





Introduction
At Meta, we handle billions of video uploads per day across Facebook, Instagram, Messenger, Whatsapp, and Oculus. These videos can range from short clips, such as Stories and Reels, to multi-hour live broadcasts or high-resolution 360 content for Oculus headsets.
To more seamlessly process this wide range of content, we have built several technologies to simplify the process: virtual video files, FFUSE, and FUSE file systems.
With these tools, we can instantly and efficiently transfer video bytes around our data centers to provide the best possible experience for people using our apps.
In this blog post, we’ll cover the challenges of processing and storing videos at Meta Scale, how we leverage the MP4 file container format to create a virtual video abstraction to more easily manipulate video data, and lastly how we connect this all to FFmpeg—the encoding “Swiss
Army Knife.”

Videos at Meta: a brief history
Before diving into the technology, let’s take a quick look at the history of Videos at Meta. Facebook first added support for videos in Newsfeed in 2007. Video creation continued to grow as new products were built: videos for Instagram, Stories, Reels, live video. One of the key drivers to the success was DASH playback, which greatly improved video quality and playback experience.
But this improved playback experience came at a cost: increased storage.

Progressive to DASH MP4 files
Prior to the addition of DASH, videos were stored as progressive MP4 files. This type of MP4 file is what you would typically see on your phone or laptop—a single file with both audio and video stored together.
With progressive playback, there may be SD (standard definition) or HD (high-definition) quality video; however, you cannot seamlessly switch between the two. Changing from one to the other would cause some brief pause in playback.
When DASH was introduced, we began to produce both progressive MP4 files and DASH MP4 files. As with most new technologies, we needed to support both the latest clients—in this case, ones that supported DASH playback—and also the previous-generation clients, those that only supported progressive MP4 files.
As a result, we increased the number of different copies of a given video we stored over time. As DASH playback became more widely available, the amount of watch time for progressive files decreased greatly, to less than 5% of views.

DASH to progressive
While we had to continue to make progressive MP4 files available, to ensure any device could play back videos on Meta, we also wanted to reduce the storage costs spent on this older encoding type. By reducing storage costs spent on progressive MP4s, we can instead use that space to generate even higher quality encodings, such as VP9 and AV1.
To reduce the storage space used by progressive MP4 files, we built a new technology we call “virtual video files.” With virtual videos, we can instantaneously convert our DASH encodings into progressive encodings. Rather than store extra copies of a video in progressive file format, we create them on the fly, as needed.
Interestingly, Vimeo published a blog post on a similar technology very recently.

