





We will be hosting a talk about our work on Workflows@Facebook: Powering Developer Productivity And Automation At Facebook Scale during our virtual Systems @Scale event at 11am PT on Wednesday, March 10th, followed by a live Q&A session. Please submit any questions you may have to systemsatscale@fb.com before the event.
Introduction
A fundamental issue of scale is the need to automate processes that were not previously automated. At small companies, OS upgrades can be performed by somebody walking around upgrading each machine individually. At medium-sized companies, that starts to take too long. It then makes necessary a model where updates are pushed out by some central service. By the time you get to a Facebook-sized fleet of machines, not only can you not afford to upgrade each machine manually, you can’t afford to manually monitor the automated process for failures. Automation is required to process your automation. So the automation gets deeper. It also grows wider as more developers start to automate more processes. Most of this automation involves coordinating work across multiple machines. As a result, whether they know it or not, more people are writing distributed systems, leading to an increase in complexity:
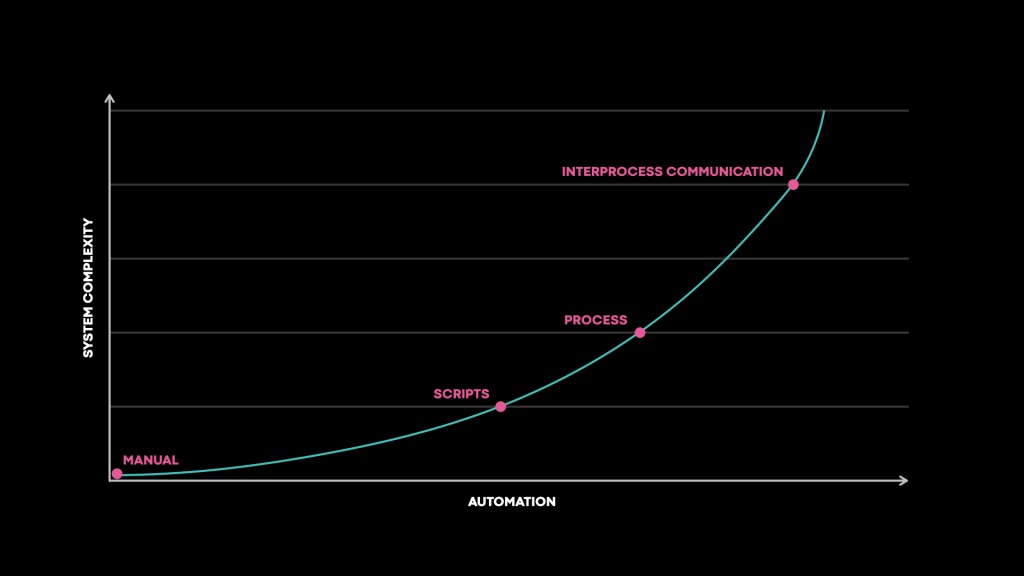
Distributed systems are complicated because they introduce a lot more things that might go wrong. What happens if one service crashes? What happens if they all crash? What happens if you want to collect logs across multiple machines? How do you handle temporary unavailability? And so on. Inside the Core Systems organization, much of our time is spent investigating these challenges. But outside, they’re usually a distraction from the business logic customers care about. So how do we help developers concentrate on their core business while reliably executing at scale? Obviously, given the title of the blog, the solution is workflows.
Workflows are a framework you can code against, allowing you to abstract away the “messy bits” of distributed systems and focus on the business logic. The fundamental notion is the separation of orchestration–deciding what to do next–and execution–actually doing it. Once that separation is clear, many useful constructs arise naturally: breaking the workflow into reusable steps/tasks, retries on failed tasks, making some tasks contingent on others, adding compensation logic in case of failed tasks, etc.
