






The increasing need for continuous integration and delivery in data center environments has led to the widespread adoption of microservice architecture, in which an application is decomposed into a collection of services that can be independently developed and deployed. To manage the remote procedure call (RPC) traffic among these services, many organizations use a service mesh—a dedicated infrastructure layer—to manage service-to-service communication.
ServiceRouter (SR) is Meta’s novel service-mesh solution—perhaps one of the world’s largest service meshes—which has been in production since 2012. ServiceRouter operates at hyperscale: We route tens of billions of requests per second across millions of hosts spanning tens of thousands of services.
In this blog post, we will explore the key features of ServiceRouter that set it apart from the other major offerings: First, how the design of decentralized service discovery sets the foundation for hyperscale. Second, how load-balancing techniques can be optimized to serve a diverse profile of services. And third, how to introduce latency and load awareness in routing across geo-distributed regions.
The need for service mesh: Why we built ServiceRouter
A service mesh aims to address some of the challenges of building and managing distributed systems, such as service discovery, load balancing, traffic routing policies, and telemetry. ServiceRouter’s origins emerged from a modest goal: We wanted to introduce a centrally supported routing library with a robust host-selection algorithm. At that time, major services such as Ads and News Feed were maintaining custom routing solutions to optimize the traffic distribution for their services. Smaller services utilized a minimal interface that provided service discovery and primitive host selection. Unifying any system can be a challenge, especially when mature systems have already adopted targeted custom solutions. We added one feature to ServiceRouter that changed the game, however, and kicked off the rocketship of widespread adoption: out-of-the-box observability and logging for all RPC traffic.
Unlike other routing libraries, which were built as wrappers on top of the transport, ServiceRouter was uniquely positioned to offer key routing observability insights, as it is integrated directly into Meta’s primary RPC transport, Thrift. ServiceRouter has direct access to a wealth of internal transport data and provides this logging as a first-class feature. This has proved immensely useful to small and large services alike.
An overview of ServiceRouter
ServiceRouter is a scalable service mesh deployed as an embedded routing library in each of the microservices in Meta’s ecosystem. It’s a central location that offers a vast array of routing features, from service discovery and load balancing to connection pooling, security, and observability.
Let’s first dive into Meta’s high-level service mesh ecosystem. One of the primary components of a service mesh is referred to as service discovery, the mechanism that allows services in a distributed microservice architecture to locate each other and communicate. At Meta, services independently register themselves with the centrally managed Service Discovery System, the source of truth for routing information. From there, we employ a highly scalable distribution layer that transmits routing information to individual clients for service lookup. Each client requests only the subset of routing information relevant to them and subscribes to updates for this subset from the Service Discovery System. By replicating the routing information across clients, we decentralize the configuration and management of each client, which enables us to scale to millions of clients.
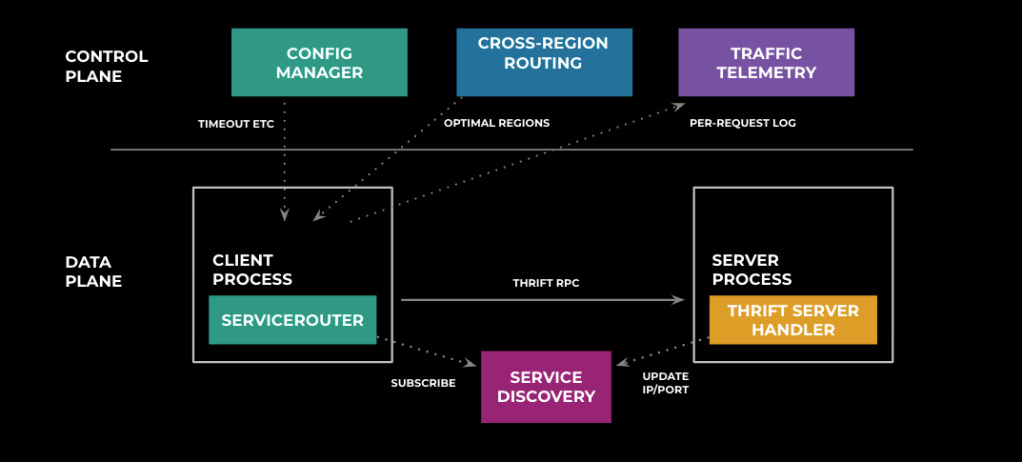
Dynamic configuration with ServiceRouter
One key property of ServiceRouter is its ability to dynamically update control-plane configuration for individual clients. Similar to how the library selectively subscribes to service lookup information, SR will also subscribe to that service’s configuration and react in real time to changes in that configuration. This property becomes useful when we need to respond quickly to production incidents, referred to as SEVs (also known as high-severity incidents; SEV derives from the word “severity”). Configuration changes can be targeted at individual services or at the service mesh as a whole, and the reaction time is on the order of seconds.
