









Background
An important aspect of social media platforms is providing people with the ability to interact remotely in real time. When someone starts watching a live video of a celebrity, thousands of comments might be posted every minute, and users see the comments right away and can react to them. In messaging apps, users see which friends are currently online. Similarly, when a user initiates a live video, their friends and followers are notified immediately, and they can watch the live streaming as it happens. Numerous other examples can illustrate how real-time experience is used in practice, but the bottom line is that social media platforms provide users with a real-time interactive environment.
Real-time experience demands that the most updated contents are provided almost immediately. Otherwise, users will periodically try to download fresh data by reloading the entire page. For example, if users do not see any new comments on a live video, they may refresh the whole page. This leads not only to a bad user experience, but is also inefficient for both the client device and the server: a full-page reload leads to battery drainage, high internet data usage, and greater server utilization.
State-of-the-Art Solutions
In this blog post, we’ll discuss two high-level solutions for continuously delivering fresh data to clients: periodic polling and pushing server-side events. Periodic polling is a simple approach for fetching new events at certain intervals. It’s easy to implement, but can be inefficient in large-scale systems. Pushing server-side events is a more efficient alternative method, as it eliminates unnecessary requests to the server, but results in a system that is more complex to design, implement, and maintain. Below, we will further discuss these two approaches.
Polling new contents
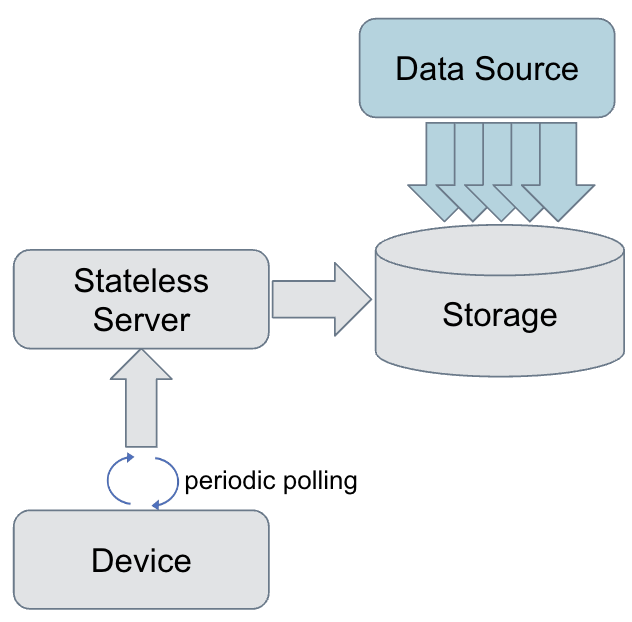
When periodic polling is in use, the device sends a request to the server at certain intervals to receive the incremental data updates since the last poll. Polling is based on simple request-response architecture, where the client makes a normal HTTP request and the server responds with a subset of full data (or no data, if there has been no update).
Despite the simplicity of this approach, the device still needs to make periodic requests, which creates additional load on both the device and the server. A high polling frequency leads to high server utilization, as it has to execute an expensive time-range query to fetch only the latest contents. Similarly, every poll requires battery and network data usage of the client device, which goes wasted if there is no new data. On the other hand, clients using less-frequent polling can miss data if new contents are generated often, such as in a live video with many viewers. Regardless, polling remains a good solution for many applications where frequent polling for data isn’t needed.
