







Introduction
The past couple of years have been nothing short of extraordinary for technology, especially for artificial intelligence (AI). Amidst this rapid progress, machine learning (ML) engineers have found themselves trapped in a relentless cycle of model training, testing, and refinement. But what if we could ease and expedite this process for them?
In this blog, we will touch upon the new orchestration challenges that emerged in the AI space, and how Meta’s AI Infrastructure and Serverless teams partnered to solve these challenges and create a new workflow orchestration engine: Meta Workflow Service (MWFS).
We will also take a deep dive into the design philosophy and architecture of this new engine and elaborate on how this new system is helping us shape the future of workflows at Meta.
Let’s start by looking into the recent orchestration-related challenges within the AI infrastructure at Meta.
FBLearner Flow’s monolithic architecture
FBLearner Flow is the current implementation of the ML pipeline authoring SDK and orchestration framework for almost all mission-critical offline and recurring ML training workloads. AI researchers also use FBLearner Flow in combination with Bento to experiment with new ML methods for training.
Previously, FBLearner Flow mixed numerous concepts in every layer of the stack. This led to substantial confusion as to whether the system was a generalized workflow engine, an end-to-end ML platform, or some combination of both. We needed to properly separate out the pieces so users could make effective use of each component and enable innovation in each logical layer. In addition, we wanted to enable the FBLearner Flow team to focus on the ML specific parts of the system rather than on just the general-purpose workflow parts.

Problems with Legacy FBLearner Flow architecture
The challenges with Legacy FBLearner Flow architecture include:
- Lack of flexibility for integrating with multiple execution environments Earlier, the job responsible for running an operator had to be scheduled through a scheduler that was tightly coupled to its execution environment. This whole system is called Chorons. To incorporate other execution environments, like those designed for GPU workloads, we were limited to using wrapper Chronos jobs, which resulted in certain drawbacks:
- One prerequisite for running Chronos jobs was the provisioning of dedicated containers for each job, which contributed to increased latency in execution.
- UI layers must implement abstractions to identify wrapper jobs and specialize them for log fetching, DAG (direct acyclic graphs) view, etc.
- Resource accounting must be specialized to identify wrapper jobs and attribute cost across schedulers.
- Decreased reliability due to extra dependencies.
- AI framework builders must build directly upon Flow if they care about the UI and other high-level features not provided by the underlying orchestration service. Some common examples are MLHub, resource management, GPU cluster integration, IO implementation, and observability dataset. Building their SDK on top of Flow leads them to inherit all the limitations and unnecessary features, which exposes impacts such as:
- Increased latency of execution due to performance issues stemming from tech debts. According to our data analysis, for operators running less than 5 minutes, overhead introduced by Flow runtime is about 1/3 of the entire execution time.
- Slow builds due to architectural problems, leading to dependency bloat.
- Monolithic database for tracking all workflows and operators. Flow keeps source-of-truth metadata and runtime status in a single sharded database for workflow management, UI, and observability dataset. There are two impacts:
- Requires limits on size of workflows and number of operators. This restricts patterns that customers would like to do (e.g., one framework from Reality Labs requires up to 20K operators in a pipeline that FBLearner Flow does not support today).
- The size of the DB instance (~1.7TB) is above normal, which impacts reliability and query performance. There is little room to scale up, so in future years it won’t sustain the expected workload growth.
- No explicit DAG representation from the SDK. Flow must execute user Python code to construct a DAG as in-memory Python structure. This results in not having a user-friendly way to write unit tests for workflows, leading to a heavy dependency on integration tests.
Our new architecture built on top of Meta Workflow Service
To address the key problems outlined in previous section, we re-architected FBLeaner Flow by leveraging the Meta Workflow Service (MWFS), an orchestrator, to have clear separation of concerns, flexibility in supporting new types of schedulers and SDKs, and the ability to evolve into event-driven-based observability.

Meta Workflow Service Architecture and Orchestration
We collaborated with AI Infrastructure in an effort to address their orchestration challenges and concurrently develop a generic workflow engine as a solution. We wanted to build a system that is:
- powerful enough to handle all the AI use cases now and in the future, and
- flexible enough to grow to handle the majority of other workflow systems at Meta.