What are virtual video files?
The core idea behind virtual video files is to have the ability to take any set of frames or samples, from any set of source files, and instantly produce not a new file, per se, but a representation of the file: We know what the file size is, and we can read the file at any offset; the data itself, however, is only produced as requested, lazily.
Virtual Files are necessary for converting even multi-gigabyte DASH videos into progressive files in just milliseconds. Otherwise, trying to play back a large file would result in an unacceptably slow experience.
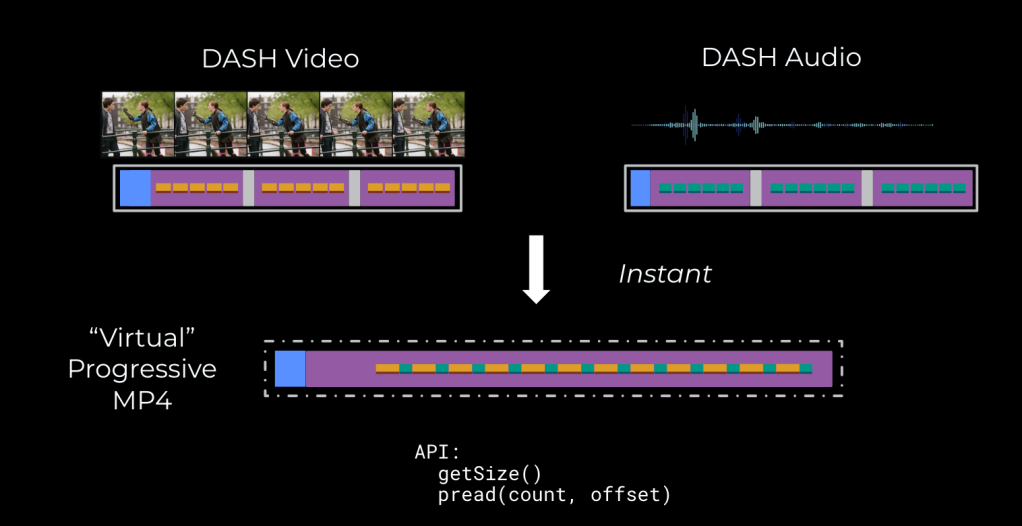
How virtual video files work
MP4 Files: A Review
To understand how virtual video files work, we need to dive into some details about MP4 files.
MP4 is a type of file format used to store media data. There are many different file formats, often denoted by their file extension: .mp4, .mov, .avi, .mkv, and so on. The purpose of a file format is to store and organize media data (including video, audio, and subtitles) in a way that is easily stored, transmitted, and ultimately played.
The purpose of a video file format (or container) is to provide organization to the samples stored within, and to the instructions needed to interpret them correctly.
A file format will typically contain information about the following:
- What is the overall video duration?
- How many tracks are there (e.g., audio, video, subtitles)?
- What is the track metadata—codec, decoder configuration?
- Where in the file are the samples for a given track?
- When should those samples be played?
An important data structure within a container is the sample table. This is a table containing the file offset, size, PTS, DTS, and flags (e.g., if a frame is a key frame) for every sample in a given track.
With the track metadata and sample tables, a video player has all the information needed for playback.

MP4 file layout
MP4 files use a tree-like data structure to organize information. The file itself sits at the root of this tree, and then nested nodes called “boxes” or “atoms” contain a hierarchy of information.
Each atom contains a 4-byte type, a size, and may also contain children. Generally the data is stored in the leaf nodes, whereas the interior nodes simply provide organizational structure.
For example, the ftyp atom, or “File Type” atom, indicates the file type. The moov (Movie) atom contains the most crucial information about the file, including information about tracks and their sample tables. The mdat (Move Data) atom contains an arbitrary blob of data, which would typically contain the raw audio/video samples.
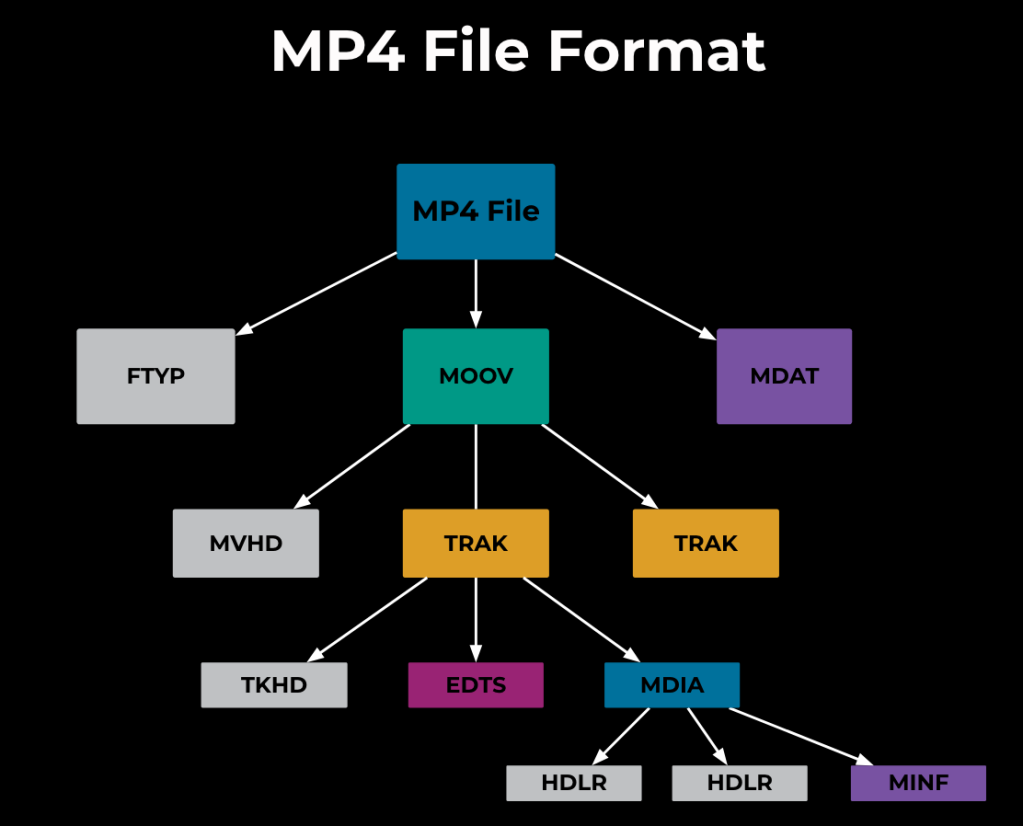
In terms of physical layout, the content of each leaf node will vary depending on its type and the information it stores. The parent nodes’ content is simply the serialization of their children. Finally, the top-level atoms are simply stored one after the other, in the file itself.
To read an MP4 file, we read the atom type (to determine if it contains children or how to parse its payload) and size (to determine the position of the next atom).