Pushing server-side events
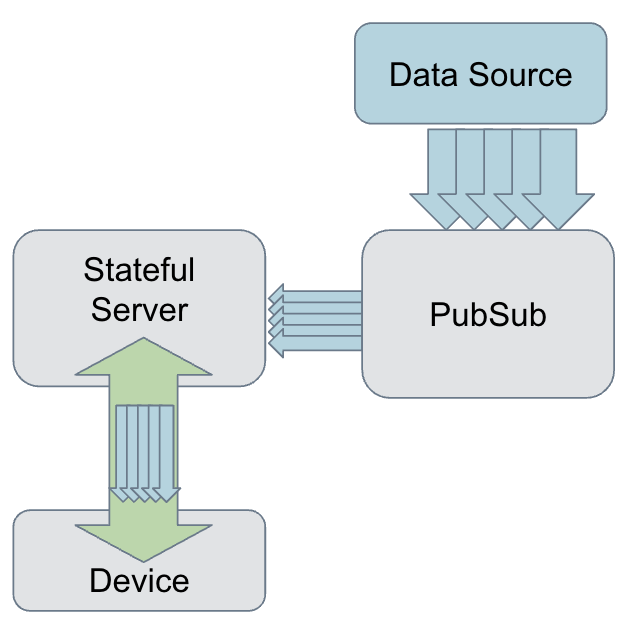
Real-time push, where a bidirectional, persistent connection between client and server is maintained, is a more efficient solution. Each connection represents a logical stream that delivers a certain data type to the client. For example, one stream may deliver comments posted on a live video, while another stream delivers real-time reactions on that same video.
Delivery of server-side events requires a PubSub service that receives events from the client and dispatches them to other services or clients that are waiting for them. Such a PubSub system uses unique string keys to categorize different data sources. These keys are called “topic.” For example, for the comments posted on a live video, the topic can be a combination of “live_video_comment” (to signify the category) and video ID: for example, “live_video_comment/video_id_1234”. Any client that is publishing a comment sends it, along with the topic, to the PubSub service. The topic is what indicates to PubSub the video to which the comment belongs.
When a device connects to the stateful server to receive live video comments, the topic is passed along as part of the request. The stateful server uses this information to create a persistent subscription to the PubSub service and receive the fresh comments as they are posted.
Keeping two long-running connections between the PubSub service and the device allows the stateful server to receive the events from PubSub as they happen and immediately push them to the device. If there is no new event, the device will not receive any updates, which saves resources on both the client device and the server.
BladeRunner as stateful service
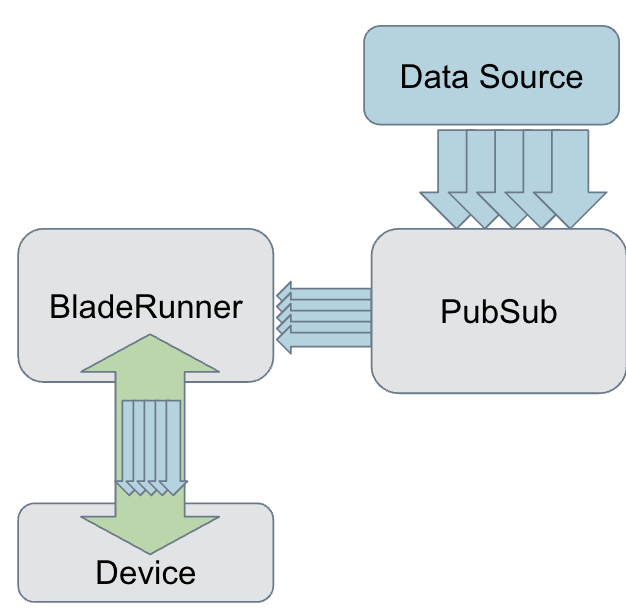
In the diagram above, Meta’s BladeRunner is the stateful server that maintains a persistent connection between the client and PubSub service. Details of BladeRunner are presented in [1]. Devices that need to receive real-time data connect to BladeRunner and provide a topic to subscribe to. For every client connection, BladeRunner creates a new subscription to PubSub service for the same topic. As BladeRunner receives new events, they are passed to the product logic that performs various operations such as payload transformation and localization. If the product logic determines that the event should be delivered, BladeRunner pushes the event to the connected device.