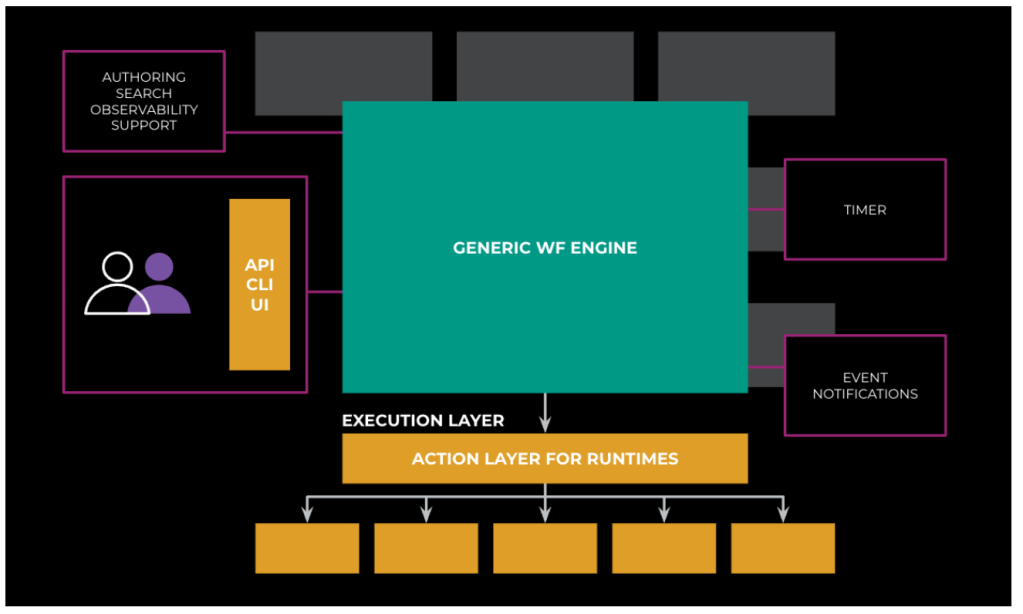
So, we built Meta Workflow Service (MWFS) with a collection of other services to introduce a clear separation of concerns—individual components with discrete key responsibilities, such that when they come together they create an ecosystem that powers the majority of workflow use cases within Meta. The combined service collection includes:
- MWFS: The core orchestration service and initial point of contact for clients defining and launching workflows. It keeps track of both the state of the workflow and the events happening in the workflow, determining and invoking code for the next steps in the workflow.
- Event Router: The core service for event management. Event Router allows developers to easily connect event sources (eg: blob store, sql db) to event handlers (such as a Lambda function). It uses a simple YAML configuration file to define the mapping between events and handlers, making it easy to manage and maintain. Additionally, Event Router provides features such as filtering and transformation of events, allowing for more flexibility in how events are processed.
- Action Service: The core service for triggering and polling status of asynchronous functions on various execution runtimes within Meta. Unlike traditional RPC systems where a client sends a request and waits for the server’s response before moving forward, Action Service allows the client to send a request and then immediately proceed with other tasks without waiting for the result. ActionService processes the request asynchronously and notifies the client once it’s completed. This approach enables the client to delegate the workload to ActionService without blocking, thereby enhancing overall efficiency and scalability of the system. Action Service also provides automatic retries making it easy to build fault-tolerant and scalable applications.
- Timer Service: The service handling all recurring and scheduled events.
As you can see in Figure 3 below, MWFS is a horizontally scalable service, built upon SQL, and uses FOQS (distributed queue) for queuing. It also has implicit dependency on Shard Manager, Configerator, Tupperware, and other fundamental services. All workflows are confined to a scope of a shard, which makes horizontal scaling seamless.
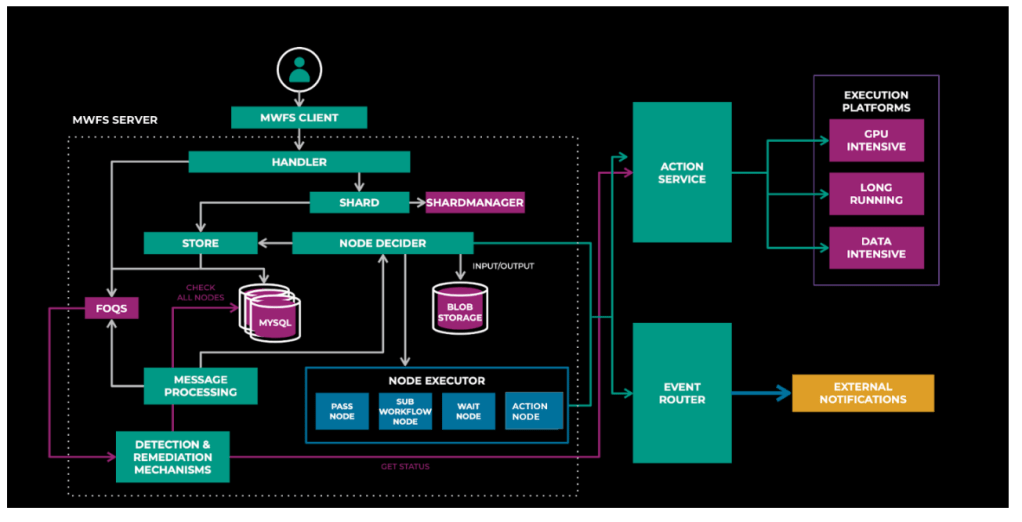
MWFS uses an event-driven model for driving workflow execution. Each event handles a small “piece” of workflow execution, such as launching a task, finishing a node, or unlocking new nodes. Events are idempotent and therefore retryable until they succeed.