Finally, an important thing to note is that the metadata atoms (ftype and moov) comprise a very small portion of the actual file—typically less than 1% of the overall file size. This is expected, as ideally we want to keep the file-metadata overhead as small as possible.
Progressive MP4
Progressive MP4 and DASH MP4 use a different scheme for boxes and file layout to store media data.
Progressive MP4 typically has multiple tracks within the same file. This is simple and convenient, as one single file can contain both audio and video together.
The sample table is stored entirely within the moov atom. This global sample table contains information about all samples for all tracks.
Most importantly, when the moov atom is stored at the front of the file, this allows a browser to download just a small portion of the file before playback is available. If the moov atom were stored at the end of the file, this would require traversing the entire mdat atom—99% of the file size.

Fragmented MP4
Fragmented MP4 files are typically used for DASH playback. With DASH, it’s desirable for MP4 files across different representations (or qualities, e.g. 240p, 360p, 720p) to be aligned. That is, it’s best that they contain key frames in the same locations, thereby making it easier for players to switch seamlessly between qualities during playback.
As a result, fragmented MP4 files use a different atom-layout scheme that organizes data into segments, often two to five seconds each.
Rather than using a global sample table, as do progressive MP4, fragmented MP4 files use a hierarchical scheme. A sidx (Segment Index) atom contains the position and timestamp for each segment of data. Each segment begins with a moof atom (Movie Fragment), which contains the sample table for only its local samples. Therefore, to build the complete sample table, one must parse the sidx atom to locate each segment, and then parse each moof atom to locate each sample.
Lastly, fragmented MP4 files typically only contain one track—audio or video. This allows for different combinations of audio and video representations to be used per playback session, at the cost of some additional complexity.
Remuxing
Remuxing is the process of converting from one file format to another. For example, we can convert from a single progressive MP4 into two separate fragmented MP4 files (one audio, one video), or reverse the process to combine the two.
Remuxing does not alter the underlying audio or video sample data in any way; only the file layout and box scheme is changing. As a result, remuxing is an extremely efficient, IO-bound operation.

Moov Atom: The Chicken and the Egg
There is one challenge in generating a progressive MP4 file efficiently: positioning the moov atom at the front of the file. Again, having both the moov atom and sample tables at the front of the file is important, as this allows playback to start with just a small portion of the file being read.
To place the moov atom at the front of the file, we run into the following challenges:
- The moov atom must know the position (offset) of each sample and store this within its sample tables.
- The position of the samples depends on the size of the moov atom, as they are to be placed within the mdat atom.
Naively, we could first write the samples and mdat atom, track the position of each sample, and then insert the moov atom into the file. However, shuffling data in this way is terribly inefficient; it would require processing the entire input and output files before any data can be accessed. This simply cannot be done in real time.

