two physical replicas for each BLOB in the associated logical volume. The physical mapping in the picture below shows how each lvol contains two pvols residing in two distinct regions, resulting in a geo-replicated system.
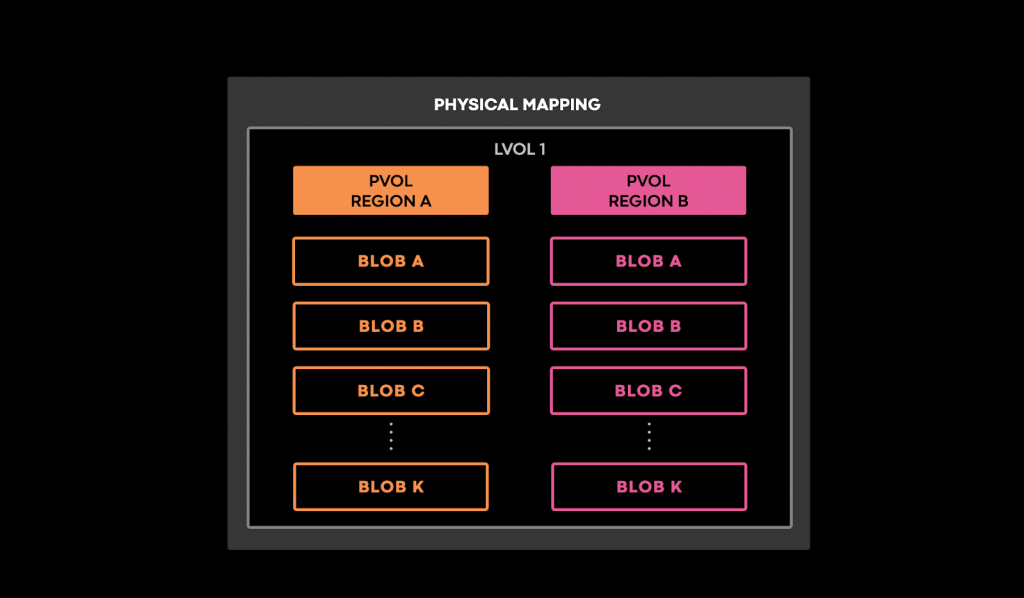
A constraint solver computes well-balanced placements of physical volumes that obey various constraints. (e.g., physical volumes belonging to the same logical volume need to reside in different regions and at least two of them must exist). A migration system moves physical volumes between regions according to the latest computed placement.
Extending this system to handle semantic replication is hardly straightforward. It can only manage constraints within logical volumes, while video encoding (chunks) are scattered across logical volumes.
Rebalancing with semantic replication
In the first attempt to achieve Semantic Replication we build a very flexible solution, called placement policy. This would require the application to specify for each uploaded BLOB one to four regions in which to have physical replicas. Moreover, later on the application would be able to update the list of regions for a BLOB, which would be materialized by a background syncing system within an SLA.
In order to achieve Semantic Replication, the video processing pipeline would attribute to each encoding a pair of regions where the corresponding chunks would be stored. This would ensure that all the chunks that form an encoding would be collocated and different encodings would be stored in separate failure domains. Later on, the pipelines responsible for evaluating the video access pattern would update the list of regions from 2 to 1 for the encodings belonging to new cold videos. In case a video would transition from cold to hot the pipelines would apply the reverse process, i.e., update the list of regions from 1 to 2.
