








Recommendation systems typically consider multiple signals based on your interactions with products. As you engage with the content—expressing interests, showing intent, indicating likes and dislikes—the recommendations get better; that is, more relevant and engaging for you. In simple terms, the more you use a product, the better it works for you.
How quickly the signals can be ingested, trained on, and used for providing recommendations is referred to as “freshness,” and we’ve found that improving the freshness for recommendation models can significantly improve user engagement.
For example, if you’re watching a football game live and an exciting event occurs, it’s satisfying to share that same moment or event. Getting immediate content recommendations from other fans discussing the same event around the world is likely to be more engaging than receiving the same recommendations hours later.
This ties back to how fresh the recommendations are and how quickly new signals can be incorporated into making them available to our users.
We are not alone in pursuing freshness. Many other companies across the industry are solving the same problem via both similar and different approaches.
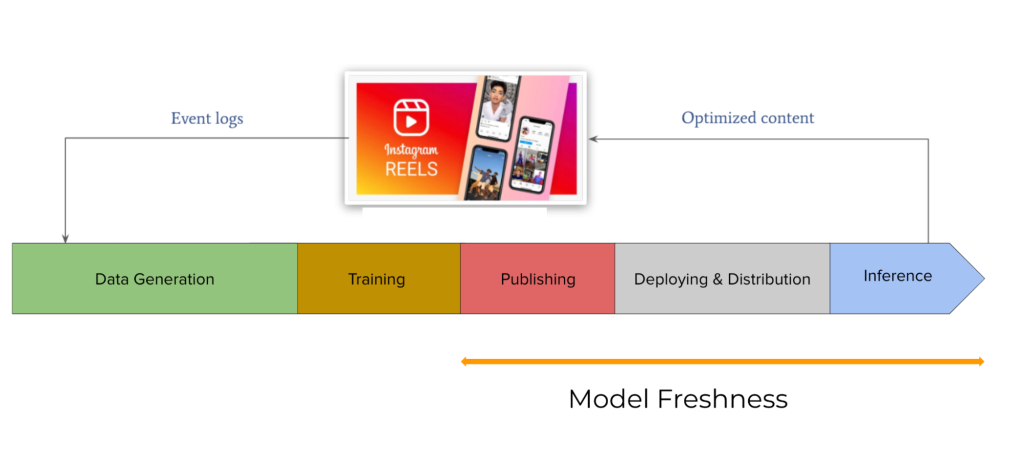
Here, we’ll dive into the challenges to improving freshness that Meta has faced and how we’ve overcome them over the past three years to build state-of-the-art recommendation systems. The entire workflow involves many components, including data and features, training, publishing, update distribution, deployment, and serving, as shown in Figure 1. We will specifically concentrate on the stages following the completion of training through active model deployment on predictors (i.e., ready-to-serve prediction requests).
Our challenges
The challenges we’ve dealt with have been centered in the areas of scale, complexity, and model diversity:
Scale
- Model size: Models have grown over the past few years—from 100s of GBs to tens of TBs, representing a massive increase in the amount of data that needs to be stored and moved around—even faster than before.
- Serving footprint: To meet market demand, model updates need to be distributed to millions of containers hosting these models.
- Update throughput: The fan-out of the large models to the large set of serving machines stresses the transport layer at an unprecedented scale—with network usage of 1000 TBPS across 20K models.
- Placement: Most model updates need to be replicated to several tens of regions across the globe to achieve the lowest latency for end users.
Complexity
To improve freshness, we faced a significant complexity challenge. Recommendation systems consist of multiple subsystems and the numerous underlying infrastructure components that support them, and enhancing freshness requires improvements across the entire system. For example, models need to be stored, validated for integrity, and safely rolled out, among other steps. If any one of these components lags or is unreliable, the entire system’s end-to-end latency suffers, limited by the slowest component in the workflow. By addressing model freshness holistically, organizations can unlock faster, more reliable, and more accurate predictions that drive better user experiences.
At the outset of our journey, many infrastructure components were not initially designed for large-scale and real-time usage. Rather than transforming all components simultaneously, we adopted a multi-year transition plan, gradually developing new services and components, and significantly reduced latency in existing services across publishing, predictors, data distribution, and control planes. In this way we achieved freshness improvements while meeting Meta’s scale and reliability standards.
In subsequent sections, we will illustrate these changes and highlight the specific improvements made to enhance freshness in our recommendation systems.