Opportunities to Optimize BladeRunner
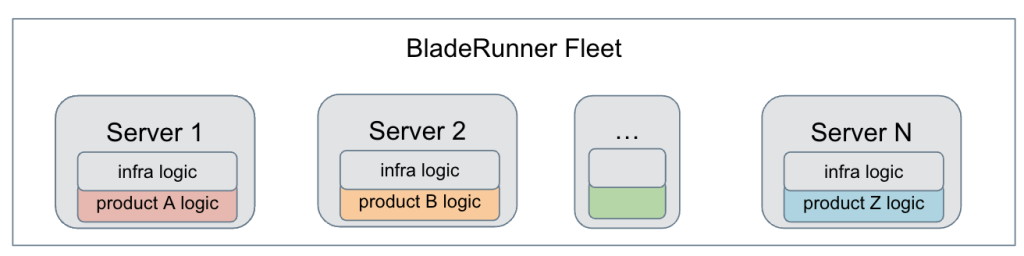
Over the years, numerous categories of products have been built inside BladeRunner. The logic of each product is closely coupled with the BladeRunner infra logic, which provides various capabilities such as subscription to PubSub service and maintenance of a persistent connection to clients. This merger of server and product roles, however, has caused multiple complications, including:
- There is a Gray code ownership boundary as product code becomes part of infra logic. This increases the effort needed to maintain the code and triage regressions.
- Product developers need to run the BladeRunner stack for development and testing, causing a difficult developer experience.
- Strong coupling between the product and the infra logic creates hidden dependencies, which complicate deployment and backward compatibility.
- Hardware capacity management becomes very difficult, as it is not clear how CPU and memory utilization is shared between the infra and product logic.
Separating Product & Infra Server Roles
Faced with these problems, we decided to revisit BladeRunner’s design and separate the infra logic from product-specific logics. We found that while each product has its own set of rules for handling new subscriptions and delivering events, most of the products use a common set of features. Therefore we divided the logic in BladeRunner into two categories:
- Common logic: This was the logic used by some or all of the products, such as a subscription to PubSub service or the application of a rate limiter to limit delivery rate of events.
- Product-specific logic: This includes operations such as data transformation that might be different for various products. For example, one product might need to translate payload to a different language, while another might need to ensure that the client is authorized to receive the payload.
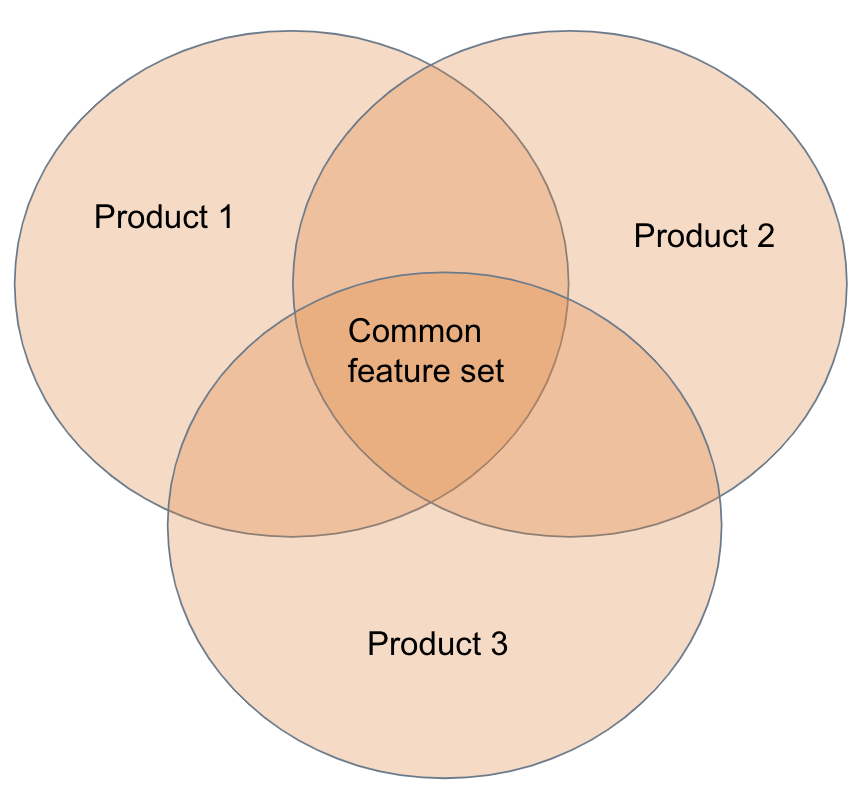
Classifying logic in this way, it became possible to separate product logic from infra logic and move the product logic to an environment that’s better suited to product development. In this approach, BladeRunner becomes a lean service that provides a set of features driven by products. For example, a product can request subscribing to PubSub service, terminating a stream, receiving response acknowledgement, or bypassing payload transformation.
