







Over the years, Meta (formerly Facebook) has evolved from a handful of small services centering around web servers to a web of large and complex services powering a rich set of user products. As we built out more regions, the scale of service deployment has accordingly evolved from single-cluster deployments to geo-distributed deployments, either because they become too big to fit into a single region or because cross-region spread is required to provide low latency to geo-distributed clients.
Managing a service across multiple geo-distributed regions incurs significant challenges:
- The amount, types, and cost of available hardware capacity varies across regions, which constrains service deployment options and can force irregular distribution.
- The deployment of services must be able to tolerate the failure of any single region, which requires the ability to quickly react to significant capacity loss and workload shifts.
- For multi-tenant services, different tenants may have different SLO requirements. For instance, some tenants can be latency sensitive while others are latency tolerant. A service needs to be deployed in a way that satisfies all those diverse requirements.
- Multi-region management requires orchestration across a plethora of cloud components, such as capacity-management systems, job- and shard-management systems, and service-mesh/routing systems.
- Last but not least, inaccurate service placement can cause mismatches between demand and capacity supply in individual regions and lead to capacity stranding and waste.
The above factors are dynamic and change over time. Thus the service-management process cannot be one-off and instead needs to be repeatable to adapt to changes.
The state-of-the-practice is that regions are exposed to service operators to manage, illustrated in Figure 1 below. They solve the problems following two approaches. The first approach is to build full-fledged, domain-specific solutions, which requires significant investment and is viable for only a few select teams. The second approach is to rely on manual management or basic scripting/automation. This is suitable for very simple services. Most stateful services fall into the middle ground—they are large and complex but have no good solutions. They experience significant operational toil to plan and change placements across regions, which often leads to reliability risks and sub-optimal capacity efficiency.
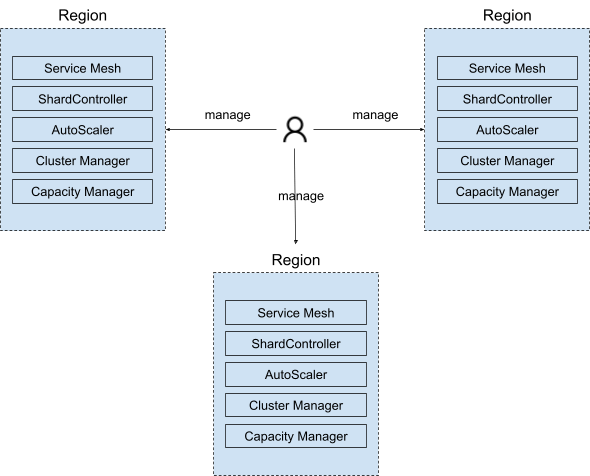
Over the past several years, this state-of-the-practice had become more and more unsustainable as the number of regions increased quickly. First, we had been pushing for higher-capacity efficiency company wide, which demanded a higher degree of deployment optimality that the existing approaches were incapable of. Second, as AI workload skyrocketed, GPU capacity was evolving quickly in terms of hardware heterogeneity and capacity skew across regions.
To meet these evolving business needs and avoid individual service owners building their custom solutions, we envisioned how to evolve our infrastructure offerings to uplevel our abstraction and provide simpler, more efficient multi-region service-management capabilities.
Vision
Historically, regions were relatively stable for services to be deployed against. As our infrastructure continues to scale, however, regions are becoming subject to more dynamic changes, like machines: They can come (region turn-up) and go (region decommission), they can fail, and their composition can change. Therefore, we want to treat regions like cattle, not like pets. Following the past evolution from cluster-as-a-computer to data-center-region-as-a-computer, our vision for the next phase of the evolution is to transform our private cloud into a planet-scale computer with regions abstracted away.
To realize this vision, we have built a core infrastructure offering called Global Service Placer (GSP), illustrated in Figure 2 below.
