EVENT AGENDA
Event times below are displayed in PT.







Data @Scale is a technical conference for engineers who are interested in building, operating, and using data systems at scale. Data already enables companies to build products with user empathy, find new market opportunities, understand trends, make better decisions, and ensure that their services and systems stay healthy. The landscape of data systems is quickly evolving, and, especially at extreme scale, imposes unique and complex engineering challenges.
This year’s Data @Scale will be focused on the new challenges that Machine Learning presents for data infrastructure.
Speakers from Meta and other industry-leading companies will discuss how they are tackling these challenges today, and we hope the event fosters a community that can discuss and collaborate on the development of practical industry solutions together.
The conference will be hosted virtually on May 18th starting at 9 AM PT, and will feature keynote sessions, tech talks and Q&A sessions.
Event times below are displayed in PT.
Event times below are displayed in PT.

This talk breaks down stage-by-stage requirements and challenges for online prediction and fully automated, on-demand continual learning. We’ll also discuss key design decisions a company might face when building or adopting a machine learning platform for online prediction and continual learning use cases.

In Meta, we had developed multiple real-time data processing infrastructure like Puma, Stylus and Turbine (SIGMOD '16 and ICDE '20). As Meta grows, the needs for real-time data has grown way beyond traditional data analytics & reporting scenarios. Recently, ML data engineering become increasingly a strong driving force. The real-time data is no longer only examined by human occasionally, but powers ML-based systems to always gain the freshest knowledge and make higher quality predictions. We will talk about the architecture of our latest generation, consolidated real-time data processing platform and how we evolve it for ML real-time feature engineering.


Machine learning is at the heart of Pinterest and is powered by large scale ML training log collection. To solve the cost efficient data ingestion & transportation problem at Pinterest we developed MemQ, a PubSub system that leverages pluggable cloud native storage like S3 using a decoupled packet based storage design. MemQ is able to scale to GB/s traffic with 90% higher cost efficiency than Apache Kafka, enabling Pinterest to ingest all of our ML training data powering offline training, near real-time model quality validation and ad-hoc analysis.

Grab a coffee and come back at 10:50 AM!
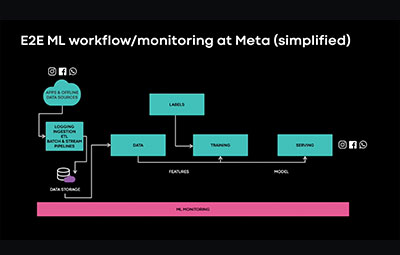
ML generates significant value for Meta’s infrastructure, tools, products, and users. It drives a varied set of insights; from end-user products such as recommendations and feeds on Facebook and Instagram, to infrastructure insights for demand prediction and capacity planning. However, problems such as gradient explosions, data corruption, feature coverage and multi-layer performance degradations impact the ML ecosystem. As features, data and models scale, the nature of these problems gets more complex to assess impact, root cause and mitigate — especially with siloed tools, teams and metadata, fragmented and manual run books — spread across the ML lifecycle. In this talk, we provide an overview of ML Challenges at Meta, our take on ML monitoring and observability infrastructure and tooling to solve for these problems. We cover an overview of our platform, use cases, and product experiences.



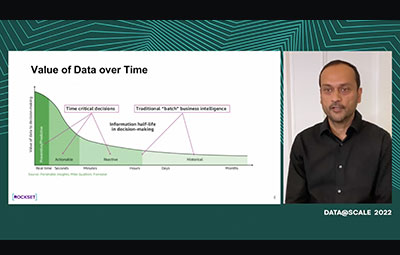
Data Infrastructure has evolved in the last 15 years from Hadoop's batch system, to streaming systems like Spark and Kafka and now to realtime systems like Rockset and Clickhouse. Automatic decision making based on massive data sets demands a data infrastructure system that is Real-Time. These decisions are made by either hand crafted rules or served by machine learned models that operate on large datasets and return results in milliseconds. We dive into the design and architecture of one such realtime data processing platform named Rockset. Rockset is a Real-Time indexing database that powers fast SQL over semi-structured data such as JSON, Parquet, or XML without requiring any schematization. All data loaded into Rockset are automatically indexed and a fully featured SQL engine powers fast queries over semi-structured data without requiring any database tuning. Rockset uses open source RocksDB as it storage engine, In this talk, we discuss some of the key design aspects of Rockset such as: * Smart Schema: Smart Schemas can take any semistructured dataset with deeply nested objects and arrays and automatically turn it into a SQL table. This becomes especially important to serve Machine Learning Models in production when the models frequently create new columns or change schema of existing columns. We show how this feature reduces the need for data cleaning or data preparation before data can be used to generate insights or serve models in production. * Converged indexing: A novel storage format (unlike Parquet or ORC), that is built for millisecond latency on massive data sets. This format builds multiple indices including an inverted index, a column index, a row indes, a range index, a time index etc with minimal overhead. This allows model serving to operate on large, fast changing datasets because a query automatically picks the best index to use, thereby making it faster than brute-force scan based systems. * The Aggregator Leaf Tailer architecture: A novel systems architecture that implements a three-way disaggregation among storage, query compute and ingest compute. We describe a novel way to embed User Defined Functions (UDF) written in JavaScript as part of any SQL query. We visualize that UDFs be used to implement Machine Learning models like kNN and Faiss to serve models in production. We describe how Rockset uses SIMD instructions in a vectorized engine to improve query performance and draw a similarity to how machine-learning training infrastructure can leverage a similar approach. We explain how Rockset manages the on-disk format of data with automatic splitting of RocksDB based column based clusters for better compressions and faster decoding, a technique that can be used by general purpose machine learning training infrastructure as well.

