





Thousands of services at Meta utilize Configuration Management. Because of this, changing configuration reliably is essential. In this post, I will tell a story spanning several years – describing how my team exponentially grew coverage of a protection mechanism to enable developers to reliably change configuration at scale. This small but ambitious post encompasses a large timeframe – while admittedly compressing some details. I will gloss over some large and important projects we delivered to accomplish this goal. And I won’t have the chance to address the other protection mechanisms we built. That said, I will guide you through a curated 10,000 foot view of the process we undertook to scale this protection mechanism. I’ll also dive into several specifics of challenges we faced and overcame.
Early Days of Config Change Safety
Meet Configerator
Configuration management at Meta comprises many powerful tools, one major platform being Configerator. Engineers can use Configerator to update configs. They can see those updates reflected across our million+ server fleet in a matter of seconds. Due to that featureset, Configerator operates at a very high scale. Over 99% of our thousands of services at Meta leverage Configerator for runtime configuration. Not only that, thousands of employees regularly make configuration changes during their work. This occurs to the degree that, combined with automation, we observe multiple sets of changes per second at peak.
Such a powerful tool also introduces some risk. Just like engineers can roll out a configuration change to toggle a feature in a matter of seconds, we can also make a config change that uncovers a bug in that same timeframe. Due to that risk, safely changing configuration at our scale has become one of Meta’s primary strategies to prevent reliability issues.
Early Days of Config Testing
We’ve established that making config changes reliable and scaling that protection to cover all the use cases we identified is key. So how do we do that? The first step we took entailed giving developers the ability to test their changes. We built a system they could use to manually override their changes on a subset of the target. This allowed them to not only test their changes in a sandboxed environment. It also enabled them to exercise their changes on real workloads to catch bugs perhaps missing in sandboxed environments. Let’s walk through an example of how I would test my change with this functionality:
- I’m making a change to config foo/baz and setting the value of a to 2.
- I expect it to be used by Service A. Instead of making my change on all 12 boxes of Service A, I’ll override my change on a single box, number 3.
- Now I’ll let it bake for some time so box 3 can use it. I’ll then monitor important metrics of Service A coming from box 3 vs. the other boxes.
- After waiting a bit, I find box 3’s metrics looking worse off than the other boxes, probably due to my change. Luckily, my change only regressed 1/12 of the incoming workflows. However, I should remove the override to fix those workflows.
This process took us a step in the right direction. However, its complexity made it tedious and prone to knowledge silos. It required authors to know where their change could trigger a breakage and override the change there. They had to manually monitor the important metrics of the target, and wait for enough signal to deem their change safe. In the absence of sufficient signal, they had to start this testing loop again with a broader target group. This process clearly wouldn’t scale to meet our needs. The obvious next step was to automate it.
Meta has an array of unique services. Many aspects differ – their health definitions, their scale, and their config usage patterns to name a few. Our automation must account for these differences. Such a system needs information about these specifics like we used during our manual testing, such as:
- On what set of machines should we test?
- What percentage of machines should we override?
- How long does the override need to bake for us to gather enough signal?
- What metrics and values signify a healthy target?
A structured test plan we call a Canary Spec provides this information. Our Canary Service can follow one to test a config changeset on a given service. Canary specs reduce many manual test repetitions, busy waiting for signal, and knowledge gaps on which metrics to check. However it still requires developers to know which canary specs to run for their changes and manually start them during their change workflow.
So we solved both challenges. First, we identified which canary spec to run for changes. Determining where to test a config change presents challenges, even with only hundreds of services. This selection can also frequently change. So we asked service owners to give us a list of the names of configs that should run their canary spec. With that information in hand, we created AutoCanary, an addition to the config change experience. It will automatically canary with the following strategy:
- Gather the names of configs being changed, and use the lists provided by service owners to find the canary specs we should run.
- We execute those canary specs in parallel with one another. If every canary signals no regression in the underlying targets, then we allow the change to be rolled out. Otherwise, we block it.
This enhances the AutoCanary enrollment workflow, but services still need to enroll in AutoCanary to gain its protection.
