





Meta’s approach to engineering is at an inflection point. Artificial intelligence has revolutionized the way that our engineers write code, enabling small teams of engineers to produce new applications and new backing infrastructure in a fraction of the time previously required. However, authorship is just one step in the software-development life cycle. Code must be tested, deployed, and operated reliably at Meta scale.
This last concern, operating reliable infrastructure at Meta scale—that is, at planet scale—is one of many areas where we are leveraging AI today. Crucially, day-to-day operations entail risk. Even in the best of times, engineers must deal with software bugs, server failures, power outages, and degraded networks. And sometimes those ubiquitous challenges are compounded by natural disasters or geopolitical events. Many of the tools and techniques we use to address such stability challenges—such as emergency code/config hotfixes, reconfiguring networks, and rebalancing traffic—are potentially destabilizing themselves. How can we harness AI to safely execute operations at planet scale?
Meta’s day-to-day operations also include managing vast amounts of different types of data. We have invested years of engineering effort into safeguarding these datastores, ensuring they are replicated and backed up, and establishing robust security and privacy policies. In a world where failure carries potential reputational and regulatory risks, how do we safely leverage AI to manage a wide range of data?
Agent-safe infrastructure
As we incorporate AI into our work, one core value is to ensure that our infrastructure is safe by default for both agents and humans. While that goal sounds straightforward, the strategy to achieve it is rife with complexity. Agents and human engineers may have similar goals and execute many of the same tasks, but those goals differ fundamentally. Engineers undergo workplace training, spend months or years building an understanding of work culture, and cultivate empathy for users and coworkers. Unlike agents, humans are governed by both technological and social success, and the best engineers have a well-tuned sense of risk and timing, with an understanding of the consequences of bad decisions. Today’s AI agents exhibit few of these characteristics. Their capacity to take into account work culture, risk, and consequences is limited at best. As a result, a one-size-fits-all approach to creating a safe-by-default hyperscale infrastructure is unsuitable; we need nuanced policies that consider the different ways that humans and agents work.
Fundamentals: identity and observability
All agent policies are predicated on the ability to identify and observe agents acting on Infrastructure. For example, if an agent runs a command to resize a production job, the control plane executing the resize should be presented with identity credentials that identify the agent clearly. Control-plane logs should record that an agent, not a human, initiated the resize.
Thus, one of our foundational efforts is to ensure that all agents operating at Meta are identifiable and observable. To facilitate identity, we provision agents with unique credentials and execute agent-initiated, remote-procedure calls (RPCs) with cryptographically signed authentication tokens that identify the agent as well as the human user on whose behalf the agent is acting. These measures ensure that agentic-access policies (e.g., whether AgentX is allowed to modify a particular database) can be defined and enforced wherever needed.
To ensure that agent-initiated actions are distinguishable from human-initiated actions and non-AI automation, we extend our observability. This takes two forms. First, we enrich structured logs, which are primarily housed in Scuba, with agent identifiers, allowing investigators to distinguish between agent and non-agent actors. Second, we leverage Canopy to build rich agentic traces. These traces allow us to understand the multi-service interactions or trajectories that are a staple of agent workflows.
Risk discovery
Agents interact with infrastructure using a variety of control vectors: changing system code, modifying system configuration, running command-line-interfaces, and invoking remote procedure calls. Building infrastructure that is safe by default implies that actions that are unsafe for agents can be identified and appropriately protected.
Meta’s approach is to build LLM-powered classifiers that can analyze the aforementioned control vectors and produce risk scores. For example, an LLM classifier is able to analyze Thrift interfaces and assign them risk categories (e.g., read-only operation versus data deletion) and risk scores. Table 1 illustrates this classification using a fictitious RPC API.
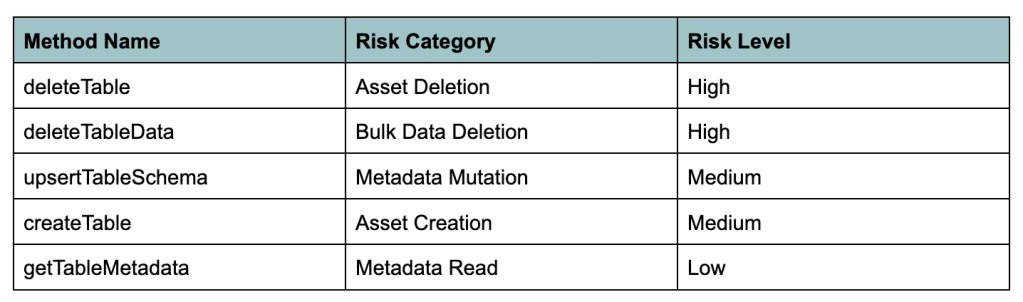
Classifiers have also been built for command-line tools, code review, and other control vectors.
