





Additional author: Woo Xie
WhatsApp History and Scale
Since the 2015 launch of WhatsApp’s calling feature, its calling relay infrastructure has been responsible for transmitting voice and video data between users with high reliability and low latency. Starting with one-to-one audio calling, followed by video calls and then group calls, usage of WhatsApp has grown exponentially over time. The app is now one of the largest calling products in the world, facilitating well over a billion calls a day.
With such staggering scale, we encounter unique problems that very few calling products experience. We have continually developed the relay architecture to keep up with the ever-increasing demand for scale and capacity.
WhatsApp Principles
WhatsApp was built around core principles of privacy, simplicity, and reliability.
To ensure privacy that cannot be compromised, WhatsApp made an early decision to mandate end-to-end encryption for all communication, including voice and video calls. This means the relay server has no access to contents of the media flowing through it, so the relay cannot upscale/downscale, transcode, or make any other modifications to the media.
To ensure simplicity, we focus on providing non-cluttered experiences to users by focusing on and perfecting the most important features. Everything from user interfaces to server architecture follows this principle. Our custom WASP (WhatsApp STUN protocol) is one example. The standard protocol used for user devices to communicate with the relay server is TURN. TURN is a somewhat complex protocol that uses multiple ephemeral ports, doesn’t work well with firewalls, and doesn’t scale well with a distributed architecture. The core of WASP is similar to TURN, but WASP uses just one port for all network communication and relies much more on the user device to make decisions and keep track of the connection state, which works well for relay server failover.
To ensure reliability, our goal is always to make sure that anyone can make a WhatsApp call—whether on high-speed networks with the latest devices, or on flaky networks with low-end devices. We want the calling functionality to work reliably even in—or especially in—times of extreme load, because that might be when people are most in need of reaching their loved ones.
What is a Calling Relay?
Two key pieces of infrastructure enable WhatsApp users to make calls: the signaling service and the calling relay service.
The signaling server facilitates the initial process of setting up the call. It is responsible for making the device ring when called, and for connecting the call when a user accepts it.
Once the call is set up, the relay service is an essential part of maintaining the connection, and is involved throughout the duration of the call. The calling relay shuttles audio and video packets back and forth between user devices.
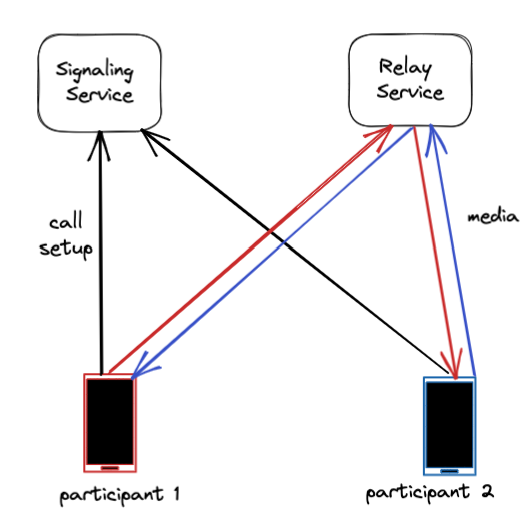
The calling relay solves some key technical challenges associated with making WhatsApp calls.
Improving Network Latency and Packet Loss
The best calls are ones where the conversation flows smoothly, without delays or interruptions, like it would in person. This is our ultimate goal for every call. Two key technical challenges can affect this sense of presence in a call: network latency and packet loss.
Network latency introduces lag in conversations and interferes with the natural flow of conversation. Latency also makes it much harder for calling algorithms to work optimally, because they end up operating on stale information.
Packet loss causes issues such as video freezes and robotic-sounding audio and can severely affect the calling experience.
Latency
The best way to improve latency is to route a call via the shortest path possible—and that means hosting the relay service as close as possible to end users.
To do this, we designed WhatsApp’s relay infrastructure to run on thousands of points-of-presence (PoPs) that Meta has set up around the world. These PoPs were originally built to serve Meta’s content delivery network (CDN) and are capable of handling the massive demands that products such as Facebook and Instagram exact on it.