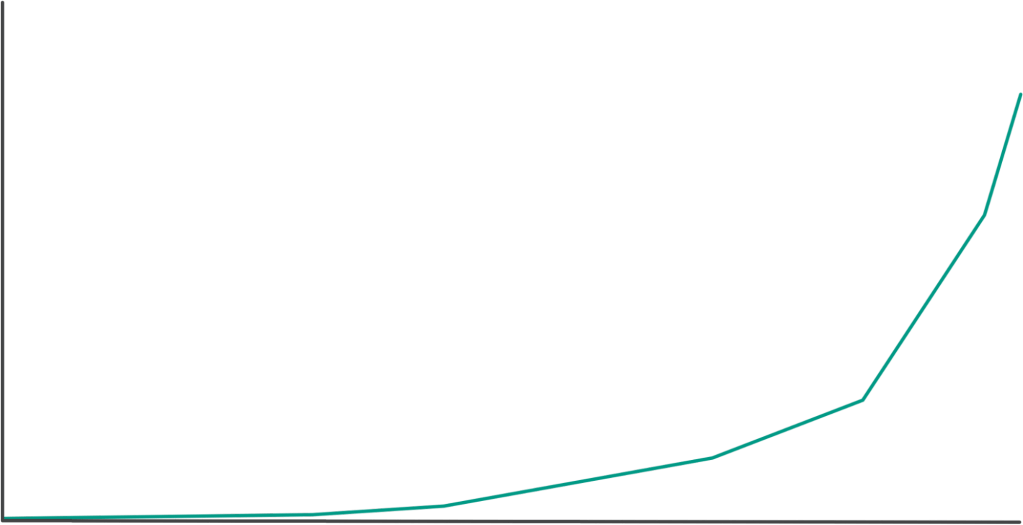
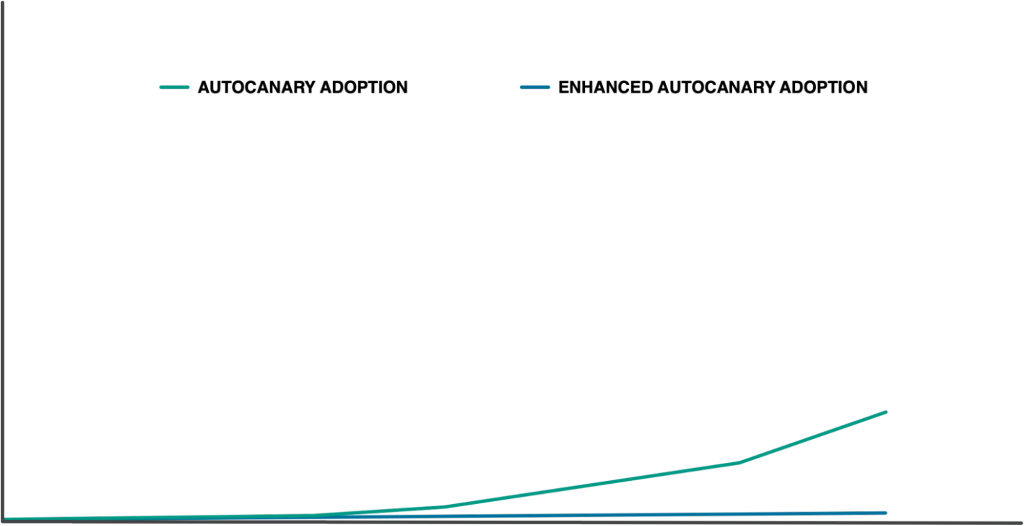
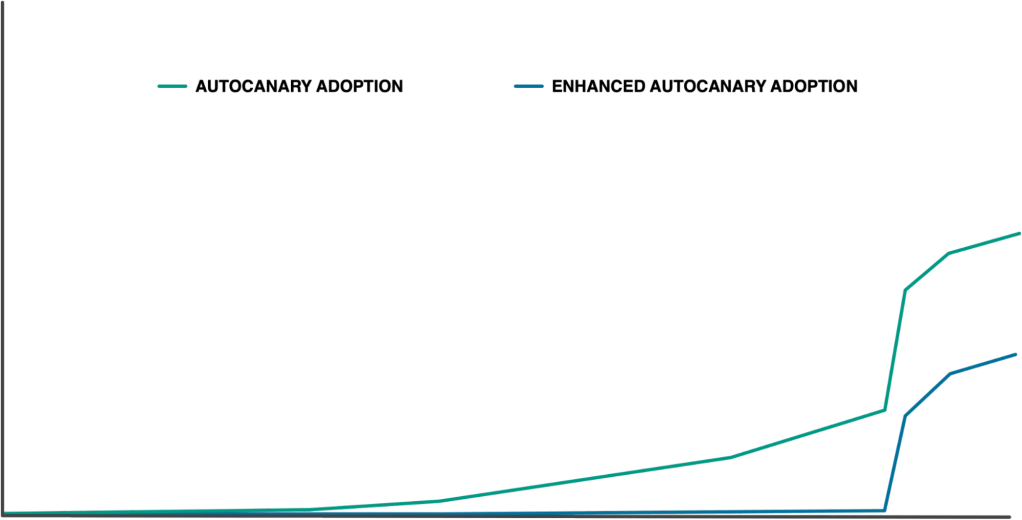
Over the handful of years following AutoCanary’s creation, we made enhancements, but largely kept the enrollment process the same. Services onboarded organically, giving us the AutoCanary adoption depicted below. We focused on scaling up other aspects of Configerator throughout those years. But after further exploration in the change safety space, we returned to check: Could we improve the AutoCanary adoption process and protect more services from unsafe changes?