Risk discovery also requires an accurate understanding of the importance, from a reliability perspective, of the infrastructure assets (e.g., data stores and services) that agents are interacting with. While an LLM classifier allows us to understand that deleteTable is a potentially dangerous action, an accurate risk assessment also requires us to understand the impact of losing data in a specific table. For example, a table containing ACLs (access control lists) is operationally critical, while a table containing synthetic test data can be trivially recreated. Thus, deleteTable(db=employee.db, table=employee_hr_data) is a high-risk operation, while deleteTable(db=test.db, table=synthetic_test_data) is not.
Distinguishing between these two cases requires building classifiers that identify the significance of classes of data (e.g., user data, employee data, operational data) as well as the significance of data within a class (e.g., not all operational data is high significance). By combining risk scoring on actions and assets, we can deploy guardrails to mitigate the most severe agentic risks.
Guardrails
Guardrails are security controls that restrict agents from executing dangerous actions on certain assets. In security terms, most agentic guardrails simply implement some form of authentication and authorization. The agentic guardrails accomplish this by leveraging the tuple of (identity, action, asset) to implement policies that restrict agents from executing such high-risk actions on highly significant assets.
- Identity: The entity acting on a data store or software system is always identified as a human, agent, or another (non-agent) system.
- Action: Every action performed by the entity has a well-understood risk level or risk score. Certain high-risk actions may be forbidden to agents based only on the combination of (identity, action), or a decision may require understanding the underlying asset being acted upon.
- Asset: Every asset being acted upon has an associated risk score that indicates the significance of the data contained in the asset. High-significance assets have commensurately high scores. High-risk actions may be permitted on low-significance assets, but will be denied on high-significance assets.
Using the (identity, action, asset) tuple, our guardrails fall into three broad categories:
- Agent sandboxing: All agents should run in a sandbox that enforces basic principles. For example, agents must use cryptographically signed agent identities for all outgoing requests. Sandboxes may also restrict agents from running high-risk CLI (command-line interface) commands (e.g., SSH wrappers that execute the same command on millions of servers).
- Action ACLs: These ACLs (access control lists) restrict agents from running actions that are never acceptable. For example, agents are forbidden to execute RPCs that allow them to provision new identities or to escalate security privileges.
- Asset ACLs: These ACLs enable asset-level policies. An agent may be allowed to perform any action on an ephemeral test database containing synthetic data, but will be forbidden from modifying a production database containing security controls.
Deploying agentic guardrails at Meta scale creates interesting challenges. Meta’s infrastructure entails thousands of services and millions of data stores. Our goal is to deploy guardrails in a way that maximizes risk mitigation while minimizing the impact to AI productivity. To balance these concerns, we must be able to measure both the risk that a guardrail mitigates and the impact the guardrail has on productivity. The latter is addressed by defining and measuring agentic friction.
Agentic friction
Most agents operating on Meta infrastructure are prompt driven. Users initiate a session in a browser or terminal and provide text-based commands that iteratively direct the agent to complete a task. This framework allows us to define a few simple constructs:
- Session: a long-running conversation between user and agent that may encompass many tasks. Sessions can last minutes or even days.
- Turn: a single, prompt-driven exchange between user and agent. Typically involves the user directing the agent to complete a specific task or refining the instructions to the agent as the session progresses. A session typically contains multiple turns.
- Actions: agent-initiated interactions in service of completing the current task. These can include MCP (Model Context Protocol) calls, CLI invocations, or remote-procedure calls to gather information (e.g., code search) or complete a goal (e.g., restart a failing server).
