







At Meta, our vast infrastructure spans over 20 data center regions and comprises millions of machines, all of which work together to power services that serve billions of users worldwide. To effectively manage this enormous scale of resources and ensure optimal capacity and operational efficiency, we rely on our large-scale cluster-management system, Twine, previously introduced in 2019 at System@Scale.
The cluster-management landscape has changed significantly in recent years due to automation growth, increased fleet complexity, and exponential AI workloads growth. This has led to many changes in how we operate our fleet in Twine. In this blog post we look at how the Twine API, which is the gateway for service owners and automation to interact with Twine, has evolved to adapt to the ecosystem change, and how our architecture has been enhanced to better position us for the future.
A brief introduction to Twine architecture
At Meta, thousands of microservices drive our array of products that include Facebook, Instagram, and WhatsApp.
- Services are deployed as a collection of Twine Jobs by application developers.
- A Twine Job is composed of multiple subunits referred to as Twine Tasks, and each task runs as a container on a host.
- The requirements for these jobs are defined by service owners with a Twine Job Spec.
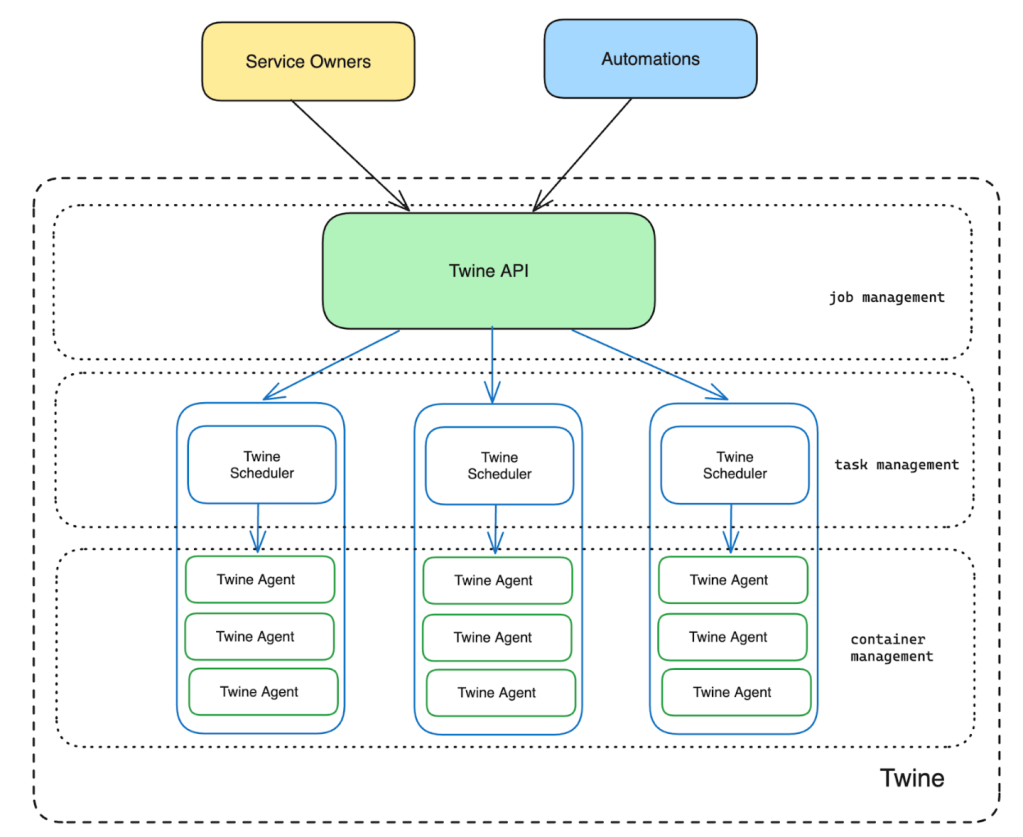
- Twine has a multi-layered architecture with different components managing different levels of abstractions.
- At the bottom of Figure 1, we show Twine Agents that manage the container lifecycle on a given host.
- On top of that, we have Twine Schedulers that handle task lifecycle management. Twine Schedulers translate job-level intent into task-level operations and leverage Twine Agents to run containers for those tasks.
- Finally, the Twine API that service owners interact with provides job-level abstraction and leverages Schedulers for task management.
In this blog post, we are primarily going to focus on the Twine API component, and how service owners and systems interact with it.
Who talks to Twine?
- Twine sets the foundation for all of Meta to interact with their jobs.
- Twine offers CLI, API, and UI for service owners and systems to interact with.
- Developers and production engineers use Twine CLI to perform some or a majority of operational changes.
- Automations build on top of Twine APIs to offer higher-level abstractions such as autoscaling, change deployment, and testing.