Maximizing fleet utilization and service throughput with load balancing
Another important role of service mesh is to distribute traffic across the available instances of a given microservice via load balancing. As the number of unique applications at Meta and the number of hosts running those applications have scaled, so too have ServiceRouter’s load-balancing algorithms evolved to accommodate this growth.
As mentioned earlier, each ServiceRouter client will fetch the host list for a target service from the Service Discovery System, cache this list of hosts, and subscribe to any changes to react in real time to host state transitions.
A service may be deployed across thousands of hosts in order to achieve horizontal scale. To limit the number of connections, each client will choose a subset of the available hosts, called a selection. This selection is done via a modified form of weighted rendezvous hashing, which ensures that the subset remains stable even as the full host list undergoes changes (including host addition and removal). When choosing an optimal subset, ServiceRouter takes into consideration the locality of hosts. The further a host is from the client, the higher the network latency overhead will be for that request. To minimize this latency overhead, SR prefers hosts in the same geographic region as the client and will expand to other regions only as necessary.
Once the stable selection has been determined, ServiceRouter then employs a load-balancing algorithm commonly referred to as “power of two choices (pick-2)”, as first described in Michael Mitzenmacher’s 1996 dissertation, The Power of Two Choices in Randomized Load Balancing. In “power of two choices,” instead of comparing the load across all hosts in a selection, we will randomly choose two hosts and compare their load, routing the request to the host with the lower load. It may seem counterintuitive that we achieve better load balancing by introducing more randomness into the system, but the power of pick-2 lies in the fact that this randomness avoids a thundering-herd effect, where every client tries to send a request to the globally least-loaded host, thus overloading it.
This random sampling helps us narrow down the choices to two hosts, but how do we determine the actual load of each host? ServiceRouter offers two different load-determination algorithms: load polling and cached-piggyback load.
Load Polling
In load polling, ServiceRouter will pre-fetch the load by directly requesting it from each target host and then use the result to choose the lesser-loaded one. The main advantage to load polling is that the load information is fresh, making it a good approximation of the current real-time host state. The fresher the load, the more accurate the load-balancing decision will be. However, load polling incurs high overhead—each poll introduces latency, as the client must wait for the server to respond to the poll request before sending the actual RPC. To combat this overhead, ServiceRouter introduces a second load-determination algorithm, cached-piggyback load.
Cached-Piggyback Load
The name for this algorithm comes from the technique used to efficiently transfer load information from the server back to the client with minimal overhead. With every response that the server sends, it will piggyback the current load value with the metadata of the response, which the client then caches locally for future routing decisions. This method does not introduce additional latency for the request, as the client just reads from the local cache to compare the load between hosts. A cached load comes with its own downside, though: It relies on frequent responses from the server to update the cache and maintain a fresh load. If the request rate from the client is not sufficiently high, the cached load becomes stale, which can result in poor load-balancing decisions that don’t account for the real-time state of the system.
The chart below illustrates the ideal load-determination algorithm based on the service’s properties. A client with a high request rate can effectively utilize the cached load, as that load will always be fresh. For a client with a low request rate, the decision becomes more nuanced. Because load polling introduces extra latency overhead, services that are highly latency sensitive can’t afford to incur this overhead, and their best option may be to do random load balancing if the cache is sufficiently stale.
| Service Characteristics | Low request rate | High request rate |
| Low Latency Sensitivity | Load Polling | Cached Load |
| High Latency Sensitivity | Random | Cached Load |
Services saw great results when configuring their load balancing to the appropriate algorithm based on their unique traffic profile. As Meta infrastructure grew in size, however, so too did the number of different services and the number of teams owning those services. Tuning the load balancing configuration across so many services became increasingly difficult to manage. Here we saw an opportunity—the SR library itself has access to all of the data needed to make smart load-balancing decisions on behalf of services. SR could track the request rate and the latency of the requests, and it could use this to build a heuristic that determines whether a client needs to refresh the load information for a given backend server. As such, we introduced Automatic Load Balancing, a feature in which the library can dynamically change the load-balancing policy for a given service based on the service’s real-time traffic profile.
The chart below shows the impact of enabling Automatic Load Balancing for one of Meta’s major services. The y-axis here indicates the distribution of load across hosts in a service. Larger spikes imply more load imbalance—some hosts are underloaded, while others are overloaded. As you can see, the distribution of load across available hosts in the service converges, indicating that automatic load balancing better utilizes the capacity of each host.