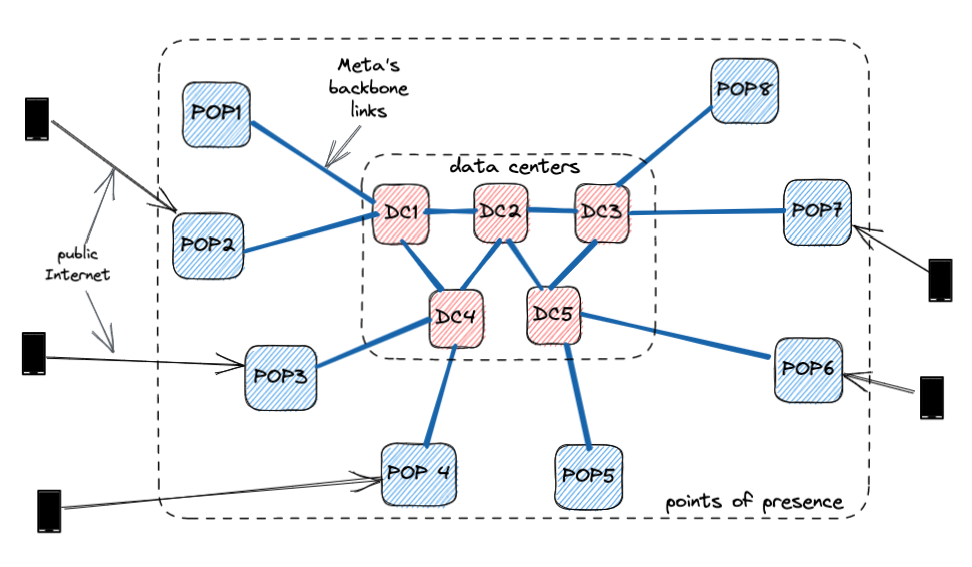
With these PoPs located in many more regions than in data centers, the relay service is much closer to end users, resulting in lower latency for WhatsApp calls. In addition, these PoP clusters are interconnected using extremely high-quality and exclusive backbone links.
It is not enough just to be close to end users; we also have to pick the most optimal cluster for each WhatsApp call. To do this we apply sophisticated targeting algorithms to historical latency data, which computes the best cluster for each call. The most optimal cluster for a call can change during a call—for example, when a user who switches from WiFi to cellular. If we detect significant changes in ongoing call conditions, we recompute the most optimal cluster.
Packet Loss
The best way to remedy packet loss is to prevent it from happening in the first place. Most packet loss arises from network congestion, and congestion is caused by improper use of bandwidth (by sending too much data), often a result of inaccurately estimating the bandwidth of a network link. So, accurately estimating bandwidth and regulating bitrate is key to preventing congestion.
Bandwidth is highly variable, however, and fluctuates during the call. Many packet loss and bandwidth issues arise in the last mile, such as in users’ Wifi networks. The relay server assists in accurately estimating the bandwidth for each leg of a call. It does so by measuring packet delay and packet loss and sharing this as feedback with user devices. Quickly and accurately estimating bandwidth helps devices adjust bitrate to reduce network congestion and packet loss.
Some networks are lossy regardless of congestion. In lossy networks, the relay service uses active packet loss mitigation. One such technique is called NACK, or negative acknowledgement. The relay server caches a few seconds of media packets and retransmits them in response to NACKs sent from devices. Retransmitting from the relay service is much more efficient than end-to-end retransmissions, because the relay sits halfway between participants in a call and reduces the latency of retransmissions. In addition, the relay is more efficient because it has the ability to retransmit packets only on links where they were lost.
Minimizing Device Resource Usage
Increased numbers of audio and video streams, especially in large group calls, leads to higher bandwidth usage. Complicating matters, mobile data plans in some countries continue to be expensive, and we cannot assume that users have unlimited data even on WiFi. Furthermore, operations such as encoding/decoding and encryption/decryption are CPU intensive, and more CPU usage translates to more battery usage. So we want to be frugal with device resources, minimizing users’ bandwidth usage while maximizing the battery life of their devices.
