








Introduction: AI inference at Meta
At Meta, AI workloads are pervasive across a wide range of products. Some of those include Feeds, Reels, Ads ranking, and Generative AI. These AI workloads cover both the training and inference portions of the popular, deep-learning recommendation models (DLRMs) class, which power major services and applications at Meta. AI inference workload is characterized by being complex and real time with strict performance requirements (lower latency and high throughput) and model diversity.
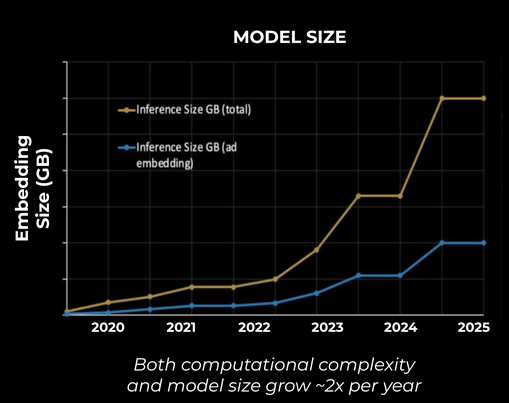
In recent times, AI inference workloads at Meta have grown rapidly in terms of model types, applications, and infrastructure footprint. Over a two-year span, the number of servers used for AI Interference has grown roughly five to seven-fold as discussed in Meta’s inference hardware paper [1]. At the same time, the inference models are becoming more complex in terms of both compute/flops and model size (two to six-fold projected growth over the next three years). Thousands of AI inference models run on thousands of powerful and expensive generic compute and accelerator machines consuming multi-megawatts of data center AI capacity.
In terms of complexity and resource characteristics, these inference models vary across a wide spectrum. There is a long tail of low-complexity, low-traffic, and low-utilization inference models. Contributing to the low utilization are factors such as provisioning for tail latency and unpredictable user traffic. When it comes to such diverse resource characteristics (including varying compute and memory requirements), one-size-fit-all server configuration becomes challenging and sub-optimal.
Enter multi-tenancy (MT), which refers to the ability to share AI hardware infra resources across a suite of concurrently running models in an efficient and reliable manner. MT offers several advantages, including improved scalability, a boost in inference-fleet utilization, and lower infrastructure cost, in terms of both capital (CapEx) and operational expenditures (OpEx).
In this blog post, we will share the efforts, learnings, progress, and future directions from our experience of zero-to-one bootstrapping of AI inference multi-tenancy at Meta scale. We will describe the journey of onboarding an important class of AI inference workloads (Ads inference) to this multi-tenant accelerator infrastructure.
AI inference hardware landscape at Meta
Meta has traditionally relied on CPU-based servers for running AI inference workloads, but the increasing compute and memory requirements of these models have pushed the company towards using specialized solutions, such as GPU and custom inference accelerators like MTIA, along with future generations of these, as shown in Figure 1.

The AI inference fleet is multi-dimensional in terms of its diverse infra-resource characteristics and the workloads (ML models) that it hosts. Each of the AI inference hardware has a sweet spot in this multi-dimensional space (see Figure 2) based on their offered value proposition.

Accelerator adoption for AI inference
Multiple factors influence the adoption of accelerators to drive AI inference workloads. As AI models grow in size and complexity, the underlying hardware needs to provide, in a super-linear way, more memory and compute, while remaining efficient. Accelerators fit the bill here. Inference accelerators are designed to be more flexible and adaptable and thus able to support a broader range of workloads. They offer enhanced scalability and efficiency as well as better performance per watt. AI accelerators complement the processing power of CPUs in data center servers.