Minimizing connection latency via connection pooling
ServiceRouter employs several techniques to reduce the connection establishment overhead for a wide variety of services. SR utilizes a common technique called connection pooling, which reduces both the latency of an RPC and the resource overhead incurred by sending each request. Establishing a network connection between the client and server is typically an expensive operation, even more so when sending traffic over secure transport that requires authentication of each connection on establishment. Connection pooling reduces this overhead by reusing established connections instead of creating new ones for each RPC.
When a client sends a request to a new server, SR will establish the connection and add it to a shared pool, which can then be used for future requests to that same server. Connections are maintained as long as they are being used. If the connection remains idle for longer than a specified threshold, it will expire, which frees up those resources for use elsewhere in the process.
When talking to the same set of hosts, many clients can achieve minimal connection latency overhead by making use of local-connection pooling. Imagine a client that has selected 10 hosts from a backend service and sends 20 requests per second. On average, each backend host will receive 20/10 = 2 requests per second, enough to keep the connection active and warm.
This optimization breaks down, however, when dealing with microsharded services, where a large number of clients need to route requests to specific shards that are fanned out across many different backend hosts. Let’s consider a service that is split across 1000 shards with a client that sends 20 requests per second, with requests evenly distributed across all shards. Now, on average, each backend host will receive 20/1000 = 0.02 requests per second, or one request every 50 seconds. In this case, each client ends up connecting to all the backend hosts, and the request rate from each individual client to each backend server is not sufficiently high to maintain warm connections.
One solution here is to reduce the fanout burden by first aggregating traffic in a small proxy tier that sits between the client and server, which essentially acts as a shared connection pool across many clients.
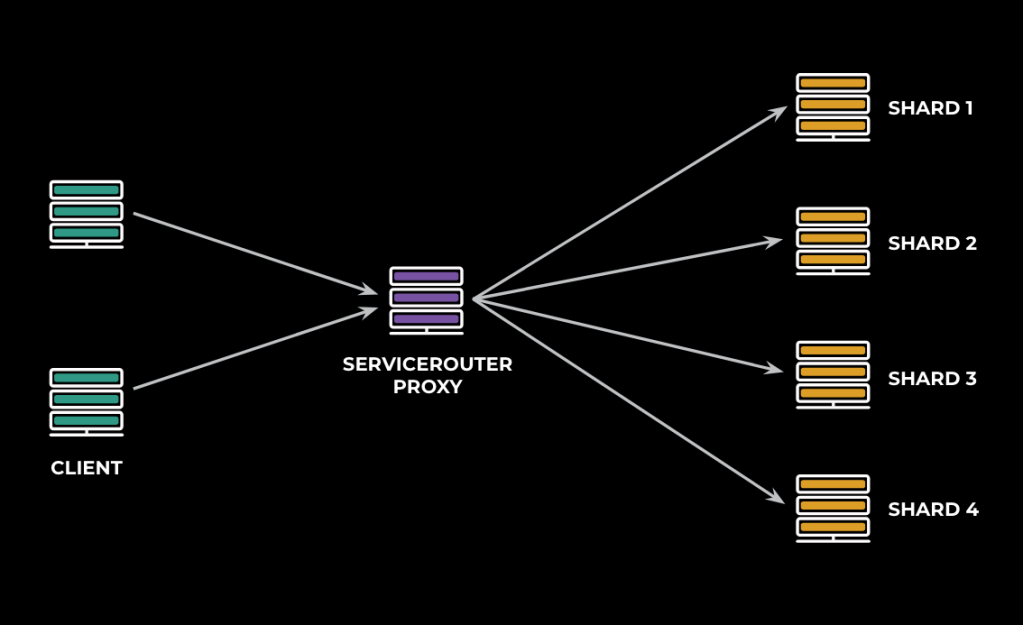
ServiceRouter has first-class support for plugging in this proxy to the service mesh. The local client library can transparently forward traffic through the proxy, thus eliminating the need for a direct warm connection between client and server. Clients maintain a small connection pool to the proxy tier, which enables the connections between client and proxy to stay active. Furthermore, the proxy tier is able to maintain warm connections to the backend service, as it fans in traffic on behalf of many clients. This fan-in amplifies the request rate from a proxy host to the backend as compared to sending the request directly from client to server. The amplified request rate enables the proxy to better utilize connections to the backend.
The proxy is a lightweight wrapper around SR library code, hosted as an independent service that simply forwards traffic to the backend service. As such, the improvements to connection latency that it provides for these types of sharded services outweigh the small additional overhead incurred by the additional hop in routing.