This involved creating a new class of logical volumes called placement policy volumes. Different from classic lvols, they have a physical volume in each region rather than in just two regions as it can be seen in the figure below:
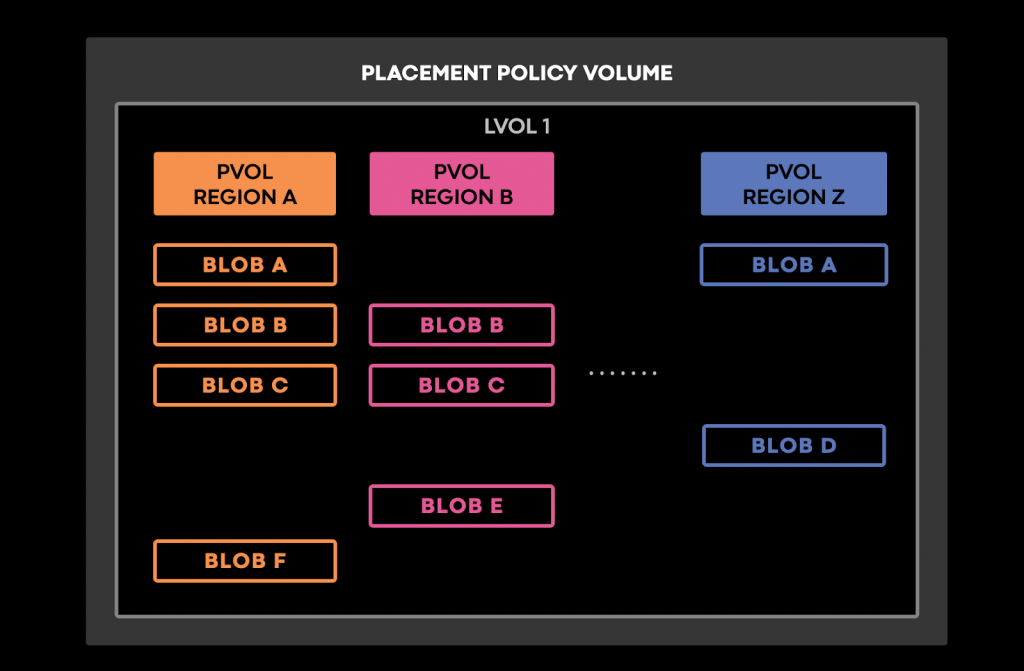
Per-BLOB metadata specifies in which regions that BLOB should have copies. We modified the background synchronization service used for repairing BLOBs with incorrect physical replicas to: copy BLOBs to regions in which they were supposed to exist, but were not yet present in and remove BLOBs from regions in which they were no longer supposed to reside.
We took this system to production. The initial feedback was good, thanks to the system’s simplicity and high flexibility it provided to product teams. However, after we reached a few million pvols, many problems surfaced. The common root cause involved the high overhead incurred by all those extra pvols. With over ten regions, each lvol went from having 2 pvols to 10+ pvols.
As an example, memory utilization in the smallest region increased significantly. Even though the smallest region is an order of magnitude smaller than the largest region, it still had the same number of pvols. This was due to placement policy volumes requiring a pvol in every region. Every server therefore had to handle more pvols.
We detected another high overhead with the I/O spent on metadata reading. Our background syncing engine generated these metadata reads, performing them in a quadratic manner. For every sync of a pvol performed, it fetched the metadata from all peer pvols. Thus, performing a round of syncing all the pvols of a lvol skyrocketed from 4 metadata reads to 100+.
The new system ran in production for more than 6 months with no rebalancing. Enhancing or creating a new video processing pipeline to perform data rebalancing was evaluated as introducing too much complexity in the application layer. In this system, rebalancing needed to be performed at the BLOB level rather than the volume level. The only means to move data around would be to perform a metadata update on individual BLOBs. Thus the problem explodes from managing millions of pvols . . . to managing trillions of BLOBs.
Revising placement policy
Our insightful experience with the first version helped us better understand our system and identify flawed assumptions.We’ve begun working on a replacement system incorporating the ideas that proved to work well while avoiding some pitfalls.
Given the high overheads discovered in the initial approach for the placement policy volumes, we decided to move back to the classic approach of utilizing only two pvols. Using classic volumes will enable us to have a linearly scalable solution as proved by the current system.
Another direction we decided to steer clear of involved doing rebalancing at the BLOB level. As described above, this would require trillions of metadata updates rather than handling millions of pvols. Moreover, doing balancing across trillions of objects would require building a new solution as the current system would not scale.
Generalizing logical volumes
Based on these realizations, we came up with a new abstraction, a mega volume. A collection of lvols that have their pvols placed in the same set of regions at all times and have a max logical size. These properties make a mega volume behave exactly as a logical volume, but at a larger scale.

A mega volume is a useful container for storing chunked objects, such as video encodings. By writing all the chunks of an encoding to the same mega volume (as illustrated below), they would end up in lvols that have two pvols in the same regions. This would result in all chunks residing in the same failure domains at all times. Moreover, by removing the need to write all the chunks into a single lvol, the write reliability would not be impacted by the unavailability of a single lvol.
