





We will be hosting a talk about our work on Virtualizing Consensus In Delos For Rapid Upgrades And Happy Engineers during our virtual Systems @Scale event at 11am PT on Wednesday, March 17th, followed by a live Q&A session. Please submit any questions you may have to systemsatscale@fb.com before the event.
When the Delos project started in late 2017, we aimed to create a new storage system for the Facebook control plane. Our first use case required a database with a table API. However, we needed to eventually support a range of other APIs (such as ZooKeeper).
To rapidly implement and deploy Delos, we leveraged the novel technique of virtual consensus, where multiple copies of a database are kept synchronized via a VirtualLog abstraction that stores and orders commands. The VirtualLog itself is layered over different consensus protocols called Loglets and can switch between them, allowing Delos to change its consensus subsystem without downtime.
Virtual consensus allowed the first Delos-based database (DelosTable) to reach production using ZooKeeper as its underlying Loglet. In a sense, we used ZooKeeper’s tried-and-tested consensus protocol while supporting a table API on top. Later, we switched DelosTable to a custom-built NativeLoglet protocol for better performance and to remove ZooKeeper as a critical path dependency.
However, the ultimate goal of Delos was not to build yet another single, monolithic database with a fixed API. Instead, we wanted to enable a range of databases with different APIs, so that applications could select the API best suited to their needs. Concretely, our next immediate task was to replace the ZooKeeper service at Facebook by building a second database exposing the ZooKeeper API. In doing so, we had to scale Delos: not just in the usual dimensions of throughput or capacity, but in terms of the engineers working on the codebase who needed to understand, extend, and operate Delos.
Abstraction makes engineers happy… right?
To scale the development and operation of multiple databases, we designed Delos as a platform for building databases. Each Delos-based database (such as DelosTable) consists of a thin layer of API-specific code running over the Delos platform. The platform provides support for common but complex functionality such as consensus, local storage, backup, etc. As a result, building, deploying, and operating new databases with custom APIs is vastly simplified: much of the code and operational tooling between databases is identical.
Such a separation allowed the ZooKeeper team at Facebook to start implementing a ZooKeeper clone (called Zelos) over the Delos platform. In principle, the ZooKeeper team could focus on implementing the complex ZooKeeper API as a Delos database and migrate its customers. The DelosTable team could similarly focus on satisfying use cases that required a Table API. Meanwhile, a Delos platform team would continue to improve low-level code for consensus and storage to obtain better reliability and performance. Each team could focus on its own goals and core competence while amortizing the cost of developing and operating a complex service. In other words, we would have happy engineers!
However, we immediately ran into a number of challenges. While the large majority of the code required by Zelos was identical to DelosTable, it still required a degree of customization. For example, ZooKeeper requires a session-ordering property from its ordering protocol stronger than any other system. In other cases, the Zelos team required changes to the platform (for example, batching support to match ZooKeeper performance) and were blocked on the Delos platform team’s cycles. Somehow by linking together these different teams via a single codebase, we ended up with unhappy engineers.
Virtualization saves the day… again!