This should sound familiar. We can express workflows in a variety of ways–as a state machine, a thread/task model, or a directed acyclic graph. Most people have seen them in practice in the form of a build system, a data processor, or a planner. At Facebook, we discovered at least a dozen teams had implemented workflow systems in their products, either intentionally or accidentally. Notable examples include the following:
- General purpose workflow systems such as
1. Facebook Job Engine (FBJE), a platform to build scalable automation workflows in Python
2. CWS, Async Workflows and DAG, which we will cover in detail in this blog post as case studies - Workflow systems for specialized needs such as
1. FbLearner, a platform that enables engineers to run machine learning workflows at scale
2. Streaming Video Engine (SVE), a platform for distributed video processing at Facebook scale
3. Enterprise Workflow, a platform for building workflows to help enterprise products inside Facebook such as finance, data center products
But what we also found is many of those workflow systems were insufficient to serve as a general-purpose workflow engine. In some cases, they were insufficient for the needs of the teams that had developed them – they were missing critical features, weren’t sufficiently reliable, or didn’t scale.
In recent years, Facebook has increasingly pushed towards reliable automation for two reasons: 1) The natural effects of growth, and 2) an intentional move by Core Systems as part of two large-scale initiatives. The first is a transition from customized, team-run hardware to centralized machine management by a dedicated team. The only way to make that change and enable a single team to manage that many machines is increasing the amount of automation used to manage the machines’ provisioning, control, and decommission. The other Core Systems initiative involves simplifying service management for developers. In some cases, developers are building workflow-like systems. We’d like to provide first-class support for this model. But even if developers aren’t building workflows directly, service management still leverages workflows to manage the turnup and monitoring of services.
For all these reasons, a dedicated team tackling the workflows problems frees other teams from time spent maintaining and debugging their own workflow systems. As a result, they can focus on implementing the code they actually care about. Onward from here, this blog post discusses two products that address the general-purpose workflow problem at Facebook through different lenses. We’ll cover what we’ve done so far, and where workflows are headed in the future.
Case Study: Async Workflows and DAG
Background
Async, a widely used asynchronous job execution platform at Facebook, lets product developers write a function and invoke it asynchronously. (We will refer to a function invocation as a job going forward.) In researching customer use cases and needs, we discovered that multiple customers used the following patterns to model their complex business logic on Async by “hand constructed workflows.”
- Running n jobs in parallel, waiting for them to finish (e.g. have another job which periodically checks for others to finish), and finally running (n + 1)th job. An example use case: importing contacts for a large enterprise into Workplace.
- Recursively scheduling other jobs from a given job and managing the state across these jobs using a data store. An example use case: asynchronously processing content such as a user post.
These “hand constructed workflows” were on their own when it came to tracking state, failure handling, retries, debugging and cancellation. Some had invented ways to address these aspects. Others muddled along without them and ran into problems. While investigating other systems for similar patterns, we found the need for “workflow” processing in distributed video encoding, backfilling data in data warehouses and running test automations. All were being addressed or had plans to resolve by building one-off custom infrastructure.
The requirements common across these use cases were:
- Ability to build a Directed Acyclic Graph(DAG) representing the workflow in a decentralized way (e.g. from code scheduling the workflow, code executing workflow steps or any other code which wants to interact with a running workflow and has the workflow identifier) at Facebook scale.
- Performance in terms of millisecond level latency between processing steps for workloads like video encoding, where the end-to-end latency matters a lot for user experience.
We also discovered two customer segments for such systems at Facebook:
- Product developers who want a fully managed experience.
- Infrastructure developers who wanted to build platforms for others to use.
We assessed internal and external workflow solutions. No internal solutions met our needs without significant changes. The challenges we found with the external solutions involved making them work at Facebook scale and also integrating them with other components in Facebook infra. So we decided to build an in-house solution and built the following systems to better serve the above mentioned customer segments:
- Async Workflows offers a fully managed workflow solution on Async platform. The developer writes the functions (Async jobs), uses workflow APIs to build DAG of the Async jobs and submits them to Async Workflows to run on Async platform.
- DAG service lets users define and manage dependencies between items in Facebook Ordered Queue Service (FOQS). FOQS is a distributed priority queue service inside Facebook which offers APIs such as enqueue, dequeue, ack and nack to power asynchronous applications. DAG service builds on top of FOQS. It offers the ability to create Directed Acyclic Graph (DAG) of queue items as nodes and dependencies between them as edges. It makes queue items available for processing once their dependencies have been satisfied.
The combination of DAG and FOQS serve as a building block in other systems as a queueing and dependency management layer. In fact, Async Workflows uses DAG and FOQS as its infrastructure. (More on this below in the Deep Dive section.) At the time of this writing, around 2 billion DAGs are created in DAG service per day. Around 10 million of those are workflows run on Async Workflows.