Model diversity
Meta’s model landscape encompasses a wide range of types, including retrieval, early-stage ranking, late-stage ranking, foundation models, and GenAI models. Each model type requires unique freshness requirements. While some models can thrive with a freshness of one hour, others necessitate minute-level refreshes to maintain optimal performance.
Furthermore, even within the same model type, different components may have distinct freshness requirements. For instance, updates to item embeddings in late-stage ranking models can yield substantial gains with zero-second latency, whereas dense parameters can tolerate delays of tens of minutes without compromising performance.
Given these nuances, a one-size-fits-all approach is not feasible. When designing systems, tradeoffs must be carefully made to balance the freshness requirements of various model types and components. Engineering the optimal freshness interval that balances performance, effectiveness, and resource efficiency presents a significant challenge.
A multi-year journey
Overcoming the challenges outlined above and paving the way for realizing business gains has been a multi-year endeavor. In this section, we will delve deeper into the development stages that have led to our current state-of-the-art system at Meta.
2021-2022
Let’s begin with the relatively simple paradigm known as snapshot transition, which was the default state before we started our journey.
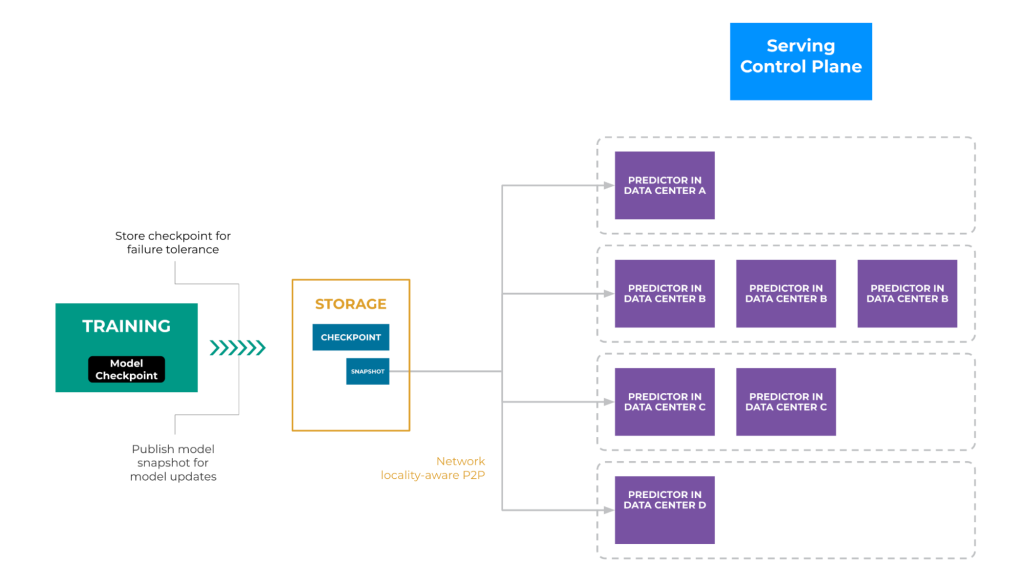
In this paradigm, trainers continuously train the model and periodically generate checkpoints. These checkpoints serve as a safeguard against node failures in distributed training jobs, allowing the job to recover from the most recent checkpoint in the event of node failures. Additionally, every few hours, the checkpoint is used to publish a full snapshot of the model via a separate service. A snapshot is optimized for the purpose of inference and stores the model’s latest parameters for a model. Figure 2 below is a high-level overview of the model training, snapshot generation, and snapshot serving.
From the storage- and network-transport points of view, the snapshot is essentially a large data blob stored. The inference-orchestration control plane detects the new snapshot and gradually notifies each predictor across the globe to load the latest snapshot. During the loading process, the predictor temporarily stops serving prediction requests and resumes once the loading is complete. To ensure uninterrupted service, capacity buffers are allocated to facilitate this gradual transition, guaranteeing that sufficient predictors remain online to handle all prediction traffic while others are offline for updates.
At this stage, the model-update latency was approximately three to six hours. Fortunately, when we first began investigating improvements to the latency, there were several low-hanging fruits that presented opportunities for improvement.
For instance:
- We implemented a novel network locality-aware, peer-to-peer (P2P) sharing technique, which is detailed in our publication “Owl: Scale and Flexibility in Distribution of Hot Content” (OSDI’22).
- A new in-line publishing framework enabled snapshot publishing to occur concurrently with checkpointing states into storage services in the training system.
- Both the modeling team and the model publishing team employed more aggressive model-optimization techniques to reduce snapshot size.
By leveraging these techniques, we successfully reduced the latency to a range of one to two hours for certain critical models that were only a few hundred GBs in size.