A workflow is defined as a collection of nodes along with their relationships (or edges). MWFS currently supports DAG only. MWFS workflows can be ephemeral or non-ephemeral:
- Ephemeral workflows are “one-shot” workflows that start running immediately after they are created.
- Non-ephemeral workflows have a workflow definition that is uploaded once and then called many times to create new instances based on the same definition.
Nodes within a workflow follow a strict state transition: PENDING –> READY –> RUNNING –> FINISHING –> FINISHED. This allows MWFS to maintain high concurrency while also maintaining correctness.
The two key components here are the NodeDecider and NodeExecutor.
NodeDecider
The NodeDecider is responsible for managing and coordinating the execution of workflows. Its primary role is to decide which task node should be executed next based on the state of the workflow instance and the definition of the workflow itself.
Here are some key aspects of the NodeDecider’s role:
- Workflow orchestration: The NodeDecider orchestrates the execution of tasks within a workflow by determining the appropriate task to execute at any given time. It does this by analyzing the state of the workflow instance, including the completion status of previous nodes.
- Handling task dependencies: The NodeDecider ensures that nodes are executed in the correct order by respecting the dependencies between them. If a node has unfulfilled dependencies (e.g., previous nodes that haven’t completed yet), the NodeDecider will wait until these dependencies are satisfied before scheduling the node for execution.
- Error handling and retries: When a node fails or encounters an error during execution, the NodeDecider can initiate retries according to the tenant’s retry policy. This helps ensure that transient failures do not prematurely terminate a workflow instance.
- Scalability: To support scalability, NodeDeciders are idempotent and work within the scope of a shard.
NodeExecutor
The NodeExecutor focuses on behavior “within” the nodes. These are tailor-made to handle the actions performed by the node.
- TaskExecutor
Launch a task with the given input parameters (plus timeout, retry policy, and so on) via the Action Service (AS). The result of the task is received in a callback from the AS. The node is considered a failure if it can’t launch or if the AS reports the action as having failed; otherwise it’s a success.
- WorkflowNodeExecutor
Launch a sub-workflow with the given input parameters (or form a given workflow definition). The node is considered a failure if the sub-workflow fails to get created or finishes with a “Failed” state.
- WaitExecutor
Pause for the specified interval or for an external event. The node ends immediately if the external signal is received or when the time interval elapses.
- PassExecutor
Helps define a dummy node. Succeeds instantly with no output. This is commonly used for scenarios where we need to trigger multiple actions concurrently and wait for all of them to complete before triggering a new action.
In the future, we will be expanding these and introducing MapNodeExecutor, LoopExecutor, and more.