Compared to other well known workflow systems in the industry, Async Workflows closely resembles AWS Step Functions.
Deep Dive
Async Workflows and DAG service offer similar APIs. However, while the unit of work in Async Workflows is Async jobs, in DAG, it is items in FOQS. Notable APIs include the ability to:
- Create a DAG representing the workflow
- Add nodes (representing unit of work to be performed) and dependencies among those nodes for a given DAG
- Other APIs to enable getting status, cancellation, retry, output data passing in a DAG
A typical workflow run looks like this:
- User invokes APIs provided by the workflow system to create a DAG representing the workflow instance, to add the nodes (the work items) and dependencies between them (e.g. wait for nodes A and B to finish before running C).
- User can decide to add more nodes and dependencies to the workflow in a decentralized way. e.g. when more user inputs arrive, or from the running workflow code, or a task which was delegated to an external system completes.
- At any point, the workflow system runs the nodes which do not have dependencies on other nodes in the workflow or any external dependencies. The definition of “run” here varies between Async Workflows and DAG in the following way:
- With Async Workflows, the Async jobs are run by Async system
- With DAG, the items in FOQS are made available for consumption by the processor
- As the running nodes finish, the workflow system evaluates which other nodes are unblocked (to run) based on the DAG’s current state and runs them.
- Once all the nodes finish running (or the user aborts workflow for any reason), the workflow run finishes.
To dive deeper into the DAG services’s architecture, first understanding the APIs provided by FOQS distributed priority queue is helpful. FOQS stores “items” that live in a “topic” within a “namespace.” The core FOQS API offers the ability to enqueue items, dequeue items with a lease, ack items to mark them as done processing, nack to requeue items and revive to enable items which were enqueued in disabled mode.
Here is the architecture of DAG. Note that both DAG and FOQS are thrift services:
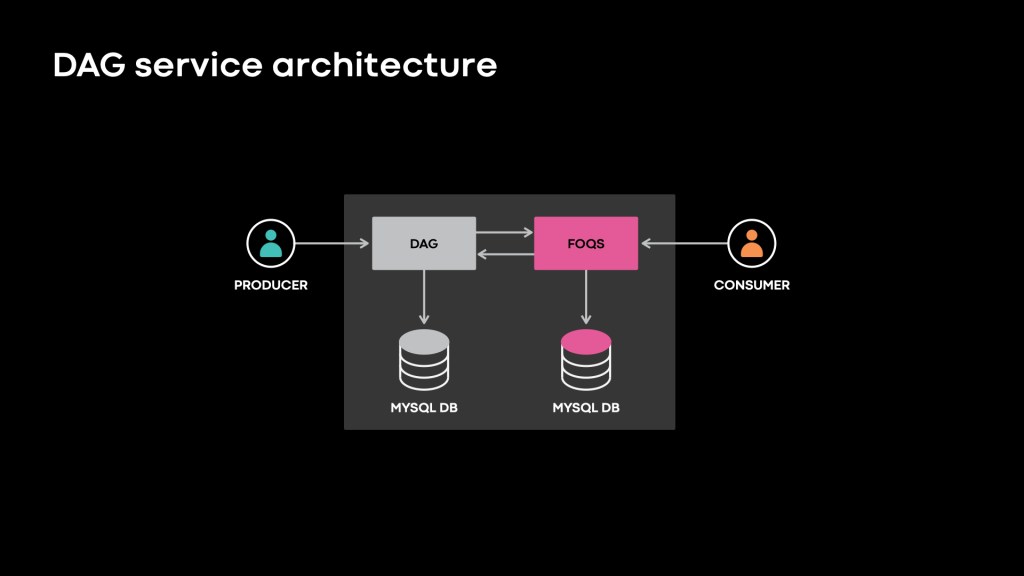
DAG service works with FOQS to power dependency management between items in FOQS.
- DAG service uses sharded MySQL databases and stores the information about the DAGs in dags, items and dependencies tables. Shard Manager assigns shards to DAG service hosts. DAG service’s reliability features guard against transient failures at database level and entire region level. They also prevent tenants from affecting one another by overusing resources.