Cluster-management trends and problems
Over the past few years, we have observed significant evolutions in Meta’s infrastructure ecosystems and in how they interact with Twine. We want to call out three main trends:
- The amount of automation using Twine has increased a lot. Some of this increase is from organic growth as more service owners have enabled higher-level systems such as Conveyor and autoscaling due to release safety and capacity-efficiency initiatives, but we’ve also seen brand-new automation systems from AI training and Inference emerge over the years to dynamically create, manage, and delete Twine jobs.
- The amount of complexity in the fleet has grown as we utilize more distinct hardware SKUs as well as more specialized hardware types such as GPU, which has increased the amount of customization that service owners require from their jobs.
- The number of jobs Twine manages has grown exponentially. Historically, that number has been relatively stable, as we typically saw increases only when new data-center regions created new capacity. With emergent AI systems building on top of Twine, the number of jobs it manages is now tied to AI-model lifecycles, resulting in an increase in job counts by whole orders of magnitude.

These increases in complexity and automation caused a large shift in how Twine is used at Meta, where certain features that had served us well for the last decade no longer worked so well. One such feature was the developers’ ability to customize tasks directly in Twine.
Task customization
Typically, all Twine tasks within a job adhere to the same properties defined by the job spec. In ideal cases, we would treat all tasks uniformly. Certain use cases, however, use task customization called Task Overrides to prompt Twine to allow properties for specific tasks to differ from the job spec. To apply these task overrides to particular Twine tasks, we introduced Task IDs as unique identifiers for tasks within the job.
Over the past decade, various workflows have been developed within Meta’s infrastructure, based on these Task Overrides. This has enabled higher-level actors to adopt and build features quickly on top of Twine:
- Conveyor is Meta’s Continuous Deployment system. It enables services to set up deployment pipelines to safely and automatically roll out changes to their jobs. Conveyor implemented gradual rollouts of pushes by directly updating a set of tasks within the target job. This feature is used widely across Meta to ensure a safe rollout process.
- Testing infrastructure targets specific tasks to conduct time-bounded experiments (aka Canary) with a limited set of production traffic within Twine jobs. This could be as simple as just selecting some number of tasks, but could also be as complex as ensuring that the tasks chosen have similar characteristics for accurate A/B testing.
- Stateful services were able to quickly adopt Twine by assigning shard identifiers to different tasks.
- Certain edge-network proxy services assign each task a unique Virtual IP in the task overrides, allowing each task to handle certain types of routing workloads.
Problems observed with task customization
While task customization allowed for new use cases to be built quickly, we noticed a few problems with this approach as both the number of jobs and the amount of job management automation increased.
Conflicting automations/intents: While automations worked well in isolation, they experienced a few issues when operating simultaneously on the job.
- Conveyor would update tasks directly to implement a gradual rollout feature. For example, a staged rollout of 50% for a 100-tasks job would translate to Conveyor updating the first 50 tasks of the job.
- Autoscaling continuously changes the size of the job based on traffic patterns and could potentially downsize the job while a Conveyor push is in progress. In these cases, we noticed that the job could be completely running on the new binary if autoscaling sized down the job, violating the service-owner contract and increasing the reliability risk.
Implicit contracts: Developers may run canaries to test changes on production and gather additional signals. These canaries target specific tasks within a job and potentially could conflict with tasks involved in gradual rollouts and weaken the push signal. We noticed that to avoid these conflicts, systems and teams build implicit contracts outside of Twine, thus bypassing its abstractions.

Ecosystem incompatibility: Some services utilize task customization to configure each task uniquely within a job, a common example being statically sharded stateful services. Twine would not know how to safely add or remove tasks in such jobs. That means capacity-efficiency features such as auto-scaling cannot be enabled on such jobs. Service owners were not always aware of such risks when leveraging task customization, and this created a lot of operational overhead for both Twine and developers. Furthermore, this prohibited Twine from meaningfully evolving the job-level abstraction, as these use cases forced us to functionally continue supporting a task-level abstraction.
We saw the need to uplevel Twine’s abstraction to solve these challenges and better set us up for the future.
Introducing the Job Control Plane
As we aimed to evolve job management within Twine, we established two design goals:
- To uplevel abstraction for job management and completely eliminate direct task customization. Instead, we have to be able to capture user intent. That allows us to get out of the over-constrained setup that emerged over the last decade and allow Twine to help resolve some of the conflicts between writers.
- To balance the extensibility in adding new capabilities with the maintainability of the system. This is important given the trends we’ve seen and the fast-changing nature of the AI landscape.
To that end, we have undertaken a rework of the developer-facing data model for Twine. We built a new component, the Job Control Plane (JCP), to implement the redesigned data model and achieve our vision for cluster management:
- JCP provides a more structured integration point that captures service-owner and automation intents directly.