Ameliorating Larger Issues
This brings us to the next chapter in our story – ameliorating larger scale reliability issues triggered by config changes. So let’s solve the largest pain point of AutoCanary adoption.
Enhance AutoCanary
Our observations revealed the manual process to specify and update the list of config names to test on a spec as the largest blocker. Asking humans to manually find all the config names to test quickly gets complicated, inaccurate, and high maintenance. Services can use libraries which themselves utilize configs. Therefore a library’s config change could trigger a breakage on the service itself. Asking service owners to find each of those configs manually grows complicated and can produce inaccuracies. Due to that behavior and general service evolution, consumption patterns can frequently change for an individual service. Asking humans to keep the list updated becomes high maintenance. If those lists aren’t updated, they become inaccurate. Some power users even began independently working to automate this process for their services due to these challenges, so we decided to scale up this manual process.
How do we do that? Let’s take a step back and run through a thought exercise to depict how we enhanced the process. The image below depicts service’s config consumption patterns.
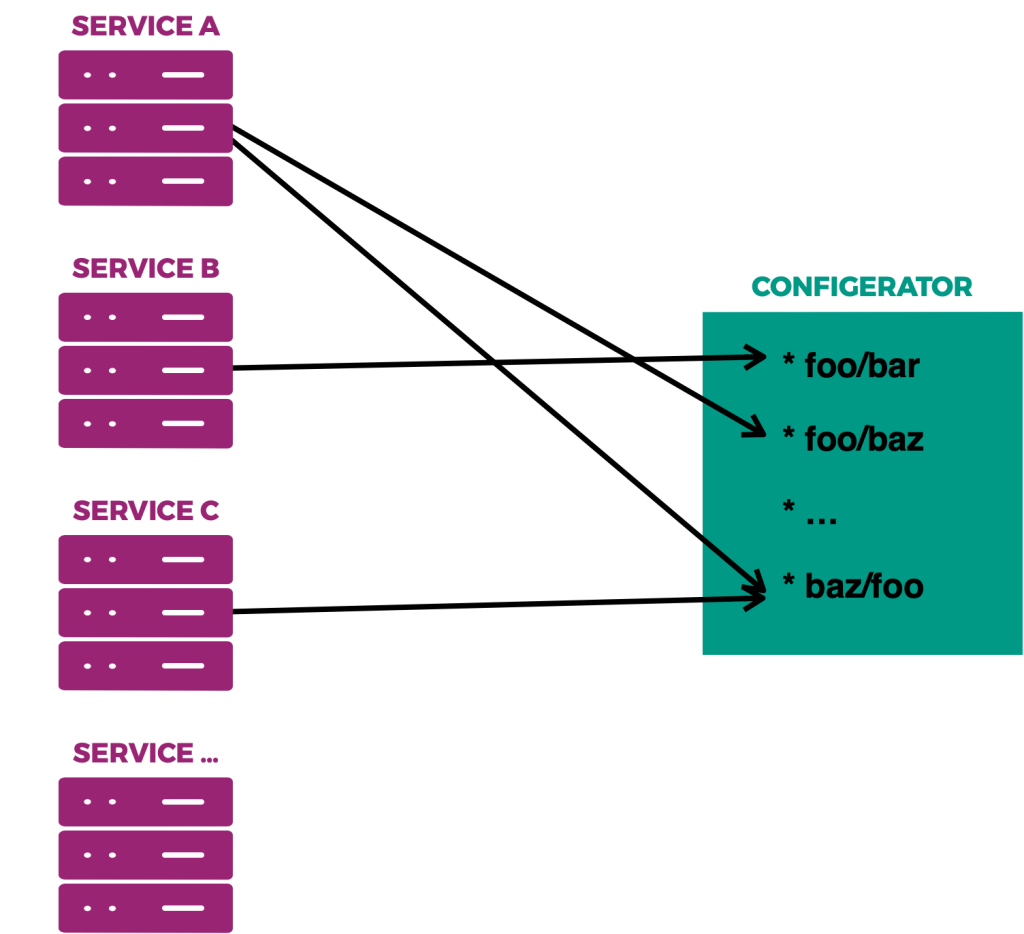
With the illustration as reference, what services run the risk of breaking if baz/foo uncovers a bug? ServiceA and ServiceC. In general, config changes represent a risk to those services that consume them. We enhanced AutoCanary’s enrollment to solve those earlier pain points with config consumption patterns in mind. Let’s simply ask service owners for the name of the service they want us to protect from bad config changes, and the canary spec that tells us how to test configs on their service. We’ll take care of the rest! We evolved AutoCanary to track the config consumption patterns of the millions of servers in our fleet (a scaling challenge in its own right). Now when someone goes to make a change to configs, we:
