






Meta large-scale deployment needs to support billions of customers who rely every day on our family of apps (Facebook, WhatsApp, Instagram, etc). Our infrastructure has grown to an extraordinary number of internal applications and to a fleet of 15+ geo-distributed data center locations. This complex ecosystem requires an efficient and reliable remediation pipeline to help us sustain maximum fleet availability and ensure that we run healthy applications. Putting efficient mechanisms in place assures we can more reliably remediate software and hardware failures.
Through this post we want to provide a deeper dive of how we manage software and hardware remediations at Meta, zooming in on the work that was introduced in one of our latest blog post. We’ll also focus on two of its primary services: FBAR, our event-based software remediation platform, and RepairBrain, which orchestrates the hardware actions.
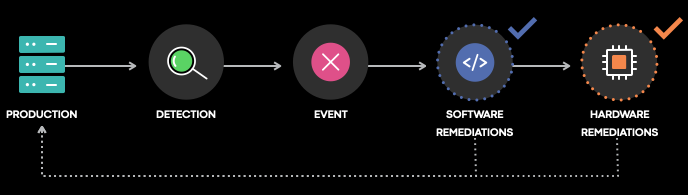
Detection of software and hardware problems
It all starts with detection. This step assures that services operate efficiently and reliably in a distributed system. Identifying problems in this way helps reduce the risk of workloads getting exposed running on faulty devices. This (in turn) minimizes disruption of services. It further allows for us the system to take remediable actions earlier to correct faulty conditions.
For that we use MachineChecker, a system responsible to assess the production worthiness of devices. It does so both locally, running on the target system as a binary or as a service through the execution of remote commands. This system periodically scans our fleet of devices — with the majority of the assessments performed through binary on the host.
For several years, we’ve utilized on-host detection as our primary method for hardware health detection. We’ve learned a great deal in maintaining this flow across our fleet of devices. We adapted and shaped solutions to address pitfalls imposed by different failure methods hindering our detection workflow. Doing so enabled us to identify problems over time. For instance, we built a MindTheGap system, responsible to ensure that no systems fall through the cracks. It watches out for systems that have not had a health assessment reported during a specified time period. This triggers an ad-hoc verification to force unmonitored systems to enter the remediation flow.
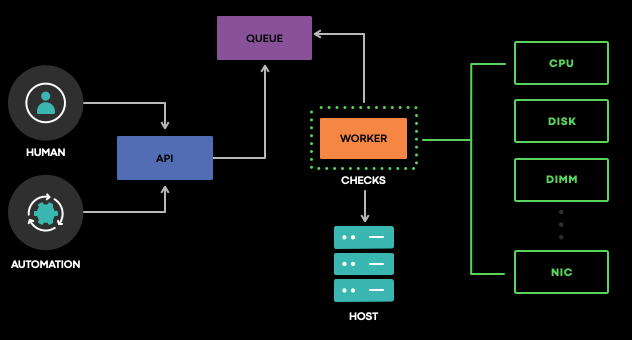
A collection of checks comprises the health assessments performed by MachineChecker. Each check holds responsibility for assessing the presence, absence or values above predefined thresholds. For example, it detects the presence of I/O errors on the kernel ring buffer, network interface speed and systems sensors, among others. Upon completion, results get sent to storage. Failures get raised in the form of alarms, (in effect) the entry point for the remediation flow where FBAR picks them up for further processing.
In addition to the main hardware health detection framework mentioned above, we also count with additional custom detectors built to react whenever a datapoint breaches a predetermined value. We count as well through machine learning detectors that learn patterns and alerts on anomalous trends. We also funnel these to FBAR.
Remediations
Software Remediations
When first introduced in 2011, FaceBook Auto Remediation (FBAR) entailed a collection of scripts wrapped around APIs calls. We employed it to automatically mitigate small repetitive outages originally resolved manually, mostly related to broken servers.
Since then its architecture has deeply evolved. It currently serves hundreds of customers (IG, Messenger, etc) with different use cases. Customers can now define remediation actions written in Python. This mirrors what happens with AWS Lambda. Actions are executed when a particular event gets created. Mapping between events and actions is specified through configuration files. For running the remediations in separated and isolated workflows, we leverage the CWS workflow engine previously presented at the spring edition of systems @scale.
