









In this blog post, we will explore the evolution of change-safety management for the hundreds of thousands of network devices in Meta data centers. We will delve into the methodologies and tools we use for safe deployment. We will discuss how automated testing, simulation, and controlled rollouts come together to minimize the risk of network disruptions and downtime.
Change is the Biggest Reason for Network Outages
- July 2024: CrowdStrike distributed a faulty update to its Falcon Sensor security software that caused widespread problems with Microsoft Windows computers running the software.
- October 2021: Due to a network configuration change, Meta experienced an outage that took down all its services, including Facebook, Instagram, and WhatsApp.
- September 2020: Microsoft Azure experienced an outage that affected multiple services, including Azure Active Directory and Azure Storage, due to a configuration change that caused network congestion.
- October 2020: AWS experienced a major outage that affected multiple services, including EC2, S3, and RDS, due to a configuration change that caused network congestion.
There seems to be a common theme across many of these outages:

Change Management for Meta Data Center Networks
The ever-growing size of the fleet
The ever-expanding size of Meta’s data center fleet is driven by the need to support the growing demands of its family of apps and services, which includes Facebook, Instagram, WhatsApp, and more. With 25 data centers globally, each housing thousands of network switches, Meta is committed to providing the necessary infrastructure to ensure seamless user experiences.
Likewise, Meta is experiencing a substantial surge in its AI-dedicated infrastructure, a pivotal element in driving transformation across various dimensions, such as revenue growth, content integrity, privacy, and the Metaverse. This expansion is not just a response to demands but also a proactive measure to support the increasing complexity and scale of Meta’s products and services.
What kind of network changes are deployed?
Meta’s data centers are equipped with servers interconnected by network switches. These switches rely on the Facebook Open Switching System (FBOSS) service to program forwarding and routing entries into the hardware’s forwarding application-specific integrated circuit (ASIC). FBOSS works with internal routing systems, such as Open/R, and other software components to ensure network switches can efficiently forward traffic.
Our deployment strategy involves a bundle known as the forwarding stack. This bundle, which includes FBOSS services, other network services, and a snapshot of the configuration, plays a pivotal role. By deploying the forwarding stack, we can guarantee that our network switches are correctly configured and can efficiently forward traffic. This, in turn, ensures seamless communication between servers within the data center, which is the ultimate goal of our deployment.
Challenges for safe change deployment at Meta
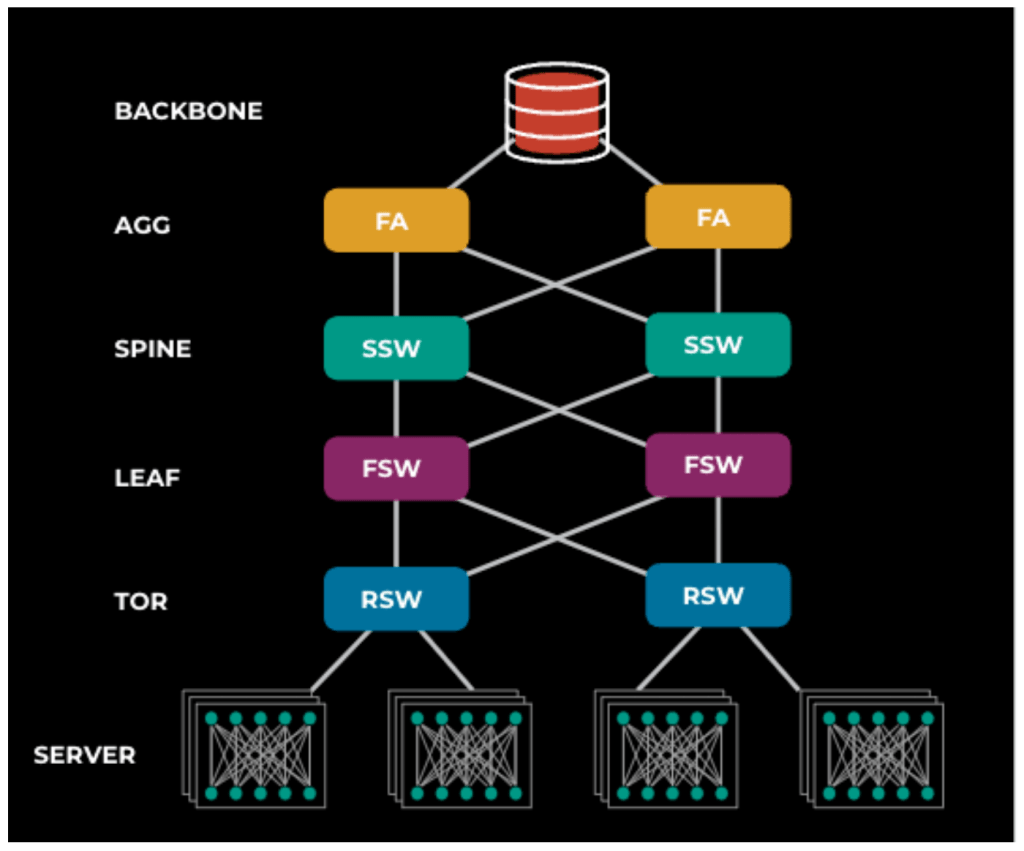
To deploy changes safely at Meta, we need to address the following challenges:
- The vast diversity of network platforms across each layer results in the need for comprehensive health checks to detect and prevent bad changes from being deployed on network switches.
- Since there is only one top-of-rack switch, frequent changes to these switches must be non-traffic-affecting so the rack servers can continue functioning.
- We adhere to the philosophy of “release early, release often.” This accelerated release cycle increases the potential for a faulty configuration change to affect the availability of Meta’s suite of applications, including Facebook, Instagram, and WhatsApp. Therefore, to maintain the reliability and stability of our services, we must execute these changes with utmost care and precision.
Strategies for enhancing change safety
Recent industry outages have highlighted the critical importance of robust change management. To safeguard against future disruptions and address the unique challenges of safe-change deployment at Meta, we have identified five key strategies.
- Test more, catch more: Implementing comprehensive testing to detect and prevent errors.
- Go slow: Adopting gradual rollouts to minimize risk and ensure stability.
- Keep it safe: Employing techniques to guarantee safe deployments and avoid network disruptions.
- Identify and handle high-risk changes. Some changes are more dangerous: Identifying and handling high-risk changes with extra caution.
- Limit the blast radius: Implement measures to prevent potential damage and widespread outages.
Below, we will explore each of these strategies in depth, examining the work done to ensure the reliability and safety of our network infrastructure.
Test more, catch more
Qualification Pipeline
In the qualification process for the FBOSS forwarding stack, we conduct several types of testing to ensure the reliability and safety of changes before they are deployed. Here’s a breakdown of the testing types.
- Individual binary qualification: This involves three main steps:
- Initial testing: When a change is submitted, it undergoes breadth-wise testing to cover all roles and platforms, along with quick tests to prevent the review process from being blocked.
- Extensive stress testing: After the change lands, nightly stress runs are conducted to test the trunk’s stability and reliability.
- Qualifying for push: Each package maintains its conveyor, conducts more breadth and depth tests to validate the package, and qualifies the package for push by tagging it with a “qualified” tag.
- Bundle qualification: This includes
- Config testing: Testing configurations of packages
- Integration tests: Conducting tests between binaries owned by various teams and hardware tests
- Realistic prod canaries: Mimicking how the push will occur in production environments to ensure real-world applicability and reliability
- Automated and manual monitoring: The process uses tools to monitor trends and track long-term service level agreement (SLA) performance, ensuring that all qualification stages meet the defined standards.
These testing stages and mechanisms are designed to minimize the risk of network disruptions and downtime when changes are eventually pushed to the production environment.