- Gather the names of the configs being changed.
- Look up the services potentially affected by the change – those consuming the configs.
- Of the services we should test, we obtain the canary specs for those that are enrolled.
- We then run those canary specs in parallel with one another. If every canary passes, we then allow the change to be rolled out. Otherwise it gets blocked.
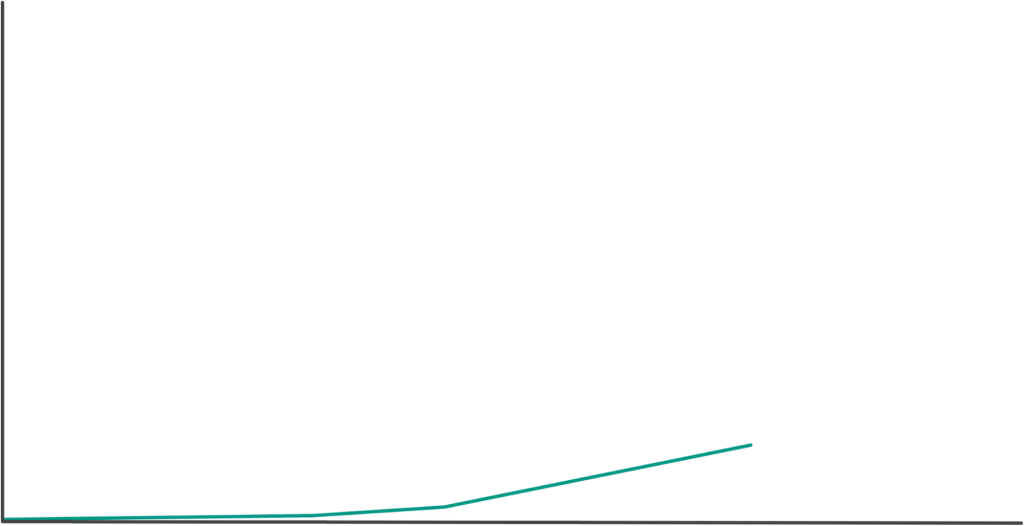
After enhancing AutoCanary, we decided to invest further in our internal infrastructure’s maintainability and reliability so we could move faster. AutoCanary grew organically throughout that time as shown below. As we closed out that aforementioned investment, we pivoted a good chunk of our team back to focus more directly on changing configuration more reliably. The config change workflow already included AutoCanary as a standard ingredient of the config change workflow. This gave us a lever to make config changes more reliable via increased coverage, so we opted to continue our AutoCanary work. We made one minor change. Instead of allowing adoption to happen organically, this time we took matters into our own hands and drove adoption. Now, with thousands of services to onboard, where to start?
Move Fast to Protect Things
We strove to prevent larger issues triggered by config changes. So we focused on adding protection to the subset of services that could trigger a larger issue when broken. Around the time of our work to remove onboarding blockers, we observed larger issues getting triggered by config changes more frequently.