- Initially, DAG service “enqueues” items to FOQS in a “disabled” state (ie., cannot be dequeued). The DAG service is responsible for “reviving” these items either if they did not have any upstream dependencies in the first place, or when FOQS consumers have processed all of their upstream dependencies. The “revived” items can be “dequeued” and processed by the FOQS consumers.
- In the background, DAG polls a special DAG-specific topic in FOQS to discover items that have recently been “acked.” i.e. consumers have finished processing them. DAG service then looks up the immediate children of these items, figures out if all of their upstream dependencies have been processed and if so, “revives” them in FOQS. This process continues until all DAG items have been processed. We have implemented multiple optimizations such as short-circuiting database operations, cross datacenter regional hops wherever possible to keep the latency between processing steps in order of milliseconds.
Async Workflows extends the architecture of Async as shown in the diagram below. It does so by using the DAG service and powers workflows of Async jobs, which enjoy all the benefits offered by Async around efficiency and developer productivity. We won’t delve into a lot of detail here. However, this is an example application which uses DAG service:
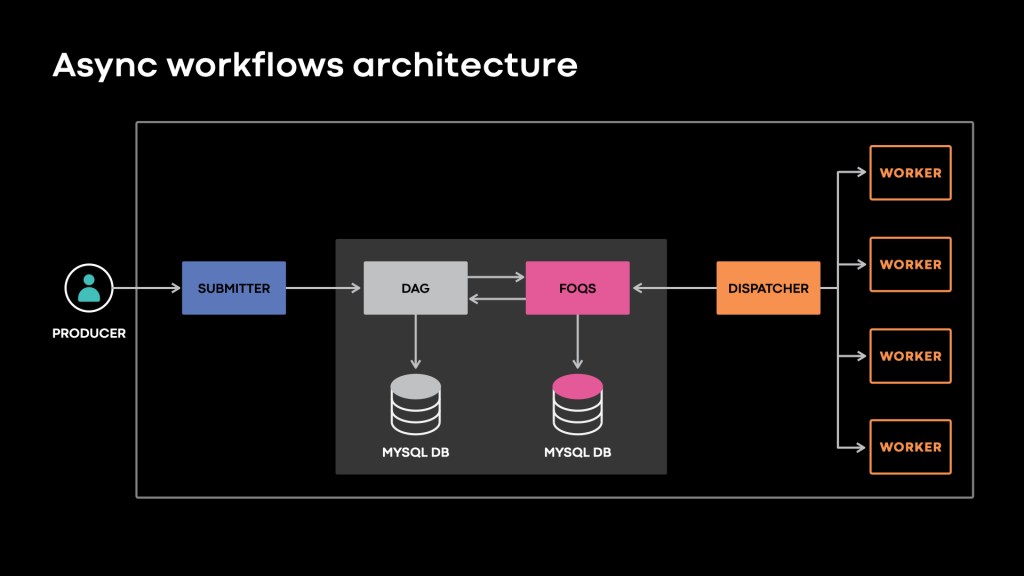
Async Workflows and DAG In Practice
We initially designed DAG service to support a large number of small sized (around 1k nodes and dependencies) DAGs and scales horizontally for such use cases. All the items and dependencies for a given DAG instance are localized in a single shard of the DAG service. This design decision limits its scalability for larger sized DAGs. Over time, customers of DAG and Async Workflows have used the service for larger DAGs by building the DAG in an incremental way through multiple API calls to add items and dependencies. We built a concept of external dependency on a node which can be resolved using an API call. This concept aids such incremental construction of a DAG in a way that won’t start processing nodes till the entire DAG is done building.
We refer to the authoring model offered by Async Workflows and DAG as the Decentralized Orchestration authoring model as it offers a programmatic way to alter the workflow structure in a decentralized way. This authoring model gives additional flexibility to the users to construct the workflow structure. It also eliminates the need to host the workflow definition code separately from its scheduling or execution code. On the other hand, it does make following the overall structure of the workflow difficult and affects its debuggability as it spreads the workflow definition code in multiple places. In the next section, let’s dive deeper into CWS’s distinctive approach on the authoring model to address these challenges.