Go slow
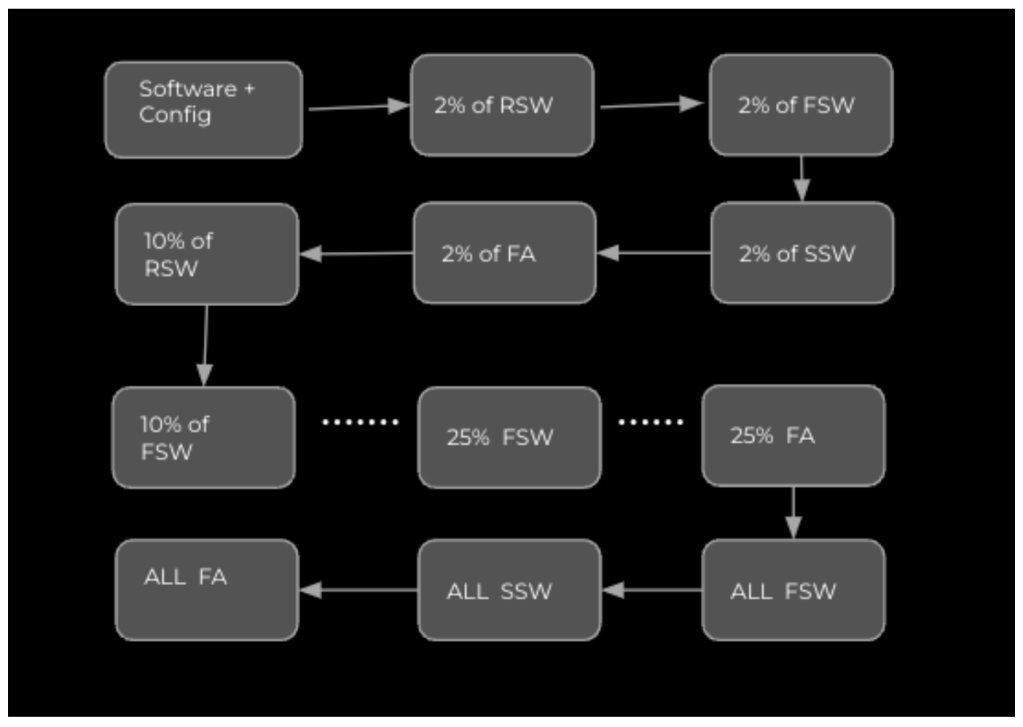
When upgrading network devices, the phased approach is not just a strategy; it’s a crucial risk-mitigation tactic. This method, which involves dividing the fleet into smaller groups or phases based on roles and hardware types, is instrumental in containing any issues within a specific phase, thereby preventing widespread outages.
Each phase has its failure threshold, defined as the ratio of devices with failed health checks to the total number of devices in that phase. This threshold serves as a trigger for stopping the rollout if too many devices in a given phase start to experience problems. For example, if the failure threshold is set at 5 percent, and more than 5 percent of devices in a phase begin to fail health checks, the rollout will be automatically halted.
Before upgrading, we conduct device- and scope-level health checks. These checks are not just routine; they are proactive measures to ensure that our network is in the best possible condition for the upgrade. Device-level health checks are used to evaluate the health of individual devices by analyzing device signals. In contrast, scope-level health checks examine the broader network environment to ensure everything works together seamlessly. By identifying potential issues before they become significant problems, we can proactively address them, thus both preparing better for the push to production and building reassurance that the rollout will be successful.
When a failure threshold is reached during an upgrade, the rollout is automatically stopped. This ensures that any issues are contained and don’t spread to other phases or devices, thus maintaining the safety and efficiency of the upgrade process. By taking a phased approach and setting clear failure thresholds, we not only minimize the risk of widespread outages but also instill confidence and security in our procedures.
Keep it safe
Centralized Safety System
Recent events have underscored the importance of robust health checking across our network domains. In response, we’ve undertaken a two-year effort to consolidate and standardize our health checking processes. By unifying these functions into a single system, we’re better equipped to test changes thoroughly and ensure consistency across data centers and backbones. This consolidation enables us to manage changes more safely and efficiently, ultimately contributing to the overall reliability of our network infrastructure.
Network Health Service (NHS) is a centralized system designed to ensure the reliability and safety of network operations across various domains. It plays a crucial role in managing change workflows by providing a consistent and reliable way to assess the health of network devices.
NHS functions by aggregating health checks from multiple sources, such as microservices that handle specific types of data or network functions. These microservices run detailed audits and checks, ensuring that every aspect of the network’s health is monitored. For instance, one subsystem of the NHS is responsible for running custom health checks, and similar setups exist for other data sources such as network state, device configurations, and more.