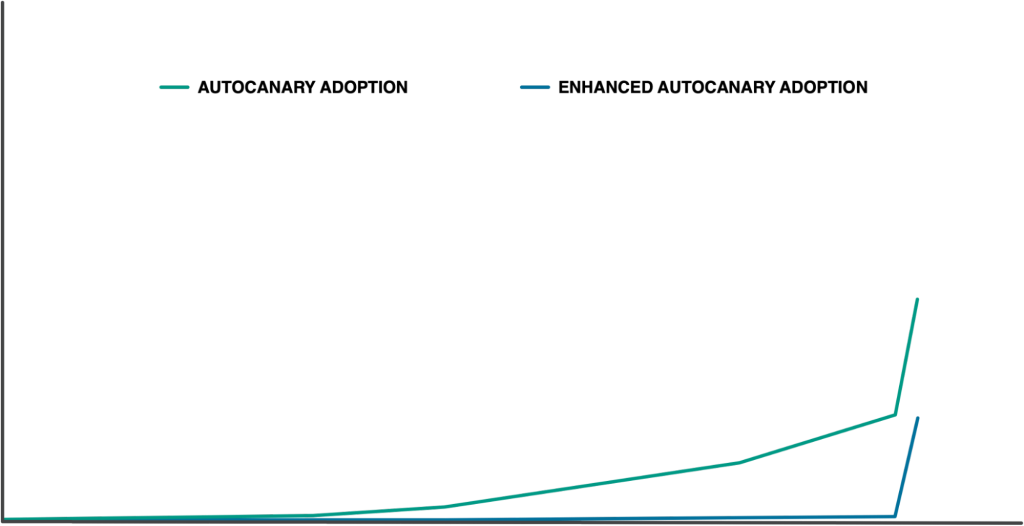
Meta quickly responded to this challenge. We decided to bolster our config change safety with multiple strategies. One of these pertains directly to the area we’ve discussed so far. The subset of services that could potentially trigger a larger issue when broken should be enrolled into AutoCanary. Doing so ensured that these services have a strong mechanism to protect them against breakages triggered by bad config changes. We expedited our AutoCanary adoption plan to accomplish this goal. We scaled AutoCanary and its dependencies to support more growth. We improved our AutoCanary workflows and scaled out our other manual onboarding process – canary spec creation. Specifically, we built tooling to automate canary spec creation. In this way, service owners could simply run the tool with their service name. The resulting tooling would generate a spec and enrollment with required fields filled in. This helped the service owner avoid needing to spend resources learning about each field. They didn’t need to search for all the values or do all the validation of these fields. This default spec could be tuned to improve its signal. It ensured a service had some protection against breakages triggered by bad config changes.
With tooling in hand, and collaboration across our org, we accomplished our goals in a short time period. We boosted AutoCanary coverage 2x. Since our AutoCanary adoption event, we’ve observed a downward trend in the proportion of large issues triggered by config changes. We prevented a potential larger issue, and observed no further issues of that caliber triggered by configerator config changes. That concerted effort drove adoption growth much faster than our organic approach of times past and we accomplished our goal. So what’s next?
Driving Broad Coverage
Now we’re going to protect services that can trigger a large issue when broken!
Importance of Developer Experience
Before we discuss that process, let’s talk about the importance of developer experience. If we’re just trying to eliminate issues triggered by config changes, an easy solution exists: simply stop all config changes. Then no issues triggered by config changes can occur. Easy, right? Unfortunately, if we stopped all the config changes, developers wouldn’t be able to use configerator to mitigate issues, or do their daily work. A major part of reliably changing configuration @ scale entails avoiding unnecessarily impeding the config change workflow with our protection mechanisms. Not just because it is important that developers can make config changes. We also observed that too much friction may impact usage of AutoCanary, potentially resulting in an issue that may have been caught by AutoCanary. We could increase AutoCanary adoption by hundreds more canaries to protect against more classes of issues. But our earlier 2x increase in adoption impacted the developer experience. Additional adoption could further impact the developer experience. We must strike a balance between adoption and developer experience. Let’s explore why an increase in adoption can impact the developer experience.