Figure 4 below illustrates the sample workflow:
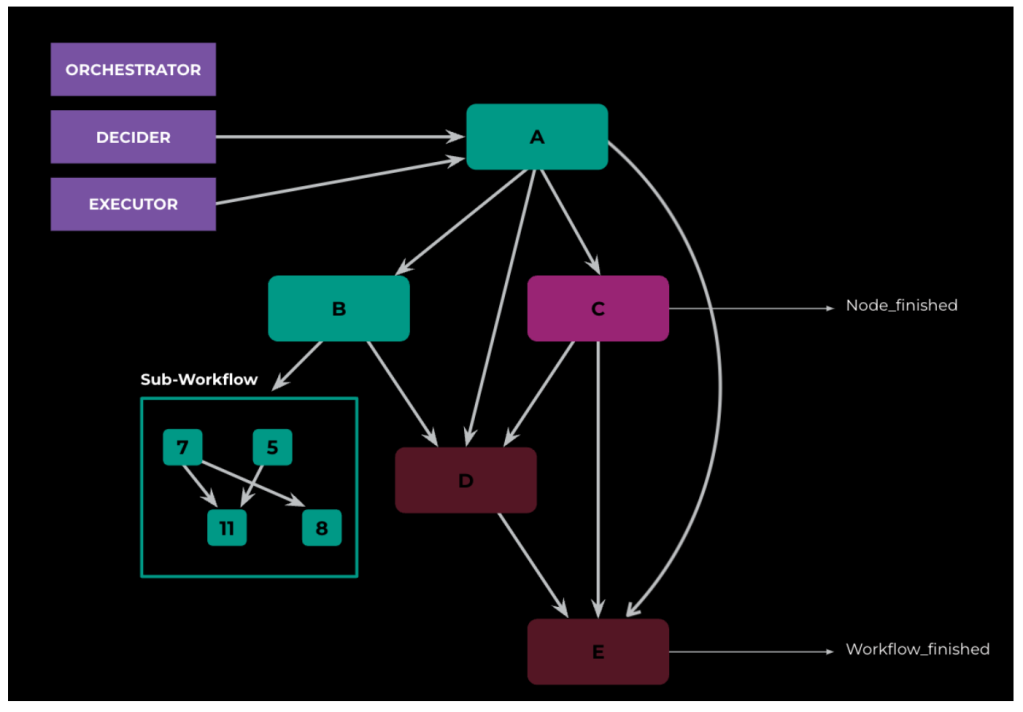
At any given point, the NodeDecider will unlock the nodes for execution if their dependencies are satisfied, and the executor will execute actions based on the node type. At each stage, we ensure strict in-order execution of nodes. A node:
- can trigger an action on an external runtime (see Figure 4: Node C)
- can create a new sub-workflow and wait for its completion (see Figure 4: Node B)
- can be a dummy pass node, which finishes as soon as it gets started. (see Figure 4: Node A)
During the orchestration, detailed event information is continuously published to the event router, providing customers with real-time observability into their workflows’ progression. Moreover, failure policies (such as ContinueProcessing, BlockDepenents, and CancelDependents) provide adaptability by enabling users to choose the preferred orchestration path for workflows. This can be configured individually per node and establishes whether the workflow continues, cancels, or fails after a node failure occurs. Additionally, the “RetryWorkflow” feature allows users to revive unsuccessful workflows without needing to rewrite and rerun them entirely.
To ensure high levels of reliability and availability, we’ve built in-house mechanisms for monitoring delay between node transitions, stuck workflow detection, and hot shard prevention.