- JCP is a stateful service that provides a set of simple, declarative APIs to interact with Twine jobs.
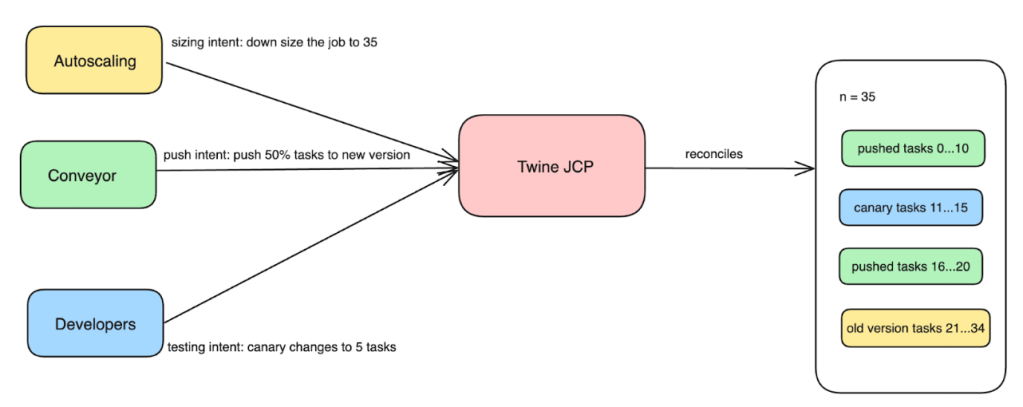
- JCP’s control loop accepts these different intents and reconciles them by computing a unified spec that gets passed down to the Twine Schedulers, to be eventually materialized into tasks.
JCP captures developer/automation intent as multiple separate dimensions such as job intent to capture conveyor/developer push intent, sizing intent to capture autoscaling intent, canary intent to capture developer testing intent, and so on. By capturing these different intents directly, it helps Twine to be better aware of the original goals and to provide more intelligent reconciliation to resolve problems arising from different systems’ conflicting intents.
JCP is in production today, and it manages more than 95% of services at Meta.

Figure 5: JCP is a reconciliation engine that converges Twine jobs towards the desired state defined by the multi-dimensional intents. JCP computes a unified spec and emits various job-management operations that pass down to the Twine Schedulers, to be eventually materialized into tasks.
The JCP management paradigm
JCP provides a set of upleveled paradigms and prohibited direct-task customization from higher-level actors. As you can observe in Table 1 below, in JCP we capture higher-level intents as close to the original use-case intent. This provides simplification and operational improvement across the board.
| Use case | Task Customization Primitive(Before) | Job Control Plane Declarative System (After) |
| Gradual rollout | Update first 10 tasks of the job | Update 10% of the job |
| Canary targeting | Canary on tasks 2,3 of the job | Run canary for 2 tasks |
| Canary targeting hardware | Canary on tasks 2,3 of the job | Run canary targeting allocation |
| Sharding use cases | Customize each task to run a different shard | Migrate use case outside to higher-level system, Shard Manager |
Table 1: New job-management paradigm
For example, previously developers mapped their canary targeting vector to exact task IDs to canary for different use cases:
- Developers want their canaries to run similar hardware and would map the similar machine types to task IDs.
- Developers wanted a simple canary to run any available tasks, but the interface necessitated specifying task IDs, and they picked random task IDs.
- Developers didn’t want canary to diminish the push signal and would pick non-overlapping tasks for their canaries, creating implicit, fragile contracts on their end.
With the new job-management paradigm, these canary workflows are simplified and offer much clearer contracts:
- Developers provide the number of canary tasks to run, and JCP intelligently picks target task IDs for the canary. JCP ensures the push signal is not diluted and is aware of push intent, and can reconcile the two to provide an ideal experience for developers.
- Developers who want to run a canary based on hardware type can now specify that in the intent. This allows Twine to tie the canary life cycle directly to a given host’s hardware usage, providing clearer contracts for developers.
We acknowledge that not all use cases can be satisfied by the new abstraction, and we made the decision to no longer support having special services that configure each task. As part of this decision, we undertook an effort to migrate services that were leveraging task customization for static assignments to higher-level systems such as Shard Manager, Meta’s sharding platform.
Job management evolution and observed benefits
Let’s revisit some of the problems we’ve observed with task customization, examine how they map to our new data model, and consider how they perform.
Revisiting push versus auto-scaling and implicit contracts
Previously, we saw how auto-scaling coinciding with Conveyor push can potentially increase the target vector of gradual rollout and pose reliability risks to services.
In the new data model, JCP captures the push intent to know that the job has to be updated to, say, 50% with the target spec, while the rest of the job should run the old/stable version.
- JCP also captures auto-scaling and canary intent: If they are conflicting with Conveyor push, it can still ensure that 50% of the job is running the new version while the rest of the job is running the stable version of the job.