The Multiple Comparisons Problem
Let’s pause and talk about canaries. Canaries offer the benefit of testing config changes on the exact workloads we see in production. This enables us to catch corner cases that may not be exercised in a Sandboxed environment. As a result, we also get non-determinism. Every canary spec will have some bit of flakiness wherein the canary spec can exhibit a false positive in which it blocks a safe change. This can be expressed with the conditional probability of a canary spec passing/failing when a change is safe or ![]() . With that formula, we observe a canary spec is somewhat flaky when
. With that formula, we observe a canary spec is somewhat flaky when ![]() . All canary specs selected by AutoCanary need to pass in order for the change to pass. If even one fails and signals the change is unsafe for its service, AutoCanary blocks the change. Therefore the chance of AutoCanary passing on a safe change is equivalent to the product of each of its canary specs passing on a safe change, denoted by:
. All canary specs selected by AutoCanary need to pass in order for the change to pass. If even one fails and signals the change is unsafe for its service, AutoCanary blocks the change. Therefore the chance of AutoCanary passing on a safe change is equivalent to the product of each of its canary specs passing on a safe change, denoted by: ![]()
While driving up adoption accomplishes our end goal of increasing the percent of services we cover, it also increases the average number of canary specs that run during AutoCanary. Since every spec is at least the slightest bit flaky, increasing the number of specs run on average decreases the chance of AutoCanary passing on a safe change as seen in the equation from our earlier slide. That can impact the developer experience. This is better known as the Multiple Comparisons Problem. Given the above, how do we get a handle on the multiple comparisons problem?
Taming the Multiple Comparisons Problem
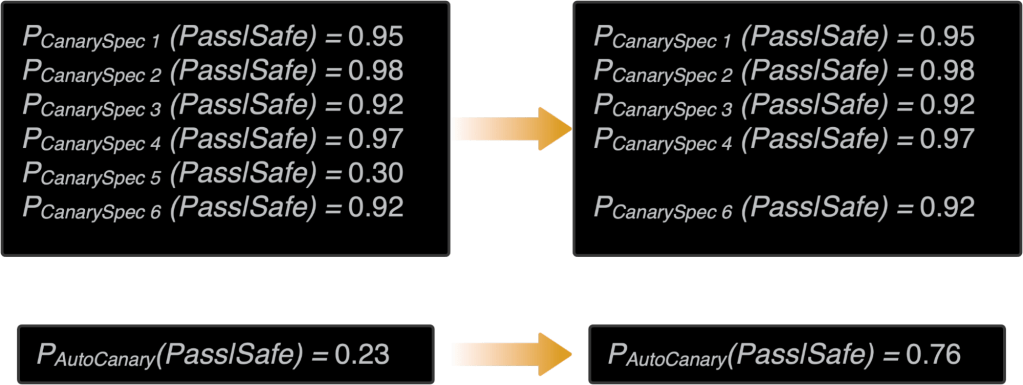
Let’s use a hypothetical example. Assume before broad adoption AutoCanary would run the three specs with the hypothetical flakiness seen at the top of the image for our changeset. If our changeset is safe, the chance of passing AutoCanary with those specs’ hypothetical flakiness is 86%. Now consider the case when we drive up adoption, and that results in AutoCanary selecting three more specs for our changeset with the flakiness seen in the bottom left part of the image. Then if our changeset is safe, the chance of passing AutoCanary with those specs drops way down to 23%. At that point you’d have a better chance flipping two coins and both landing heads than AutoCanary passing on that change. What can we do to improve our chances of passing AutoCanary without sacrificing too much of this important coverage? Let’s explore a solution.

As you may have noticed, one canary spec has a much lower chance of passing than the others, spec 5. What if we skip spec 5? Cutting out that one spec shaves off 70% of flakiness. It increases our chance of passing on a safe change from 23% to 76%!
Automatically Improving Developer Experience
Let’s turn that theory into practice! We’ll need to measure the chance a spec passes on a safe change in order to know if we should skip it. We should react quickly to changes in flakiness so we can accurately reflect production. Otherwise, we might run a spec when it’s flaky or skip when it’s healthy. Lastly, we need to support all specs that could be enrolled in AutoCanary. We have thousands of services. So we can assume we’ll need to support thousands of canary specs. Let’s tackle each requirement in turn.