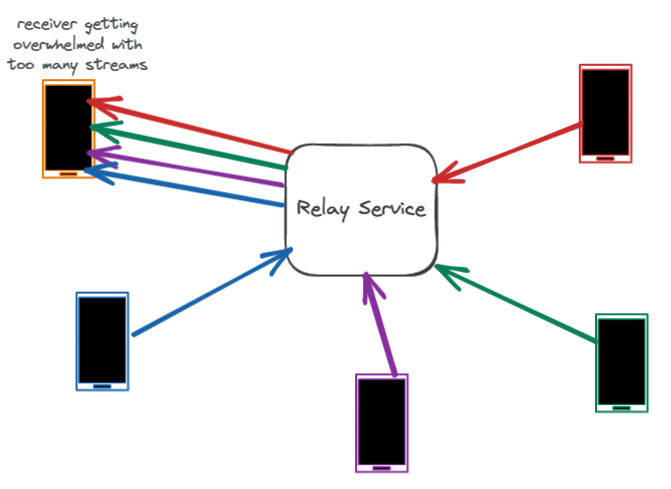
An obvious solution to conserve bandwidth in an audio call is to transmit streams only for users who are speaking. This solution is called dominant speaker detection.
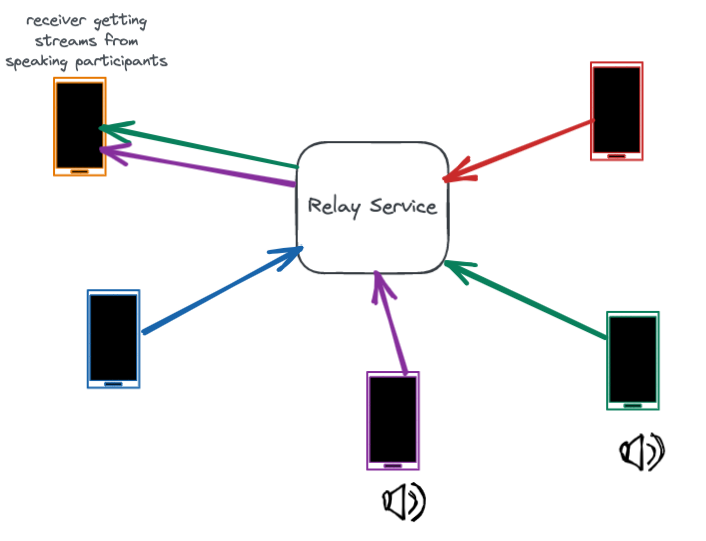
However, end-to-end encryption makes dominant speaker detection more complex, because it prevents the relay service from inspecting the audio contents and figuring out who is speaking. To solve this, the WhatsApp relay server requests volume information from user devices in a call. By sharing only volume information and not audio contents, the relay server gets just enough information to identify the dominant speaker while still preserving the privacy of the call.
There is an additional challenge with this solution: When a new participant starts speaking, there is usually a lag before the dominant speaker algorithm compares all volume levels and the relay starts forwarding audio for this new speaker. This can result in their initial words being cut off. To eliminate this lag, we allow the devices to override the dominant speaker algorithm when there is a sudden increase in volume.
Optimizing for network conditions
We want to provide users with the most optimal experience that their network will allow. Often the biggest technical challenge we face here is not in the variety of networks that the relay service encounters but in the asymmetry of network conditions on a single call.
Consider a video group call, where some users have great networks while others have poor networks. Devices on good networks transmit high-bitrate video streams, causing congestion for devices on flaky networks, and in turn causing them to have a poor experience. Because of end-to-end encryption, though, the relay server cannot access the media to be able to selectively downscale video quality for poorer networks.