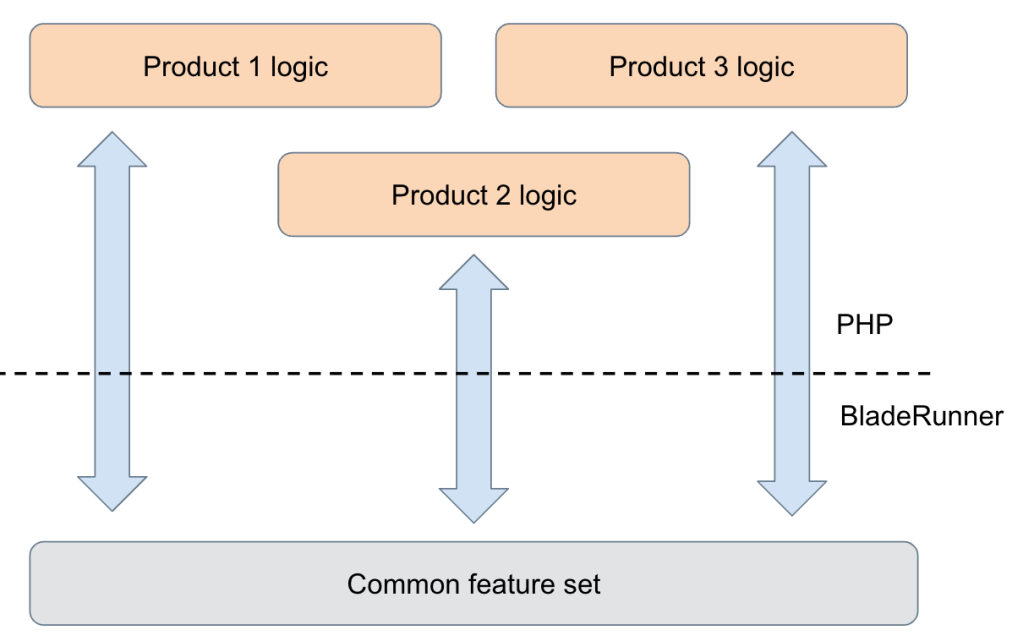
The result was a new framework where BladeRunner developers focus on the development of infra-side capabilities, while product developers focus on delivering product-specific features. This approach also made capacity management much easier, because product logic costs could now be measured in terms of the standard feature set they use. In the new framework, the computational cost of each BladeRunner capability is known, and therefore products using various capabilities can determine how much capacity they need. Finally, the separation of infra and product logic creates a clear code-ownership boundary, since the infra code runs in BladeRunner while the product logic is executed in a different platform.
Separation of product logic from the BladeRunner stack allowed us to choose a different platform for product logic development—PHP, a popular and widely used development environment at Meta. PHP is a scripting language with great developer experience, ample tooling for code annotation, CPU profiling, and various tools for capacity management. Due to its stateless nature and the fact that PHP servers mainly use RPC calls with a short memory life cycle, PHP memory management is also very efficient. Given all of these advantages, PHP was an obvious choice for the development environment for product developers. It should be noted that while we selected PHP as the product development environment for BladeRunner, there is no added value unique to PHP, and such a framework can be extended to other server-side programming languages such as Java and Python where needed.