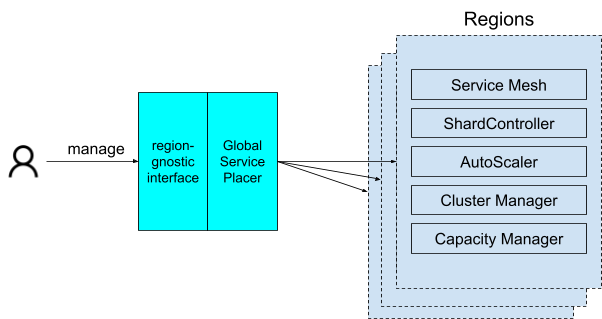
What is Global Service Placer?
At a high level, GSP is a solution that autonomously places services across regions. Instead of service operators managing region-level details, we uplevel service management from regional to global level and provide operators a region-agnostic interface where they can specify placement intents in the form of enforceable SLOs. For example, for multi-tenant services, instead of service owners specifying individual region names to achieve their latency requirements, a common latency sensitivity intent/SLO is provided to GSP for each tenant.
Terminology
In our nomenclature, a tenant is an entity that can be independently replicated and deployed by GSP. For instance, each ML model is considered to be a tenant. Each tenant replica can be sharded across multiple servers. For example, a model replica can be sharded if it is too large to fit on a single server.
GSP capabilities
GSP will globally optimize service placement to adhere to the provided intents. In the example of latency SLO, GSP will determine optimal region placement for tenants and execute the deployment plan by integrating with back-end services. This will deploy applicable tenants to regions close to client regions such that the request latency is within the SLO while considering other variables such as capacity availability across regions and more.
As part of this flow, GSP also integrates with Service Mesh to influence client-to-service routing to adhere to the SLO. Before GSP, the service mesh operated reactively by observing the service-replicas workload. With GSP, however, a service deployment plan and a traffic matrix are jointly computed to proactively ensure that traffic distribution aligns with tenant placement.
Beyond baseline placement capabilities above, GSP also integrates with the broader capacity-planning ecosystem to provide additional capabilities. At Meta, our fault-tolerance policy requires that the failure of any single region should not noticeably impact users of products hosted on our cloud. GSP optimizes service placement such that disaster readiness is achieved while honoring provided intents. Furthermore, GSP provides simulation capabilities to validate DR scenarios and surface whether any intents or policies would be violated when a region is unavailable.
Akin to region failure, GSP also provides simulation capabilities for new region turn-up/exit scenarios to surface capacity requirements in order to honor provided intents. Beyond simulation, GSP will optimize and move tenants automatically to new regions as needed to leverage new capacity and satisfy intents—or similarly, to move tenants out of a region during region exit cases.
This setup not only delivers the value of operational simplicity to service operators by abstracting away regions, it also delivers capacity efficiency by optimizing capacity usage. First, GSP determines sufficient service replication to comply with SLO without over-replicating. Second, GSP influences Service Mesh to efficiently route traffic and avoid capacity stranding. GSP also provides experimentation capabilities for operators to evaluate tradeoffs between the SLO and capacity amounts.
Additionally, because GSP is able to move workloads across regions, GSP provides operational simplicity to our infrastructure’s capacity management layers by enabling capacity planning and usage flexibility across regions. Transitively this also improves effective usage of cloud capacity by balancing capacity usage across regions and avoiding capacity stranding.
Design principles
Abstracting away regions is a daunting challenge, so we want to share the key design principles behind GSP.
First, service management involves many aspects such as capacity planning, managing fault tolerance, and configuring routing. To succeed at abstracting away regions, we need to take a holistic approach and consider how service placement interacts with other service-management aspects to pave a coherent story on global-service management.
However, adopting the new abstractions would require additional efforts for service owners. A key design principle is to focus on building a low barrier to adoption by building principled and effective integration flow for adopters by deploying a pluggable architecture customizable to different service needs.
To facilitate that, we orient our design across modularity and extensibility. Services have varying SLO and placement intents, and the requirements landscape can be fast-changing across use cases, and such a design setup ensures we are well positioned to quickly support these requirements with low friction.
Adoption
GSP has been running in production for multiple years now and is powering a spectrum of diverse stateful services, totaling tens of thousands of tenants across more than half of a million machines. Representative services include:
- Index Serving: Indexes large amounts of data from data-warehouse and other data sources with low-latency access. Social graph is one notable use case.
- Relational Database (MySQL): Hosts a variety of critical large-scale data like user and operational data for various systems. Replication factor, latency requirements, and workload characteristics vary by tenants.