Progress in 2022-2023
Model consistency versus model freshness
Following extensive experimentation and research, we discovered that many recommendation models do not require consistent and atomic updates. Instead, the quality of the final predictions is more heavily influenced by the freshness of the model parameters than by the consistency of the models themselves.
For instance, we can incrementally update specific components of a model on a predictor while it continues to serve prediction traffic. During this gradual transition phase, the model exists in an inconsistent state: Certain parts may be updated to the new version, whereas others remain on the old version. Although this approach offers a weaker consistency guarantee, for numerous recommendation models it does not compromise prediction quality.
Figure 3 below illustrates this concept:
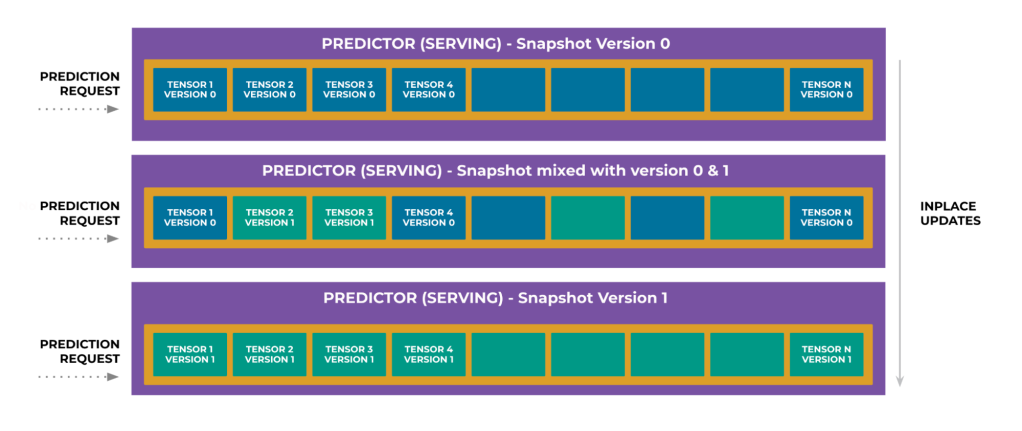
Figure 3: In-place updates
Building on our observation, we also considered the possibility of selectively updating specific parts of models to prioritize fresher parameters. Specifically, could we maintain a model that operates with a mixture of old and new tensors for an extended period (e.g., 30 minutes)? Meanwhile, could other models still be updated, albeit at a lower frequency, using traditional snapshot transitions to ensure eventual consistency (e.g. every 2 hours)?
After conducting additional experiments on critical recommendation models, we found that the answers to these questions were indeed yes.
By further relaxing consistency constraints, we began publishing delta updates for models every 15 minutes, offering the following flexibility to the modeling team:
- We can generate delta updates for both dense and sparse model parameters, which can be applied in parallel at different frequencies.
- Delta can be both lossless and lossy, meaning they don’t need to capture all changed parameters between two snapshot versions. Instead, people have the option to configure by focusing on the top 10% most important model parameters to reduce infrastructure costs associated with storing and distributing the updates globally. This approach was published in “QuickUpdate: A Real-Time Personalization System for Large-Scale Recommendation Models” (NSDI’24).
Figure 4 below illustrates the delta update concept, which selectively updates only parts of the model weights.
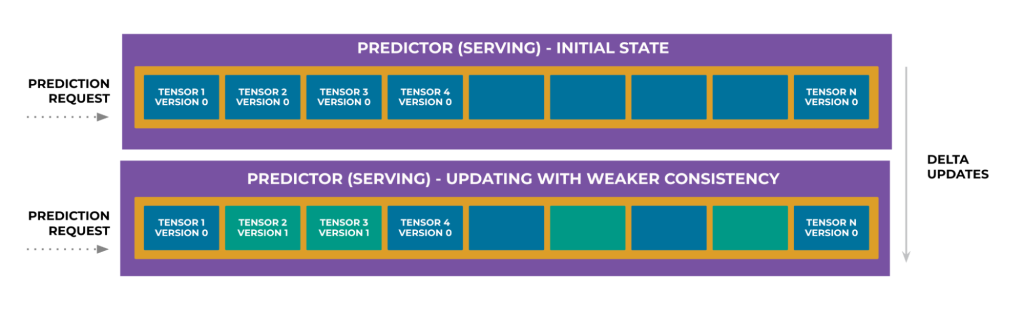
Figure 4: Delta updates
Beyond the introductions of delta updates, we also:
- Improved the inference-serving control plane and its underlying infra. This reduced the latency overhead for the control plane to notify each predictor before each one starts loading the latest delta updates.