Multi-tenancy in the AI era
There are multiple motivations behind making a strong case for multi-tenancy for AI inference workloads. MT is a prominent infrastructure lever for boosting the utilization and efficiency of the accelerator fleet. MT acts as a glue to tightly couple AI hardware with emerging AI workloads to create a cohesive infra-optimization strategy. This approach specifically suits the AI-inference applications, which are characterized by being real time, low throughput, latency sensitive, and driven by varying traffic patterns. These AI-inference models are not able to fully utilize the GPU computing resources because the diversity in model characteristics results in different resource bottlenecks and performance sensitivities. Therefore, the one-size-fits-all approach of making a single GPU more powerful is not optimal for all workloads, as it leads to inefficient resource utilization. In contrast, MT addresses these gaps by bridging application characteristics with accelerator-infra capabilities, thus acting as a harbinger of promising datacenter infrastructure CapEx and OpEx savings.
GPU multi-tenancy infrastructure at Meta
Types of GPU Multi-tenancy
When evaluating multiple MT approaches, we focused on the following four main factors:
- performance
- code change
- isolation
- flexibility
The bottom line is that workloads running with multi-tenancy should be as performant as with a whole GPU. This scenario requires that the overhead for MT be minimal. Another significant but easy-to-ignore factor is code change. The greater the number of code changes required to onboard workloads to MT, the harder it will be to get MT adopted widely. Isolation is also an important attribute, as it provides predictable performance and security, both of which are essential for cloud infrastructure. Flexibility measures the ability to nimbly adapt to versatile needs. A flexible MT solution offers more potential for optimization and simplifies management.
To the best of our knowledge, there are three common types of GPU MT solutions: time slicing, software-based MT (SMT), and hardware-based MT (HMT). Time slicing is the simplest solution to enable multiple processes to use the same GPU in turns. But considering the overhead required for context switching and that individual processes may not fully utilize the GPU at all times, time slicing could lead to fairly inefficient hardware utilization. In contrast, SMT and HMT are both solutions that support simultaneous multi-tenancy. SMT uses a software layer to dynamically merge process contexts to run as a single process, while HMT uses hardware primitives to divide one GPU into discrete sub-components with the same functionalities. Both offer great opportunities for boosting GPU efficiency—though choosing the right one for a specific setup is not easy. Here we will share our methodology for comparing the two MT solutions and our underlying reasoning behind choosing HMT for our infrastructure.
Performance and code change
To compare the performance of SMT and HMT, we use both to run the same workload with two degrees of MT, sharing each GPU with two processes, and then measure the peak throughput with a target P99 latency. This is done on a sufficiently powerful machine so that the GPU is the bottleneck resource. The end result shows that both SMT and HMT are on par with the same workload running on whole GPUs, while SMT shows 7% higher throughput than HMT. This is a considerable edge but still not enough to become a deciding factor.
Regarding code change, both SMT and HMT can be used transparently by existing applications, thanks to library abstractions from our selected vendors. Due to loose isolation guarantees, however, SMT requires an extra scheduling layer that ensures each GPU is shared by tasks owned by the same user. This leads to the reasons why isolation is one of the important attributes for adopting GPU MT.
Isolation: the key to stacking
Isolation is the key to MT, from GPU sharing to host-wide stacking. At Meta, we use Resource Allowance System (RAS) to manage containers across region-wide data centers by reservations, which represent a set of dynamically assigned servers. One ongoing effort to improve fleet efficiency is to support stacking reservations, so that multiple owners can share a single server. Each stacking reservation now instead represents T-shirt-sized server abstractions; for example, N-GB shapes for memory-bound servers and N-GPU shapes for GPU servers. Capacity for other resources is scaled proportionally by the primary resource. Such abstraction promises container boundaries similar to virtual machines without actually running VMs, which is not possible without comprehensive isolation.
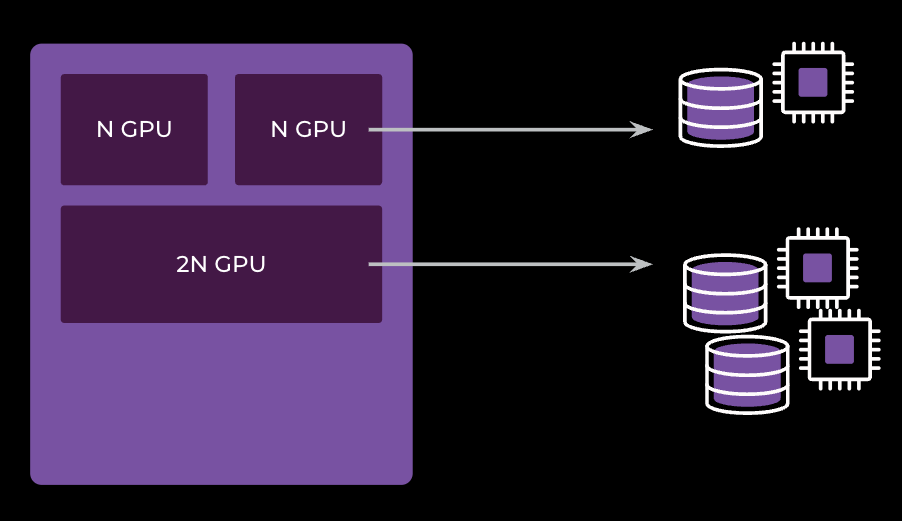
Coming back to GPU MT, SMT provides software-level isolation for memory, bandwidth, and compute, but error handling is not isolated. Whenever one process causes a hardware exception, all processes sharing the same GPU will fail. Therefore, SMT is more suitable for cooperative MT, which may not suit all workloads or require additional scheduling support. In comparison, HMT partitions each GPU into slices with statically assigned resources. Processes running on those slices are completely isolated from each other, making HMT the ideal solution for stacking environments.