Optimizing for cross-region routing
In order to reach hyperscale, Meta’s microservice architecture is distributed across numerous geographic regions. As the number of regions increases, the routing decision becomes more complex: Should a client route requests to servers that are located in the same region but have higher load, or is it better to incur the penalty of increased network latency to route to the least-loaded region? Or should a client find an in-between region where latency and load are both acceptable? Many existing service mesh solutions are not optimized for cross-region routing.
ServiceRouter introduces the concept of locality rings for services to express their preferred tradeoff between latency and load. Each geographic region is assigned to a ring relative to the client’s locality, with each ring representing a network latency threshold. Services have the ability to specify their latency tolerance by configuring a load threshold for each ring. For example, a service may specify that requests should stay in region unless the in-region load goes above 70 percent, at which point the service may utilize capacity from a farther locality ring.
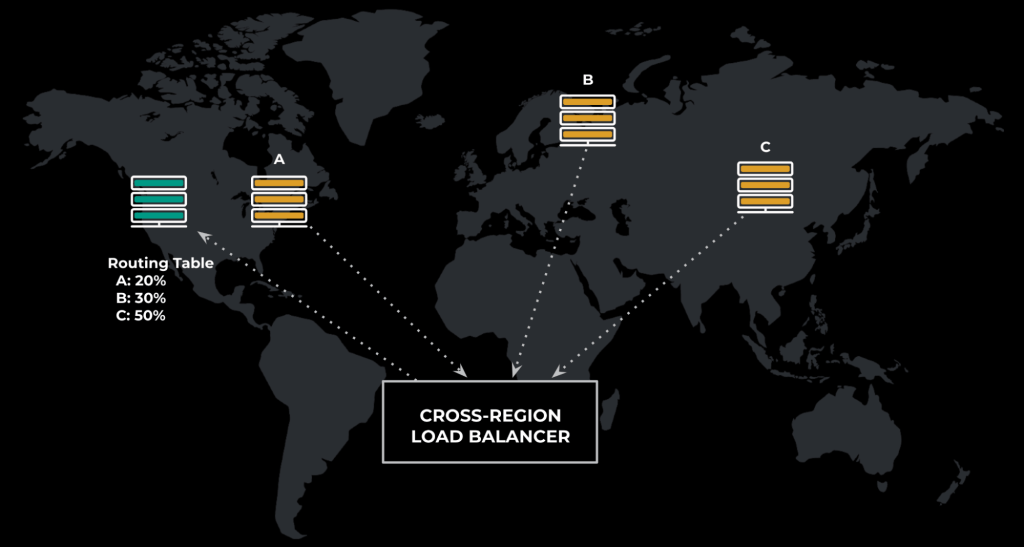
In conjunction with locality rings, Meta’s service mesh also employs a Cross-Region Load Balancer, which aggregates global traffic information and distributes it via the Service Discovery System to local SR clients in the form of a cross-region routing table. The table then guides local client load-balancing decisions. It’s important to note here that the Cross-Region Load Balancer introduces the benefit of a centralized global view without the downsides of centralization’s single point of contention and resulting failures. It works because the global traffic information is collected in a background process and then distributed to the relevant local clients.
Key Takeaways
ServiceRouter offers a rich library to power the service mesh across Meta’s distributed microservice architecture. From its origins as a simple yet robust service-discovery mechanism, ServiceRouter has grown to serve tens of thousands of unique services, routing tens of billions of requests every second across millions of servers. ServiceRouter’s deployment in production since 2012 proves that we can scale the typical service mesh abstraction by decentralizing key aspects of the control plane logic. ServiceRouter makes use of decentralized load balancing to maximize capacity utilization across the fleet while minimizing the resource overhead of routing RPCs. As much as possible, ServiceRouter delegates routing decisions to local clients to reduce the potential for bottlenecks that arise from centralized decision making. SR is flexible enough, however, to plug in centralized components only where necessary, as seen in the use of remote proxies for managing connections to fan out services. That flexibility also allows the use of the Cross-Region Load Balancer to optimize for routing across the many geo-distributed regions that Meta infrastructure maintains.
We’ll be presenting our paper, “ServiceRouter: a Scalable and Minimal Cost Service Mesh,” at the 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’23). It describes ServiceRouter’s design and implementation in more detail and discusses the unique properties of SR that make it novel with respect to other widely known service meshes. It elaborates on the different architectures that ServiceRouter supports and offers an in-depth analysis of the hardware savings that the embedded library architecture provides.

