






Additional Author: Woo Xie
Introduction
Meta has some of the world’s most widely used calling products: WhatsApp, Messenger, Instagram. One out of every five calls made on Meta’s calling applications is an international call, and as the world becomes more interconnected, the volume of international calls is only growing.
Making an international call is more affordable and accessible than ever before, but improvements in call quality have been lagging. The longer distances involved in international calling translate to more network hops, which lead to issues such as higher latency, packet loss, and jitter. These manifest to users in the form of conversation lag, video freezes, audio stalls, and audio-video sync issues. Moreover, the high latency involved in international calling reduces the effectiveness of algorithms designed to improve call quality. Therefore, not only does international call quality present more challenges to overcome, but these challenges are also quite complex to solve.
We spent the better part of last year working to improve the quality of international calls across Meta’s family of apps. In this blog post, we will describe how we have rearchitected the calling relay to optimize for international calling and addressed both one-to-one (1:1) and group calls.
Basics of relaying calls
Calls are almost entirely composed of audio and video packets that are exchanged between call participants. Many devices connected to the Internet are behind a Network Address Translation (NAT) unit, which can prevent them from communicating directly with other devices. This makes it necessary to have a “middle man”—a calling relay—to help relay media packets between the call participants, as depicted below in Figure 1.

A calling relay sits in the middle and acts like a proxy between the call participants. In a one-to-one audio call, each participant sends one stream and receives one stream, whereas in a video call, since audio and video are encoded as separate streams, the same participants send two and receive two streams.

In a group call the number of streams increases significantly, as shown in Figure 2. Each participant sends out only one or two streams but receives many more incoming streams.
Network adaptation at the relay
The relay is in an advantageous position because it processes all media packets in the call, and as a result can do much more than simply relay media. It can play an active role in improving the quality of the call by detecting certain network conditions for each participant and then adapting the flow of media to best suit those conditions.
Most voice-over-IP applications are built on top of the real-time transport protocol (RTP) and its companion, Real-time Transport Control Protocol (RTCP), where the application heavily relies on peer feedback via RTCP to detect and address network congestion. If the relay just plays a passive role, the RTCP feedback flows end-to-end, as shown in Figure 3.
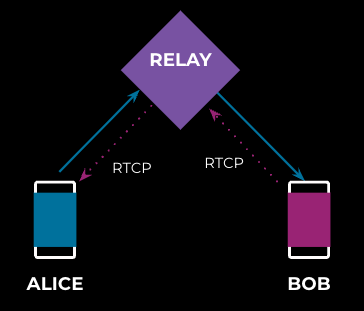
This can be improved on with some modification to the relay server, making it play a more active role in the feedback process. We can do this by breaking the end-to-end feedback mechanism into a hop-by-hop feedback mechanism, where the RTCP feedback is sent and received between relay server and clients, as illustrated in Figure 4:
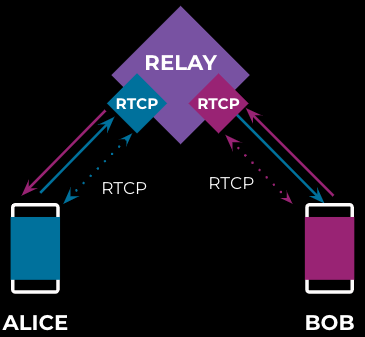
This hop-by-hop feedback mechanism allows the relay to transmit and process RTCP feedback in roughly half of the round-trip time.
This enables:
- quicker feedback that results in faster computation of bandwidth estimates
- quicker reaction to packet loss and network congestion, such as packet retransmissions, forward error correction (FEC), pacing, and so on
| Network conditions that the relay can detect | Actions the relay can take to address the conditions |
| Bandwidth | Faster feedback for better bandwidth estimation |
| Downstream packet loss | Retransmission from cache |
| Upstream packet loss | Negative Ack (NACK) generation |
| Link congestion | Pacing |
| Persistent packet loss | Forward error correction,audio duplication |
Let’s look at an example of how the relay can help with downstream packet loss.

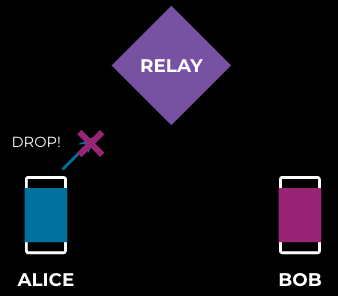
Figure 5 illustrates a packet dropped after it has been relayed. This is called “downstream packet loss” since this is downstream of the relay.

In ordinary circumstances (as in Figure 6 above), Bob would detect a missing packet and generate a negative acknowledgement (NACK), and then send it to Alice via the relay. This would cause Alice to retransmit the packet. This is called “retransmission from source.”

The relay can be smarter, however, and can optimize this exchange. If the relay caches the packets before forwarding, it can intercept the NACK from Bob and retransmit cached packets. This is called “retransmission from relay” (as in Figure 7 above). If the relay is equidistant from Alice and Bob, this cuts the retransmission time by one half!
Similarly the relay can also deal with upstream packet loss, as shown in Figure 8:
This scenario illustrates the packet being dropped before it reaches the relay. This is called “upstream packet loss.” Under normal circumstances, Bob would notice the missing packet and generate the NACK that triggers the retransmission.
However, the relay is able to monitor packet sequence numbers and identify when packets are missing. Instead of waiting for Bob to send a NACK, the relay can generate one on Bob’s behalf, causing Alice to retransmit the packet, as we see below in Figure 9.
Again, if the relay is equidistant from Alice and Bob, the retransmission happens in half the time.