Initially, we based the service on an old monolithic application written in Python. The first step we took involved isolating the deployment of remediations code containerized in per-customer fashion. We then tackled the main logic: extracting it and moving to a microservice-based architecture initially written in Python and now redesigned in C++.
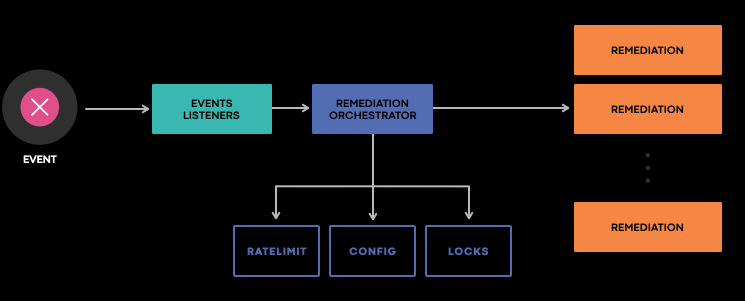
Events are fetched by both reading from a stream or by polling the events storage. Once an event has been fetched FBAR orchestration evaluates that. First, it assures that no blocklist exists on the type of event. Then, it assesses if adding a new event is possible for that ratelimit, along with other checks done on the host. If all of the checks pass, FBAR will schedule on a separate orchestrator the workflow which executes the customer code.
Hardware Remediations
The remediations described above all have among their default result action another possibility: a repair workflow can get triggered in case they spot their resolution steps didn’t work and they suspect that this could be caused by faulty hardware. Additionally, when the health-checks described in the detection paragraph do assess something wrong exists with the hardware, they similarly trigger an alert that’s caught by FBAR. That in turn triggers the procedure for executing the repair workflow.
By repair workflow we mean all the series of actions that we execute against a broken device that can mitigate a failure which potentially derives from an hardware issue. These actions differentiate from FBAR remediations as they tend to be more invasive (e.g. re-provisioning the devices) These usually get executed after we drained the device from serving production traffic.
Historically, we handled the repair workflow as a deterministic state machine flow. We would execute a fixed series of steps before handing over the device to a datacenter technician for further and more advanced (but often manual) troubleshooting. Among the main pain points of this approach, given that it was running on legacy code, modifying or simply adding additional resolution steps grows challenging (for example for a very specific hardware type).
With that in mind, we’ve decided to redesign a resilient and yet flexible repair workflow capable of being influenced both by a decision engine as well as by humans.
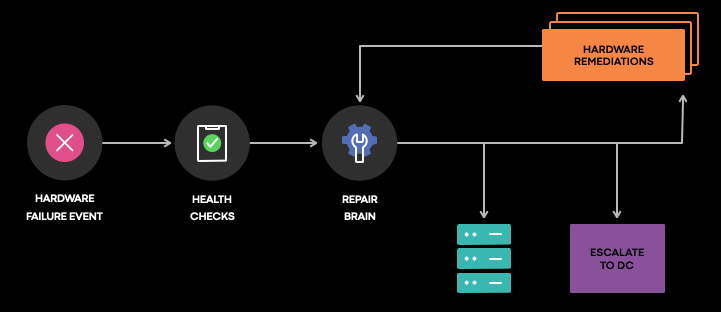
A platform called RepairBrain, steers the execution of the repair workflow. After being drained from the production traffic, a device enters the repair workflow. We then kick off the flow by re-assessing the current issues or any failure occurring in the device. In case we extract the failure signature and pass it to RepairBrain which has two ways of proceeding:
- A rule-based decision engine, where operators can specify actions to get executed when the failure signature matches the expected ones,
- A ML-based decision engine, where the failure signature is passed to a ML model in charge of predicting which action has the highest chance of mitigating the problem.
In case an action requires human intervention such as swapping a DIMM or a CPU, the system advances this operation by creating a ticket in a dedicated queue for the datacenter engineer to complete the action.
Future Work
We’re handling new challenges while continuing to scale our remediation pipeline. In particular, we’re working on three main areas:
- Faster detection: it’s important that we speed up the time to detection of any software or hardware problems.
- Generic remediations: so far we’ve employed this pipeline to remediate issues on server and network appliances. For the future we want to introduce other device types.
- Higher accuracy: this work is related to improving the accuracy of our decision engines, which continuously learns from the past actions and where we want to improve its reliability in identifying the right action to pursue.