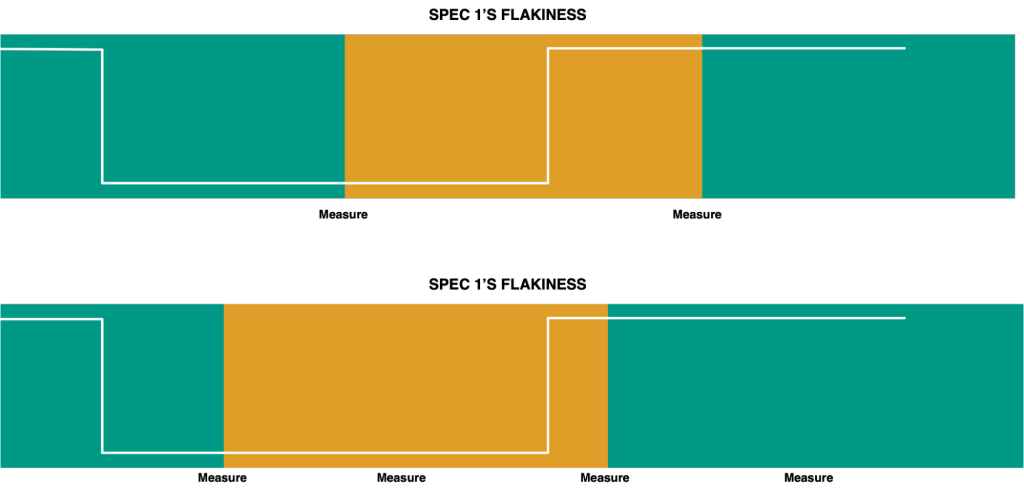
I pose this question to you: What change is always safe? One that will never break a target – a config that is never consumed. To determine if a canary spec passes on a safe change, we simply run it on a changeset containing a config that never gets consumed and check if the canary passess or fails. Alright, next requirement: reacting quickly to changes in flakiness. The white line in the image below reflects the true value of ![]() over time. Colored boxes indicate our measured value of passing on a safe change. When the box goes orange, we’ll skip that canary spec. When it turns green, we’ll run it. In our example depicted at the top, we run infrequent tests. As a result, we don’t react quickly enough. We run the spec even though it is flaky for a large time period. Then when it goes healthy again, we continue to skip it for a while. In the example beneath it, we run tests more frequently. In turn, we react quicker. We run the unhealthy spec less frequently, and skip less frequently when the spec becomes healthy again. The more frequently we run our tests, the more temporally accurate our estimate will be. We should perform our tests continuously and frequently.
over time. Colored boxes indicate our measured value of passing on a safe change. When the box goes orange, we’ll skip that canary spec. When it turns green, we’ll run it. In our example depicted at the top, we run infrequent tests. As a result, we don’t react quickly enough. We run the spec even though it is flaky for a large time period. Then when it goes healthy again, we continue to skip it for a while. In the example beneath it, we run tests more frequently. In turn, we react quicker. We run the unhealthy spec less frequently, and skip less frequently when the spec becomes healthy again. The more frequently we run our tests, the more temporally accurate our estimate will be. We should perform our tests continuously and frequently.
Lastly, how do we support thousands of canary specs? We can’t manually do these continuous tests for that many canary specs. We need to build automation to scale this process.
So we created Canary Spec Doctor, a service to continuously measure the flakiness for every spec enrolled in AutoCanary. Canary Spec Doctor will continuously retrieve the set of canary specs enrolled in AutoCanary. For each spec it will:
- Run the spec with a never-consumed config to determine if it passes on a safe change.
- Look back over a window of these runs to determine an aggregated pass rate.
- If the pass rate exceeds a healthiness threshold we define, we consider the spec healthy. Otherwise, we deem it unhealthy.
Among other actions, we integrated the spec health information into the AutoCanary workflow so AutoCanary:
- Retrieves the set of specs it should run based on our consumption data.
- Consults the spec flakiness info to determine which specs are healthy.
- Runs those specs that are healthy and marks the others as skipped.
While we can directly reduce the AutoCanary flakiness by skipping specs, we shouldn’t skip too aggressively or we’ll reduce our coverage and risk missing an unsafe change. So what results did we see from tackling the set of flakiest specs, you ask? Since this system was productionized, we’ve only observed one large issue that may have been caught with a skipped spec. But this system reduced the average failure rate of individual canary runs by more than 3x and shaves off over 60% of flakiness on average for the AutoCanary runs it applies to.