How is health checking integrated with the software/configuration update process for network switches?
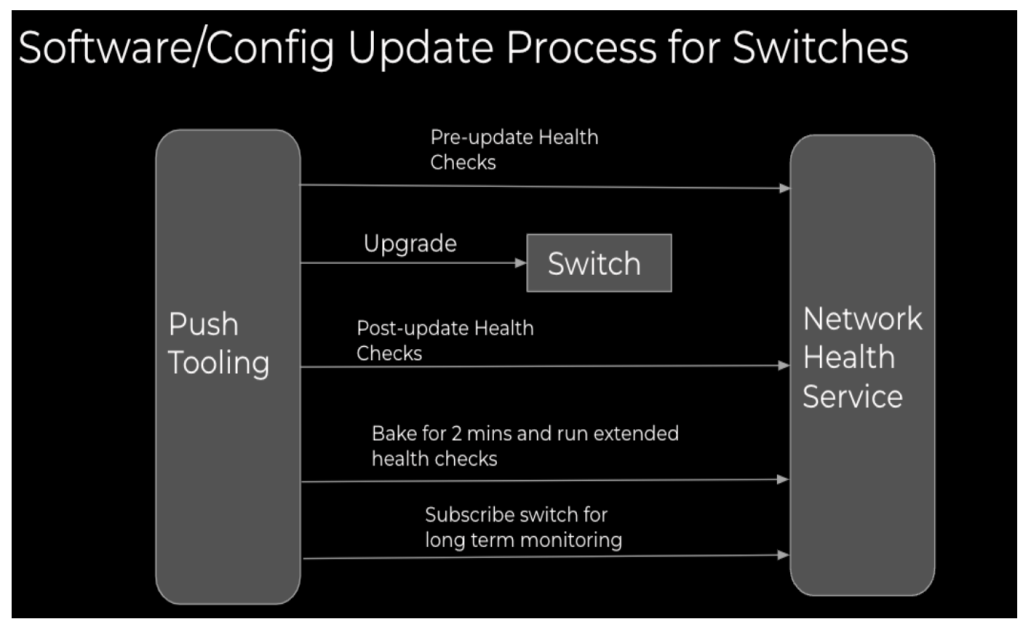
NHS performs various health checks during upgrades to ensure the stability and reliability of network devices. These checks are categorized into point-in-time and snapshot-based checks, each serving a specific purpose during the upgrade process.
Point-in-time checks are executed at specific moments during the upgrade to assess the immediate state of the network. For example, NHS performs checks such as
- BGP config validation: NHS connects to the BGP daemon on the device to retrieve and validate the running configuration, ensuring the peer’s list is not empty. It also verifies that the forwarding information base is synchronized.
- Traffic forwarding binary availability and uptime: NHS confirms the availability and uptime of all traffic-forwarding binaries, ensuring they are functioning correctly and have not experienced any unclean exits.
- Device reachability: NHS verifies the ability to ping the neighbor device using different address types (e.g., inband, out-of-band, and management) to ensure continuous reachability to the device. This check is then augmented to verify reachability to servers in the rack where a software/config change is deployed on top of rack switches.
Snapshot checks involve capturing the state of the network or device before the upgrade and then comparing it with the state after the upgrade. This helps identify any discrepancies caused by the upgrade. Examples of snapshot checks include:
- For originated routes, NHS collects snapshots of routes that originated before the upgrade and compares them with routes after the upgrade to ensure no missing routes.
- Routing sessions, which involves capturing the uptime of established BGP sessions before the upgrade and comparing them post-upgrade to detect any session drops.
- Interface health: NHS collects extensive information about interface health in a snapshot and compares it with the information after the upgrade to ensure no interface issues occurred during the upgrade.
Additionally, NHS provides extended monitoring for devices post upgrade. If a device is deemed healthy after the initial checks, it is registered for extended monitoring during which health checks are run periodically to ensure the device remains stable over time.
These comprehensive checks help to maintain the integrity and performance of network devices during critical upgrade processes, thereby minimizing disruptions and ensuring seamless network operations.