Virtual video files to the rescue
Virtual video files solve this problem. The goal is to implement a virtual-file interface—what the file would be if we did the full remux—without having to materialize the data up front. In doing so, we can serve the file (e.g., over an HTTP server) as if it exists, but only materialize bytes as needed. Once this file is created, both reads() and stat() can be served in constant time.
Step 1: Analyze the Sources
First, we must parse the MP4 atom structure to build an in-memory representation of both the sample tables, as well as all other key metadata contained within the file. This can be represented in memory as a set of structures that can then be used to construct a new MP4 file.
At a high level, an MP4 file is a structure that contains a list of tracks. Each track contains some metadata and a list of samples. And finally, the sample table shows information contained within the list of samples: their position, size, timestamps, and flags.
One important thing we’ll also track is the file from which each sample comes. Because we may be combining samples from multiple different source files, we need to know which file to read later on when referring to this sample.

Step 2: Compute Sample Layout
Next, we’ll compute the new sample table for our virtual file. For a progressive MP4, we do this by interleaving samples in ascending decode-timestamp order. This allows a video player to fetch both audio and video samples in a single contiguous range of data.
As we lay these samples out, the result is a new sample table, with references to the original samples. We know how large the new sample layout is (the mdat atom size), and the relative offset of each sample within.
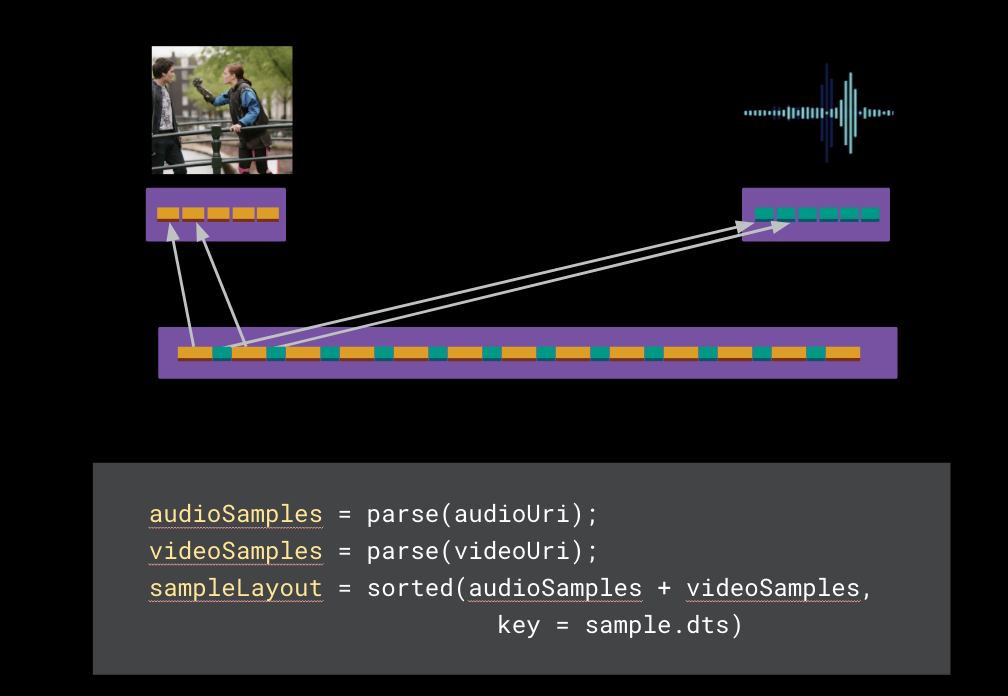
Step 3: Compute Moov Atom
With the new sample layout, we can compute a corresponding moov atom. For this new moov atom we’ll simply copy over the original track metadata, but we’ll build a sample table assuming the new, interleaved sample layout.