- Key-value Datastore (ZippyDB): This provides several tiers of guarantees and storage offerings, ranging from efficient, single-replica setup, to global replication on local SSD, to global replication on a disaggregated storage system.
- AI Inference (IPNext): This hosts trained models and serves inference requests from user products or internal systems. This is a fast-growing platform in terms of both scale and complexity.
- Stream processing (Turbine): This messaging bus powers the majority of our streaming applications and is among the top users of cross-region network bandwidth.
Operation simplicity
The adoption of GSP has helped services to achieve both operational simplicity and capacity efficiency. GSP enables handling of cross-region changes much faster and more reliably. Below are some notable examples of GSP’s demonstrated value.
- When fleet utilization across regions gets skewed, we shift demand (primarily user traffic) across regions to rebalance capacity usage, via Flux. GSP is integrated with Flux to observe the pre-generated shift plan and proactively move tenants based on source and destination of the shift.
- During the turn-up of a new region, select services need to be moved in. GSP proactively identifies and adds tenants at scale to new regions based on what demand will be shifted to them. After the shift, GSP scales down or completely removes tenants from some other regions.
- Region exit is the process of evicting all existing workload from a region. It’s exercised when we want to physically decommission a region or run completely different workloads there. Moving a service out completely used to be a lengthy process and could take weeks. For services on GSP, we provide simulation to assess capacity sufficiency in other regions and automate tenant move-out at scale with no or low operational toil and high reliability. Service exit time was reduced to days at most.
Capacity efficiency
With GSP, capacity efficiency of services has been improved significantly. In total, GSP has helped services to produce a significant reduction in capacity usage, at the scale of hundreds of thousands of machines. These capacity savings are architecturally sustainable and compound.
Building applications with GSP
There are two steps involved in onboarding a service onto GSP to manage their service placement across regions.
- Intent-based specification: Service owners provide an intent-based PlacementSpec to GSP. Service owners leverage this to define their placement intents for each of their tenants to be managed by GSP.
- Execution integration: Service owners implement an interface to execute deployment plans with their business logic of tenant movement plugged in. They will also implement the interface for fetching input data needed for optimizing service placement.
Intent-based specification
Service owners provide GSP with a placement specification for each of its tenants managed by GSP. A PlacementSpec allows the following placement intents to be declared without dictating their specific implementation, as shown in the example below:
The key placement parameters are as follows:
- Latency threshold
Tenants specify a network round-trip time (RTT) threshold, and GSP places tenant replicas to ensure that the RTT between any client and its closest tenant replica is below this threshold. RTT is measured at the network layer, excluding application-layer request processing time, as GSP’s placement decisions can only affect network latencies. In practice, we have found that RTT thresholds typically fall into four categories: regional (1ms), zonal (20ms), continental (70ms), and global (200ms).
- Resource Table
Each tenant provides a resource table that specifies the amount of each type of resource required to serve one unit of demand. For example, the resource types can include A100 and H100 GPUs, and the resource table may specify that a tenant such as an ML model requires either one H100 GPU or two A100 GPUs to serve 100 RPS. Based on the resource table, GSP determines the tenant’s optimal mix of resource types for each region, ensuring that sufficient replicas are created to handle demand while minimizing total capacity usage aggregated across all tenants for the service.
- Request types
Tenants often have different latency requirements for different types of requests. A good example of this is data-storage services, which have read and write requests. Read requests are typically on the critical path and demand lower latencies, while write requests are less frequent and more tolerant of higher latencies. GSP’s placement policies allow requests to be classified (such as read or write) and support distinct latency thresholds for each latency class. Accordingly, demand data is categorized by these latency classes
- Placement Priority
Full allocation of all tenants all the time is not always possible. For instance, services may intentionally oversubscribe capacity, or placement constraints may be too strict. When full allocation cannot be achieved, tenant priorities are used to rank tenant-allocation priority and to evict lower-priority tenants.
Execution integration
GSP provides out-of-the-box, native-placement execution integration for two standard domain back ends that manage a domain, or for a set of tenants sharing a capacity pool.