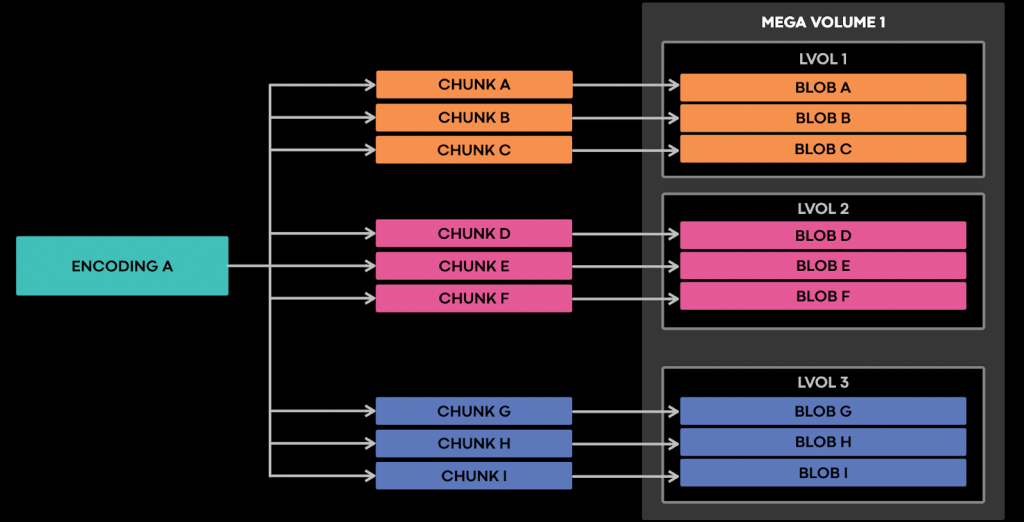
By capping the logical max size of a mega volume in the order of petabytes, it becomes a shard that can be utilized for doing data rebalancing across regions for large amounts of data needing to be collocated. The mega volume can be seen as an improved lvol with higher capacity & higher write reliability. Another benefit of this new concept: we can apply similar rebalancing algorithms as they are just larger shards than lvols. Thus existing infrastructure can be leveraged.
Generalizing physical volumes
By introducing the concept of mega volumes we have achieved the means of performing chunk collocation and doing rebalancing while maintaining data collocation. However, we have not managed yet to ensure that a video’s encodings do not end up in the same region at any point in time.
A natural thought would be to write distinct encodings of a video to different Mega Volumes that pairwise possess at least one distinct region. However, this generates multiple problems. Firstly, no guarantee exists that such a set of Mega Volumes can be found at the write time. Secondly, even if such a set can be found at the write time, we can’t assure that after rebalancing the Mega Volumes will not end up in the same set of regions.
Another possible problem is what happens when the replication factor for an encoding gets reduced from 2 to 1. If we perform this operation on two of a video’s encodings that live in the common region of the mega volumes storing them then in case of region down scenario both of them would get lost.
All these scenarios amplify the need of constraints in between mega volumes. Not having any guarantees endless ways things can go wrong. For this reason we decided to create N-tuples of mega volumes residing at all times in distinct regions and call each such grouping a semantic volume. The following diagram depicts an example of semantic volumes consisting of 3-tuples:

How does this grouping of mega volumes help us? Each encoding of a video could be uploaded to a distinct mega volume belonging to the same semantic volume as shown in the diagram below. Such a distribution of encodings would help us maintain the encodings in distinct regions at all times despite any rebalancing, thanks to constraints imposed by the semantic volume.