- Further reduced the network-distribution latency for the new delta-update type.
Figure 5 below shows the improvement on delta distribution:
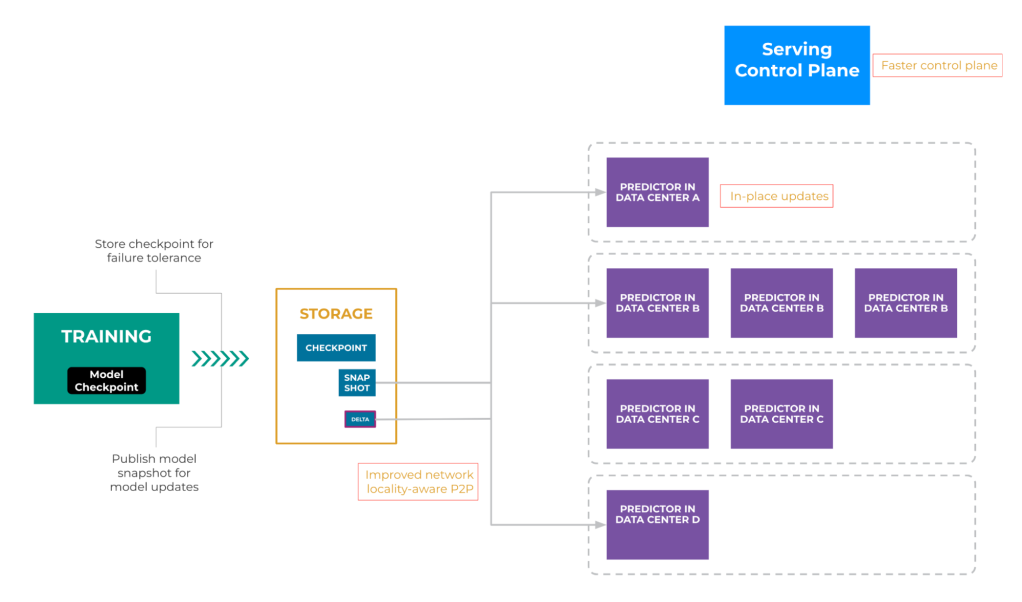
Figure 5: Additional Delta Distribution Improvements
By leveraging these techniques, we achieved freshness at approximately 10-30 minutes.
2024 to the present
Further contributing to improving model freshness, another key observation we made is that we can significantly improve the efficiency of our pipeline by overlapping the training, distribution, and serving processes. This is possible because both the training and serving sides operate at the tensor level, with each model comprising thousands or more tensors.
In the existing workflow, publishing involves a working queue that processes all tensors, buffering updates until it receives them from all tensors before sending them out. Meanwhile, the predictor remains idle, waiting for serving-control-plane signals to start processing the update. This process can take up to several minutes, depending on the total update size and control-plane overhead.
To address this bottleneck, we have adopted a more efficient approach: Instead of batch-processing all tensors in a given model simultaneously, we can stream individual tensors to the inference systems as soon as they are updated. Figure 6 below illustrates this data flow. Meanwhile, we make the serving control plane operate asynchronously to the predictor (data plane) for streamed updates. This allows us to overlap the training, distribution, and serving processes, reducing idle time and improving overall pipeline efficiency.
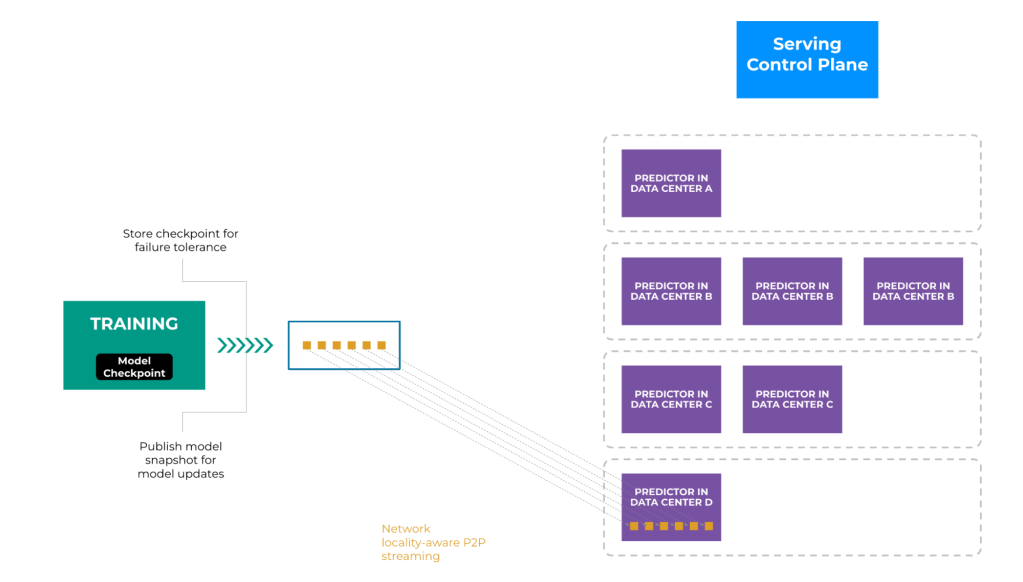
The underlying streaming can be complicated. The new P2P streaming system is built on top of Meta’s Owl system, which was originally designed to construct peer-to-peer distribution trees rooted from a single data source.