This oversimplified framework provides a basis for defining friction measurements that allow us to begin to understand the impact of deploying guardrails. Although our friction metrics are still evolving, we have found the following metrics to be quite useful:
- Impacted sessions/day: the % of sessions that encounter at least one guardrail per day
- Impacted turns/day: the % of turns that encounter at least one guardrail per day
- Blocked actions: the % of actions that are blocked by any guardrail
- Guardrails/users/day: the % of users that encounter at least one guardrail per day.
Metrics like these help us to aggressively pursue risk mitigation while imposing a ceiling on agentic friction. When friction becomes too high, we are forced to improve the accuracy and targeting of guardrails—typically replacing broad guardrails with narrower ones that target fewer actions or very specific assets. In other cases, we may introduce new APIs, designed for agents, that mitigate the risk and remove all agentic friction.
Future work
Guardrail Validation
Our goal of building agent-safe infrastructure encompasses virtually all of Meta’s infrastructure from our network to our datastores. As a result, we expect to deploy guardrails across thousands of software services and millions of data assets. However, software infrastructure is not static. New services and data assets emerge daily, and existing services/assets evolve over time. New actions and new assets may require new guardrails. For example, a database system may introduce new APIs to support efficient replication when the number of replicas is quite large. These APIs represent new actions that may require new agentic guardrails.
Existing APIs may evolve over time as well. A particularly interesting trend is that API owners will modify an existing API(s) to be safer (e.g., removing side effects) because they want agents to use that API(s). Such changes can significantly lower the risk profile of an action, necessitating lighter guardrails and enabling new types of agentic productivity.
As our infrastructure evolves, we are looking for ways to continuously update our guardrails and to validate that guardrails continue to serve their intended purpose. This work falls into three main categories:
- Continuous risk assessment: We are pursuing continuously running LLM classifiers that (re-)evaluate all agentic control vectors (e.g., CLIs, RPC APIs, system configurations) for risk and identify new or updated vectors that require guardrails. Note that this process may produce tighter guardrails on some control vectors and looser guardrails on others.
- Sweep-testing of all guardrails: This is test infrastructure that validates the entire corpus of existing guardrails regularly (e.g., daily). These tests are simple sweep tests that perform basic validation on every guardrail. For example, if a high-risk command-line tool (e.g., rebootServer –now) is forbidden to an agent, then a sweep test will try to execute that command (on a non-production server). The test passes only if the agent is unable to successfully execute the command.
- Penetration testing of critical guardrails: Agent-orchestrated interactions with systems can be complex affairs involving sequences of synchronous or asynchronous interactions with multiple systems. Guardrails may exist at multiple points of interaction along the way. Agent identity may be intentionally or unintentionally laundered along the way (e.g., when another system acts on behalf of an agent) causing agentic guardrails, which are predicated on agent identity, to be circumvented. Our approach to this risk is to execute penetration tests in which an adversarial agent attempts to execute a forbidden action by exploring different paths through our infrastructure. To start with, these tests are supervised, but we are looking for ways to automate such exploration in future.
Recovery Workflows
While we believe deploying AI guardrails is ultimately beneficial, we know that guardrail coverage will be imperfect and guardrails will occasionally fail. For example, an asset owner may choose to give an agent access to high-significance data because it enables massive productivity improvements. Alternatively, a misconfigured agent may fail to use its designated agent identity, thus bypassing any guardrails predicated on authentication/authorization.
In these scenarios, we need to be able to quickly and safely recover from destructive actions. While this need to recover data and systems has always existed, our expectation is that agent workflows increase the need for robust recovery workflows. Our initial focus is on exercising data recovery for data assets where agents have permission to update or delete data.
Conclusions
The advent of artificially intelligent agents operating software infrastructure introduces a fundamentally new actor that can operate software infrastructure—presenting new opportunities to improve engineering productivity while simultaneously introducing new risks to that software infrastructure. While today’s agents usually operate under human supervision, we envision large numbers of increasingly autonomous agents operating infrastructure with less human scrutiny over time. This future is only possible if infrastructure is safe by default for AI agents. To get there, we must ensure that:
- agents are always clearly identified,
- high-risk actions are protected by guardrails, and
- high-significance assets are similarly protected.
Guardrails should be deployed with an eye toward minimizing agentic friction, and iteratively narrow broad guardrails to enable agentic productivity while still effectively mitigating risk. As infrastructure evolves, guardrails should be continuously validated to ensure they are fit for their purpose. Last, guardrail failures are expected and recovery workflows should be regularly exercised.