Embracing inflexibility
Strong isolation does come with compromises. HMT supports a much lower degree of MT than SMT does because all resources are statically partitioned, which also means that HMT is non-work conserving. In addition, HMT can be reconfigured only when the GPU is idle, while SMT configs can be applied dynamically. However, the inflexibility of HMT turns out to be acceptable or even desirable. For example, the benefit of a higher MT degree is marginal because host resources quickly become the bottleneck when running more instances of common GPU workloads. The non-work conserving attribute of HMT naturally aligns with stacking environments, as it provides predictable performance. By tying the HMT config to reservations, the impact of reconfiguration friction is then negligible, because GPUs may remain under the same HMT partitioning for weeks until server maintenance. HMT configurations are further constrained to have host-wide, uniformed partitioning. This allows reusing existing scheduling infrastructure that assumes homogeneous GPUs per host. This scheme may leave GPUs in one HMT config unassigned while they could have been reconfigured and utilized for a different HMT setup, but the missing opportunities amortize with larger fleet size.

One complexity from reducing HMT setup frequency is that workload owners now have to be judicious about the HMT config. It boils down to finding the maximum degree of MT so that no resource is bottlenecked. In practice, there are strategies to trade off resources to further increase utilization. For example, if GPU memory is at its limit while host RAM is not, the host RAM could be shared to GPUs to resolve the bottleneck. Another example is that if host resources are the bottleneck with N degree of MT, then sharing the total resources among (N-1) workloads, by intentionally giving up one partition of the GPU, may give better utilization than using the next lower degree of homogeneous partitioning, as that number could be much smaller due to HMT limitations. There are more such examples, and we are still exploring the desired solution for taming this inflexibility as more workloads onboard to GPU MT.
The choice we made
In summary, we’ve chosen HMT as the GPU MT solution for Meta infrastructure mostly due to its superior isolation guarantees, although we have to compromise on its inflexible configuration. A key insight is that any existing infrastructure may pivot how we apply GPU MT. To harness its full potential, GPU MT should be treated as a first-class concept when developing applications, infrastructures, or even future hardware and drivers. At the time of this writing, Ads inference is the biggest user of GPU MT at Meta, while there are promising new users including generic AI inference, AI unit testing, and development environment. It is a truly exciting moment with many challenges and opportunities to evolve GPU MT technologies.
Ads inference productionization journey with multi-tenancy
Why does Ads inference care about multi-tenancy?
Ads inference is the ad-technology-prediction service that makes recommendations based on data from ad campaigns. Through modeling of various factors such as user behavior, ad performance, and market trends, Ads inference optimizes ad targeting and ad delivery to help advertisers make informed decisions about their campaigns and improve their return on investment.
Ads inference is an important class of AI workloads at Meta. The service heavily leverages the above-discussed accelerator multi-tenant infrastructure at Meta. In the sections below, we will discuss some salient related topics.
At Meta, we have hundreds of different Ads Machine Learning models serving with diverse complexity and characteristics that serve real time. Hence, diverse container shapes are necessary to boost the serving efficiency of Ads models.
How to map models to befitting container shapes?
Provided with diverse container shapes, Ads inference engineers need to find a method to effectively map models to their desired container shapes to ensure efficiency of Ads model serving, especially high-throughput and high-utilization multi-tenant infrastructure.
Ads inference service has developed an “oracle” that takes a model as input and outputs the desired container-deployment configuration. In a nutshell, the oracle relies on per-model, offline-performance benchmarking under load test to determine the maximum throughput a model can attain under performance (i.e., latency) constraints. The resulting bounding resource(s) help ascertain the right container shape to ensure efficient bin-packing as much as possible. This process is illustrated in Figure 7.

How does multi-tenancy interface with service control-plane?
Ads team uses inference platform (IP) (i.e., IPNext or shard manager) to manage the deployment of trained ranking models and provide recommendations or predictions at serving time. The inference platform uses a collection of key service-control-plane components to manage the lifecycle of models (aka shards) like load balancing, traffic routing, autoscaling, and snapshot transition. The IP framework also interfaces closely with the underlying heterogeneous multi-tenant infrastructure for E2E service functionalities.
We want to highlight one such component called shard scaler. Shard scaler executes auto-scaling functionality, where it monitors the workload demand on each model/shard and dynamically scales (up/down) model replicas as a function of traffic and manifested accelerator-metrics changes. This process is illustrated in Figure 8.