Network Scopes Monitoring
Network Health Service periodically monitors the health of all network scopes, such as data centers, pods, and regions, using various production-monitoring signals and locking a network scope if it becomes unhealthy.
If a bad change causes network loss, the push is automatically paused in the affected scope. Thus, this works as a dynamic feedback loop for the health of the current push and acts as a second line of defense if device-level health checks do not detect the bad change.
Some changes are more dangerous
Routing changes are a specialized type of artifact that require additional safety checks to ensure their safe deployment. We perform these extra checks to mitigate potential risks and ensure the reliability of our routing changes.
An emulation-based system to verify routing configurations
To address the issue of misconfigurations in routing policies that cause multiple incidents, we created a system that safeguards the domain using emulation-based routing policy verification at the time of code submission.
The system thoroughly verifies every routing change by employing an emulated network across multiple regions, closely replicating packet-forwarding paths from any rack to any other rack. This ensures the accuracy of every routing change and prevents config changes that do not align with the operator’s intent. Furthermore, it identifies violations of safety invariants, such as routing loops, funneling, priority inversion, loss of reachability, drain safety, and others.
A specialized system to monitor control-plane health
We designed a specialized system to monitor and ensure the health of the control plane within a network. The control plane routes and manages network traffic by deciding where data should be sent. This specialized system aims to detect and address issues in the control plane to maintain network reliability and efficiency.
Key functions of this system
- Visibility: This system provides a consolidated view of the distributed routing and control-plane state across data centers. It leverages a central store for all state information of a switch to obtain BGP or Open/R configuration and operational states, ensuring comprehensive monitoring coverage.
- Detection: The system detects network-level issues such as route propagation, convergence, and policy compliance. It sends these signals to a remediation pipeline, which can automatically address detected problems.
- Fault detection and alerts: This system can identify faults in the network by monitoring various signals at both the network and device levels. For instance, it checks for route origination, route propagation, and the presence of minimum ECMP paths. Faults detected are then raised to the remediation pipelines for mitigation.
- Device-level monitoring: In addition to network-level signals, this system monitors device-level signals such as the health of routing services, adjacency states, and FIB states. This ensures that the routing infrastructure is robust not only at the network level but also at the individual device level.
Limit the blast radius
We established the Global Network Touch Program (GNTP) to enhance the safety and reliability of large-scale changes to the production network. The program aims to develop and implement a comprehensive set of administrative and system controls to ensure such changes are properly scoped and executed with minimal risk. This initiative is part of our ongoing efforts to improve the resilience and stability of our network infrastructure.
The GNTP program aims to address the issue of network changes being made through various means, some of which may not be sufficiently protected or executed safely. These changes can be risky due to their considerable scope or non-optimal execution methods.
The GNTP program includes policy creation, tracing, protection, and reporting to improve the reliability and safety of changes made to Meta’s production network. These efforts aim to provide end-to-end visibility of crucial information, enforce policy compliance using common system frameworks, and ultimately enhance the stability of the network infrastructure.
Key Takeaways
- Safety is no longer optional.
- Investing in a qualification pipeline for network changes and gradual rollouts ensures that changes are thoroughly vetted before deployment.
- The three top challenges in change management are the:
- Diversity of network platforms
- Need for non-traffic-impacting changes on top-of-rack switches
- Accelerated release cycle
- A centralized safety system provides a consistent and reliable way to assess the health of network devices, keeping us informed and in control.
- The Global Network Touch Program (GNTP) was established to develop and implement a comprehensive set of administrative and system controls to identify and mitigate potential risks.
What’s Next
As we witness a significant expansion of AI-dedicated infrastructure, the size of our fleet is expected to grow exponentially. To accommodate this growth, we must perform many upgrades simultaneously. This necessitates improving the efficiency of our current health checks while maintaining their safety and effectiveness. By doing so, we can minimize the time spent on health checks while ensuring that they are even more reliable and robust.
Continued investment in developing and implementing robust change-management processes that will minimize the risk of network disruptions and downtime.
We will continue collaborating with industry partners and peers to share best practices and learn from their experiences in change safety management.
