






Meta runs thousands of services across millions of servers and multiple data centers throughout the world. Operating such distributed systems at scale and investigating issues arising within them is no easy feat. In a world with increasing complexity of systems and ever-growing telemetry data, engineers are left looking for a needle in a haystack. And as engineers, we are used to automating tasks to assist us during investigations for root-cause analysis. However, when we on Meta’s AIOps team first started our journey to automate investigations, folks were skeptical. And rightly so. A lot of expertise goes into investigating an issue and if done incorrectly can result in a costly, time-consuming wild goose chase. Furthermore, Meta has mature observability systems that have evolved over several years and that our engineers are already used to. We need to build an investigative solution that can meet our engineers where they are, instead of creating new systems from the ground up.
In this blog post we will outline our multi-year journey towards accelerating investigations and driving down the MTTR (Mean Time To Recovery) for incidents at Meta. We will delve deep into the technical aspects of the three foundational systems developed by Meta—Automated Runbooks, Analysis Algorithms Service, and Event Isolation—and how they have been used to speed up and streamline key investigation challenges across several domains in Meta.
We’re openly sharing these ideas in the hope that the broader engineering community can leverage them as a blueprint to improve the reliability of their own systems.
Breaking down investigation gaps
When we set out to improve our investigations infrastructure in early 2021, our on-calls were struggling with a few fundamental challenges:
- Too much disconnected data: At Meta, we have robust observability infrastructure that collects a wide range of operational data and telemetry across our entire fleet. Observability infra at Meta has grown organically, however, and across the different observability data we generate, there is no shared metadata. A user can not plug in a service name and discover all the data for a service at Meta.
This results in a large number of time series, high-cardinality dimensional metrics, logs, distributed traces, and events that engineers must manually analyze during high-pressure SEV (SEV is Meta’s internal term for a critical incident) scenarios.
- Bottlenecks caused by too few experts: With a large amount of observability data, debugging expertise is often required and gets limited to a few subject-matter experts (SMEs) in the domain. These SMEs can become bottlenecks during investigations and may feel overwhelmed themselves. There is no easy way to transfer their knowledge and expertise to other team members, making it difficult to federate this knowledge across the broader team.
- On-call toil: This is a significant issue, as it is unsustainable for engineers to manually investigate and identify all root causes of the dozens to hundreds of incidents that occur during their rotation. As a result, many of these incidents go uninvestigated and unresolved. To deal with this situation, teams across the company had built diverse investigation workflows. We needed a strategy to help meet the users in their existing workflows.
Diving into the system architecture
To address the challenges engineers face, we developed three foundational systems aimed at providing a generalized solution for all on-call teams at Meta. Our focus is on creating platforms and experiences that seamlessly integrate with existing user workflows, rather than introducing new ones.
Foundation 1: Automated Runbooks

We built Dr Patternson (a fun portmanteau of Pattern-matching and Dr Watson, a beloved Sherlock Holmes character; aka Dr P) as a system for experts to encode their knowledge into executable investigation runbooks—to be used by experts and non-experts alike during investigations.
To streamline the authoring of these executable runbooks, we developed an SDK that included simplified APIs to access data from internal telemetry systems, ML algorithms to quickly analyze and correlate this data to generate findings, and an easy way to visualize results. Dr P runbooks offer all the richness of Python-based authoring and declarative APIs to quickly codify a manual or wiki-based,on-call runbook into a powerful automated investigation workflow, with rich UI visualizations.
Dr Patternson platform: To make it easy for users to seamlessly onboard automated runbooks for their team, we also built a fully managed platform where users can host these executable runbooks. The Dr P platform takes care of deploying runbooks, monitoring and alerting issues, and orchestrating these runbooks for automated or interactive use cases. As pictured below, the Dr P platform natively integrates with Meta’s detection platform. User-configured runbooks are automatically triggered whenever an alert fires, and the result is available right in the alert UI when the engineer investigates the issue. Additionally, users can manually trigger these runbooks from a dashboard or UI to analyze an anomaly. And along with all these features we’ve described, we have a flexible post-processing layer that runs customizable user actions on top of the output produced by the runbook.

Foundation 2: Analysis Algorithms Service

With Foundation 1 (Automated Runbooks) in place, we still had an open problem around analyzing large amounts of observability data at Meta. To tackle this problem, we developed a set of scalable and efficient ML algorithms, including fast dimensional analysis, time series analysis, anomaly detection, and time series correlation. A major challenge with these algorithms is leveraging them in real-time, latency-sensitive investigations. We built a pre-aggregation layer on top of existing data, with which we were able to reduce our dataset size by up to 500X and significantly speed up analysis.
Next we built an analysis algorithms service that hosts these algorithms and returns insights to users in just a few seconds. This service is callable from any Dr Patternson executable runbook as well as from some of our most visited dashboards and UIs, allowing users to quickly analyze time series or other datasets and generate findings directly in the UI. This saves users the trouble of having to manually inspect dashboards with a large number of widgets and helps them navigate to the most important data quickly.
Foundation 3: Event Isolation Assistance