Emulation of a Stateful PHP Server
PHP is used to implement a RESTful API, where a simple request-response architecture is needed. PHP servers can communicate with backend services as well as client devices, and in both cases a short-lived connection is opened and closed when the request is fulfilled. As a result, PHP functions are stateless, meaning that they cannot hold a persistent connection or any other long-running state. If any persistent state is needed, it should be stored in a data storage system and retrieved for every request, which will incur more processing and storage costs.
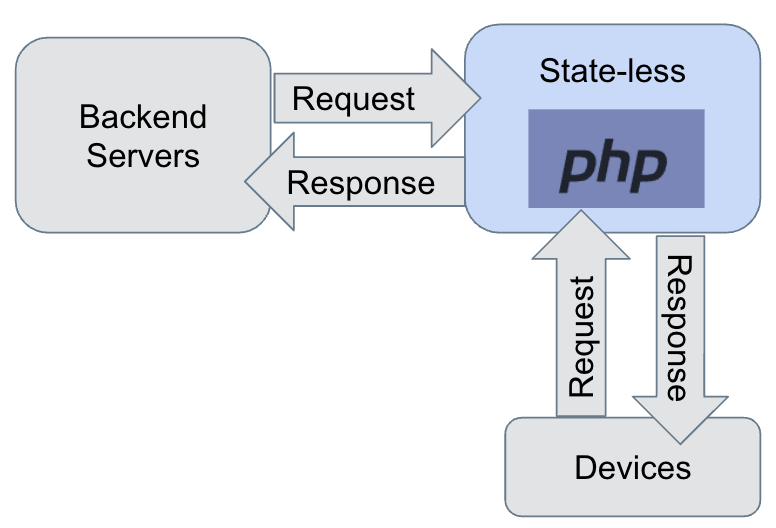
Having a stateful PHP web server is the dream of product developers who want to provide real-time experience to their clients. In other words, if PHP web servers could maintain a persistent connection to clients and a long-running subscription to PubSub services, product developers could easily write the whole real-time push logic in PHP. Since PHP servers are stateless, however, BladeRunner emulates a stateful service for PHP developers where:
- BladeRunner holds the stream state for PHP.
- BladeRunner receives real-time events and delegates processing of the events to PHP lambdas (i.e. product logic).
- PHP lambda responds with a set of “actions” to instruct what BladeRunner should do.
This architecture has three main components:
- Events: the events received at BladeRunner, including the start of new client subscriptions, or an event received from the PubSub system that should be processed
- Lambda: the product logic implemented in PHP to handle events; for example, to process client subscriptions