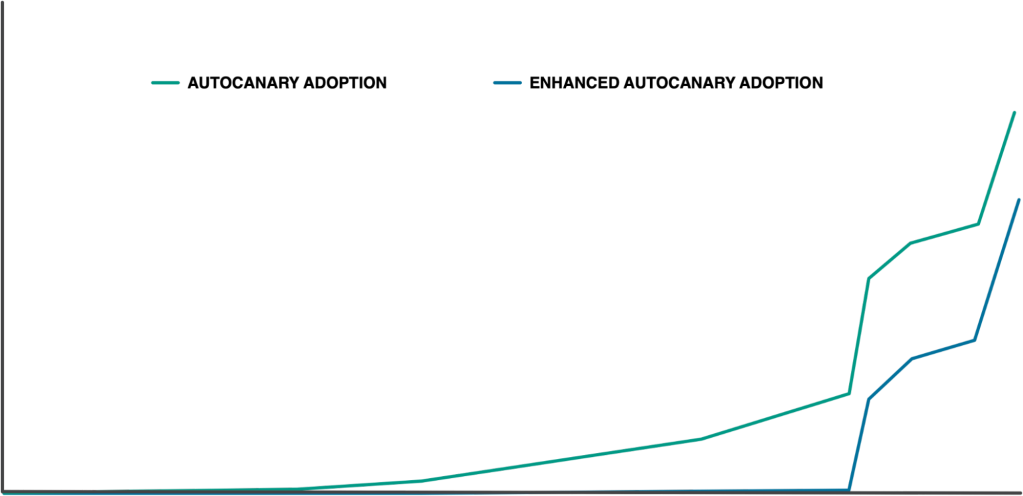
Over that time we had a hybrid organic/concerted adoption effort going to keep high coverage for the services that could trigger a larger issue when broken and allow other services to onboard if they wanted to, resulting in a less drastic adoption slope. But not for long! Now that we’ve implemented Canary Spec Doctor (and other UX improvements we don’t have time to cover today), we can move on to drive up broader coverage.
Preventing Coverage Inflation
Should we perform another event to drive up coverage? Engineers create new services. If we only did that manual effort, the number of services onboarded may increase initially, then flatline. While the number of total services may increase over time. That inflationary process can drive down our total coverage over time. Let’s scale up a human process once more. We built automation to constantly look out for new services and run all the tooling we talked about from our initial AutoCanary adoption event. With that automation in place new service owners only need to accept the generated spec and enrollment to gain AutoCanary protection. Nowadays, AutoCanary protects over 80% of services that can trigger a larger/large issue when broken. We expect this percentage to increase as we close our initial push. It will then roughly stay constant as new services get created and automatically onboarded with this system.
We’re mostly caught up to the present day. What’s next?
Moving Safer, Faster
The journey is only 1% finished. As more developers join Meta, they’ll make config changes, and we’ll create more services that use configs. We aim to do far more than simply maintain the status quo. We plan to move safer, and faster.
Improving and Balancing Developer Experience and Safety
We accomplished our goal of driving up coverage to gain greater protection for our services. Now further improvements to the quality of that coverage will improve the protection of thousands of services and developer experience of thousands of change authors. In addition to improving the quality of the adoption process, we’re invested in improving Meta developer experience and safety directly. Projects like creating a better Canary Spec Management UX, and automatically improving the quality of canary specs, represent a few key ways we’ll enhance developer experience and safety.
Beyond improving each area directly, we intend to do more. An inherent tradeoff exists between developer experience and safety. We can onboard more services, and make stricter health check metrics to improve safety. But that could increase flakiness and slow down developers. We could set a more aggressive flakiness threshold to consider specs unhealthy sooner and skip more to improve the developer experience. However, that could decrease our safety. We will improve both developer experience and safety, yet those efforts may take time to roll out. To improve developer experience or configuration safety ASAP, we’re building a principled mechanism to gauge and act on the risk of config changes to balance the two.
Get Involved
I would like to thank my teammates and our partners who made this journey possible. And thank you for joining me on this journey of AutoCanary adoption. As you saw, scaling our protection mechanisms to cover the config changes consumed by thousands of services at Meta remains crucial to our reliability. Doing so while maintaining a high quality developer experience is even more important. If you like the challenge of making config changes safer and faster at our scale, then come join Meta!