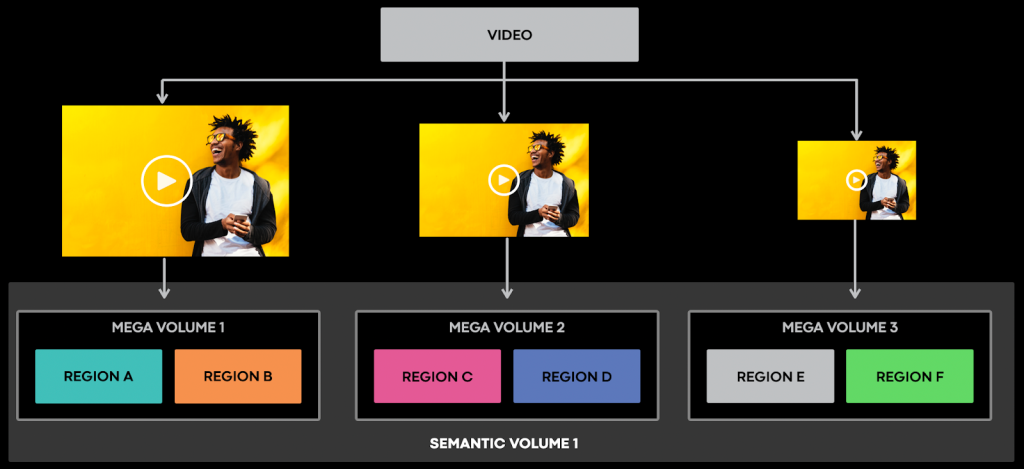
The new setup is linearly scalable as it relies on the same primitives that we have been utilizing successfully so far, lvols & pvols. The novelty of this design is the logical grouping of data and enforcing different constraints on tuples of such groups. On one hand, mega volumes can be visualized as enhanced lvols that enable collocation of data despite rebalancing. On the other hand, we can also view mega volumes as generalized pvols for the semantic volumes. As classic pvols, they can be placed anywhere, thus allowing us to make full use of the available capacity. However, they have to live in distinct regions at all times.
As with any system trade offs arise that must be performed. We have improved on the scalability axis. However we lost the ability of controlling the data placement at a granular level. This is an acceptable trade off as all the requirements for Semantic Replication are met.
Controlling the physical replication factor for encodings
Having the ability to control the replication factor for encodings is the last requirement for achieving the storage savings. Updating from 1 to 2 replicas is a trivial operation as it translates to ensuring that the BLOBs are present in both pvols. However, reducing the replication factor from 2 to 1 is not a trivial operation. Let’s explore why.
Firstly, an encoding can and is likely formed out of many chunks. When reducing its replication factor from 2 to 1, we want to avoid splitting it across two failure domains. We do this by having part of the chunks in one region and the rest in the other region of the mega volume storing the encoding. Additionally, the spread of those chunks across multiple logical volumes makes the problem trickier.
The chunks are still independent BLOBs with random ids from the storage system point of view. This rules out the popular approach of hashing the BLOB id and using that to determine the region to which we downgrade the data. Such an approach would lead to the encoding having part of the chunks in one region, and part in the other one. This would mean that the encoding would be split across two failure domains, an undesirable outcome. As the chunks may get spread across multiple volumes, a similar reasoning would also eliminate lvid based hashing.
As highlighted above we need a way of connecting all the chunks belonging to an encoding. One possible solution would be taking a hint from the video team in the API call responsible for marking the data for replication factor update. This hint could be either an explicit choice between first and second region. Or we could use it to deterministically match it to one of the two regions. However, either of the choices contain the caveat that the video team should provide the same hint for each chunk. Otherwise, chunks may end up again in distinct regions.
However, a common property of all the chunks is that they are written to the same mega volume. Thus if we were to decide at a mega volume level in which region to store the single copy, this would simplify the process, the API exposed to the Video team and reduce metadata required to be stored for each BLOB.
For the above reasons, we decided to define a primary and secondary region for each mega volume. By always storing the BLOBs with a replication factor of 1 in the primary region, the process becomes easy to reason about, be deterministic and keeps the overhead of certain operations very low (e.g., routing reads for single copy BLOB would be as trivial as going to the primary region, materializing replication factor downgrade asynchronously would be as simple as checking if the BLOB is present in the primary region & deleting it from secondary)
Future work and opportunities
So far, we have shipped the first iteration of semantic replication and applied it to newly uploaded videos. This has resulted in reducing the physical growth rate. Currently, we are in the process of building and testing the second design to solve the scalability issues discussed. In addition, we want to migrate all the videos uploaded before this effort started to semantic replication which will yield a considerable amount of storage space.
Although we only discussed video today, applying semantic replication to other media types with multiple resolutions like photos should be possible. To summarize, Semantic Replication is a powerful idea leveraging observations about the data being stored instead of just treating them as bits. This lets us optimize on how data is stored, making the storage system more scalable.