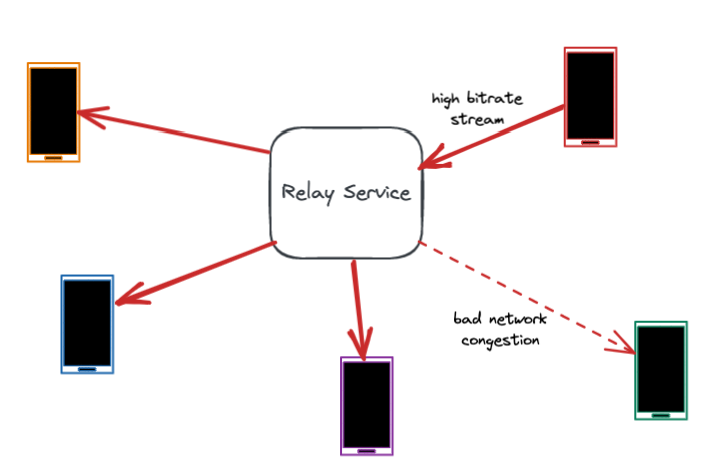
The relay server could instruct all devices in the call to lower their bitrate. This would allow the users on the poor networks to participate in the call, but the devices with great networks would receive low-resolution video, despite having a higher-capacity network that allows for a better experience.
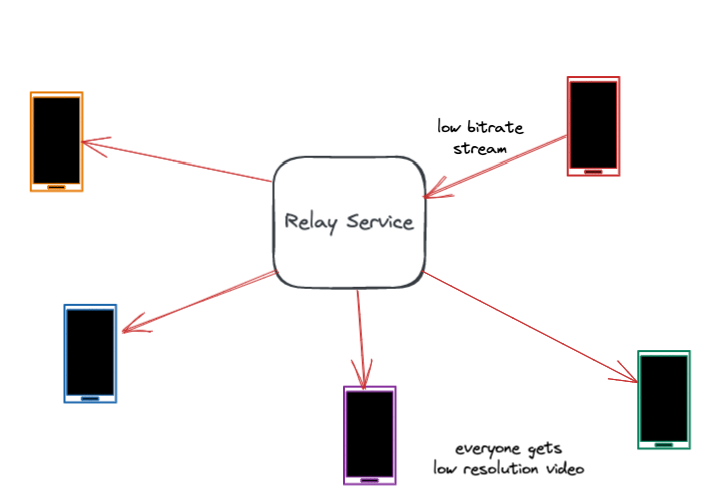
To solve this we use a technique called “video simulcast.” When the server detects a call where users have varying network quality, it instructs users on good networks to “split” their streams and send one high-bitrate and one-low bitrate stream. The relay service then selectively forwards the high-bitrate stream to the users on the good network and the low-bitrate stream to the users on the poor network.
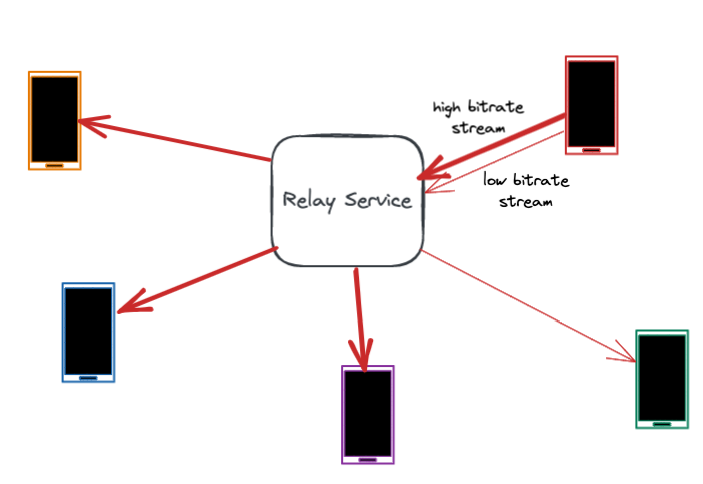
This allows all users on the call to have an optimal experience, while still preserving end-to-end encryption.
In addition to this solution, we also addressed users’ differing needs regarding video. While everyone in a call expects to hear the same audio, not everyone expects to see the same video. While most participants would likely want to watch the video of the users who are talking, others might want to “scroll” through the user list. So the server needs to “switch on” or “switch off” video for participants based on whether their video is needed or not. To achieve this, we use a feature called “video subscriptions,” where every participant informs the server about which video they are interested in. This information combined with bandwidth estimates help the relay server decide which users should be transmitting video and at what bitrate.