Grab a bite and come back at 12:30PM
The problem of deep learning and building large scale systems for production is not just one of model training, but data preprocessing as well. At production scale, just the data loading and processing part of the system can cause significant friction and consume your engineers’ time, while still being non-performant as more and more data is used. We provide an overview of the top pain points that are normally faced in this space. With these pain points in mind, we’ve created two libraries that solve different parts of the data workflow, TorchData to make pipeline creation composable, easy to use, and flexible simplifying the path from research to production, and TorchArrow a DataFrame library that allows for scale through the use of high performance execution runtimes built on the Arrow memory format. We’ll step through the out of the box offerings with our open-sourced TorchData and TorchArrow APIs and building blocks, and provide a real world case study that shows how we’ve made data preprocessing performant at scale within Meta. Lastly, we’ll give a peek into upcoming work as we continue to develop and share our learnings with the open source community.



Machine Learning models are only as good as the data that was used to train them. Datasets are often plagued with problems such as quality, discoverability, and undesirable social biases. As data and modeling tools are becoming more accessible, tools to maintain auditability, data lineage, and reproducibility have not caught up. Ignoring these concerns affect data and model quality and will only compound as the amount of available training data grows. Growing datasets incur additional costs and impact productivity due to a lack of tools that promote re-use and sharing of these computations. In this talk we will introduce two open source products – Flyte: A platform for orchestrating Machine Learning and Data Workflows. It is built on core tenets of Reproducibility, Efficiency and Auditability. Pandera: A programmatic statistical typing and data testing tool for scientific and analytics data containers. Together these can drastically improve the workflow of a user and address data quality requirements throughout the ML/Data product development lifecycle. Flyte was built to be type-safe to promote the re-use of computations across an organization. This was modeled similar to a Service oriented API design, so that teams could offer data transformations as a service. Flyte tasks definitions use typed inputs and outputs, which permits the platform to statically verify and reason about a workflow. The approach combined with immutable versioning permits reusable task computation. Furthermore, pre-computed outputs can be leveraged to save costs and time. When combined with Pandera, it brings quality guarantees throughout the development process. This talk will conclude with a demo and concrete steps for attendees on how they could leverage either of these products to deploy quality ML & data products.


We’re truly living under the rule of Algorithms, our day-to-day activities from news consumption, job search, and mortgage financing are increasingly being decided by algorithms. Most of these algorithms are AI-based and are increasingly black-box to humans. If we continue to let these algorithms operate the way they do today, in the black box and without human oversight, it would result in a dystopian view of the world where unfair decisions are made by unseen algorithms operating in the unknown. Therefore it is critical that we build trust between AI and humans. In this talk, we will learn about how we can do this by continuously monitoring AI for performance and bias issues and sharing these insights across teams to build a culture of trust in the organization. Fiddler works with Fortune 500 companies to enable responsible AI and regulatory compliance of AI algorithms.

Barak Yagour is the Vice President of Engineering at Meta, leading the Data Infrastructure... read more

Aparna is VP Engineering at Meta, responsible for AI Infrastructure, Data Infrastructure and Developer... read more

Chip Huyen works to accelerate data analytics on GPUs at Voltron Data. She also... read more


Weiran leads the Stream Processing team at Meta powering real-time data applications in a... read more

Ping works on Ads machine learning in Meta, and leads the effort of building... read more

Ambud Sharma is a tech lead at Pinterest. He has worked on architecting, stabilizing,... read more

Ion Stoica is a Professor in the EECS Department at the University of California... read more

Andrea is a Senior Principal Engineer at Amazon Web Services. He is the Chief... read more

Partha Kanuparthy is a Software Engineer in the Monitoring area at Meta. His work... read more

Animesh Dalakoti is a Product Manager in the ML Monitoring and Observability space at... read more

Kunal Bhalla is a software engineer working on improving the developer experience for ML... read more

Dhruba Borthakur is CTO and co-founder of Rockset, the Real-Time Analytics company where he... read more

Yann LeCun is VP & Chief AI Scientist at Meta and Silver Professor at... read more

Wenlei is a Research Scientist working on PyTorch in Meta. He is excited to... read more

Vitaly Fedyunin is a Software Engineer at Meta, where he works on PyTorch Data... read more

Yingxin Kang is a software engineer from the ML Data Platform team at Meta,... read more

Ketan Umare is the TSC Chair for Flyte (incubating under LF AI & Data).... read more

Katrina Rogan is software engineer at Union.ai who works on the open source Flyte... read more

Krishna Gade is the Founder/CEO of Fiddler.AI, a Model Performance Monitoring startup. Prior to... read more