The subsequent section of this blog post will concentrate on the strategies employed by AI Infrastructure and MWFS to facilitate a seamless transition of all Flow workflows without any downtime while maintaining high levels of reliability.
Evolution of Meta Workflow Service
Let’s look into how we reached this modular architecture while solving the various challenges one by one in the AI space that we mentioned above.
AI models can be represented as workflows where at each step the individual node performs specific tasks. Below is a simple representation of a workflow, illustrating the end-to-end life cycle of AI model training.
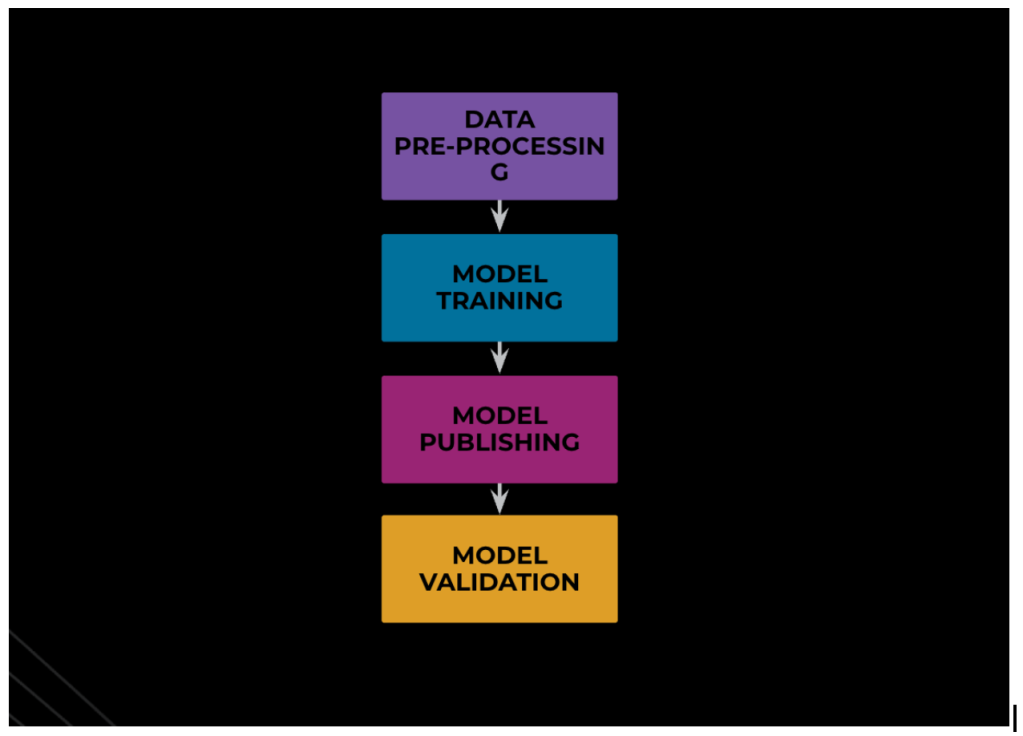
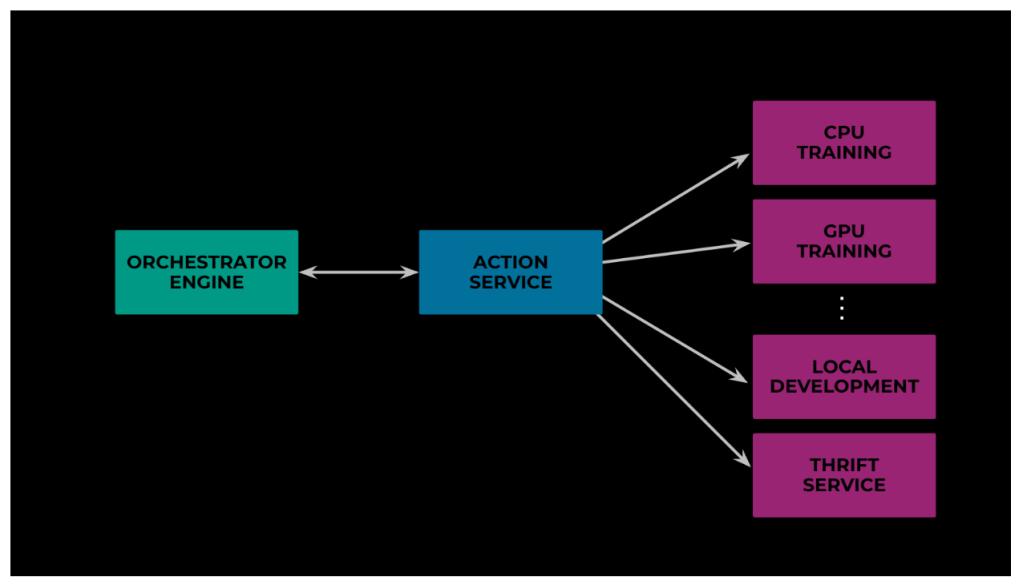
Depending on the nature of the work, different nodes need different hardware resources and/or different software paradigms. For example, for data preprocessing we need CPU-based batch jobs, whereas GPUs are required to efficiently train the weights of parameters of the model, and a client can host Thrift Service to scrape, gather, and store data.
To execute the overall workflow effectively, the orchestrator needs to talk to these different execution environments. To avoid tight coupling, we didn’t integrate the orchestrator directly with these different platforms. Rather we introduced a layer in between that launches and tracks such jobs. This helped us in optimizing and supporting various existing use cases really fast.