- Actions: a set of standard features that BladeRunner provides to all PHP lambdas, which include subscriptions to PubSub service and pushing payloads to clients
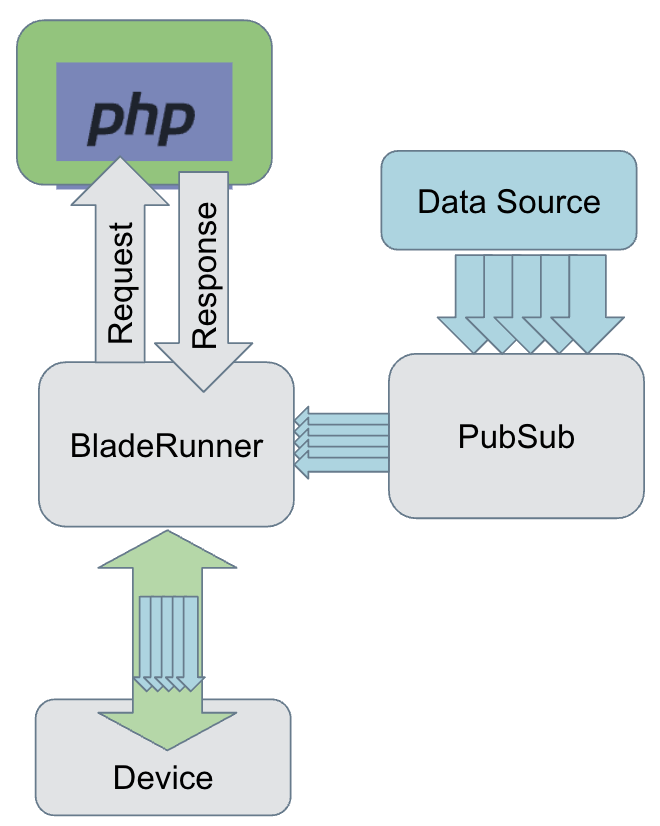
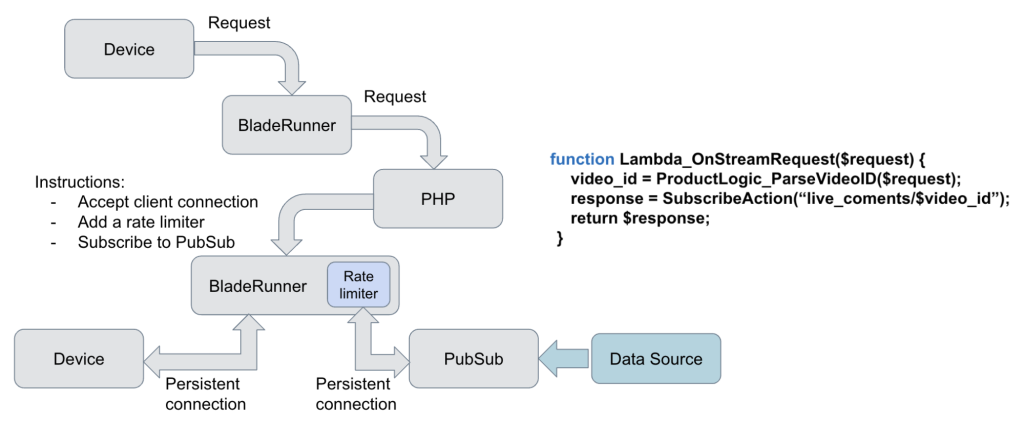
Here’s a real-world example of the end-to-end flow. One of BladeRunner’s real-time use cases is live video comments, where users watching a live video connect to BladeRunner to receive comments as they are posted on the video.
As shown below, the flow of live video comments starts with a request from a client device—a mobile device, web platform, or other means by which users watch live videos. BladeRunner passes the request to PHP lambda, which extracts the ID of the video that the user is watching and instructs BladeRunner to subscribe to receiving comments posted on the video. In addition, lambda tells BladeRunner to accept the client stream (assuming the video ID is valid) and add a rate limiter on the publish path. The rate limiter is especially important when a client is watching a popular video with thousands of comments posted every minute. Processing all these comments is a waste of resources, because humans cannot read such a high volume of comments. In response to instructions, BladeRunner initiates a persistent connection to the client. It also subscribes to PubSub service to receive the video comments.
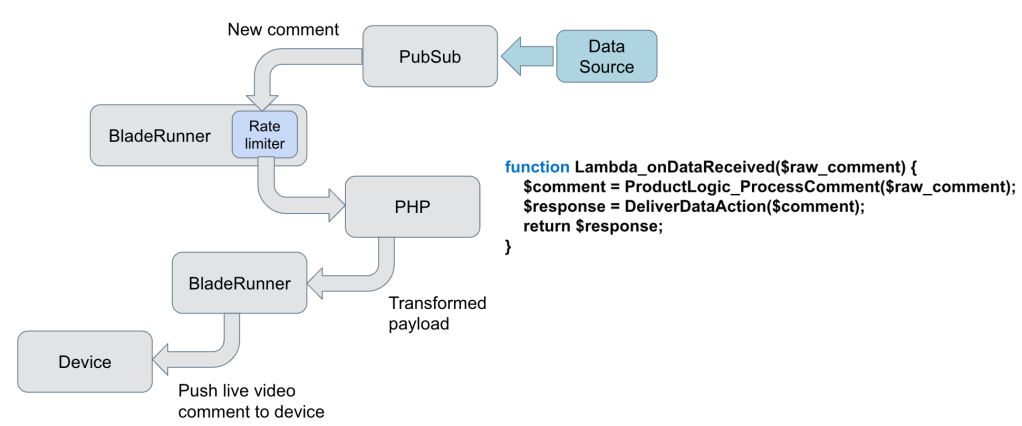
The publish path starts with a live video comment sent from PubSub service to BladeRunner. If the comment passes the rate limiter, BladeRunner sends it to PHP lambda, where product logic is applied and a transformed payload is sent back to BladeRunner. Depending on the instructions from PHP lambda, BladeRunner may send the payload to the user or ignore the comment.