One such domain back end is Infra Cloud Service Platform (ICSP), an infrastructure ecosystem that streamlines and orchestrates building and operating a service. ICSP provides hierarchical configurations to help service owners to manage their infrastructures at different levels. For example, a service may have multiple tenants. Each tenant is an isolated management unit with its own hierarchy of deployment groups. The leaf deployment groups are the physical deployments (depicted below in Figure 3).
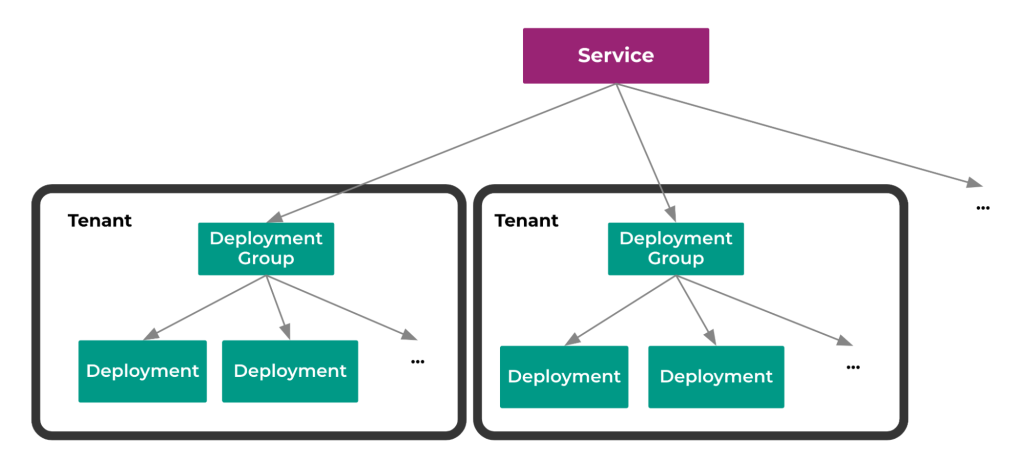
Service, tenant, and deployment groups are all configurable units. Solving tenants are often configured with their own solving constraints, and GSP is configured at the service level to solve for all tenants and their deployments. ICSP’s execution engine is a set of controllers, provided by infrastructure teams, that will materialize the infrastructure assets to their specifications.
GSP also integrates with a shard controller that deploys each tenant replica as a separate Linux container. Another domain back end is ShardManager, a generic sharding platform that facilitates efficient development and operation of reliable sharded applications. GSP integrates with ShardManager so that multiple tenants can share the same Linux container. Services deploying on these systems can leverage GSP directly by specifying the placement intents above.
GSP also supports integration with custom domain back ends. We provide a pluggable architecture that allows us to seamlessly retrofit global-placement capabilities into existing cloud systems: Users continue deploying their tenants through these systems, while GSP refines placements as needed by using a service-implemented execution interface. We describe two of those below.
- GetState()
For services not using the out-of-box native integration mentioned above, service owners implement the GetState() interface to provide the current deployment state. In particular, the deployment state is composed of critical information such as demand data for each tenant broken down by latency class, capacity availability for each region and resource, and current-tenant deployment state. This state is used along with the operator-provided intents to jointly compute the optimal service placement.
- ExecutePlan()
When a new placement plan is available, GSP calls ExecutePlan() to adjust tenant placement and update routing behavior. Service owners implement the ExecutePlan() to define the service-specific behavior for executing a placement plan. For example, MySQL implements such an interface, allowing GSP to integrate with MySQL’s pre-existing control plane.
Architecture
In this section we will dive into how GSP is built to support the functionalities described above. We will start by showing the high-level architecture of GSP.
Internally, GSP can be broken down into two key components: the placement planner and the placement executor. (See Figure 4 below).