With some careful accounting, we now know the new moov atom size. We can then adjust the sample offsets accordingly, from their relative position within the mdat atom to their final absolute position in our virtual video file.
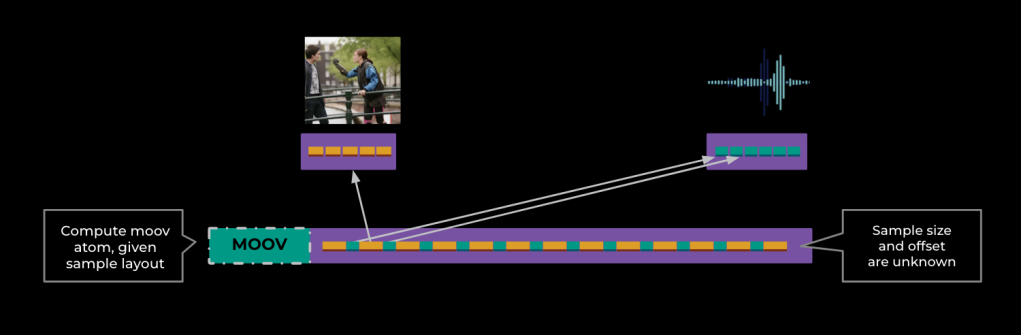
Step 4: Materializing Lazily
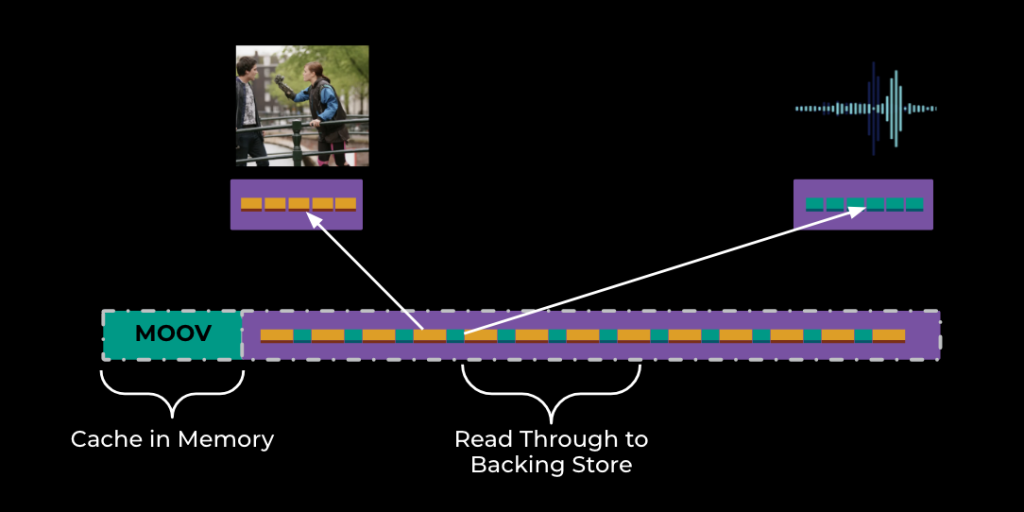
At this point, we know precisely how large our new MP4 file would be, if we were to construct it. This is simply the combined size of the ftyp, moov, and mdat atoms.
The ftyp, and moov atoms can be cached in memory or stored in a database for future use. For any read request accessing the file that overlaps with either of these atoms, we can simply serve the overlapping region from memory.
The mdat atom is never directly constructed. Instead, for any read overlapping with this atom, we’ll determine which portion of which samples are stored there, and then read that sample data directly from the original sources.
Virtual video files: API
The result is extremely powerful: an abstraction to produce new MP4 files efficiently and lazily. The new virtual MP4 file can contain any samples, from any number of sources, and can be materialized very quickly.

Use Case: DASH to Progressive
Our initial use case for virtual video files was to generate a progressive MP4 file from DASH sources—on the fly. That is, we will generate only the bytes that are actually requested by a given video player.
When we need to serve a progressive MP4, we generate a special URL that is handled by our Virtual video file abstraction. A player can use HTTP HEAD to request the file size, and GET requests to access byte ranges.
Since we can precompute and cache the virtual MP4 metadata, the time-to-first-byte for these requests can be kept low—just milliseconds.
As a result, we no longer need to store progressive MP4 files at Meta.