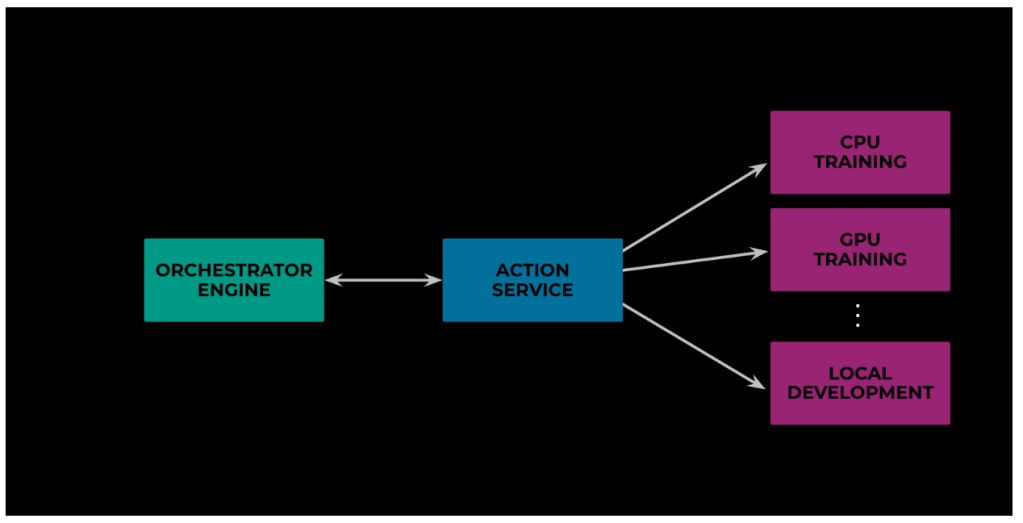
Below in Figure 7 you can see an example use case that demonstrates this point further. We had workflows with nodes that were creating a sub-workflow and attaching it to one of its nodes as parent. Previously, due to our reliance on Chronos jobs for executing node logic, we needed to provision a container, run these steps, and then deprovision it. Now with the new flexibility, we were able to allow the v2 Flow server to delegate to various action destinations. And so, we could convert the Chronos job logic into a thrift API and use it directly via Action Service. This increased flexibility helped in reducing the overall time to train the model, as now we don’t need to wait for a container to warm up before running these steps.
Our next challenge was to support the observability requirements of AI model trainers. You see, AI systems require granular-level observability not only for operational reasons but also to enable continuous experimentation, course correction, and rapid iteration. For instance, an ML researcher may want to analyze the results midway through model training to determine if the experiment should be continued or restarted with new parameters. To tackle this challenge, we needed to provide in-depth observability capabilities.
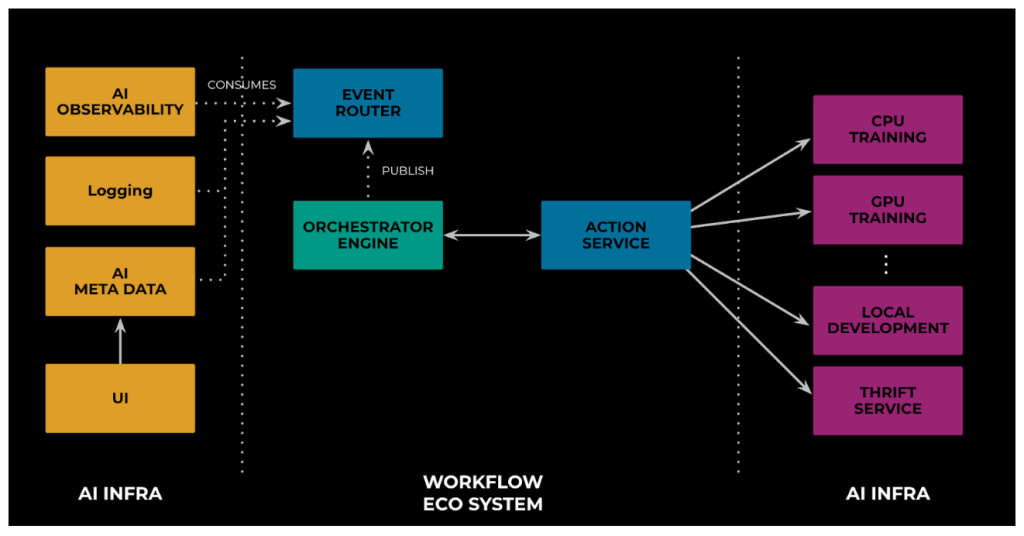
This is where Event Router (ER) comes into play, which we discussed earlier while presenting MWFS’s high-level system architecture and we illustrate below in Figure 8. ER is a pub/sub system. It continuously receives various events—such as workflow_start, node_start, node_end, and if node failed, why it failed, and so on—from the orchestrator throughout a workflow’s life cycle. On the AI side, the observability infrastructure subscribes to these events and processes them as per their requirements.

ER allows having multiple subscribers. In Figure 9 below, we illustrate how this flexibility allowed us to use the same approach to support various subsystems required for effective model training. These subsystems include client-facing UIs, AI metadata stores for collecting results across multiple experiments, and logging systems to handle operational events.
This modular architecture, of decoupled events and Action Service, has proven immensely useful for improving and extending the system even further. Let me share two examples illustrating this point.