Ensuring scalability, reliability, and availability
Scalability
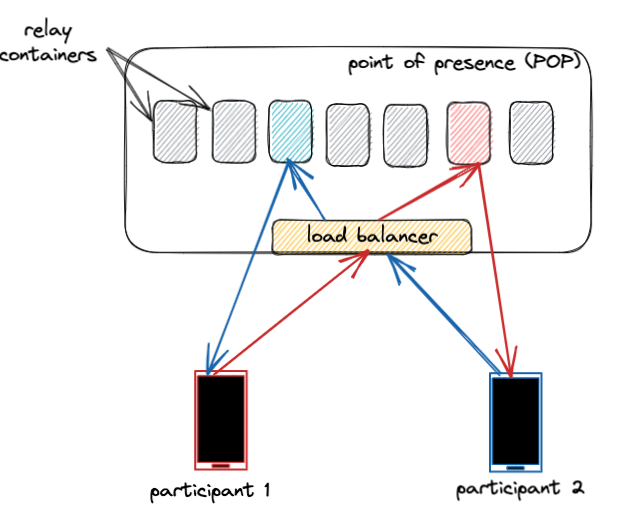
Serving billions of calls every day is no easy feat. To achieve this scale, we run the WhatsApp relay service not just on thousands of PoPs but also on hundreds of containers within each PoP.
Consider the structure of a single PoP cluster. Each cluster has hundreds of relay containers running. Individual connections are load balanced onto these containers. In fact, multiple participants in the same call are often served by completely different containers. This helps us balance the load evenly across all containers in a cluster, even though individual calls have different durations and group sizes.
Reliability
Nothing is more frustrating than a call that drops midway through an important conversation.
One of the challenges with serving calls reliably is dealing with planned and unplanned maintenance events. When calls run on hundreds of thousands of containers, there is constantly some form of maintenance going on, on at least a portion of the servers.
Planned maintenance events such as software upgrades will restart containers, while cluster resizes in response to capacity changes can take containers offline. Unplanned events such as power outages or software crashes can also cause containers to restart or go offline.
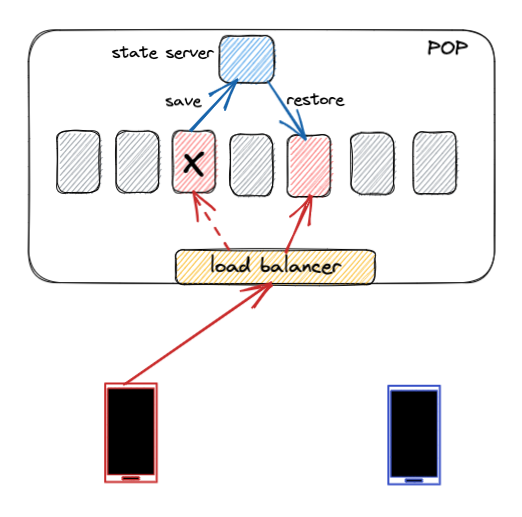
To handle these conditions, we’ve built the relay service to be resilient during failure. When a relay container goes down, the load balancer detects this and redistributes connections among healthy containers. A new container will pick up connections that were being served by the downed container. For the new container to continue serving those connections, it needs to recover all the context about those connections. This context is called “call state.”
We have two types of call state:
- Critical call state, which is critical to the call, includes parameters such as group size and device network addresses, without which the call cannot function. Examples of events that change the critical call state: a new participant joins a call, or a participant switches from WiFi to cellular
- Ephemeral call state, which changes constantly, such as bandwidth estimates and who is currently speaking in the call. An example of an event that changes the ephemeral state is when a new participant starts speaking.
We use a state server to store this state, so it can be retrieved by other containers. Critical call state is saved to the state server every time it changes. If the call state is lost, it is nearly impossible to recover from a container switch or container restart.
Ephemeral state is more forgiving. If it is lost, the quality of the call may temporarily deteriorate, but it can be recovered quickly. The ephemeral state might not be saved to the state server at all, or it might be check-pointed infrequently.
By being selective about what state we store and when, we improve the reliability of WhatsApp calls without compromising on scalability.