Use Case: Distributed Encoding
While virtual video files were initially built to remux DASH to Progressive instantly, we have found many other uses for them. Distributed encoding is one example.
With distributed encoding, a large video is broken into smaller chunks that can be processed in parallel. The outputs for each chunk are then combined together to produce one logical output. In doing so, even long videos (e.g., multi-hour live broadcasts) or high-resolution content (e.g., 8k stereoscopic Oculus) can be processed much faster than in serial encoding.
With virtual video files, this process can be done seamlessly, without any single host having to materialize the entire output file.
First, we analyze the source file to be processed and identify the key frames to be used as chunking points. For each chunk, we construct a virtual video file to refer to just those samples contained within the chunk.
Second, we can process each chunk in parallel. Because the virtual chunk refers only to the samples we want to process, we download the exact set of bytes we need from the original source.
Lastly, we can construct one more virtual video file to combine the results of each chunk. This video file can make the disparate chunks, stored in different locations, available as one logical, final output.

FFmpeg, FFUSE, and FUSE
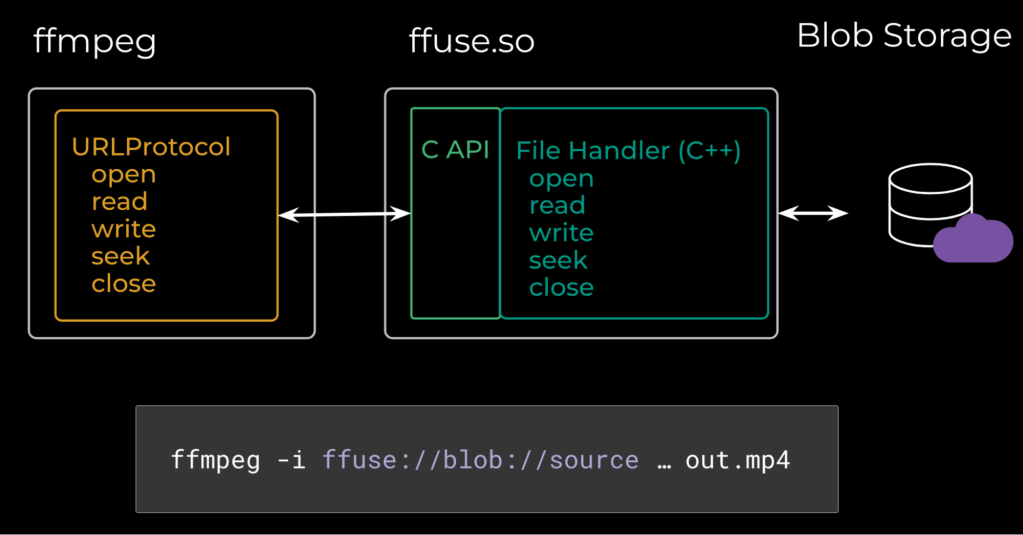
Virtual video files are a powerful abstraction to enable us to access video data, but one more tool is needed to make them easy to use—we need a way to connect virtual video files and Meta’s internal blob storage systems to the Swiss Army Knife of video processing, FFmpeg.
For many years now, Meta’s answer to this problem has been FFUSE, which gets its name from the Linux Kernel FUSE, or “Filesystem in User Space.” Much like FUSE, the idea is to have a custom file protocol that can be used by FFmpeg but written outside of the FFmpeg source tree itself. The result is a relatively stable, unchanging piece of code built into FFmpeg and an external file handler implementation.
Much like FUSE, this lets us quickly iterate on the file-protocol implementation, in any programming language, and release updates separate from FFmpeg itself.
To do this requires three pieces of code:
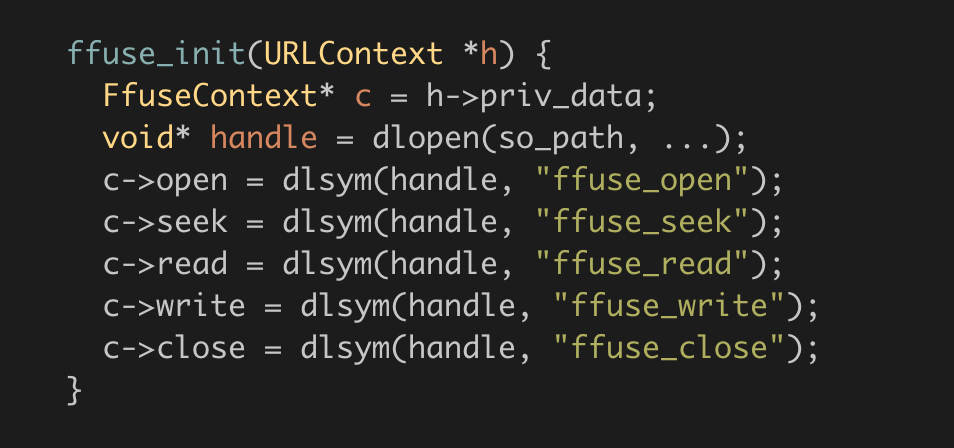
First, a URLProtocol implementation built into FFmpeg. This URLProtocol handles all ffuse:// URIs.