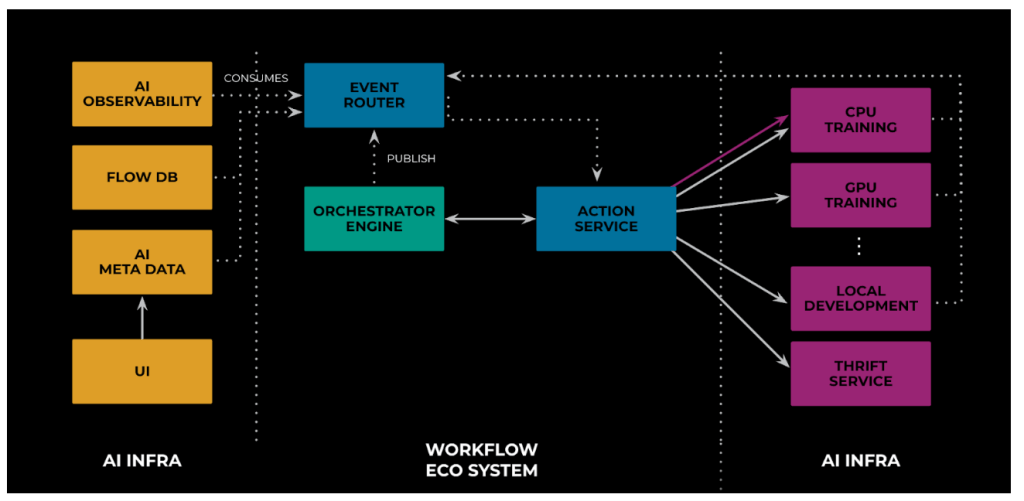
Prior to the implementation of publish/subscribe support, AS frequently polled multiple execution platforms for updates on the status of previously launched jobs, resulting in wasted compute resources and significant delays in overall model training time due to the lag between job completion and notification.
Leveraging the flexibility provided by ER, we have transitioned to a push-based paradigm by integrating execution platforms with ER. In this system, execution environments act as publishers while the orchestrator responds to relevant events to trigger subsequent nodes, as depicted in Figure 3, which showcases an example workflow run. To maintain scalability, MWFS does not directly consume these events; instead, AS handles this task through a callback API, similar to its function in the previous pull-based architecture. This is illustrated in Figure 10, where the red arrow represents the prior pull-based method and the dotted arrow between ER and ActionService signifies the new poll-based architecture.
Our next example relates to safe onboarding. More than 1100 teams at Meta use FBLearner. So, any downtime could have resulted in significant revenue and productivity loss. To prevent this, we ran all production traffic in shadow mode. To ensure the effectiveness of this technique, it’s crucial to eliminate any side effects that might arise from executing the same requests twice. To prevent those side effects entirely, it was essential to ensure that each node was executed only once. To make this work, we added a NO-OP/Shadow Service and integrated it with AS (see Figure 11, below), just like any other execution environment. The node execution requests originating from the shadow request now would go to the Shadow Service.
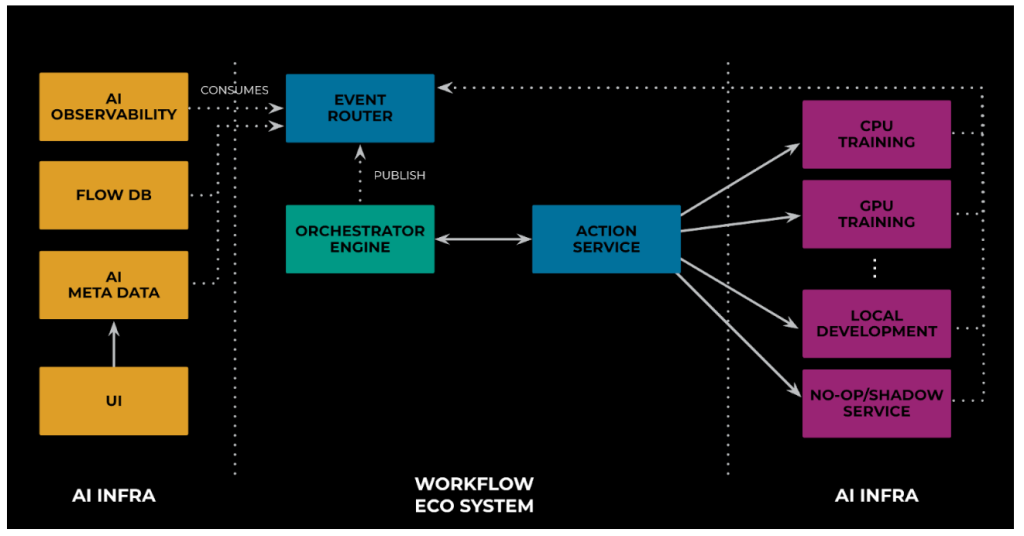
Please note: The Shadow Service wasn’t a dummy service. Depending on the type of request, it was doing different things. For example:
- For execute requests, it returned the corresponding response from the similar production request. Here, we had to handle race conditions where the AS received the shadow request before the production request.