While these techniques also work for international calls, they are a lot less effective. With international calls, Alice and Bob are much farther from each other (as illustrated in Figure 10), so even latency to a relay located in the middle can be fairly high.

Packets arrive after a significant delay at the receiver. If a packet is lost, it takes longer for the receiver to detect it, longer for the feedback to reach the relay, and, finally, longer for the retransmitted packet to arrive back at the receiver.
So packet transmissions in general are a lot less effective. Measurement of other network conditions such as congestion and bandwidth are also much more delayed, so reactions to changes in those conditions are also delayed.
All this makes international calls much more prone to packet loss, network congestion, and bandwidth fluctuations.
New routing architecture: 1:1 calls
To address this problem, we redesigned the routing architecture. We made one significant change—we added one more relay to the mix, so that each packet traverses two relays (depicted in Figure 11).
We no longer pick a relay that is equidistant from the two users, but instead we pick the ones closest to each user. This new routing architecture is called “cross-relay routing.”

At first glance, it might seem like this makes the problem worse. Indeed, every hop adds latency, so the overall latency might actually be higher.
However, cross-relay routing can significantly improve the efficacy of network-adaptation algorithms. Let us revisit the problem of downstream packet loss (in Figure 12) to see how.

With every packet now traversing two relays, both have the opportunity to cache the packet. When Bob reports a lost packet, the relay closest to him—Relay 2 in this case—can retransmit the packet (see Figure 13, below).

Since we have picked the relays closest to Alice and Bob—and in this case, let us assume that the latency from Bob to Relay 2 is 20% of the end-to-end latency—this means retransmission time will be reduced by 80%!
This also works for upstream packet loss (see Figure 14, below).

In this case, Relay 1 can monitor for dropped packets and generate the NACK, again cutting the retransmission time by 80% (as shown in Figure 15, below)!

But what if the packet is dropped between Relay 1 and Relay 2, which is the longest part of the network path? Here’s where it gets interesting!
Meta has high-quality networks connecting our worldwide relay clusters (see Figure 16). These networks are much more stable and higher performing than the public Internet. Not only do these links help lower instances of packet loss, network congestion, and jitter, they can also reduce latency.

So by using a much higher-quality network between Relay 1 and Relay 2, we significantly reduce the chance of packet loss over the longest portion of the network path for the call.
Network adaptation using two relays doesn’t just help recover from packet loss; there are many other algorithms such as bandwidth estimation and congestion detection that can be adapted to work better with two relays. Having these algorithms run closer to the user significantly cuts down on the time it takes to detect and address network conditions.
New routing architecture: group calls
Group calls pose even more challenges for international calling:
- A single international group call can have participants from two, three, or even more regions, which significantly increases complexity.
- Assigning more relays to a call can help, but assigning too many can make the system and algorithms too complex. Assigning multiple relays to a call requires a more advanced algorithm.
- In a group call, each participant sends one stream but receives multiple streams. This increases chances of congestion on the downlink, which requires faster reactions to congestion and better congestion-control mechanisms.
We can extend the cross-relay architecture to group calls, but to do so we need to impose a few restrictions to contain the architectural complexity:
- Choosing relays closer to the end user is beneficial, but we need to limit the number of relays involved to limit the extra complexity coming from the distributed system.
- There is a need for a central relay through which all packets are transmitted (see Figure 17). This ensures there is a way to make centralized decisions for the call and prevents the complexity of relays having to communicate with many other relays for a call.
- In most cases, the network link between the relay and the central relay through the backbone are stable and reliable, but we still need to consider the network congestion and jitters on those links.

The central relay has a bandwidth-allocation (BWA) module that runs the centralized BWA algorithm for each endpoint’s uplink and downlink and communicates the allocation results to relay servers to use for better congestion control.
The relays closer to the users employ network-adaptation techniques such as uplink/downlink bandwidth estimations, audio duplication, pacer, and packet caching. Pushing network adaptation features closer to the users results in significant improvements to group-call quality, especially for international calls.
Results and Learnings
Using cross-relay architecture for 1:1 WhatsApp calls, we’ve seen significant wins in latency as well as reductions in packet loss. Instagram and Messenger use this architecture for all group calls and have seen significant improvements in latency, bitrate, and packet loss.
The results we’ve observed include:
- About 40% reduction in feedback round-trip time on international calls, leading to better and more accurate bandwidth estimation and increased usage of higher-bitrate videos.
- Faster loss recovery, leading to 15% reduction in video freezes and a 4% reduction in audio stalls on some products.
The positives
- Moving network adaptation closer to users has huge benefits for both 1:1 and group international calls.
- Even though additional hops increase latency, it is possible to reduce overall latency through the use of high-quality routing links between those hops.
A word of caution
- Adding active hops (i.e., calling relays) to a call means additional processing. This results in higher resource-utilization costs. With hundreds of millions of international calls every single day at Meta, this increase is not trivial.
- Cross-relay routing does not improve metrics on all routes. There are certain routes where the connectivity happens via a third region. So blindly enabling cross-relay routing on all routes can cause regressions on some of them.
What’s Next
Armed with the learnings from our initial rollouts, we are looking to further refine our algorithms to decide when to use cross-relay routing and how to use it more efficiently to reduce costs. We are working on how to selectively assign relays to calls as well as how to enhance the security, reliability, and efficiency of media traffic over the backbone.
Furthermore, we are looking into adding more network-adaptation features (such as simulcast, temporal scalability, video pause, and so on) to relays to better improve the capability of relays to handle network congestion.