Case Study: CWS
Background
Core Workflow Services (CWS) was originally intended to build a highly reliable system for storage control plane management, which was a natural fit to support data center automation. During early planning phases, we explored Uber’s Cadence, an open-source workflow framework inspired by Amazon’s Simple Workflow. While conceptually exactly what we wanted, the specific technologies were a bad fit for Facebook. Specifically, Cadence used Java, Go, and Cassandra, technologies not currently popular or well-supported at Facebook. Furthermore, we wanted to take advantage of Facebook’s in-house tooling for service discovery, RPC and serialization, metrics, etc. So CWS was born.
CWS leans hard into the orchestration/execution split. Customers write code for the orchestrators using their language of choice (currently C++ or Python, but we expect to add support for a half-dozen other languages) in combination with a library managed by our team. It offers primitives like starting tasks or timers, forking child workflows, waiting for external signals, etc. Orchestrators must have deterministic behavior when called with the same event history, and have limited ability to do side effects directly. In most cases, the orchestrator must create a task to request something be done. The CWS server then receives that request and schedules the task to be handled by one of a pool of executors. The executor takes in the task type and parameters and does the work. It then reports back a result to the CWS service. This may trigger the orchestrator to run again. Orchestrators are fed from an append-only event history tracked by the server with a record of each time a task is created, assigned, or finished.
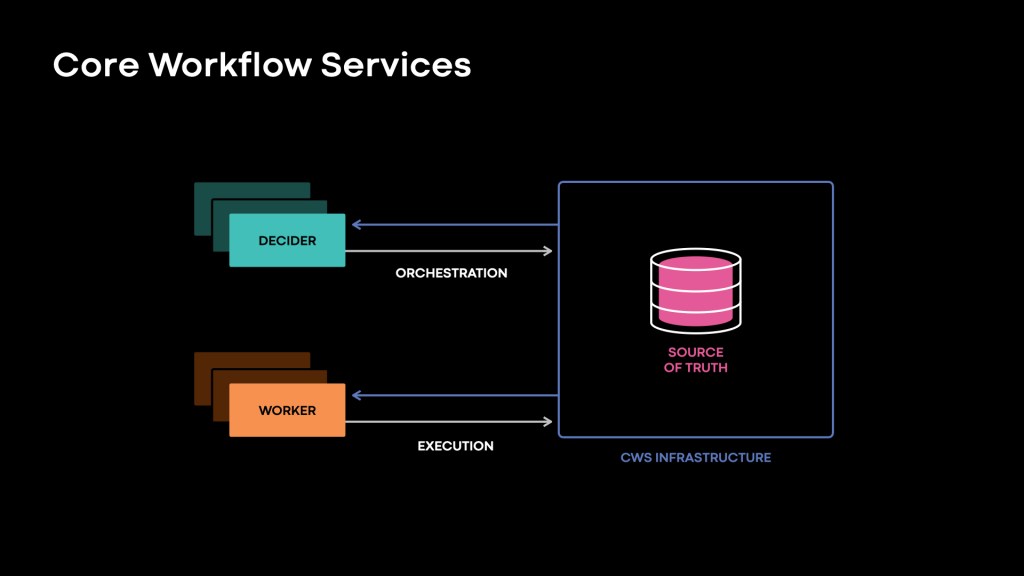
Decider Deep Dive
Let’s take a look at how deciders – the CWS term for orchestrators – work, in a little more detail. Consider this piece of decider code:
def sample_decider(args: str, ctx: DeciderHarnessContext) -> bool:
task_id = await ctx.fork(SAMPLE_TASK, “xyzzy”)
value = await ctx.join(task_id)
return value
The first time this code runs, it evaluates the first line, the fork. It checks its local cache, determines it hasn’t executed this task before, and schedules the task for execution. Then it proceeds onwards to the join and checks if the task has returned a value yet. Of course, since it’s just been scheduled, it hasn’t. At this point the decider exits, marking the current decision as finished but the workflow as a whole as waiting for more data. (At this point, the task is actually created in the system). The task runs and returns a value, which triggers the decider to run again.
This time when the decider runs, it checks its local cache and sees that the task has already been created. That means the fork call just returns the task id, but doesn’t schedule anything for execution. The code proceeds to the join. Unlike last time, now there is something in the cache. The code reads the value from the cache and returns it. This time, when the decision is completed, it also marks the workflow as completed. Once you have a handle on how this works, consider how to implement ctx.is_task_finished. We know a call has to return the same value each time to make the workflow deterministic, so is it impossible to implement this in a useful way? Consider: any particular call to this method has to return the same value all the time. However, two different calls to the method don’t necessarily need to return the same result.