- For status requests, the Shadow Service polled the corresponding execution system.
- Cancel requests were the most challenging, as they could impact actual production jobs. We addressed this by recording the cancellation intent from the production orchestration engine and the corresponding results in a single, separate database. For shadowing the orchestrator, we queried the shadow database. Here too, we had to handle race conditions where the proxy received the shadow request before the production request.
Next, we updated the client library to create a duplicate or shadow request. As described before, the original (production) request was sent to the existing orchestrator, and the shadow request was forwarded to the new orchestrator (Figure 12). We added a no-op flag in the shadow requests, enabling the new orchestrator to differentiate between shadow and non-shadow traffic. It simply forwarded the nodes to be executed to the Shadow Service, which was now intelligent enough to understand the shadow flag and make appropriate decisions.

For effective verification, it was crucial that MWFS experienced node execution with the same order, and that throughput, latency, and error metrics were not degraded. We implemented a monitoring system to ensure these guarantees.
To monitor the workings of the new scheduler, we built an offline monitoring system that pulled and compared artifacts from the databases of the legacy and new scheduler. While we monitored multiple dimensions, our primary focus was on the following three aspects:
- Workflow execution end state
- Job/node execution end state
- Running time for workflow and jobs
The future of workflows at Meta
While we have delved deeper here into the new workflow system and explored how it tackles various AI infrastructure challenges, we have not yet addressed the question of why we developed a completely new system instead of building upon existing solutions.
Over the course of a decade, we had created more than a dozen workflow solutions within Meta. We realized that many of these systems had been built over time out of the needs of individual domains/orgs (such as Data Infra, AI Infra, Video Infra, Core Systems, and so on.) Their execution and orchestration layers were tightly knit together, which made it difficult to consolidate or unify them.
When we started our collaboration with AI Infra, our initial plan (Figure 13) was to use DAG and FOQS, since these are well-tested components at Meta’s scale. In addition, we created a “consumer” to offload the AI workload to a dedicated ML execution runtime and then continuously poll for status. But as our collaboration grew, numerous feature requests emerged, including support for parent-child workflows, failure propagation, life cycle-event notifications, workflow revival and repair, recurring workflows, and scheduled waits. After evaluating, it seemed impractical to retrofit all these features in a system that was inherently not flexible and extensible enough to address these requirements.

This made us take a pause and think again. This time we thought of it in terms of Legos—basic building blocks with discrete responsibilities that together create an ecosystem that can cater to the needs of the ever-changing AI space.
Figure 14 illustrates the Serverless vision of creating a generic workflow system, which we are realizing as we are building Meta Workflow Service.
Our successful collaboration with AI Infra and their successful onboarding to MWFS with zero downtime has boosted our customer trust and enabled us to now collaborate with Data Warehouse to onboard all of their workflows to MWFS by 2025. In addition, there are multiple, parallel streams of evaluation and exploration to merge the multiple workflows systems such as Enterprise workflows, Async Workflows, DAG, and CWS within MWFS in the coming years.
Our next steps
We are continuing to build our feature set and support more node primitives to unlock newer use cases for our customers. Those include Loop node, MapReduce node, Conditional nodes, and more.
To realize our vision of creating workflows for everyone at Meta, we are investing in a drag-and-drop authoring model.
We are building a UX to enable all experiences—including authoring, real-time monitoring, troubleshooting, and searching—to happen at a single location.
Thanks to all the members who have contributed to this AI Infra and MWFS collaboration: Adam Hardy, Amey Jain, Artem Denisov, Avanish Pandey, Brian Lee, Chang Wang, CQ Tang, Dan Shiovitz, Ernesto Gonzalez, Girish Joshi, Haonan Wu, Havish Chennamraj, Herman Chen, Igor Kruk, Igor Shatilov, Jalaj Kumar, Jeffery Dunn, Jin Sun, Kim Freedman, Manan Manan, Manukranth Kolloju, Marcio Carmona, Nagarjuna Malempati, Ned Newton, Neeraj Pathak, Omar Abdou, Peiyao Zhou, Sayak Kundu, Sebastian Kimberk, Shie Erlich, Shobhit Mehta,Shawn Chen, Stefan Larimore, Vin Wang, Vipul Patel, Yingji Zhang, and Yury Kitaev.

