






In today’s rapidly evolving technological landscape, virtual communication has become the new norm. The emergence of Virtual Reality (VR) and Augmented Reality (AR) has revolutionized the way users meet and gather. With the widespread adoption of video conferencing (VC) software, remote communication has become easier and more accessible than ever before.
AR and VR environments offer a more immersive experience, providing a sense of physical presence in a virtual world. This leads to a more engaging and meaningful experience, enabling better collaboration and ideation. Moreover, AR/VR environments provide a greater level of control over the setting, allowing users to customize their surroundings to suit their needs.
In VR, going to movies with friends, playing games, huddling over design specs, collaborating over whiteboards while being hundreds of miles apart is a real possibility. Being present with one another has never been so easy.
But how do we make being present in this way happen?
Human Representation
The most important aspect of being present in virtual worlds is human representation. In traditional calling scenarios, this is done by two-dimensional (2D) video. But 2D video doesn’t apply directly to the Metaverse: first, because it isn’t always possible to capture a video of the user’s face while it is obstructed by a headset, and second, because we need a deeper understanding of the user’s movements in three dimensions so they can interact with their virtual surroundings.
We’ve been working on a spectrum of human representations, ranging from cartoony avatars to photorealistic ones. We can broadly divide this into three forms:
- Stylized Avatars
- Photorealistic Avatars
- Volumetric Video
For each of these representations, we expect the user’s device to be able to capture certain expression data. This can be done via inward-facing cameras on headsets, eye tracking, lip syncing based on mic audio, and so on.
Stylized Avatars
These are relatively low-fidelity, cartoon-like avatars. All participants share their avatar assets when the real-time call (RTC) session begins. Skeletal movements are streamed in real time, and the avatar is recreated on the receiver side.
Photorealistic Avatars
These very-high-fidelity avatars are almost indistinguishable from reality. The system creates a specialized codec for each participant in the call. Assets, textures, and codecs are shared before the RTC sessions starts. Neural Networks (VADs) are used to compress facial-expressions data into neutral embeddings in real time and send them over the network. Using state-of-the-art ML techniques, we are able to have 30 FPS photorealistic avatars consuming as little as 30 KBs.
Volumetric Video

These are the highest-fidelity avatars, through which a person is reflected exactly as they appear. A three-dimensional capture of the person is sent over the network as a combination of RGB and depth. While standard 2D codecs can be used for the RGB component, special codecs need to be developed to compress depth. The RGB and depth components also need to be perfectly synced and stitched on the receiver’s end to render a scene that accurately represents the person in the virtual environment. Achieving all of these components together is essential for creating a truly immersive and lifelike virtual experience. This approach is bandwidth heavy and requires a lot of post-processing to get rid of compression artifacts.
Depending on device constraints, network quality, and user activity, we can choose which form of human representation to use. In a game-like setting where non-RTC activity consumes system resources and/or there is a large group of participants, we may choose stylized avatars. They are computationally the least expensive and don’t feel out of place in a casual activity session. In work settings, however, where participants are collaborating over a whiteboard, we might want to use photorealistic avatars.
World State
We’ve discussed how we represent humans in virtual spaces. Now we need to give users the tools and capabilities to interact with both their surroundings and remote participants. That’s where real-time world state comes into play.