Second, the URLProtocol simply loads a shared object containing the true implementation for each file operation, and proxies the requests:
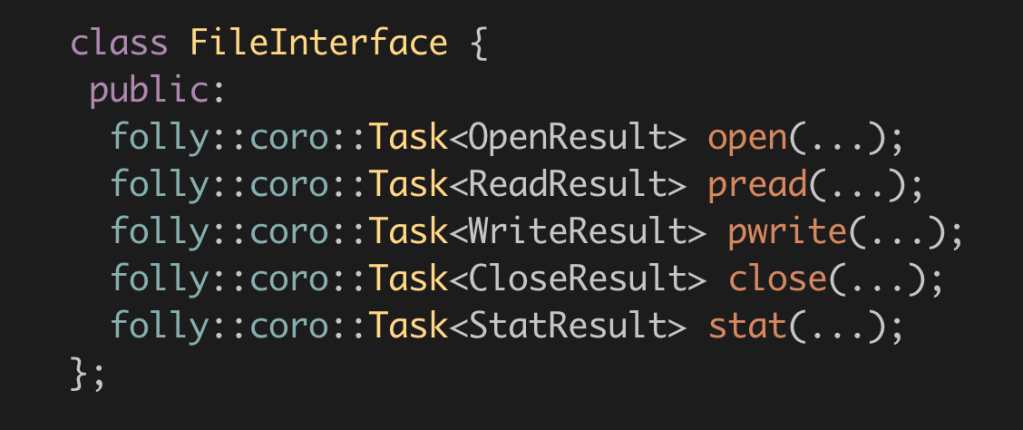
Finally, the true implementation for the file handler interface is provided in any language. At Meta, we use C++:
Putting this all together, we are able to directly connect FFmpeg to both virtual video files, as well as our own internal custom-blob stores.
The future: FUSE
While FFUSE has served us well for years now, FUSE proper is our new long-term direction.
Building a FUSE filesystem has a fairly steep up-front engineering cost, and when things go wrong, they can go terribly wrong. Avoiding process hangs, file system lock-up, poor quality of service, and hard-to-debug errors requires a fair amount of care and planning. We initially built FFUSE for these reasons—it provides a much tighter integration with FFmpeg and much simpler, easier-to-understand failure modes. A known devil is better than an unknown angel.
However, FUSE proper offers many advantages over FFUSE:
- Interoperability: FUSE works with any binary, not just FFmpeg / FFprobe.
- Kernel Page Cache: FUSE can fully utilize system memory, in a safe and reclaimable fashion. In typical scenarios this offers more optimal caching and performance.
- Simplicity: With FUSE, everything is a file. This offers simplicity and flexibility in building out new use cases, reading inputs, and writing outputs. This can be a double-edged sword, hiding the details of IO behind another layer of abstraction, but is offset by increased developer efficiency.

Recap
Working with videos at Meta is both a fantastic challenge and source for inspiration. Out of the need to reduce storage costs, we’ve built technologies such as virtual video files and FFUSE that make the rest of our stack simpler, more efficient, and more agile. By investing in tooling and abstractions like the ones described in this blog post, we can solve ever more complex problems—and so can you!