Shard scaling is an important service functionality with respect to both efficiency and reliability, since we do not want to over-provision replicas wasting accelerator resources, while at the same time insufficient replicas may overload the machines loading hot shards, causing potential service-reliability concerns (e.g., latency regression).
The impact of multi-tenancy on Ads inference
Onboarding Ads inference to accelerator multi-tenancy came with several benefits, as highlighted below:
- Capacity saving: At Meta, even at peak traffic, many Ads Machine Learning models, especially AB testing models, could not saturate a bigger container of non-hardware multi-tenancy. We observed appreciable capacity savings, depending on the model type for these models.
- Better performance: We have observed lower p99 and p95 latency and higher throughput with hardware multi-tenancy (HMT) compared to non-hardware multi-tenancy.
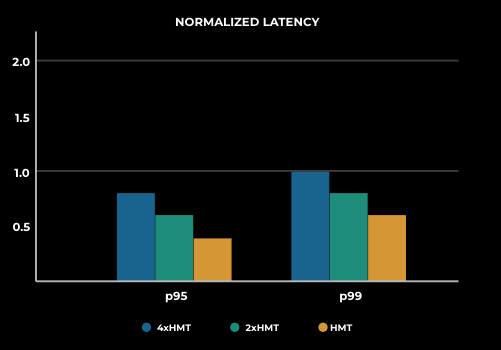
- Better resource distribution: The smaller container size of hardware multi-tenancy enables better resource fungibility through fine-grained container shapes and provides improved reliability. As shown in Figure 10, smaller containers are easier to reallocate and provide more flexibility than bigger containers.

The future of multi-tenancy
With the capability of AI inference multi-tenancy, the journey never ends. With regard to hosting more diverse model architectures, we still have many future directions to explore to bring about improvements in system efficiency, developer efficiency, and flexibility:
- New service-control plane:
- Next-generation inference platform (IPNext) will make the management of multi-tenant models easier, through providing the management capability of routing, configuration, auto-scaling, and more.
- A cooperative, multi-tenant, aware-control plane could facilitate using SMT or a more dynamic HMT in stacking-first environments.
- New hardware generations:
- Future generations of accelerator hardware types will be more performant in compute and more diverse in resource distributions. Multi-tenancy will empower us to utilize the new hardwares types with flexibility.
- Future hardware may provide different types of MT solutions and program paradigms. It should be driven by production experience to provide seamless integration.
- Better utilization hardwares:
- Currently, the uses of HMT containers are restricted for many models due to memory-utilization limitations. We are exploring offloading models from device memory to host memory, or even SSD. With such capability, multi-tenancy could achieve better service efficiency when device memory size is no longer a constraint for certain models.
Conclusions and key takeaways
AI applications are ubiquitous. Accelerators are proving to be the hardware of choice to optimally serve these emergent AI workloads. AI-inference applications are characterized by diverse model characteristics with a long distribution of low-complexity and low-traffic models. AI-inference workloads represent a unique opportunity to harness multi-tenancy in the accelerator-dominant, AI hardware landscape. Unfortunately, a one-size-fits-all model doesn’t work well for AI-inference workloads running on accelerators that are compute power horses.
At Meta, we bootstrapped accelerator multi-tenant infrastructure from zero to one, and onboarded an important class of AI applications—Ads-inference service to multi-tenancy. This has helped us reap many benefits including efficient colocation of workloads towards significant capacity savings and improved application performance through better isolation.
Acknowledgments
The idea of accelerator multi-tenancy for AI-inference workloads originated from close collaboration among Ads inference, Containers, and Capacity teams at Meta. We would like to express our gratitude to every member of these teams for the splendid collaboration that bootstrapped multi-tenancy for AI projection from zero to one. Other infra teams at Meta supported this project execution, including Tupperware, RAS, and Telemetry. Special thanks to core team members Dan Schatzberg, Dianshi Li, Zhijian Jiang, Jakob Johnson, Hao Wang, Nishant Yadav, Cedric Fougerat, Kristine Tan, Yudong Guang, Rohith Menon, Michael Fulthorp, Jon Faulkenberry, Arun Kejariwal, Shupin Mao, Rishi Sinha and Matt Arturi.