Collaborative virtual environments require a robust system for managing objects shared across participants. A networked, shared-object stack can be reasoned about in the form of the following layers:
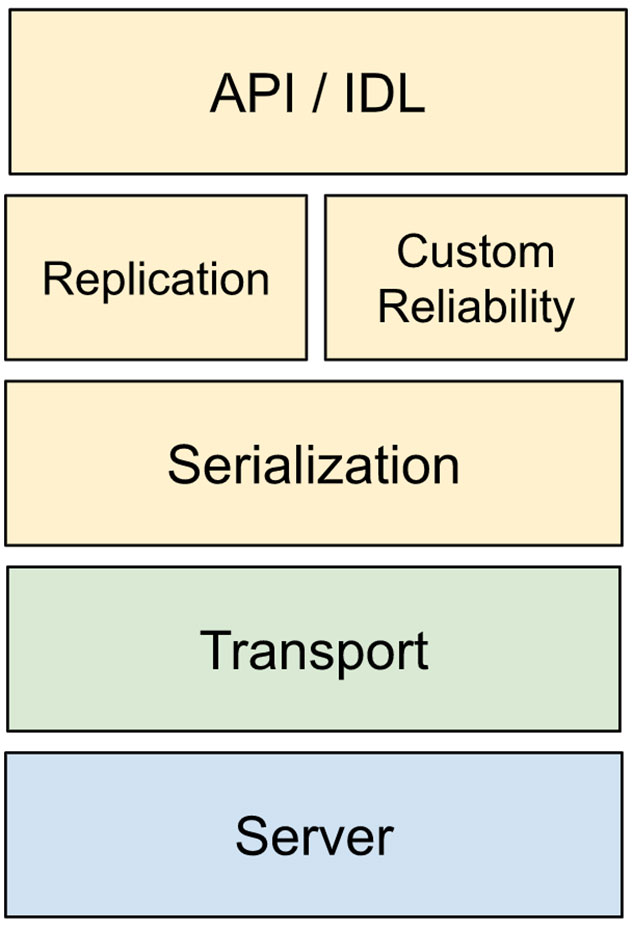
- API / IDL: An ergonomic way for developers to define/modify/read the state of their objects.
- Replication: Logic to replicate objects across participants, using low-level transport APIs.
- Custom Reliability: Logic to achieve custom reliability and sequencing specific for states, to avoid any wasteful retries.
- Serialization: Mechanism to efficiently serialize objects to a wire format in the most compact way possible.
- Transport: Low-level transport APIs to send and receive packets with configurable characteristics such as reliability, latency, congestion control, etc.
- Server: Server-side infrastructure required for selective forwarding or fanout of packets.
To provide the most ergonomic experience to developers, the system should abstract away all the internal complexity of this architecture. We typically want them to work with the mental model of defining a schema for their objects. An object is a collection of fields. Objects can be created, modified, and destroyed throughout a session. The underlying framework is responsible for transmitting these mutations in real time across the network.
As the number of shared objects within a session increases, we need to come up with innovative ways to put a cap on the amount of network bandwidth consumed to synchronize this data. Possible approaches include computing deltas, making effective use of field of view, and using lower FPS with interpolation and extrapolation.
Objects can be modified by multiple participants simultaneously. To resolve conflicting updates, we need to build an ownership framework. Objects fully owned by a participant can be mutated only by that participant (for example, a bat held by an avatar can be mutated only by that object). Ownership for other objects might get transferred throughout a session. Some world objects might not have an owner at all and would be owned by the server.
The network topology of choice can affect trade-offs around privacy, performance, and developer experience:
State-less Server
With this choice, the server doesn’t maintain any state and is responsible only for forwarding packets. One of the clients is chosen to be the primary client and to arbitrate conflicts. The server can change the primary client based on network characteristics. Network issues induced by the primary client can affect all other clients. This model allows end-to-end encryption of user activity.
State-ful Server
Here, the server maintains state and is the source of truth for all shared world objects. While this model can’t support end-to-end encryption, it is easier to identify and debug. It also performs better and is tolerant to participant churn.
Looking into the Future
As we look to the future, we will need to innovate along two axes:
- Realism
- Scale
Realism
Above, we discussed various trade-offs regarding human representation. As devices become smaller (for example, AR glasses or VR headsets) and are expected to last longer and have tighter thermal requirements, working under their constraints will present challenges to pushing the envelope on realistic human representation.
Still, improvements can be achieved by a combination of optimizing machine learning (ML) models that power avatar generation on devices and offloading partial rendering to the cloud. The latter places a tighter bound on acceptable latency (approximately 50 ms), because the rendered content needs to react quickly to the user’s real-time movements, such as head rotation. This can be partially mitigated by doing a layered approach, where the server renders the scene only partially, and the device does the final repositioning and correction of the user’s real-time movements.
Scale
A North Star for RTC experience within the Metaverse would be to power large concert-like events where tens of thousands of people can be present simultaneously and interact in real time. Yet this poses challenges on both the product and technology fronts.
On the product side we need to figure out how to blend asymmetry into these interactions. Having thousands of people all talking to each other simultaneously is definitely not going to work! A more palatable setup might be to have certain key participants play the role of broadcasters, like the singer at a concert, while other participants—the crowd—have a smaller span of influence.
On the technical side, handling tens of thousands of participants requires rethinking traditional server architecture for media forwarding. We need a distributed setup and much more compute power so that we can customize the media received by each individual user to account for the desired level of detail (for example, the muffled ambient noise from participants further away versus the clear audio of people nearby). We also need to push down latency to enable server-side media processing to react in real time to user movements.
Overall, Metaverse’s possibilities for creating presence are endless. And RTC is the fabric that weaves together users’ experiences within it. There are many broad and deep technical challenges to be solved, and there has never been a better time to be an engineer working on RTC.