Now that we had built solutions to tackle some of our engineers’ key challenges, we took a step back to see how we could double down on accelerating our most critical incident investigations and reducing on-call burden in those scenarios.
In 2022, the Reliability Engineering team at Meta conducted an analysis of our worst critical incidents (internally called SEV0, SEV1, and SEV2, with SEV0 being the most severe). While SEVs can have multiple root causes, the chart below shows a breakdown of the key root causes. As can be seen, more than 50% of incidents were attributed to code changes and the deployment of config changes.
We developed an investigation-assistance system that ranks thousands of events at Meta to identify the root causes. The system focuses on config-based isolation and also includes code-based isolation for specific use cases. For Event Isolation we built ML-based ranking models. These ML models leverage signals like text matching, time correlation with alerts, and context around on-call to rank events with high and medium confidence. On average, this approach filters out 80% of the uninteresting events during an active investigation; it ranks the most probable suspicious events for the on-call engineer. The system provides annotations explaining the ranking and confidence, making it transparent for engineers. It can be easily embedded as a widget in the Dr P runbook. Below is a screenshot showing this in action:

Guided Investigations
Fully automated investigation workflows are great for quickly identifying potential root causes of issues. However, sometimes additional context from a human expert can be helpful in guiding the flow of the investigation. This is where decision trees come in. A decision tree provides a step-by-step workflow that enables investigators to progressively narrow down the root cause of an issue. By combining automated investigation workflows with additional context from human experts, decision trees can help quickly investigate complex issues in cases where fully-automated solutions would have been insufficient.
Just like the other tools mentioned above, guided investigation trees integrate natively with our detection systems and are available for our on-calls to use, right where they need them. Here’s a sample snapshot of one such guided investigation notebook attached to an alert for a Tier 0 on-call, Ads Manager:
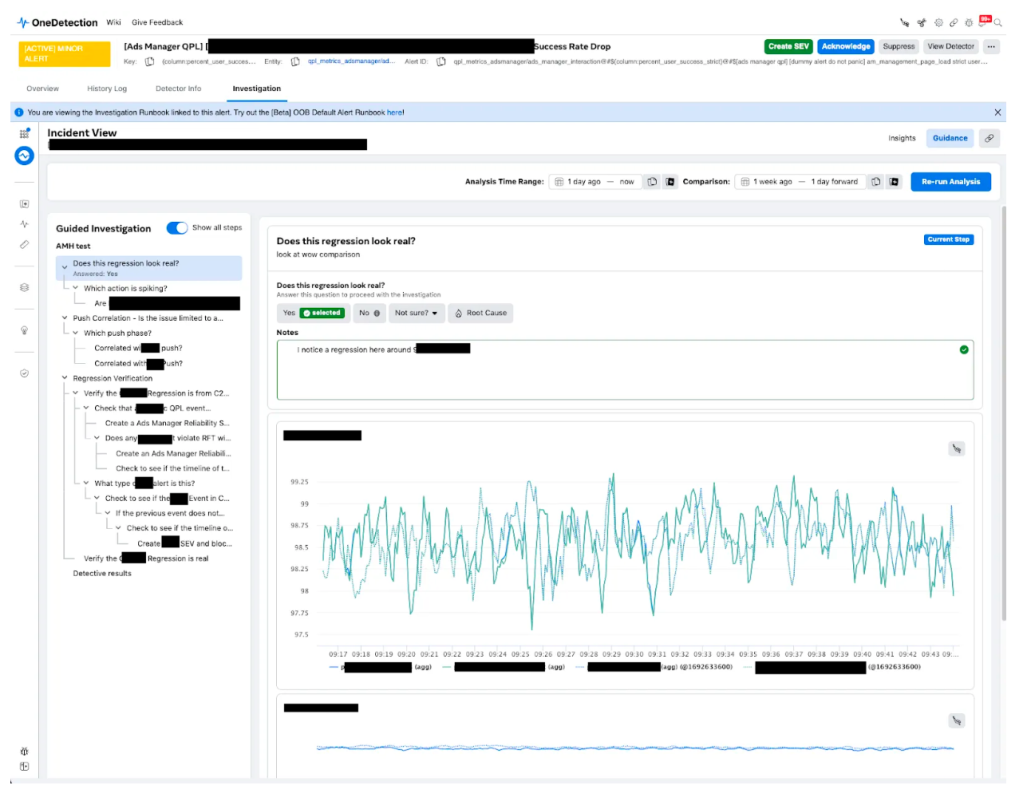
Current state of Investigations at Meta
So where are we today? Over the last two years, the foundational systems we described above have become hugely popular, with hundreds of teams quickly adopting them internally. Today we run more than 500,000 analyses per week. Leveraging these foundational systems during critical-alert investigations has been correlated with an approximately 50% decrease in MTTR for critical alerts across the company.
We’ve also observed many reliability success stories across different domains. Below we describe some of these.
Ads Manager Example
Ads Manager serves millions of monthly active business and advertising customers. In the first six months of 2021, the team experienced 100 SEVs, including seven downtime SEVs. This unsustainable situation highlighted the need to prioritize investigation and resolution of these SEVs as quickly as possible to minimize business impact.
We onboarded Ads Manager to several of the systems mentioned above; Ads Manager leveraged Dr P and was able to codify several of their manual investigation steps into these runbooks and prevent overload on a few experts. Their automated runbook codified almost 50% of what had previously required manual investigations.