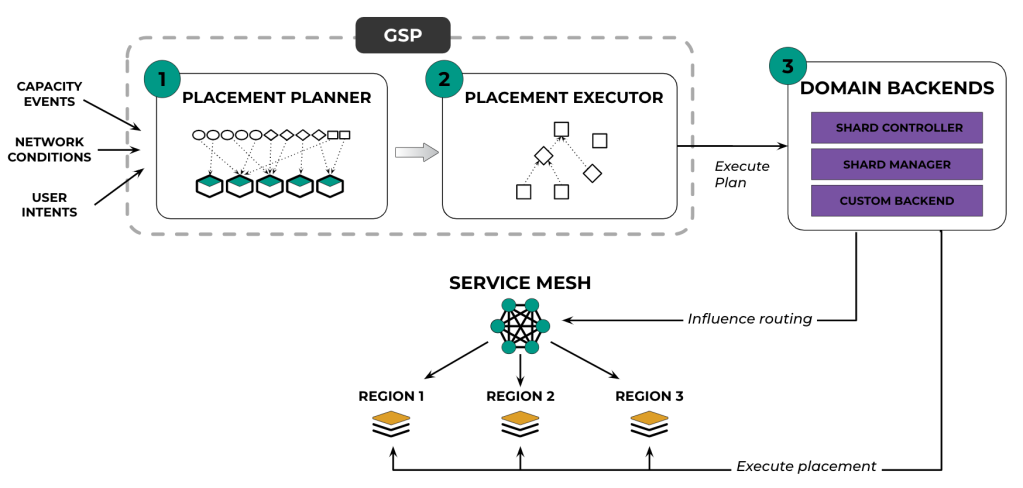
Placement planner
The placement planner is responsible for computing the optimal service placement and generating a placement plan. To achieve this, it invokes GetState() to fetch the necessary data needed for computing, such as various capacity events and capacity availability across regions for a range of resources. It also obtains user intents from the operator-provided placement spec.
Internally, this is represented as a bin-packing problem where we assign traffic for tenants (the objects) to regions and resources (the bins). To achieve this, we leverage the internal optimization Rebalancer to perform the bin packing. We formulate the user intents and the fetched data into a set of constraints for Rebalancer to solve. Common constraints are:
- demand: replicating enough tenant replicas (objects) such that demand for a tenant is satisfied
- latency: placing objects close to client regions such that latency intent is satisfied
- capacity: placing objects in regions and resources (bins) with enough room for them
Furthermore, we also build stability guardrails in placement solving to ensure churn control in tenant placement changes across optimization solves.
Assigning traffic objects to bins also generates a routing matrix for each tenant:
Map <SrcRegion, Map <DstRegion, (Preference, Weight)>
This specifies in Service Mesh how traffic should be routed for a tenant to ensure the routing aligns with the placement plan.
Placement-plan executor
Once the placement plan above is generated, it is sent to the placement-plan executor to be executed. The placement plan consists of the number of replicas for each tenant in each region, the type of resource to use for each tenant replica, and the corresponding routing matrices:
TenantPlacements:
Map <TenantID , Placement>
struct Placement:
Replicas:
Map <(Region, Resource), Integer>
RoutingMatrix:
Map <SrcRegion, Map <DstRegion, Preference>>We derive a set of placement moves from the placement plan to transition the system to the planned placement. Each move is either an upsize operation (increasing the replica count) in a region or a downsize operation (decreasing the replica count). To execute the moves, GSP invokes the service’s implemented ExecutePlan() method.
Operational safety
We orchestrate the moves into a dependency graph that captures the required execution order. GSP orchestrates the moves according to this graph, ensuring that at all times there is sufficient capacity to meet demand and that the service mesh functions properly with the underlying replica placement. This is achieved by executing tenant upsize moves first, followed by changes to the routing tables, and finally the downsize moves. As we execute the moves, we invoke the GetState() method as a feedback-loop mechanism to evaluate execution progress.
The process is carried out on a per-tenant basis; likewise, GSP adjusts placements only for tenants registered with GSP, leaving other tenants unaffected. Depending on the service configuration for GSP, it can also control the execution pace and manage double occupancy—determining how many concurrent replicas are added before corresponding replicas are dropped—balancing execution speed, safety, and temporary capacity requirements.
Case Study
Below we share a case study of how AI Inference at Meta successfully leverages GSP for global model placement.
Meta’s AI manages a set of inference models, many of which rely heavily on GPU hardware. The main challenges are:
- The GPU supplies are unevenly distributed geographically.
- Different models have different performance profiles on different GPU hardware types.
- Different models have different geographical capacity demands to serve traffic.