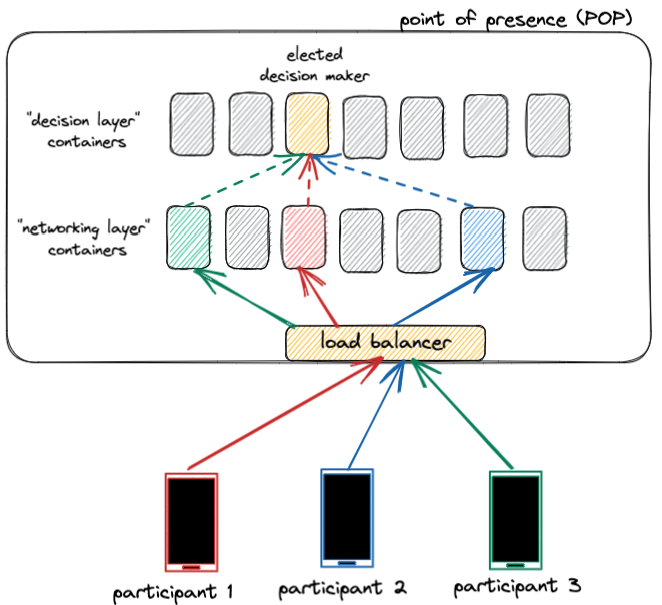
While the forwarding of media packets can be handled in a completely distributed manner, there are many centralized decisions that need to be made for every call. A good example of this is the relay server’s “dominant speaker detection,” which needs to compare audio volume levels for all participants in the call. Another example is the server’s “bandwidth allocation,” which compares bandwidth estimates for participants in a call and tells devices at which bitrates they should be transmitting. To make centralized decisions, we have split the networking layer from the decision-making layer in the relay service. The networking layer remains distributed and deals with the firehose of media packets, while the decision-making layer is centralized for each call and uses metadata updates from the networking layer to make centralized decisions for the call.
Availability
There are times when the relay service is under extreme load because a lot of people are trying to make a call. This is common during sporting events or during natural disasters, when people are trying to reach their loved ones. It is important for the calling service to be highly reliable and available at those times, allowing users to connect when they need to the most. As long as the Internet is available, we want WhatsApp calling to be possible for our users.
The most interesting “extreme event” that WhatsApp deals with every year is New Year’s Eve—and supporting calls during that event is one of the most unique engineering experiences at Whatsapp. Those celebrations are special in that they take place in nearly every country around the world, and they happen at a specific time in each region—midnight. As the clock strikes midnight in each country, we see a huge spike in calling volumes for that region. Each volume spike starts exactly at midnight, is extremely steep, and lasts about 20 minutes.
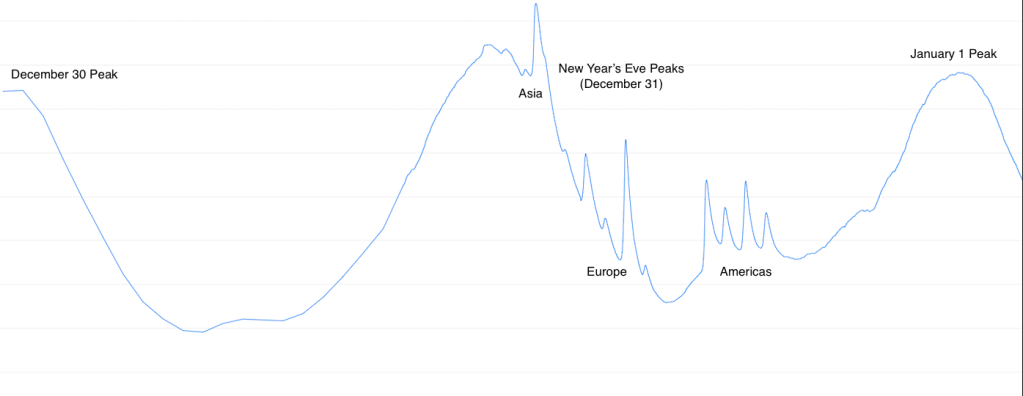
Because the spikes ramp up so quickly, there is almost nothing that can be done manually in response to an observed failure. Much of the resilience we see during extreme spikes is baked into the relay architecture.