In our distributed training setup, however, we no longer have a single root for each tree. This complexity is further compounded by the fact that a single predictor may not be able to hold an entire large model within its memory limit, necessitating model sharding across multiple hosts, also known as “distributed inference.” As a result, we require all-to-all mappings between training and serving hosts, which adds another layer of intricacy. To address these challenges, our P2P streaming system creates a P2P forest that bridges the training and serving hosts, facilitating low-latency model updates across Meta’s global data centers.
This can get even more complicated when we have different types of model updates, such as in the scenario mentioned above where a model has weaker consistency. Different model parts can be updated at different cadences, and we update only the most valuable parts in terms of model freshness wins at the highest frequency. We do not need to update model parts that rarely get updated. So, effectively, there will also be different data flows happening at different cadences. For example, one of the specific challenges is to how to reduce the contention of different data flows on the predictor side.
On the serving-control-plane side, we also made a big change. Instead of notifying predictors in multiple stages to load updates, the control plane starts acting asynchronously: Notifications of new updates no longer go through the control plane in the happy path, but the control plane still observes update-consumption status and serving-cluster health. This brings freshness down to O (one minute).
Balancing Latency and Safety
There exists a fundamental tradeoff between mean time to failure (MTTF) and mean time to revert (MTTR). In other words, we must balance the need for reliable model updates with the desire for freshness. To achieve this balance, we offer three distinct approaches to validate model updates, each with its own tradeoffs, that cater to various model-owner preferences:
- We can thoroughly validate the model and key metrics (such as NE metrics) for tens of minutes before deploying it in production. Subsequently, we use staged rollouts to update the model in production, where 10% of predictors load the new snapshot and bake for 15 minutes to detect regressions before the remaining predictors load the new snapshot.
- We can perform light validation for a few minutes, followed by either a single-stage rollout or a faster two-stage rollout with only one-minute baking time.
- We can perform sanity checks on the publishing side and send updates in real time, while having mechanisms in place to detect failures quickly and roll back fast. This approach assumes that such failures are rare and cause less damage than the benefits of real-time updates over time.
Snapshot transitions are generally considered high risk, since the model shape can change significantly between updates. Therefore, we are employing the first approach with a staged system, “Conveyor: One-Tool-Fits-All Continuous Software Deployment at Meta” (OSDI’23). Although the system was not originally designed for latency-sensitive use cases like delta updates, recent improvements have reduced the overhead significantly. For delta updates, some model owners prefer the second approach, while others opt for the third approach, depending on their specific requirements.
Looking Forward
As we move forward, we face several challenges that will test the limits of our infrastructure. For instance:
- Achieving second-level model freshness with 10x model-size growth: As model sizes continue to grow, we face significant scalability challenges in updating these large recommendation models efficiently in real time. This growth will lead to substantial data movements across the globe, resulting in high cross-region network costs that will become a substantial portion of our total infrastructure costs.
- Handling hardware heterogeneity: With a diverse range of GPU and CPU hosts, each with different processing speeds, network bandwidth, and resource usage, we must develop strategies to effectively update models on these varied hardware types. This is especially challenging when hardware types are mixed together for receiving updates for the same model.
- Collaborating with ML engineers to unlock the full potential of infra latency reductions: Many existing models do not account for real-time updates of individual model components. To fully harness the power of our infrastructure latency reductions, we need to work closely with ML engineers to adopt this concept, which will likely trigger increased engagement metrics.
We will continue to address incoming challenges to ensure that our infrastructure supports the growing demands of our recommendation systems and provides a seamless experience for our users.