“Use a good idea again.” — Butler Lampson, Hints for Computer System Design
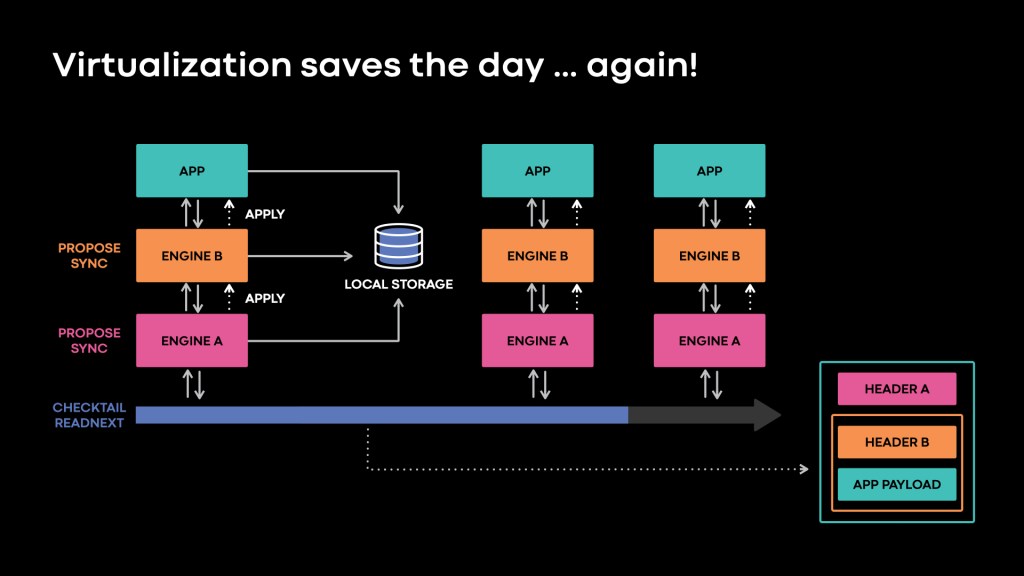
To break this logjam, we invented an abstraction called a log-structured protocol: a protocol layered over the VirtualLog. Each protocol consists of a log-structured protocol engine (or just engine) executing on each end-host, interacting with its counterparts via the VirtualLog. The Delos platform code is organized as a collection of such engines, each of which provides specific functionality. Each database (such as DelosTable or Zelos) can run over a custom set of these protocols.
In a sense, this approach represents a form of virtualization. Each log-structured protocol is a replicated virtual state machine over the VirtualLog. Rather than build the functionality of a database as a single replicated state machine, we modularize it into multiple, reusable virtual state machines. A log-structured protocol can only access its own partition of the local database state, enabling isolation between protocols.
In addition, log-structured protocols — as the name indicates — are also protocols that can be layered in a stack between the application and the VirtualLog. Such protocols add functionality above the VirtualLog in the same way that network protocols do in a conventional point-to-point-network. New log entries flow down the stack towards the VirtualLog, while existing entries in the log flow up the stack towards the database. As with a protocol in a conventional network stack, an engine can piggyback headers on log entries generated by ones above. It can filter or reorder log entries before they reach higher layers; and batch, encrypt, compress, or other mutate entries before they reach lower layers.
Log-structured protocols in Delos enabled multiple teams with disparate goals, customers, and philosophies to leverage a common codebase. We were able to unlock innovation by individual engineers on both teams, who could write new protocols without worrying about side-effects and interactions with other code. For example:
- We incrementally upgraded production databases without downtime simply by adding new engines. For example, the DelosTable team deployed a LogBackupEngine that coordinated the upload of the VirtualLog to a backup store.
- We reused code across databases, repurposing the production-ready stack of DelosTable for bootstrapping Zelos; for example, Zelos reused the DelosTable ViewTrackingEngine for tracking the number of durable copies of the database.
- We customized behavior for each database via specific engines. For example, the Zelos team enabled stronger session ordering guarantees by inserting an additional SessionOrderingEngine into its stack.
- We improved performance across databases by developing common engines. For example, the Zelos team implemented a BatchingEngine that worked seamlessly to improve DelosTable performance as well.
- Finally, we customized roles within each database, enabling support for passive read-only replicas that execute a stripped-down subset of the protocol stack.
Further, log-structured protocols allowed engineers on the Delos platform team to focus on the challenging “last mile” for consistency and durability; both databases immediately benefit from changes protecting the platform against corner case failures. In addition, oncall for engineers is significantly simplified by the existence of a single, unified toolchain for the two databases.
In a sense, virtualization has provided the same benefits for replicated databases as it has in other areas of systems: faster development and deployment cycles, as well as simpler operations. Innovation and impact is democratized across multiple teams and roles: any engineer can write a log-structured protocol for a new feature without needing to reason about complex failure scenarios. Ultimately, virtualization has had the most impact on the metric that truly matters: our engineers are happy!