- JCP can now resolve these conflicting intents from different actors, thereby eliminating the need for these systems to maintain implicit contracts.
As different automations integrate on top of Twine, JCP is best positioned to make decisions about resolving conflicts arising from these intents based on use case, relative priority, and infrastructure state. This offers a cohesive experience for automations and developers. Generally, we observed broad improvements across the ecosystem as systems built on top of Twine no longer had to worry about other systems overwriting their changes.
Infrastructure evolution: New features
One of the design goals for Twine JCP has been not only to solve past problems with a simplified interface, but also to have a system and a data model that enables Twine to experiment and build new features in a maintainable way. Let’s look at how Twine JCP has enabled us to build new features across different areas of infrastructure.
Infrastructure rollout safety
Reliability is an important responsibility for developers building the Twine infrastructure, who are developing and rolling out changes that have extensive impacts on the shared fleet (which includes millions of machines and thousands of services). A broad rollout of problematic changes can have a negative impact on systems such as Twine.
Previously, an infrastructure rollout state was evaluated and applied independently for each update. A Conveyor push spanning multiple stages for the same job could potentially have a different infrastructure rollout state in each stage. If a new infrastructure rollout is applied on the final phase of push, it would effectively bypass the testing stages defined by the user, posing a reliability risk. In general we observed that the system’s behavior would subvert service owners’ expectations and cause undesirable task updates due to infrastructure changes rolling out in an uncoordinated manner.
With JCP, Twine is able to store additional states on how internal rollouts should be applied. Furthermore, JCP has access to the Conveyor push intent, enabling us to align internal rollouts with the start of new conveyor pushes. This allows us to maintain a consistent version across a single push and better leverage the guardrails and health checks that Conveyor provides, thus improving the rollout experience for all parties involved. We are also able to return this internal state to Twine users to improve the observability of such changes.

AI capacity efficiency wins
Eighty percent of the jobs managed by Twine are launched by AI workloads service training and inference use-cases. Any improvements to efficiency for these AI workloads can quickly compound to result in major capacity-efficiency wins.
AI Inference had a problem where they were unable to efficiently utilize machines for their experimental models. Ideally, these models only required a single task to run. These models also had a high availability requirement, which forced Inference to run these models with double capacity to ensure that there was no downtime during pushes and maintenance events.
With the upleveled job abstractions in JCP, Twine Scheduler was able to build a new feature to only turn up new tasks during updates and maintenance using a shared capacity buffer across all of these jobs, which allowed Inference Platform to reduce the amount of capacity needed to run their experimental models by 30%.

Lessons learned: Migration safety
We have conducted design and productionisation of JCP over several years. Migrating to the new system was a paradigm shift that required work on multiple layers across infrastructure. Teams working on all of the core automations that interacted with Twine, such as Conveyor, AI Scheduler, and others, had to rethink and redesign their workflow and interactions with Twine to no longer operate on tasks, and to operate at the job abstraction. Services that operated to run their tasks uniquely had to either migrate to higher-level sharding systems (such as Shard Manager) or rethink their deployment to no longer require such customization.
In addition to that, migrating all of the services in Meta to JCP has been an arduous task that requires a high degree of reliability, given the mission-critical services that depend on our infrastructure and the billions of users relying on Meta’s services. The key principle during this migration has been to ensure transparency and non-disruption to service owners. To execute this massive migration involving all of Meta’s services, we developed an automatic migration process by leveraging Meta’s continuous deployment system Conveyor. This approach not only enabled us to scale the migration process but also provided reliability safeguards through service-level health checks, as well as offering observability to service owners during the migration.
In large migrations, we are building new features in the system as we are migrating services over. Having a flexible interface and data model is valuable for large migrations, as it is impossible to predict all the requirements at the beginning. A flexible interface and well-defined framework allows us to add new features based on the priority and ordering of the services in the scope of migration while not compromising maintainability.
Looking forward
For some time, developers at Meta had widely requested a feature that would test code and config changes simultaneously and reliably. Previously, developers had tried to coordinate those by performing a config canary on a specific set of hosts and targeting a code canary via Twine to target the same set of hosts. This is a bespoke way to perform a “code + config” canary. We are currently working to provide a more unified and reliable way using Twine JCP for code + config canary.
We are also working on upleveling regions and providing global abstractions. We are leveraging global job abstractions with regional guarantees to build next-generation Inference Platform solutions. By abstracting away regional boundaries, we can create a more efficient and resilient infrastructure that is better equipped to handle the ever-changing needs of Meta’s diverse product offerings.
We are excited to continue leveraging JCP to experiment and provide more value-added features, improve capacity efficiency, and provide strong reliability guarantees to developers and service owners that rely on our infrastructure.