Future Work and Conclusion
As discussed, BladeRunner provides a set of instructions that allow product developers to deliver real-time experience to clients. The feature set that BladeRunner provides is driven by product needs, and the Real-Time Infra team expands the offerings as product demands grow. Examples of features that can be offered by a stateful service like BladeRunner include:
- Timers
Long-running timers cannot be kept in a stateless server; however, lambda functions can subscribe to timer events started in BladeRunner. In this case, BladeRunner starts a timer and periodically sends timer events to the lambda function. Lambda may use timer events for various purposes such as logging.
- Deduplication
Events arriving from the PubSub system can be deduplicated before sending them to lambda for further processing. The deduplication key may be added by the PubSub service or by the application layer that generates the event and hands it off to the PubSub service.
- Skip payload transformation
Some products may not need to process the server-side events. In this case, bypassing lambda functions can make the system more efficient.
- Batching
If a stream receives many events and it is not critical to deliver every event to the client as soon as it arrives, it is possible to batch the events in BladeRunner and send them to the lambda function either periodically or when the number of buffered events exceeds a predefined threshold. In this case, batching helps to reduce network traffic and resource utilization.
- Caching
While this blog has presented BladeRunner as a service for delivering server-side events to clients, it is possible also to deliver client-side events to infra. For example, sending device logs to persistent storage is an important step in monitoring product reliability. The volume of such logs can be significant, making it inefficient to send every log to the storage system as it is generated. On the other hand, keeping logs on client devices is risky, as the device can lose its internet connection or die, resulting in the loss of critical logs. One solution to this problem is to keep a long-running connection between the device and BladeRunner and send the logs to BladeRunner as they are generated on the device. If sending every log to the persistent storage system is inefficient, logs can be batched on BladeRunner and sent to the storage system periodically. Since logs are now buffered on backend servers, there is much less risk of losing data, because server crashes happen far less frequently than client-device issues.
Overall, BladeRunner is configured to help improve product experience by providing a set of standard functionalities that are driven by product code written as PHP lambda functions. Aside from its various capabilities, BladeRunner maintains persistent connection with the client and PubSub systems, helping product developers focus on delivering real-time experience without having to deal with the underlying complexities of maintaining a stateful service.
In this framework, lambda functions receive a set of events originating from different sources such as new stream requests from clients or events from PubSub service. Lambda applies product logic to each event and returns a set of actions to BladeRunner that drives this stateful service.
Clear separation of product and infra logic is an important aspect of a stateful service driven by PHP lambdas. Such separation makes capacity management and code ownership much easier. Also, there is a loose coupling between BladeRunner and lambda function, making it easier to develop new features without worrying about backward compatibility.
Acknowledgments
The idea of BladeRunner and a distributed, stateful PHP lambda function was designed and implemented by the Real-Time Infra team. We would like to thank every member of Real-Time Infra for excellent collaboration that turned ideas into reality. Special thanks go to Tim Ryan and Sergey Volegov, who designed and implemented the initial version of this idea and helped onboard many use cases. We would also like to thank Anupama Gadiraju, Srivani Eluri, and Shilpa Lawande for reviewing the contents and providing invaluable guidance.
References
[1] Bladerunner: Stream Processing at Scale for a Live View of Backend Data Mutations at the Edge, SOSP 2021 [Available online at https://dl.acm.org/doi/10.1145/3477132.3483572]