GSP and ICSP are jointly solving for the challenge. At a high level, AI inference is a multi-tenant service managed by ICSP. Each inference model is configured as a tenant with multiple deployments. The service owner configures the infrastructures of interest (e.g., container job, routing, autoscaling, etc.) for each tenant. GSP is configured at the service level with the global view of all tenants and the capacity. At run time, GSP solves for an optimal placement plan, which is taken by ICSP, and then ICSP materializes the plan by updating the tenants and deploying their running jobs accordingly.
The end-to-end flow from GSP to ICSP is illustrated in Figure 5 below.
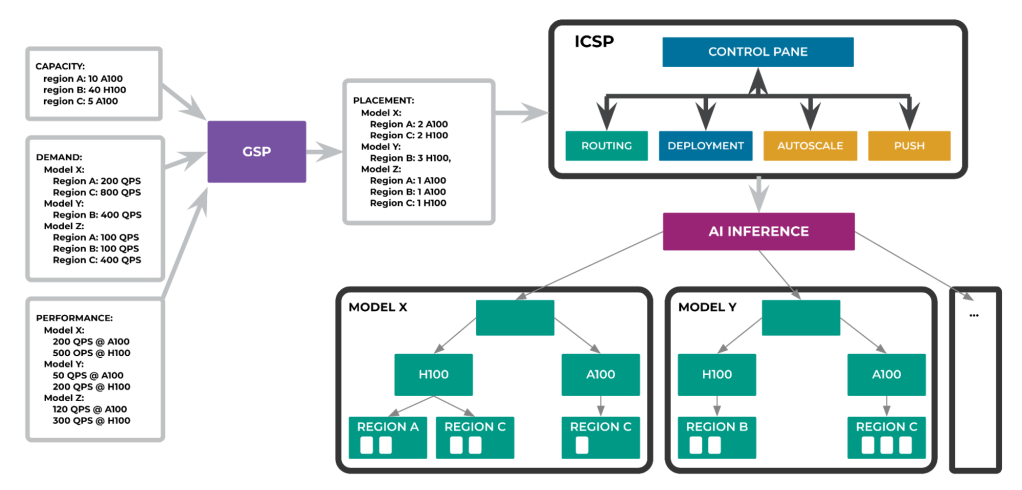
More specifically, GSP takes as input:
- Capacity supply:
- It specifies quantitative hardware distribution for all managed regions. For example, region A has 10 A100 cards, region B has 40 H100 cards, and so on.
- Traffic demand:
- The service owner provides the anticipated traffic demand across different regions for each model. For example, Model X would require serving at 200 QPS for Region A and at 800 QPS for Region C.
- Model performance:
- This is a per-model configuration to specify its compatible hardware types and performance profiles across different hardware types. For example, Model X would demand for A100 and H100; one A100 card would serve for 200 QPS, while one H100 card would serve for 500 QPS.
GSP then creates an optimal placement decision for each model, aiming to maximize overall capacity efficiency across a large number of models. For example, Model X would eventually deploy to Regions A and C. In Region A it would be served by two A100 cards and in Region C by two H100 cards.
GSP’s placement decision is taken as input by ICSP, which materializes it into the underlying service-management infrastructure resources such as the containers, routing, deployment schedule, autoscaler, and more. For example, Model X would have deployments in both Regions A and C. In Region A,
- if it were already serving with 2 A100 cards it would stay the same
- if it did not have a running instance on A100 cards yet, it would create a new deployment and size it to use two A100 cards
- If it were previously serving with less/more than two A100 cards, it would update the deployment by upscaling/downscaling it to two A100 cards.
We see promising results from this capacity-solving flow. It reduces the number of GPU cards needed for the majority of the inference models, which leads to globally efficient use of resource-intensive GPU hardware, and is ultimately a win for the company.
Future Work
We are still in the early stage of realizing the full vision, and we see exciting opportunities to make our solutions better. The advanced serving paradigms of Distributed Inference have more complex model-placement requirements. Currently, the management and capacity of inference and training is mostly independent, and we want to increase capacity fungibility between inference and training and improve GPU utilization. Additionally, we want GSP to provide better support for the optimization of cross-region network usage. We hope our work inspires the community to join us in further advancing the mission of building a planet-scale computer without region boundaries.