While there’s a lot going on under the hood, developers don’t need to worry about any of it. They can treat this as synchronous code that blocks on joins (in fact, most people use ctx.run, which wraps the fork+join combo). Their intuition about how things work will be totally correct, as long as they follow the rules that the decider must be purely deterministic, and free of side effects.
CWS In Practice
This “centralized orchestration” model requires extra buy-in from the customer. They need to learn the features provided by the decider context, and run an additional agent to manage orchestration. But the payoff is substantial. By encapsulating the business logic for the workflow in a single, side-effect-free component, you get big wins in terms of distributed system simplicity. For instance, if your workflow has a bug in production, you can look at an automatically-generated timeline (based on the event history) to narrow it down. Then you run the decider–locally pointed at that same event history–to reproduce the issue in your dev environment. After fixing the problem, you write a test case using a framework that mocks events to allow full testing of orchestration logic. Finally, you push out the fixed code to production and add a patch event to the event history to resume orchestration on the failed workflow.
CWS has enabled a lot of customers to model complex business logic as workflows which are easy to develop and maintain. That said, we’ve identified at least two groups of customers where challenges exist:
- Customers whose workflow logic is distributed in multiple places and more naturally fits into a decentralized orchestration model.
- Customers who care about millisecond level latency between processing steps.
Our distributed video processing platform SVE is a good example which builds the workflow DAG in a decentralized way as the video uploads come in and wants to minimize the end to end latency of video processing. CWS’s centralized orchestration model and latency costs incurred don’t suit such use cases.
From a “best for the company” perspective, it’s far more important that these customers be on a standardized workflow platform versus squeezing into a difficult to work with model. So how can we solve the workflow problem for everyone? In the final section, we examine what’s next for workflows at Facebook, and how we’ll bring it all together.
Looking Ahead
Based on our research of workflow space inside Facebook, we already see that CWS, Async Workflows and DAG have more than 90% of share with respect to the number of workflows run per day. They’ve additionally seen substantial growth since they were built in the last 3-4 years. We’ve gathered these takeaways while building the above systems:
- A general purpose workflow system which enables the modelling of complex business logic greatly enhances developer productivity. Making such systems easier to adopt and use yields even more developer productivity.
- Multiple teams offering a general purpose workflow system causes developer confusion and duplication of efforts to build and run such a system. Therefore, having one team focus on workflows as a product while leveraging well-established infrastructure from other teams is a win-win situation for all, including the users of the workflows product.
Here’s what we envision for future direction:
- Build a Unified Workflow System which can support all the use cases handled by CWS, Async Workflows, and DAG and additionally support the majority of other workflow systems at Facebook.
- Have the unified workflow system leverage the infrastructure provided by Async, FOQS, DAG services.
With the unified workflow system, many details remain to be figured out, such as end to end user experience suitable for a diverse set of customers, how to best leverage the Async, FOQS, DAG infrastructure from CWS and migrating customers smoothly on to the new system. That said, we’ve already begun the initial consolidation of different systems by migrating a few other workflow systems at Facebook onto these platforms: FBJE onto the CWS platform, SVE onto DAG service and Enterprise Workflow onto Async Workflows. The lessons we’ve learned in the process are helping to shape the direction of the unified workflow system. We believe that building such a unified workflow system is a strong direction which will yield the benefits of improving developer productivity, reducing effort duplication and standardizing use of workflows within Facebook.
Thanks to all the engineers who have contributed to Async Workflows, DAG and CWS projects including: Brian Lee, Dillon George, Hrishikesh Gadre, Jasmit Kaur Saluja, Jeffrey Warren, Manukranth Kolloju, Niharika Devanathan, Pavani Panakanti, Ravinder Thind, Shan Phylim, Sumeet Bagde, Leon Cheung, Yingji Zhang, Rafay Abbasi, Maneet Bansal, Sebastian Kimberk, Stefan Larimore, Manan Manan, Brian Nixon, Akhil Sharma, Farshad Toraby, and Harani Mukkala.