Ads Manager also leverages our Event Isolation to accelerate mitigation for their most critical class of SEVs—downtime issues. Just recently a widespread downtime outage was resolved in under an hour by pinpointing the problematic change, thus preventing a much wider outage.
Overall, Ads Manager has seen their investigation MTTR improve from order of days to order of minutes.
SLICK example
SLICK is a dedicated SLO store with centralized SLI and SLO definitions. (For more on SLICK, see the engineering blog, https://engineering.fb.com/2021/12/13/production-engineering/slick/.) Service owners at Meta leverage weekly reports and SLICK dashboards to monitor key SLOs/SLIs for their services.
SLICK has integrated with Dr P such that SLI violations will trigger a Dr P automatically. Dr P will then automatically add root-cause annotations for these violations. This can help with on-call handoffs, reviews, and categorizing the most common violation causes. These annotations are displayed in SLO/SLI dashboards and quickly highlight the key insights for service owners.
ML Monitoring example
AI/ML workloads have scaled up significantly at Meta. These AI/ML workloads often have different characteristics from our traditional microservice-based architecture. An issue in the workload could be caused either during the training or inference phase, and there are several complex and confounding factors that could contribute to a topline anomaly. The following is a hypothetical example of the complex debugging steps an ML engineer might need to take to investigate an issue manually.
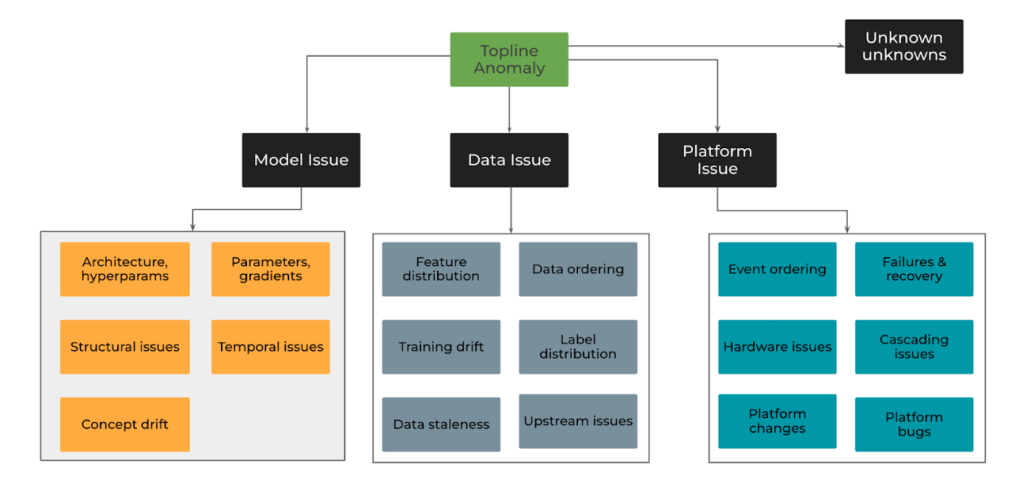
By leveraging automated Dr P runbooks and decision trees, AI/ML teams at Meta have been able to codify these complex investigation workflows into our automated or guided runbook solutions, thereby reducing a lot of toil and time complexity of these investigations.
Takeaways from our journey
Along the way to embracing AIOps at Meta, we learned a few lessons:
Data is everything: Focus on improving the quality of data and metadata in your telemetry systems.The lack of correlation between our observability systems made it much more challenging to build effective event-ranking models. We still don’t have a great solution for service dependency analysis, which limits our ability to make downstream or upstream correlations.
Automate–but also assist: Relying solely on automation can result in false positives and missed critical issues. Instead we have found that an assistive approach is better—where AI systems generate recommendations and these are further validated by engineers as required.
Focus on explainability: Give your engineers the tools to inspect and evaluate the results so they can dig deeper when needed.
Continuous learning: AIOps is not a one-time implementation; it requires continuous learning and adaptation. Our AIOps solution needed to adapt and learn from ongoing changes to provide accurate and relevant insights. Regularly reviewing and updating the ML algorithms, refining investigation runbooks, and incorporating feedback from engineers and other teams were essential to keeping the system effective and aligned with the evolving needs of the company.
Thanks to exciting new possibilities on the horizon with generative AI, our AIOps team will continue to work on developing the platform to provide more value. We are exploring how these opportunities will help us disrupt the investigation experience, for example by introducing zero-code runbook authoring or human-understandable investigation experiences. We look forward to where the next leg of our journey takes us!