A great deal of work to plan for availability happens in the weeks preceding New Year’s Eve. We use data science to project expected traffic in each region, and we run performance tests to measure the maximum amount of traffic the relay servers can handle.
Every year the traffic patterns change, which causes bottlenecks to shift. These shifts can be unpredictable, making projections difficult. For example, on the eve of 2022 we saw an extremely high number of group calls in Europe compared with prior years, which stressed the relay infrastructure in that region.
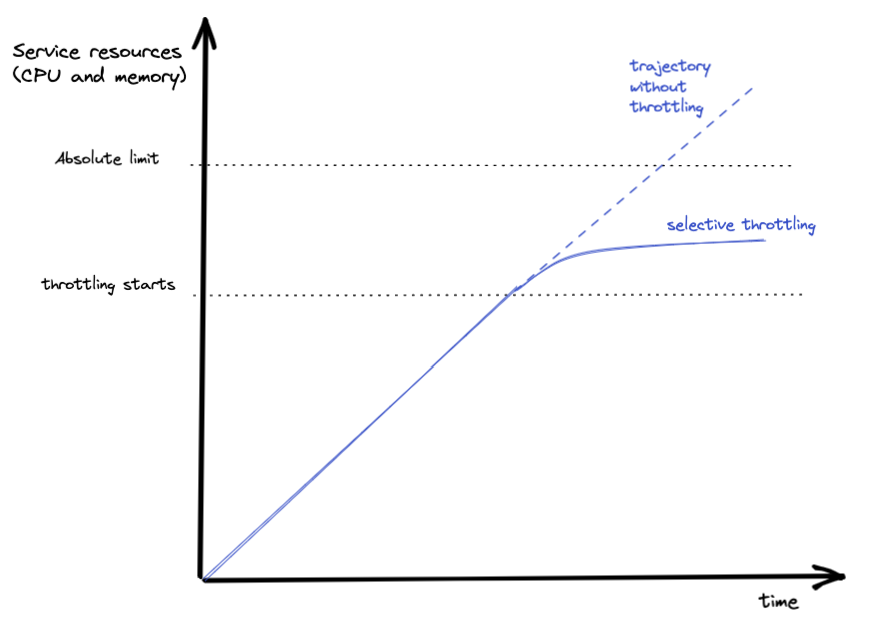
Because there is a physical limit to how many calls the relay can handle, we have clearly defined priorities and operate in a defensive way. The primary goal here is to prevent catastrophic failure and instead fail gracefully—that is, in a predetermined, gradual way, rather than all at once—in case the relay service is completely out of capacity.
As call volume increases and the relay service approaches capacity limits, resources such as CPU and memory are automatically monitored, and throttling kicks in. Our priorities inform the system about the specific order in which we allow functionalities to fail. For example, ongoing calls are more important than new calls. Our systems throttle the setup of new calls to allow the infrastructure to maintain the quality of ongoing calls. Similarly, one-to-one calls are more important than group calls.
Another challenge we face with availability is that of regional capacity. Because calling is so latency sensitive, only regional capacity matters. When we have spikes in call volume in one country, it overwhelms the capacity of local PoPs. PoPs in other parts of the world might have more than enough capacity left, but cannot be used for relaying calls because this introduces too much additional latency. Our solution here is to relocate non-latency-sensitive Meta applications and traffic to other regions, to create temporary regional capacity for real-time applications like WhatsApp calling.
Takeaways
Through our years-long experience at WhatsApp of building this relay architecture, we have gained critical insights and demonstrated that it is possible to create an extremely reliable calling product that scales to billions of calls without compromising on the privacy or quality of calls. Some of our key learnings:
- The simplicity of the relay architecture plays a crucial role in enabling high reliability, performance, and scalability.
- Each individual user’s optimal experience depends on a variety of factors such as their device and their network, factors that may vary significantly for different participants on the same call.
- While we design systems for reliability, there will always be situations in which components might fail. We need to design our systems to fail in predictable ways, so that we can prevent catastrophic failure.
- It is important to consider user needs at the heart of every technical challenge we solve and every solution we build.

